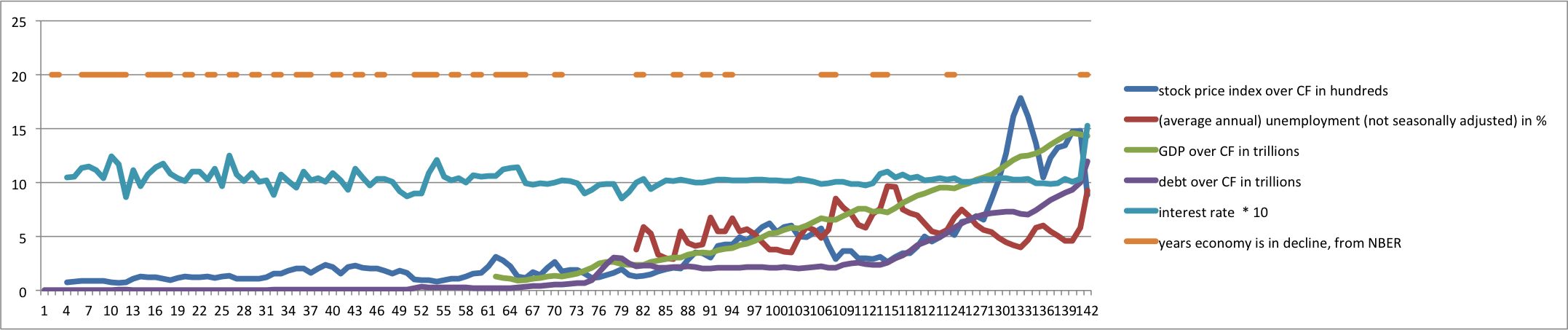
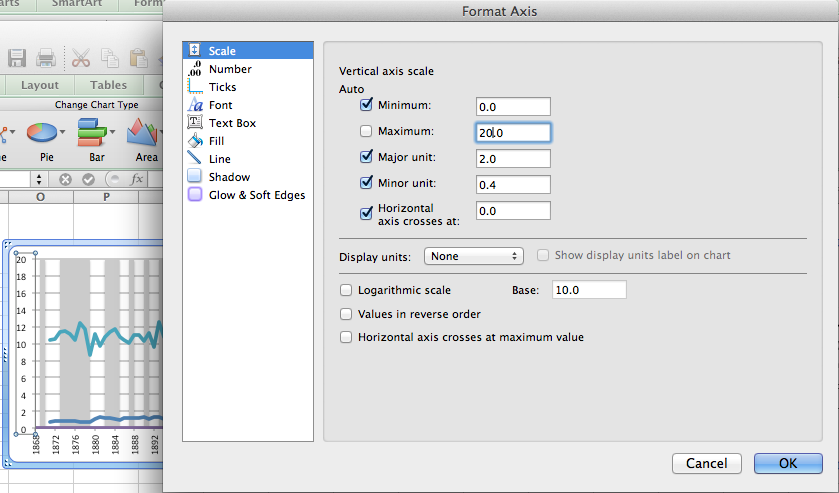
Within the Center for Data and Visualization Sciences (CDVS) we pride ourselves on providing numerous educational opportunities for the Duke community. Like many others during the COVID-19 pandemic, we have spent a large amount of time considering how to translate our in-person workshops to online learning experiences, explored the use of flipped classroom models, and learned together about the wonderful (and sometimes not so wonderful) features of common technology platforms (we are talking about you, Zoom).
