Need held curating your data or identifying a repository to share data? Helenmary can help!
CDVS welcomes Helenmary Sheridan as the third member of the research data management (RDM) team. Helenmary joined Duke in August 2024 to help the library scale up classes, group trainings, and individualized consultations on RDM topics including NIH data management plans, data sharing in repositories such as the Duke Research Data Repository, and improving research reproducibility through documentation. Her position is supported by the Compute and Data Services Alliance for Research (CDSA), a new cross-campus initiative to support researchers with their computational needs.
Prior to joining Duke, Helenmary was the Data Services Librarian at the health sciences library at the University of Pittsburgh, where she provided data management training to faculty, staff, and students across the health disciplines. She has nearly ten years of experience working with scientific metadata and file formats, especially for data from imaging research (biomedical and otherwise.)
Helenmary’s favorite part of her job is teaching, especially Introduction to Research Data Management workshops for new graduate students and faculty that may be their first formal experience with research data methods. “It sounds like a dry subject,” she says, “so I love to see how excited researchers get when they realize how much easier these tools can make their lives.” You can contact Helenmary through the CDVS inbox at: askdata@duke.edu.
Since the summer of 2018 I have been working with a set of nineteenth-century commercial almanacs for the city of Paris. As my dissertation focused heavily on the production of stone funerary markers during this period, I wanted to consult these almanacs to get a sense of how many workers were active in this field of production. Classified as marbriers (stonecutters), the makers of funerary monuments were often one in the same as those who executed various other stone goods and constructions. These almanacs represented a tremendous source of industry information, consistently recording enterprise names and addresses, as well as, at times, specific information about the types of products the enterprise specialized in and any awards they might have won for their work, and what types of new technologies they employed. An so I decided to make a database.
As a Humanities Unbounded graduate assistant with the Center for Data and Visualization Sciences during the summer of 2020, I had the opportunity to explore some of the issues related to database construction and management faced by humanists working on data-based research projects. In order to work out some of these issues, I worked to set up a MySQL database using my commercial almanacs data as a test case to determine which platforms and methods for creating queryable databases would be best suited for those working primarily in the humanities. In the process of setting up this database what became increasingly clear was the need to make clear the usefulness of this process for other humanists undertaking data-driven projects, as well as identify ways of transforming single spreadsheets of data into relational data models without needing to know how to code. Thus, in this blog post I offer a few key points about relational database models that may be useful for scholars in the humanities and share my experiences in constructing a MySQL database from a single Excel spreadsheet.
First of all, some key terms and concepts. MySQL is an open-source relational database management system that uses SQL (Structured Query Language) to create, modify, manage and extract data from a relational database. A relational data model organizes data into a series of tables containing columns (‘attributes’) and rows (‘records’) with unique keys identifying each record. Each table (or, ‘relation’) represents a single entity type and its corresponding attributes. When working with a relational data model you want to make sure that your tables are normalized, or organized in such a way that reduces redundancy in the data set, increases consistency, and facilitates querying.
Although for the purposes of efficient data gathering, I had initially collected all of the information from the commercial almanacs in a single Excel spreadsheet, I knew that I ultimately wanted to reconfigure my data using a relational model that could be shared with and queried efficiently by others. The main benefits of a relational model include ensuring consistency as well as performing combinations of queries to understand various relationships that exist among the information contained in the various tables that would be otherwise difficult to determine from a single spreadsheet. An additional benefit to this system is the ability to add records and edit information without the risk of compromising other information contained in the database.
The first question I needed to ask myself was which entities from my original spreadsheet would become the basis for my relational database. In other words, how would my relational model be organized? What different relationships existed within the dataset, and which variables functioned as entities rather than attributes? One of the key factors in determining which variables would become the entities of my relational model, was the question of whether or not a given variable contained repeated values throughout the master sheet. Ultimately determining the entities wasn’t the trickiest part. It because rather clear early on that it would be best to first create separate tables for businesses and business locations, which would be related via a table for annual activity (in the process of splitting my tables I would end up making more tables, but these were the key starting points).
The most difficult question I encountered was how I would go about splitting all this information as someone with very limited coding experience. How could identify unique values and populate tables with relevant attributes without having to teach myself Python in a pinch, but also without having to retype over one hundred years’ worth of business records? Ultimately, I came up with a rather convoluted system that had me going back and forth between OpenRefine and Excel. Once I got the hang of my system it became almost second nature to me but explaining it to others was another story. This made it abundantly clear that there was a lack of resources for demonstrating how one could create what were essentially a series of normalized tables from a flat data model. So, to make a very long story short, I broke down my convoluted process into a series of simple steps that required nothing more that Excel to transform a flat data model into a relational data model using the UNIQUE() and VLOOKUP() functions. This processes is detailed in a library tutorial I developed geared towards humanists, consisting of both a video demonstrating the process and a PDF containing written instructions.
