Need held curating your data or identifying a repository to share data? Helenmary can help!
CDVS welcomes Helenmary Sheridan as the third member of the research data management (RDM) team. Helenmary joined Duke in August 2024 to help the library scale up classes, group trainings, and individualized consultations on RDM topics including NIH data management plans, data sharing in repositories such as the Duke Research Data Repository, and improving research reproducibility through documentation. Her position is supported by the Compute and Data Services Alliance for Research (CDSA), a new cross-campus initiative to support researchers with their computational needs.
Prior to joining Duke, Helenmary was the Data Services Librarian at the health sciences library at the University of Pittsburgh, where she provided data management training to faculty, staff, and students across the health disciplines. She has nearly ten years of experience working with scientific metadata and file formats, especially for data from imaging research (biomedical and otherwise.)
Helenmary’s favorite part of her job is teaching, especially Introduction to Research Data Management workshops for new graduate students and faculty that may be their first formal experience with research data methods. “It sounds like a dry subject,” she says, “so I love to see how excited researchers get when they realize how much easier these tools can make their lives.” You can contact Helenmary through the CDVS inbox at: askdata@duke.edu.
Federal data supports Duke research across disciplines.
Since January 31, 2025, Duke Libraries has received numerous reports of federal agencies removing access to data, altering existing research datasets, and purging data documentation. As we continue to monitor changes in access to federal data collections, I want to assure the Duke research community that we continue to work with colleagues in the curation, archives, and academic professional associations working to safeguard access and preservation of federal datasets.
This week (February 3, 2025), multiple data groups are meeting to plan coordination efforts for preserving the federal data record. Given the size and complexity of the federal government’s data holdings, early efforts are focused on identifying data at-risk and documenting existing efforts to ensure its preservation. Duke Libraries will continue to stay engaged through our institutional membership in the Data Curation Network and individual memberships in IASSIST and RDAP in these efforts. We will also continue to share news as this work evolves.
Resources for the Duke community
We realize that federal data access plays a fundamental role in advancing Duke research. We encourage you to contact askdata@duke.edu or your library subject specialist if you need advice on appropriate data sources or are unable to access the data that you need for research and/or teaching. We also welcome expressions of concern about access to federal data collections with the understanding that we are trying to focus our efforts (with data colleagues around the country) on federal data of particular importance to the Duke community.
We appreciate your concern, advocacy, and research efforts in this time. We look forward to working with you to ensure data access for the Duke community.
McCall Pitcher joined CDVS at the end of October 2024 and is delighted to start her first full semester supporting Duke students, faculty, and staff as they create effective data visualizations. McCall comes to Duke from George Washington University, where she spent two years teaching data visualization to graduate students in the Trachtenberg School of Public Policy and Public Administration. Her course equipped students with core theoretical approaches around graphical communication, data storytelling principles, and foundational R programming techniques to clean and visualize data.
McCall brings nearly five years of experience from American Institutes for Research, where she built many data visualizations and diagrams for clients including the U.S. Department of Education’s National Center for Education Statistics and the Bill & Melinda Gates Foundation. She has also worked as a data visualization contractor for researchers and professors at the University of Maryland and the Aspen Economic Strategy Group.
Passionate about making graphics clean and clear, McCall looks forward to consulting and instructing in a way that prioritizes both aesthetic and story. In her short time in this role, McCall has already been blown away by the Duke community’s talent and subject matter expertise — she can’t wait to continue helping all these brilliant minds visually communicate their exciting findings and ideas.
The Duke Research Data Repository (RDR) has published over 310 datasets in a myriad of scientific disciplines including chemistry, biology, biomedical engineering, marine science, and medicine. Additionally, the RDR hosts datasets associated with articles published in PLOS, Nature, and PNAS and funded by NIH and NSF, their multiple sub-agencies and institutes, and others. The RDR provides a DOI for all datasets, and commits to long-term access and retention of data and curates all data based on the Data Curation Network (DCN) CURATED model. As members of the renowned Data Curation Network (DCN), we leverage the expertise of a multi-institutional consortium that shares expertise to increase the quality of data curation across all DCN affiliated repositories. The Duke Libraries are proud to be able to offer this local resource that supports the needs of Duke researchers who are not sufficiently served by disciplinary, data type or funder-based resources. In addition to providing the platform, we also provide front-line services for data management planning, data curation, disclosure risk review and referrals .
As the culture and landscape of data sharing evolves, researchers have many different repository options – from funder-sponsored repositories to discipline/community specific repositories to generalist repositories. Occasionally, journal publishers and funding agency Program Officers have questioned the suitability of institutional data repositories for long-term data sharing and preservation. To communicate the value of institutional resources focused on data sharing, we and other members of the DCN collaboratively wrote a letter to Science arguing that institutional data repositories provide valuable local infrastructure for researchers needing to meet data publishing guidelines.