 We also wanted to more easily surface the various online learning resources we have developed over the years via the web. Recognizing that learning takes place both synchronously and asynchronously, we have made available numerous guides, slide decks, example datasets, and both short-form and full-length workshops on our Online Learning Page. Below we highlight 5 online learning resources that we thought others interested in data driven research may wish to explore:
We also wanted to more easily surface the various online learning resources we have developed over the years via the web. Recognizing that learning takes place both synchronously and asynchronously, we have made available numerous guides, slide decks, example datasets, and both short-form and full-length workshops on our Online Learning Page. Below we highlight 5 online learning resources that we thought others interested in data driven research may wish to explore:
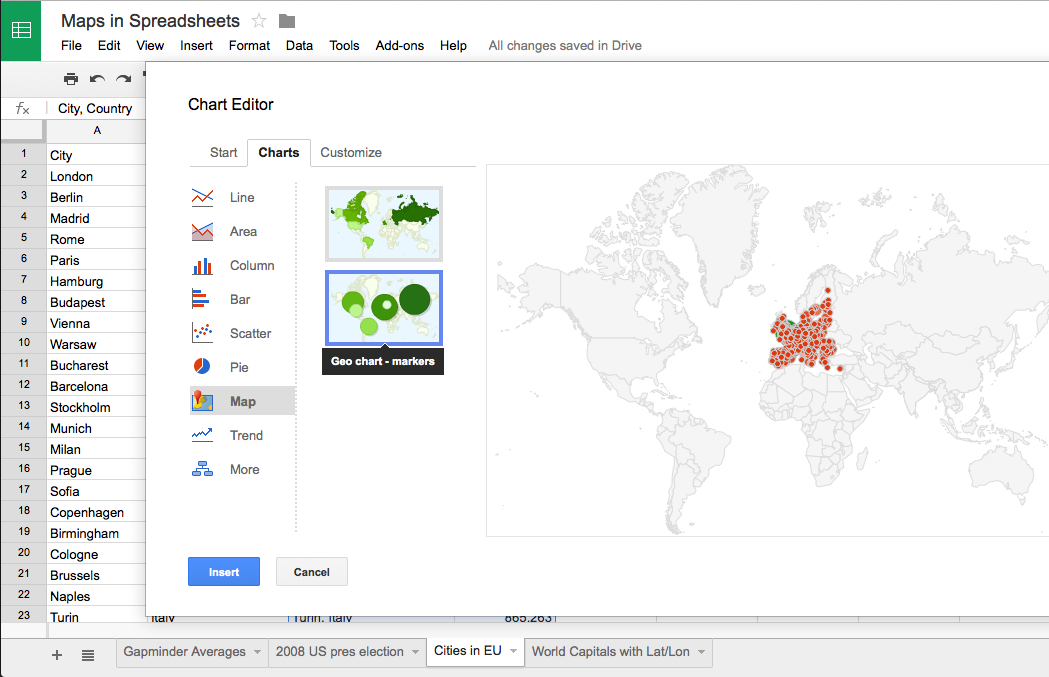
- Mapping & GIS: R has become a popular and reproducible option for mapping and spatial analysis. Our Geospatial Data in R guide and workshop video introduce the use of the R language for producing maps. We cover the advantages of a code-driven approach such as R for visualizing geospatial data and demonstrate how to quickly and efficiently create a variety of map types for a website, presentation, or publication.
- Data Visualization: Visualization is a powerful way to reveal patterns in data, attract attention, and get your message across to an audience quickly and clearly. But, there are many steps in that journey from exploration to information to influence, and many choices to make when putting it all together to tell your story. In our Effective Data Visualization workshop, we cover some basic guidelines for effective visualization, point out a few common pitfalls to avoid, and run through a critique and iterations of an existing visualization to help you start seeing better choices beyond the program defaults.
- Data Science: QuickStart with R is our beginning data science module focusing on the Tidyverse — a data-first approach to data wrangling, analysis, and visualization. Beyond introducing the Tidyverse approach to reproducible data workflows, we offer a rich allotment of other R learning resources at our Rfun site: workshop videos, case studies, shareable data, and code. Links to all our data science materials can also be found collated on our Online Learning page (above).
- Data Management: Various stakeholders are stressing the importance of practices that make research more open, transparent, and reproducible including NIH who has released a new data management & sharing policy. In collaboration with the Office of Scientific Integrity, our Meeting Data Management Plan Requirements workshop presents details on the new NIH policy, describes what makes a strong plan, and where to find guidance, tools, resources, and assistance for building funder-based plans.