In the end, all I needed to do was construct the database itself. In order to do this I worked with phpMyAdmin, a free web-based user interface for constructing and querying MySQL databases. Using phpMyAdmin, I was able to easily upload my normalized data tables, manage and query my database, and easily connect to Tableau for data visualization purposes using phpMyAdmin’s user management capabilities.
Dr. Kaylee P. Alexander is a graduate of the Department of Art, Art History & Visual Studies, where she was also a research assistant with the Duke Art, Law & Markets Initiative (DALMI). Her dissertation research focuses on the visual culture of the cemetery and the market for funerary monuments in nineteenth-century Paris. In the summer of 2020, she served as a Humanities Unbounded graduate assistant with the Center for Data and Visualization Sciences at Duke University Libraries.
Felipe Álvarez de Toledo López-Herrera is a Ph.D. candidate in the Art, Art History, and Visual Studies Department at Duke University and a Digital Humanities Graduate Assistant for Humanities Unbounded, 2019-2020. Contact him at askdata@duke.edu.
[This blogpost introduces a GitHub Repository that provides resources for developing NER projects in historical languages. Please do not hesitate to use the code and ideas made available there, or contact me if there are any issues we could discuss .]
Understanding Historical Art Markets: an Automated Approach
When the Sevillian painters’ guild archive was lost in the 19th century, with it vanished lists of master painters, journeymen, apprentices and possibly dealers recorded in the guilds’ registration books. Nevertheless, researchers working for over a century in other Sevillian archives have published almost twenty volumes of archival documents. These transcriptions, excerpts and summaries reflect the activities of local painters, sculptors, and architects, among other artisans. I use this evidence as a source of data on early modern Seville’s art market in my dissertation research. For this, I have to extract information from many documents in order to query and discern larger patterns.
Left. Some of the volumes used in this research, in my home library. I have managed to acquire these second-hand; others I have borrowed from libraries. Right. A scan of one of the pages of these books, showing some of the documents from which we extracted data.
Instead of manually keying this information into a spreadsheet or other form of data storage, I chose to scan my sources and test an automated approach using Natural Language Processing. Last semester, within the context of the Humanities Unbounded Digital Humanities Graduate Assistantship, I worked with Named-Entity Recognition (NER), a technique in which computers can be taught to identify named real-world objects in texts. NER models underperform on historical texts because they are trained on modern documents such as news or Wikipedia articles. Furthermore, NLP developers have focused most of their efforts on English language models, resulting in underdeveloped models for other languages. For these reasons, I had to retrain a model to be useful for my purposes. In this blogpost, I give an overview of the process of adapting NER tools for use on non-English historical sources.
Defining Named-Entity Recognition
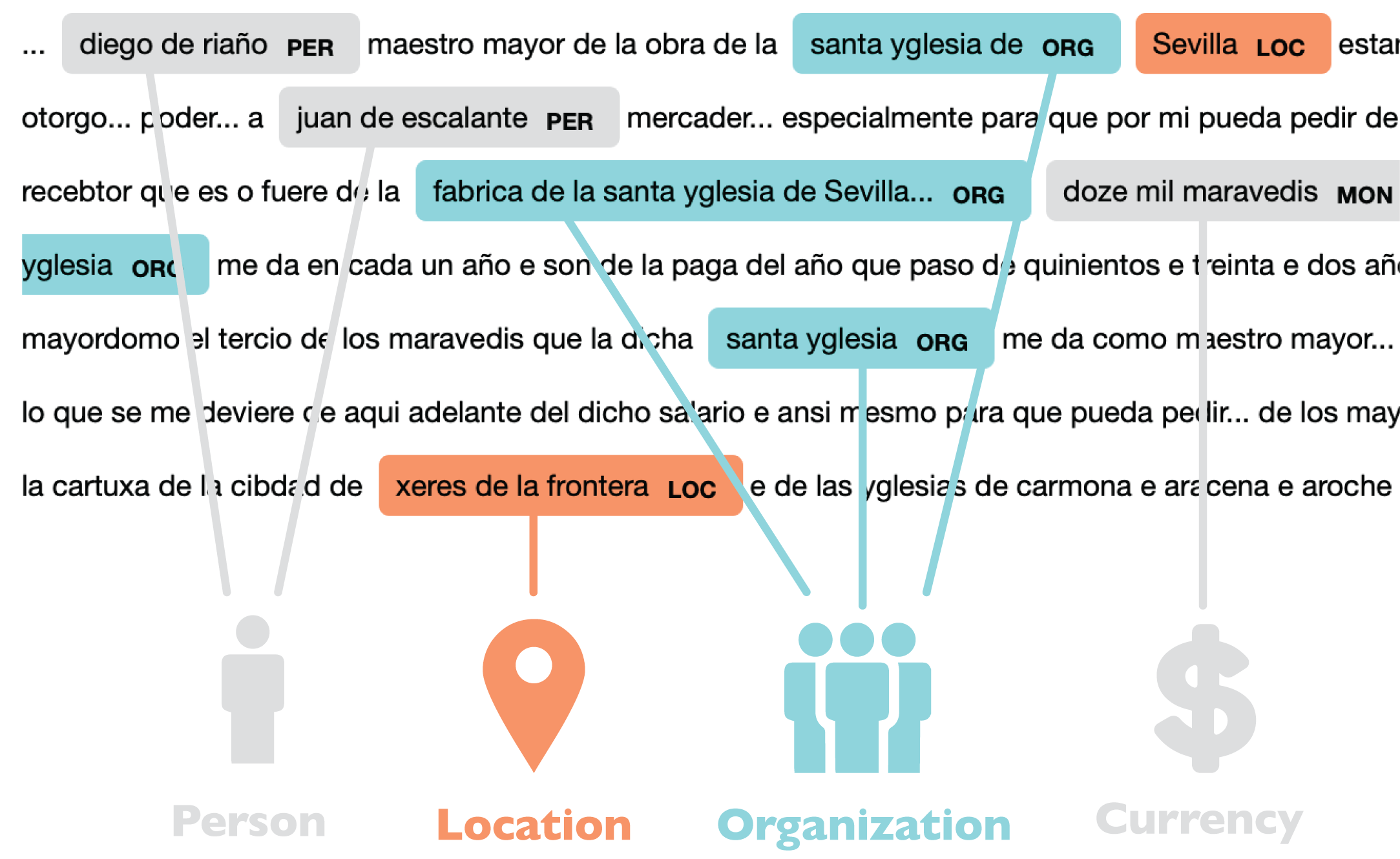