In this letter, we detail how our repositories align with the FAIR guiding principles and commit to providing sustainable access to data critical for research reproducibility. This letter was published in the September 13 Issue of Science – Institutional Data Repositories are Vital (DOI: 10.1126/science.adr0789, open access copy available at: https://hdl.handle.net/11299/265639). The DCN has also published research that examined what researchers valued about their institutional data repositories and the services they provide. As one researcher noted
“I am thankful and excited for the help in curation…I see that teamwork in this final step of research means that the best possible version of the material will be available to future generations..”
All this to say, should you, as a researcher, need to demonstrate that an institutional data repository is an acceptable strategy for sharing data, we encourage you to cite the Science letter and reference the Duke Research Data Repository’s documentation clarifying how the RDR approaches compliance with the NIH Desirable Characteristics for Data Repositories . Comments or questions about the RDR can be sent to datamanagement@duke.edu.
Publications referenced:
Jen Darragh et al. (2024). Institutional data repositories are vital. Science 385,1174-1174(2024). DOI:10.1126/science.adr0789
Marsolek W, Wright SJ, Luong H, Braxton SM, Carlson J, Lafferty-Hess S (2023). Understanding the value of curation: A survey of researcher perspectives of data curation services from six US institutions. PLoS ONE18 (11): e0293534. https://doi.org/10.1371/journal.pone.0293534
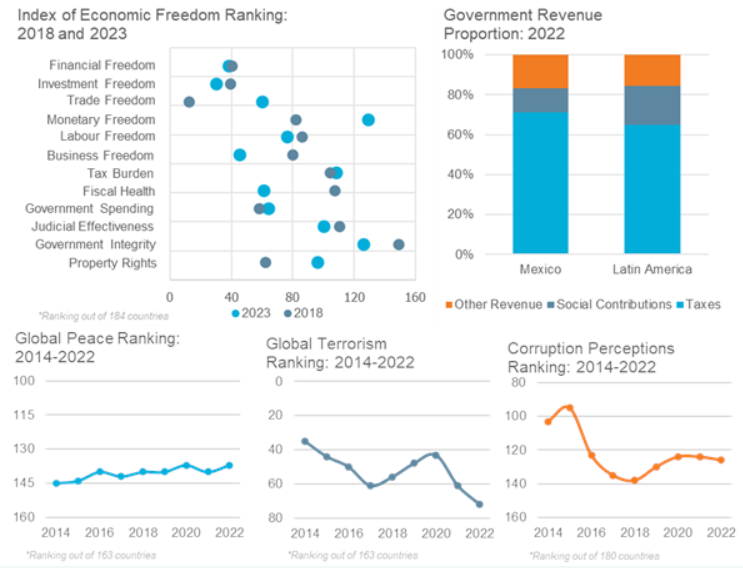
Students and researchers often ask CDVS for data on risk assessments of countries and risk comparisons between them. Some of the data sources relating to risk provide index numbers in downloadable tabular format measuring different aspects of risk, such as economic or political. They may include a few index numbers, or even thousands of nuanced indicators and changes over many years. Some of the sources provide graphic representations to compare different risk components, different countries, or changes over time. Other sources provide a more narrative discussion of risk, typically including tables and visuals, rather than downloadable datasets. The resources highlighted below present examples of each of these presentation methods and should provide researchers needing risk information with meaningful data.
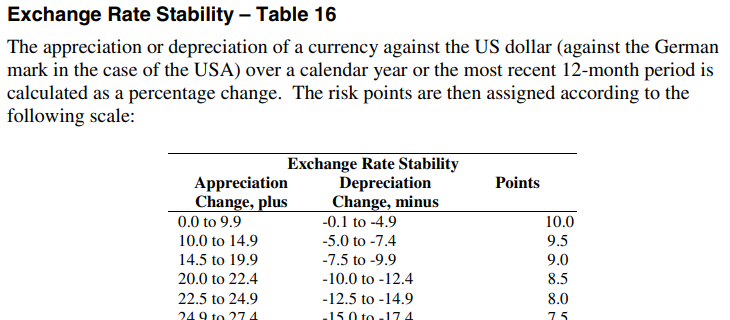
Covering 141 developed, emerging, and frontier countries, and offshore financial centers, ICRG presents monthly political, economic, financial and composite risk ratings and forecasts, provided in Excel format. The focus is on risks related to doing business in a country, although the index numbers have broader applicability. Index numbers fall within a 0-4 to a 0-12 range depending on the indicator, with the lower numbers for a given indicator representing more risk, and a codebook describes how the points are assigned.