- Data Sources: The U.S. Census has been collecting information on persons and businesses since the late 18th century, and tackling this huge volume of data can be daunting. Our guide to U.S. Census data highlights many useful places to view or download this data, with the Product Comparisons tab providing in chart form a quick overview of product contents and features. Other tabs provide more details about these dissemination products, as well as about sources for Economic Census data.
In the areas of data science, mapping & GIS, data visualization, and data management, we cover many other topics and tools including ArcGIS, QGIS, Tableau, Python for tabular data and visualization, Adobe Illustrator, MS PowerPoint, effective academic posters, reproducibility, ethics of data management and sharing, and publishing research data. Access more resources and past recordings on our online learning page or go to our upcoming workshops list to register for a synchronous learning opportunity.



 The end of the spring semester always brings presentations of final projects, some of which may have been in the works since the fall or even the summer.
The end of the spring semester always brings presentations of final projects, some of which may have been in the works since the fall or even the summer. 

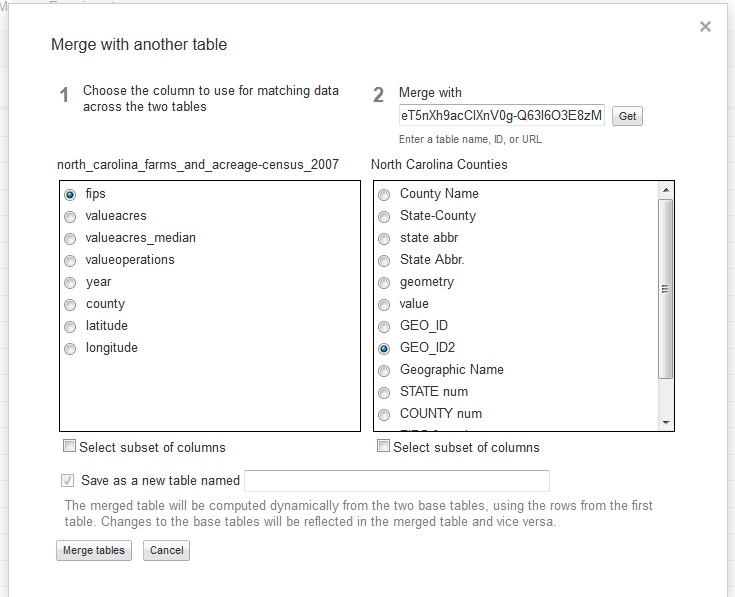
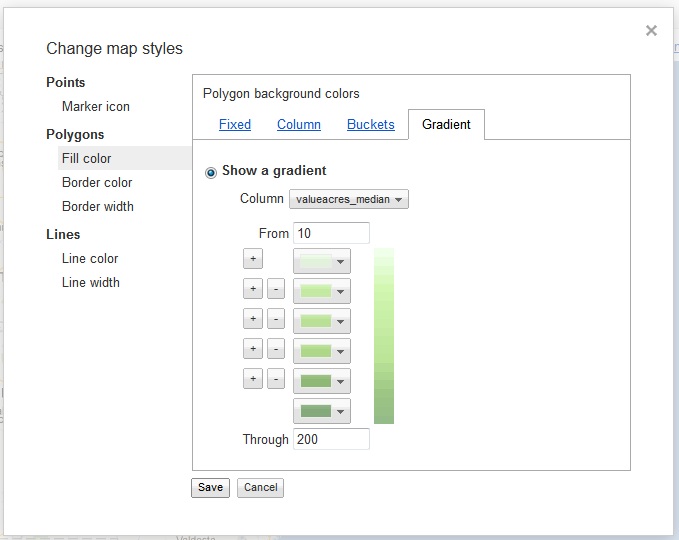
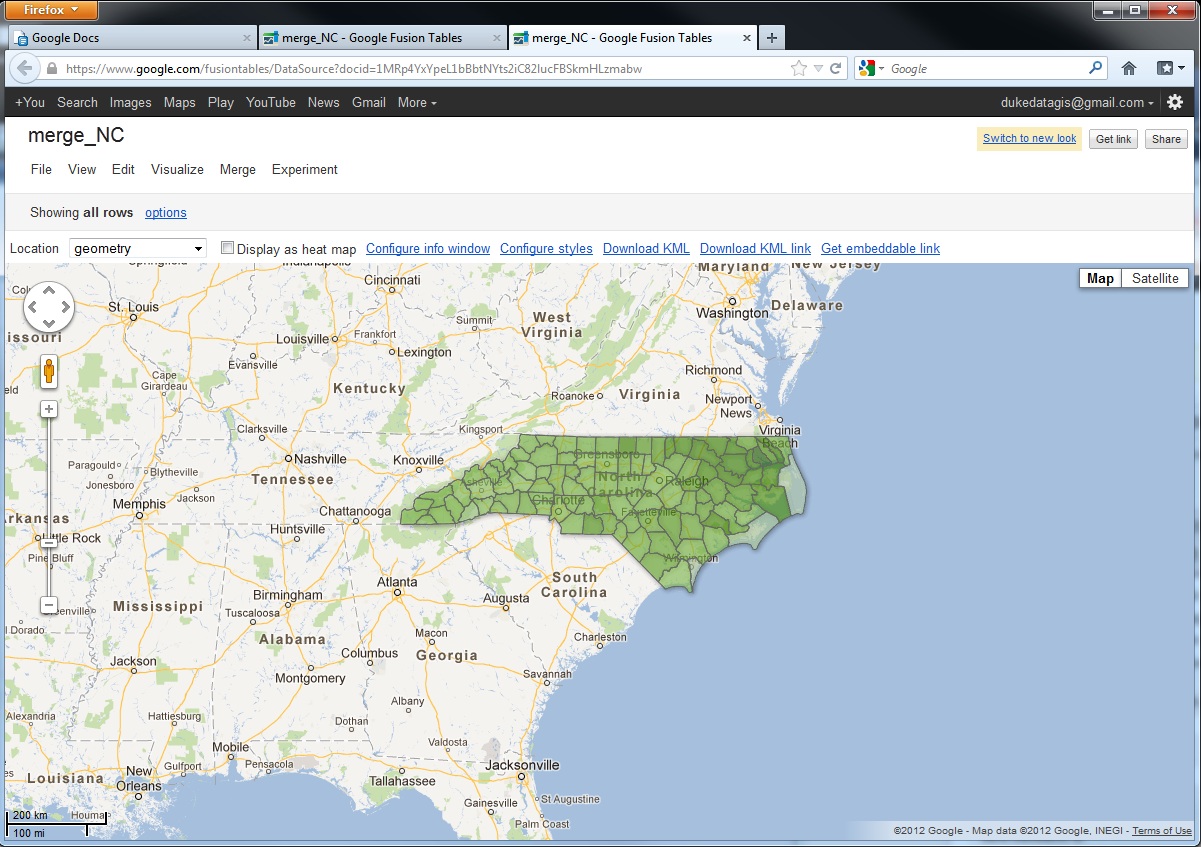
 Here at Data & GIS Services, we love finding new ways to map things. Earlier this semester I was researching how the
Here at Data & GIS Services, we love finding new ways to map things. Earlier this semester I was researching how the 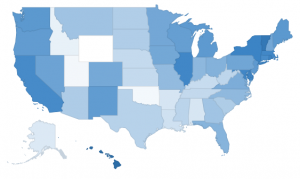 Region maps (Choropleths)
Region maps (Choropleths)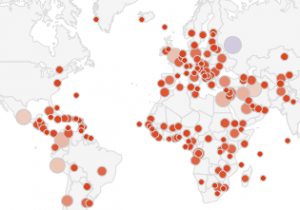 Marker maps (Proportional symbol maps)
Marker maps (Proportional symbol maps)