Named-Entity Recognition (NER) is a set of processes in which a computer program is trained to identify and categorize real-world objects with proper names in a corpus of texts. It can be used to tag names in documents without a standardized structure and label them as people, locations or organizations, among other categories.
Named-entity recognition is the automated tagging of real-world objects with names, such as people, locations, organizations, or monetary amounts, within texts.
Code libraries such as Spacy, NLTK or Stanford CoreNLP provide widely-tested toolkits for NER. I decided that Spacy would be the best choice for my purposes. Though its Spanish model included less label categories, they performed better out-of-the-box. Importantly, the model worked better for certain basic language structures such as recognizing compound names (last names with several components, such as my own). The Spacy library also proved user-friendly for those of us with little coding knowledge. Its pre-programmed data processing pipeline is easy to modify, given that you have a basic understanding of Python. In my case, I had the time and motivation to acquire this literacy.
I sought to improve the model’s performance in two ways. First, I retrained it on a subset of my own data. This improved performance and allowed me to add new label categories such as dates, monetary amounts and objects. Additionally, I added a component that modernized my texts’ spelling to make them more conducive to proper tagging.
Training NER on Historical Spanish Text: Process and Results
To improve the model, I needed training data – a “gold standard” of perfectly-tagged text. First, I ran the model on a set of 400 documents, which resulted in a set of preliminary tags. Then, I corrected these tags with a tool called Dataturks and reformatted the output to work with Spacy. Once this data was ready, I split it 80-20, which means running a training loop on 80% of correctly-tagged texts to adjust the performance of the model, and reserving 20% for testing or evaluating the model on data it had not yet seen.
Final output as stored in my database for one particular document with ID=5.
Finally, I evaluated whether all these changes actually improved the model’s performance, saved the updated model, and exported the output in a format that worked for my own database. For my texts, the model initially worked at around 36% recall (the percentage of true entities that were identified by the model), compared to an 89% recall with modern texts as evaluated by Spacy. After training, recall has increased to 64%. Some tags, such as person or location, perform especially well (85% and 81%, respectively). Though the numbers are not perfect, they show a marked improvement, generated with little training data.
For the 8,607 documents processed, the process has resulted in 59,191 tags referring to people, locations, organizations, dates, objects and money. Next steps include finding descriptors of entities within the text, and modeling relationships between entities appearing in the same document. For now, a look at the detected tags underscores the potential of NER for automating data collection in data-driven humanities research.
Felipe Álvarez de Toledo López-Herrera is a Ph.D. candidate at the Art, Art History, and Visual Studies Department at Duke University and a Digital Humanities Graduate Assistant for Humanities Unbounded, 2019-2020. Contact him at askdata@duke.edu.