For each country, the data includes monthly index numbers back to 1984. Duke has holdings of the Historical Political (Table 3B), Financial (4B), and Economic (5B) datasets, through 2016, which we occasionally update. The ICRG Researchers Dataset – Table 3B provides annual averages of the components of ICRG’s Political Risk Ratings (government stability, socioeconomic conditions, the investment profile, internal conflict, external conflict, corruption, military in politics, religions tensions, and law and order).
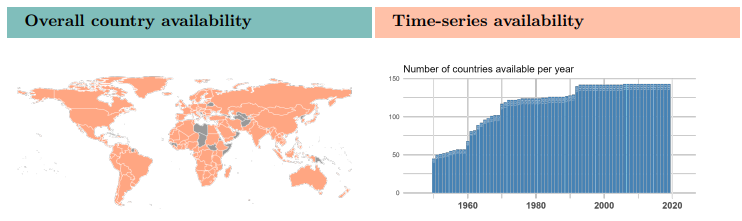
Variable availability by country, from Standard Dataset codebook
Compiled from open-source data, this free, extensive, and well-documented data collection includes their flagship Standard Dataset, with around 2100 variables. These are grouped into the following categories: Bureaucratic Structure, Civil Society/Population/Culture, Conflict, Education, Energy and Infrastructure, Environment, Gender Equality, Health, History, Judicial, Labour Market, Media, Migration, Political Parties and Elections, Political System, Private Economy, Public Economy, Quality of Government, Religion, and Welfare.
The Standard Dataset comes in a cross-section version, with recent data, and a time-series dataset covering 1946 to 2023. Formats include Stata (.dta), CSV, Excel (.xlsx), and SPSS (.sav). The codebook for the Standard Dataset is nearly 1700 pages. The QoG Basic Dataset contains the most frequently used variables from the Standard Dataset, and QOG also has datasets relating to the OECD, the EU, and for environmental indicators.
From the same company that creates the ICRG data (see above), the Political Risk Yearbooks provide a more narrative assessment of country-by-country risk factors, with probability forecasts for political, social, and economic trends for 100 countries.
The Political Rick Yearbooks are included in the Business Source Complete database from EBSCO since 2003. In the Advanced Search interface, choose the “SO Publication Name” field in the dropdown and search <Political Risk Yearbook [name of country]> to find issues from a particular country.
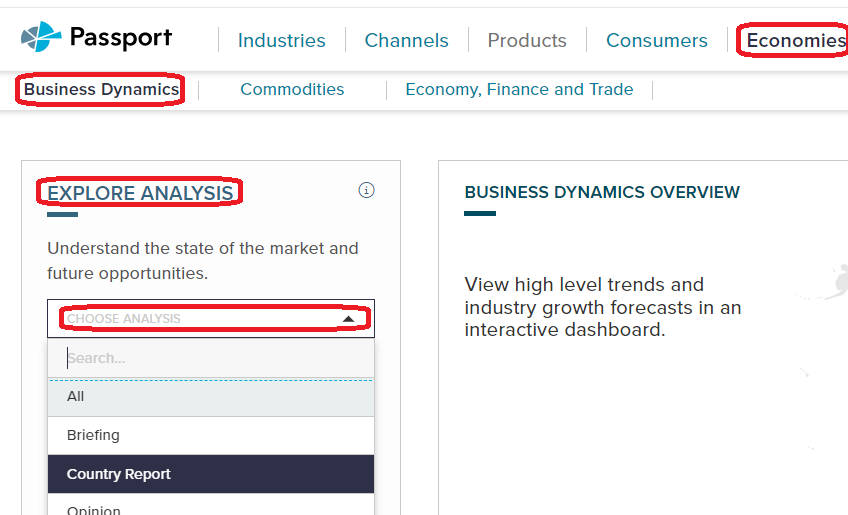
In Passport, Country Report is an option under several of the menus. One good assessment of risk can be found in the Country Reports under Economies … Business Dynamics. Under Explore Analysis, choose Country Reports in the Choose Analysis drop-down.
Also under the Economies tab, if you choose Economy, Finance and Trade, then choose Country Report under Explore Analysis as above, a useful report for risk outlook is the PEST analysis report (political, economic, social, and technological). These reports describe a framework of macro-environmental factors to use as a tools for environment scanning, understanding risks and opportunities, market growth or decline, business position, and potential and direction for operations, focusing on ways to help companies to become more competitive. The PEST reports discuss opportunities and challenges for each of the four facets.
From a Country Report in Passport
You might find other useful assessments of risk in other reports in Passport, so feel free to explore. Charts and analysis in the reports draw data from IGOs like the IMF and the ILO, as well as from think tanks with an interest in economic and political freedom, like the Heritage Foundation. Be sure to check the sources they use in their reports.
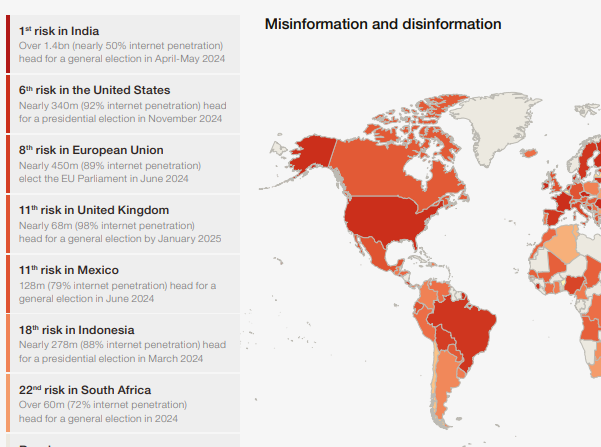
The annual Global Risks Report explores some of the most severe risks we may face in the coming years. Underpinned by the Forum’s Global Risks Perception Survey, the report brings together leading insights from over 1,200 experts across the world. The focus is on a narrative discussion of risks (economic, climate, political, etc.) facing the world as a whole, but there are some visuals or maps comparing countries or regions.
Each annual report has a summary with key findings. Data from the Perception Survey is presented as charts and graphs in the areas of Current Risks, Severity, the Global Risk Landscape, the Outlook for the World, Political Cooperation, Risk Governance, and Risk Profile. The WEF does not provide the actual raw data from the survey. “Shareables” include visuals on topics such as the “Top 10 Risks” and in “Interconnections” graphic of the global risks landscape.
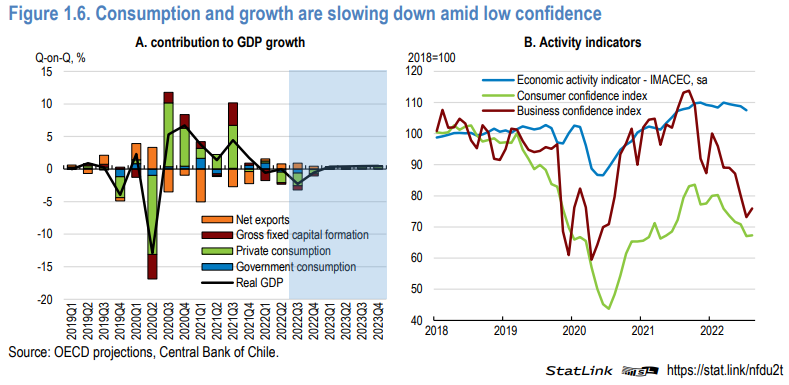
These country-level reports are thorough assessments of a country’s economy and its economic prospects. They are in PDF format, but the data used in the graphs and charts can be downloaded in Excel format from within the PDFs. The 100+ page reports cover OECD member countries and some leading trade partners (such as China) and are published frequently, although not necessarily every year. For some countries, the series goes back as far as 1962.
As part of the university’s historic centennial celebration, we are excited to announce the Research Data Visualization Competition & Showcase, where creativity and data meet to mark 100 years of academic excellence and innovation.
We invite the Duke University research community to submit data visualizations that interpret or touch on the theme of “Through Time.” Whether you are studying human history, molecular evolution, or the flow of water through a tributary, we invite you to share your data storytelling skills. This competition is an opportunity to both celebrate our rich history and envision our promising future.
Submission Deadline: January 8th, 5pm
Don’t miss this chance to be a part of our centennial celebration and make your mark on history!
In 2024, the GIS software ArcGIS Desktop (also known as ArcMap) will no longer be available through Duke’s education license. Esri has been encouraging users to upgrade to their more modern GIS software, ArcGIS Pro, or cloud-based platforms such as ArcGIS Online. CDVS’s GIS workshop series has not included an ArcMap session for the past several years, and we have been encouraging anyone interested in learning GIS software to start with ArcGIS Pro. You can read more details about the process in Esri’s blog post, ArcMap Retirement in Education Programs.
While the transition away from ArcMap has been moving forward, we occasionally hear from students and faculty who are still using this software. If you have yet to make the switch from ArcMap to ArcGIS Pro or ArcGIS Online, please consider doing so this semester.
Fortunately, there are many resources available to help you navigate the shift. Esri provides dozens of free, self-paced online tutorials about ArcGIS Pro and ArcGIS Online. You may also want to explore their tutorial series Modern GIS. For those looking for a more personal and interactive learning experience, we are offering several GIS workshops in Fall 2023. Finally, the in-depth Migrate to ArcGIS Pro (log-in required) documentation includes a training video and guide that address topics like migrating Python scripts and importing styles from ArcMap.