Over the 2019-2020 academic year, I am serving as a Humanities Unbounded graduate assistant in Duke Libraries’ Center for Data and Visualization Sciences. As one of the three Humanities Unbounded graduate assistants, I will partner on Humanities Unbounded projects and focus on developing skills that are broadly applicable to support humanities projects at Duke. In this blog post, I would like to introduce myself and give readers a sense of my skills and interests. If you think my profile could address some of the needs of your group, please reach out to me through the email above!
My own dissertation project began with a data dilemma. 400 years ago, paintings were shipped across the Atlantic by the thousands. They were sent by painters and dealers in places like Antwerp or Seville, for sale in the Spanish colonies. But most of these paintings were not made to last. Cheap supports and shifting fashions guaranteed a constant renewal of demand, and thus more work for painters, in a sort of proto-industrial planned obsolescence.[1]As a consequence, the canvas, the traditional data point of art history, was not a viable starting point for my own research, rendering powerless many of the tools that art history has developed for studying painting. I was interested in examining the market for paintings as it developed in Seville, Spain from 1500-1700; it was a major productive center which held the idiosyncratic role of controlling all trade to the Spanish colonies for more than 200 years. But what could I do when most of the work produced within it no longer exists?
This problem drives my research here at Duke, where I apply an interdisciplinary, data-driven approach. My own background is the product of two fields: I obtained a bachelor’s degree in Economics in my hometown of Barcelona, Spain in 2015 from the Universitat Pompeu Fabra, and simultaneously attended art history classes in the University of Barcelona. This combination found a natural mid-way point in the study of art markets. I came to Duke to be a part of DALMI, the Duke, Art, Law and Markets Initiative, led by Professor Hans J. Van Miegroet, where I was introduced to the methodologies of data-driven art historical research.
Documents in Seville’s archives reveal a stunning diversity of production that encompasses the religious art for which the city is known, but also includes still lives, landscapes and genre scenes whose importance has been understated and of which few examples remain [Figures 1 & 2]. But analysis of individual documents, or small groups of them, yields limited information. Aggregation, with an awareness of the biases and limitations in the existing corpus of documents, seems to me a way to open up alternative avenues for research. I am creating a database of painters in the city of Seville from 1500-1699, where I pool known archival documentation relating to painters and painting in this city and extract biographical, spatial and productive data to analyze the industry. I explore issues such as the industry’s size and productive capacity, its organization within the city, reactions to historical change and, of course, its participation in transatlantic trade.
This approach has obliged me to become familiar with a wide range of digital tools. I use OpenRefine for cleaning data, R and Stata for statistical analysis, Tableau for creating visualizations and ArcGIS for visualizing and generating spatial data (see examples of my own work below [Figures 3-4]). I have also learned the theory behind relational databases and am learning to use MySQL for my own project; similarly, for the data-gathering process I am interested in learning data-mining techniques through machine learning. I have been using a user-friendly software called RapidMiner to simplify some of my own data gathering.
A rare example of a Sevillian landscape. Ignacio de Iriarte, Landscape with Shepherds (1665)
Another example of Sevillian genre production. Francisco de Zurbarán, Still Life with Lemons, Oranges and a Rose (1633)
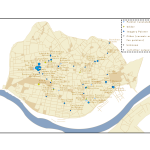
Map of painter addresses, 1676. Size represents the number of apprentices they held in that year.
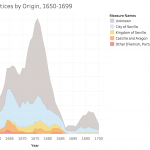
Number of apprentices in Seville by place of origin, 1650-1699. Based on documents in Duncan T. Kinkead, Pintores y Doradores en Sevilla, 1650-1699: Documentos (2007).
Thus, I am happy to help any groups that have a data set and want to learn how to visualize it graphically, whether through graphs, charts or maps. I am also happy to help groups think about their data gathering and storage. I like to consider data in the broadest terms: almost anything can be data, if we correctly conceptualize how to gather and utilize it realistically within the limits of a project. I would like to point out that this does not necessarily need to result in visualization; this is also applicable if a group has a corpus of documents that they want to store digitally. If any groups have an interest in text mining and relational databases, we can learn simultaneously—I am very interested in developing these skills myself because they apply to my own project.
I can:
Help you consider potential data sources and the best way to extract the information they contain
Help you make them usable: teach you to structure, store and clean your data
And of course, help you analyze and visualize them
With Tableau: for graphs and infographics that can be interactive and can easily be embedded into dashboards on websites.
With ArcGIS: for maps that can also be interactive and embedded onto websites or in their Stories function.
Help you plan your project through these steps, from gathering to visualization.
Once again, if you think any of these areas are useful to you and your project, please do not hesitate to contact me. I look forward to collaborating with you!