These guides should explain everything you might want to know (and much more) about the change. If you still have questions or want to learn more about other software options, please don’t hesitate to contact one of our GIS specialists by sending an email to askdata@duke.edu.
The Curation Team for the Duke Research Data Repository is happy to present an interview with Dr. Thomas Struhsaker, Retired Adjunct Professor of Evolutionary Anthropology.
CC-BY Thomas Struhsaker, Medium Juvenile Eating Charcoal, July 1994, Jozani
Dr. Struhsaker’s dataset, Digitized tape recordings of Red colobus and other African forest monkey species vocalizations, was the 200th dataset to be added to the Duke Research Data Repository. I worked closely with Tom to arrange and describe this collection. He hopes to be adding even more in the near future as he winds down his career. Tom might not know this, but his dataset has been tweeted about 36 times at this point and has been viewed 336 times since August. Ever the humble scientist, I did not know until I saw the tweets that Tom was the winner of the 2022 President’s Award from the American Society of Primatologists (congratulations Tom!).
I started my interview with Dr. Struhsaker as one typically would – by asking him to tell me about himself and his field of research. He laughs and says “Oh boy, where to begin? You’re talking half a century here.” I could listen to Tom talk for hours about his experiences as a young field biologist at a time when primatology was just figuring itself out. Tom went about his work as a naturalist – do not interfere, observe and learn. He spent 25 years in Africa (spanning 56 years from 1962-2018), observing many different species of animals, not just primates. For 18 of these 25 years Tom lived in Uganda as a full-time resident, including during the reign of Idi Amin, one of the most brutal rulers in modern history. Idi Amin aside, Tom thought that the Ugandans were some of the best folks to work with regarding conservation in Africa due to their dedication to higher education (Makerere University) with growing generations of students and the establishment of Kibale National Park. I cannot do Tom’s fascinating life justice in just this short blog post, so I encourage you to read Tom’s 2022 article, The life of a naturalist (full text access available through NetID login) and his memoir, I remember Africa: A field biologist’s half-century perspective (Perkins & Bostock Library – Duke Authors Display – QH31.S79 A3 2021). What I can tell you, at least from my perspective, is that Tom has led a life passionate about nature, wanting to know everything he could from our cohabiters on this planet and how we can best live together. If you would like your own copy it can be purchased here.
Tom recorded these vocalizations between 1969-1992. He thought it was really important to do so because they are key to understanding communication and the social life of primates. Analysis of these recordings led Tom to conclude that among African monkeys vocalizations are relatively stable characters from an evolutionary perspective and, therefore, important in understanding phylogenetic relationships. As for archiving and sharing the recordings of these vocalizations, Tom didn’t initially have that in mind. He instead followed the more traditional academic route of publishing articles including spectrograms, and his conclusions about the meaning of the vocalizations. Over the last two years as Tom began thinking about the legacy of his materials, he realized that while the visual representations are useful to share for analysis, it is just not the same as listening to the sounds themselves. Why not archive them to make it possible for others to hear them?
“He realized that while the visual representations are useful to share for analysis, it is just not the same as listening to the sounds themselves. Why not archive them to make it possible for others to hear them?”
With increasing human populations, deforestation, climate changes, etc., some of these animals (like the Red Colobus) have become critically endangered, and these recordings might be the only way future generations will ever be able to hear these animals. Tom’s recordings were made using reel to reel tapes on very large and heavy tape recorders with 12 D-Cell batteries. Crawling through the forest with these machines in addition to a large boom microphone was no easy feat. With the help of the Macaulay Library (Mr. Matthew Medler in particular), several of the original tapes were digitized to the high-quality WAV files we have in the collection. Tom has also augmented the collection with his own MP3 recordings. He hopes to have more WAV format from Macaulay Library in the future.
Tom did not initially know where to archive these vocalizations as they weren’t in scope for MorphoSource (another Duke-based repository for 3D imaging) where Tom will soon have a collection of red colobus monkey images available. Thanks to a suggestion from his neighbor Ben Donnelly, he reached out to the Duke Research Data Repository Curation Team (thanks for being a great colleague Ben!). This is where I (Jen Darragh), the author, come in.
Tom and I worked together over the course of a couple months to build his data deposit. Perhaps somewhat self-servingly, I asked him how he found the process. He stoked my ego with both a “fantastic, and easy peasy.” He said he would recommend us to anyone as we do our best to make the process as clear and pain-free as possible. Aw shucks Tom. You are one of my favorite depositors to work with, too.
I asked Tom what would he advise for early career researchers and those just getting started in the field when it comes to data sharing and archiving. He said that he is seeing increasing requirements as part of publishing (he’s right) and he’s in favor, as long as the person who collected the data is credited (cite properly!) and consulted when possible (collaboration is good). It’s important to advance the sciences. Repositories help to encourage good citation practices in addition to the preservation of important data for the long-term.
CC-BY Thomas Struhsaker. Medium-large juvenile red colobus (eating bark of bottle brush tree, Kanyawara, Kibale National Park, Uganda.
Tom also mentioned some longitudinal data he had collaborative built over the years with colleagues and that continues to be built upon. His experience of archiving his vocalization recordings with us (and his images with MorphoSource) got him thinking that repositories are a wonderful option to ensure that these important materials continue to persist and be used. He has thought of at least three important datasets and plans to reach out to his collaborators about archiving these data either with us in the Duke RDR, or in another formal repository of their choosing.
Tom recently shared with me a collection of photographs that he has taken in the same spot in Kibale from 1976-2018 that shows how the area went from bare grassland to a low stature forest (pre-conservation to post-conservation efforts). He has shared these with his colleagues directly to show the fascinating change over time. He now hopes to share them more broadly through the Duke RDR (forthcoming, we have some processing to do). Perhaps someone will be inspired to animate the images and then share back with us.
To close the interview, I asked Tom what his favorite animal was. I think it’s no surprise that he likes them all; there are so many he likes for different reasons, some subtle, some not (“some insects are damn weird”) and some just do incredibly interesting things. The diversity is what he loves.
Struhsaker, T. T. (2022). Digitized tape recordings of Red colobus and other African forest monkey species vocalizations. Duke Research Data Repository. https://doi.org/10.7924/r4pv6nm9f
You’re probably aware that voting in the United States is managed in a very decentralized manner compared to most other countries. There are limited sources that comprehensively compile local-level results or geographic data showing local voting precincts. We’ll discuss several selected projects have come about to try to pull all this data together to provide one-stop repositories, as well as state and local sources for election data. Some of these are free resources, and some are licensed by us for the use of Duke affiliates.
Election Returns
The Princeton University Library has an excellent guide to elections returns and related data in their Elections and Voting Data Guide: United States (U.S.) and International, compiled by their Politics Librarian, Jeremy Darrington. This is a good first place to look for repositories of voting data, both U.S. and international. We’ll discuss a few of the most useful of these sources that the Duke community has access to.
The CQ Voting and Elections Collection (Duke users only) has results data on Presidential, Congressional, and gubernatorial elections, some back to the 19th century. Results are generally given down to the county level of detail.
Polidata presents presidential election result data by congressional district and county in STATA, Excel, or CSV format, with data dictionaries as text files and documentation in PDF format. The Duke Libraries has obtained some of their data, curating the 1992-2008 District-level Polidata.
Geographic Data (GIS Layers)
Geographies that relate specifically to election data are Congressional or Legislative Districts, as well as voting precincts. The Census Bureau’s Voting Tabulation District (VTD) boundaries closely parallel precincts but are based on the Census Block geographies. They may not exactly match all locally created precincts, but may be all you can get electronically.
NHGIS (National Historical GIS) has the most election-related GIS boundary files, back to 1990 for VTDs, to 2000 for state legislative districts, and into the late 1980s for U.S. Congressional Districts. The Census Bureau has a scattered collection of these as well, at least for more recent years, usually on a state-by-state- or county-by-county (for the VTDs) basis. See either their web interface or their FTP site.
Election Results and GIS layers Together
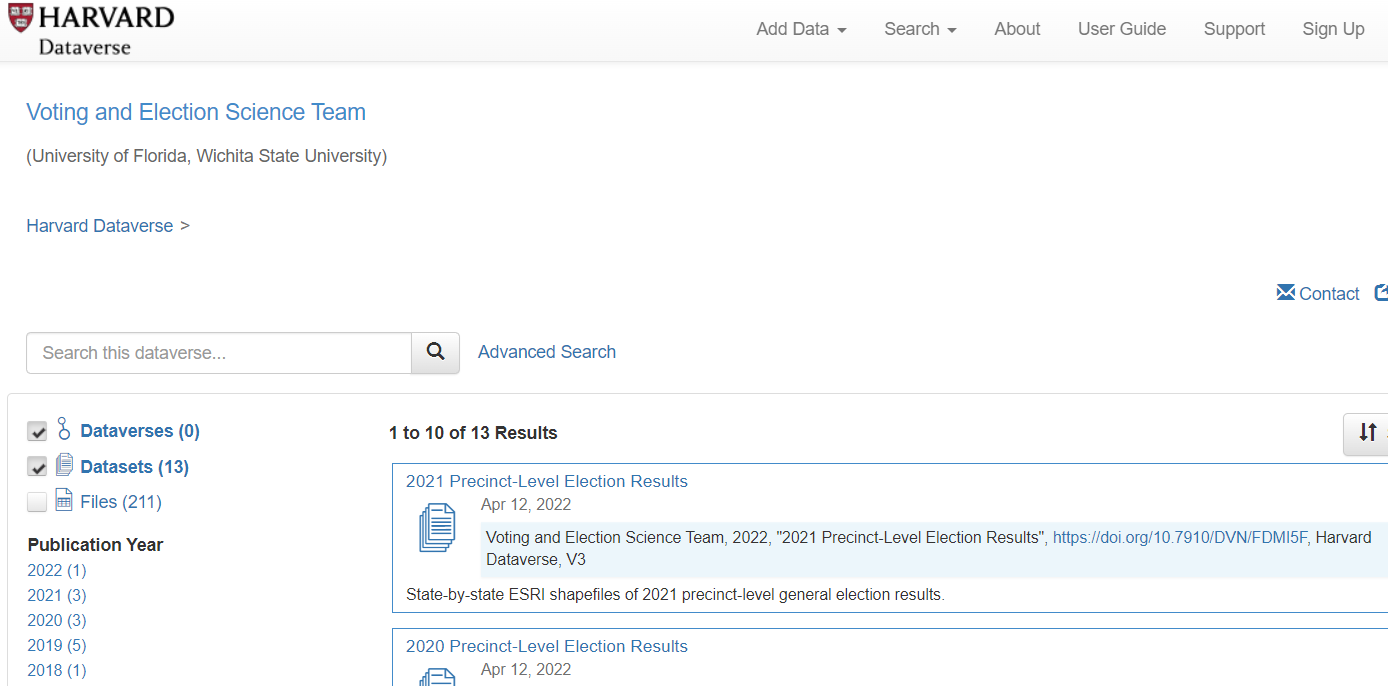
A good all-in-one source is The United States Elections Project, with lead contributors from the Voting and Election Science Team at the University of Florida and Wichita State University. It includes both election results and GIS shapefiles down to the precinct level, mostly from the last decade (as recently as some 2021 elections). For those interested in redistricting issues and gerrymandering, precinct-level data is essential.
Their data is stored in the Harvard Dataverse, a data publishing platform that includes several election-related projects (election results and sometimes GIS files). It is a rich, if somewhat scattershot, repository with a lot of hidden gems. You can use the Advanced Search interface to find some of these datasets.
State and Local Sources
Sometimes, you need to find state, county, and city sources for election data, either for local elections or for geographically granular data results, like voting precincts. The National Association of Secretaries of State (NASS) website indexes the Secretaries of State websites, which may or may not have actual election results data.
The state elections offices may only have information on registration and on voting locations, but sometimes may include results data. For instance, the North Carolina State Board of Elections has some pretty thorough data at the precinct level for recent years, with good documentation.
Some local governments are good about releasing election data at the precinct level. They may include data for such elections as municipal offices, school districts, and bond initiatives that you’d probably never find compiled at a national site. This example is from Los Angeles County.
Tools
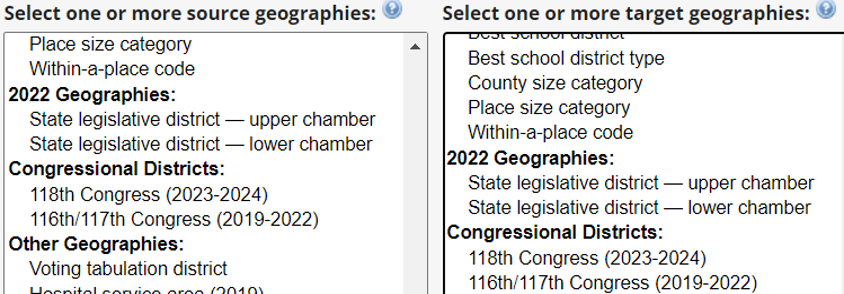
If you need statistical or GIS tools to analyze the data, be sure to contact us at askdata@duke.edu for advice. Here, I’ll mention the Geocorr utility at the Missouri Census Data Center, which you can use to reaggregate data into different geographic areas. You can create correspondence tables between geographies such as voting tabulation districts or legislative districts and Census geographies, say, if you need to analyze demographics and socioeconomic factors. The correspondence tables include weighting factors indicating the percent of one area within another.
We’ve only scratched the surface on the data sources related to U.S. elections. If you want more suggestions or have specialized needs not covered here, please contact us at askdata@duke.edu for other ideas.
This post is part of the Duke Research Data Curation Team’s ‘Researcher Highlight’ series.
In the field of engineering, a key driving motivator is the urge to solve problems and provide tools to the community to address those problems. For Dr. Mark Palmeri, Professor in Biomedical Engineering at Duke University, open research practices support the ultimate goals of this work, and helps get the data into the hands of those solving problems: “It’s one thing to get a publication out there and see it get cited. It’s totally another thing to see people you have no direct professional connection to accessing the data and see it impacting something they’re doing…”
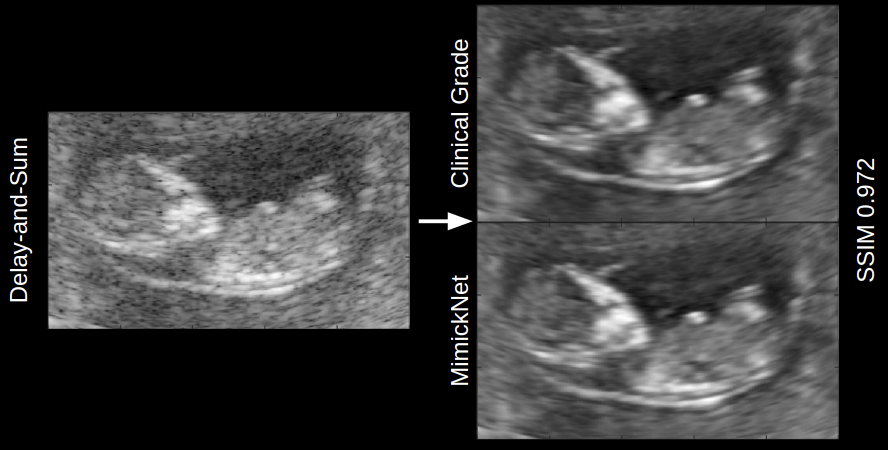
Dr. Palmeri’s research focuses on medical ultrasonic imaging, specifically using acoustic radiation force imaging to characterize the stiffness of tissues. His code and data allow other researchers to calibrate and validate processing protocols, and facilitate training of deep learning algorithms. He recently sat down with the Duke Research Data Repository Curation Team to discuss his thoughts on open science and data publishing.
“It’s one thing to get a publication out there and see it get cited. It’s totally another thing to see people you have no direct professional connection to accessing the data and see it impacting something they’re doing…”
With the new NIH data management and sharing policy on the horizon, many researchers are now considering what sharing data looks like for their own work. Palmeri highlighted some common challenges that many researchers will face, such as the inability to share proprietary data when working with industry partners, de-identifying data for public use (and who actually signs off on this process), the growing scope and scale of data in the digital age, and investing the necessary time to prepare data for public consumption. However, two of his biggest challenges relate to the changing pace of technology and the lack of data standards.
When publishing a dataset, you necessarily have a static version of the dataset established in space and time via a persistent identifier (i.e., DOI); however, Palmeri’s code and software outputs are constantly evolving as are the underlying computational environments. This mismatch can result in datasets becoming out of sync with the coding tools, thereby affecting future reuse and ultimately keeping things up-to-date takes time and effort. As Palmeri notes, in the fast-paced culture of academia “no one has time to keep old project data up to snuff.”
Likewise, while certain types of data in medical imaging have standardized formats (e.g., DICOM), for the images Palmeri is creating from raw signal data there are no ubiquitous standards. This creates problems for data reuse. Palmeri remarks that “There’s no data model that exists to say what metadata should be provided, in what units, what major fields and subfields, so that becomes a major strain on the ability to meaningfully share the data, because if someone can’t open it up and know how to parse it and unwrap it and categorize it, you’re sharing gigabytes of bits that don’t really help anyone.” Currently, Dr. Palmeri is working with the Quantitative Imaging Biomarkers Alliance and the International Electrotechnical Commision (IEC) TC87 (Ultrasonics) WG9 (Shear Wave Elastography) to create a public standard for this technology for clinical use.
Regardless of these challenges, Palmeri sees many benefits to publicly sharing data including enhancing “our internal rigor even just that little bit more” as well as opening “new doors of opportunity for new research questions…and then the scope and impact of the work can be augmented.” Dr. Palmeri appreciates the infrastructure provided by the Duke University Libraries to host his data in a centralized and distributed network as well as the ability to cite his data via the DOI. As he notes “you don’t want to just put up something on Box as those services can change year to year and don’t provide a really good preserved resource.” Beyond the infrastructure, he appreciates how the curation team provides “an objective third party [to] look at things and evaluate how shareable is this.”
“you don’t want to just put up something on Box as those services can change year to year and don’t provide a really good preserved resource.”
Within the Duke Research Data Repository, we have a mission to help Duke researchers make their data accessible to enable reproducibility and reuse. Working with researchers, like Dr. Palmeri, to realize a future where open research practices lead to a greater impact for researchers and democratizes knowledge is a core driving motivator. Contact us (datamanagement@duke.edu) with any questions you might have about starting your own data sharing adventure!