Data management and sharing policies are seeing some changes in 2026 and the CDVS Data Management team is here to help you!
NIH
On February 25, 2026, the NIH released NOT-OD-26-046 announcing a new abbreviated Data Management and Sharing Plan (DMSP) format. The updated format is intended to reduce applicant burden and support more consistent compliance monitoring by changing narrative responses primarily to yes/no answers. Beginning May 25, 2026, applicants will be required to use this new, shorter, standardized format.
The revised DMSP focuses on a concise set of required elements:
Three yes/no questions addressing whether the scientific data will be shared and associated timelines/retention information.
A brief explanation (up to 300 words) if data sharing is limited for ethical, legal, or technical reasons.
All data supporting NSF funded manuscripts will be expected to be shared at the time of manuscript publication
Exceptions to data sharing must be specifically requested
The DMSP is a record of intended data sharing and becomes a terms and condition of the award
The new DMSP will be a structured survey in Research.gov with questions focusing upon Data and Research Products, Access Policies and Limitations, Data Standards and Metadata, Public Archiving in Repositories, Retention Times, Data Sources, and Accountability/Responsibility. (Note: This survey tool in Research.gov is not yet live, it is supposed to be launched on April 27, 2026 and may be subject to change)
Tips
While these new formats may require less effort to complete, the primary intention – ensuring maximum sharing of publicly funded data – remains the same. Here are just a few things you can do to be prepared to share your data:
Identify an appropriate data repository/ies as early as possible because they have differing levels of complexity around submission requirements, data preparation and format expectations (including de-identification), and long-term storage costs that affect your budget and publishing data on time. If you are trying to identify a repository, one option might be the Duke Research Data Repository.
Accurately budget for the costs of data management including preparation for archiving data in repositories
When sharing data from human participants, make sure your informed consent allows for data sharing explicitly (see the DUHS IRB data sharing example language)
Train graduate students and other project personnel on procudures for curating and preparing for data sharing early in the project.
If you need help navigating these new funder policies, identifying appropriate data sharing options, or developing data management practices for your team, contact us at datamanagement@duke.edu.
Need held curating your data or identifying a repository to share data? Helenmary can help!
CDVS welcomes Helenmary Sheridan as the third member of the research data management (RDM) team. Helenmary joined Duke in August 2024 to help the library scale up classes, group trainings, and individualized consultations on RDM topics including NIH data management plans, data sharing in repositories such as the Duke Research Data Repository, and improving research reproducibility through documentation. Her position is supported by the Compute and Data Services Alliance for Research (CDSA), a new cross-campus initiative to support researchers with their computational needs.
Prior to joining Duke, Helenmary was the Data Services Librarian at the health sciences library at the University of Pittsburgh, where she provided data management training to faculty, staff, and students across the health disciplines. She has nearly ten years of experience working with scientific metadata and file formats, especially for data from imaging research (biomedical and otherwise.)
Helenmary’s favorite part of her job is teaching, especially Introduction to Research Data Management workshops for new graduate students and faculty that may be their first formal experience with research data methods. “It sounds like a dry subject,” she says, “so I love to see how excited researchers get when they realize how much easier these tools can make their lives.” You can contact Helenmary through the CDVS inbox at: askdata@duke.edu.
This post is part of the Duke Research Data Curation Team’s ‘Researcher Highlight’ series.
In the field of engineering, a key driving motivator is the urge to solve problems and provide tools to the community to address those problems. For Dr. Mark Palmeri, Professor in Biomedical Engineering at Duke University, open research practices support the ultimate goals of this work, and helps get the data into the hands of those solving problems: “It’s one thing to get a publication out there and see it get cited. It’s totally another thing to see people you have no direct professional connection to accessing the data and see it impacting something they’re doing…”
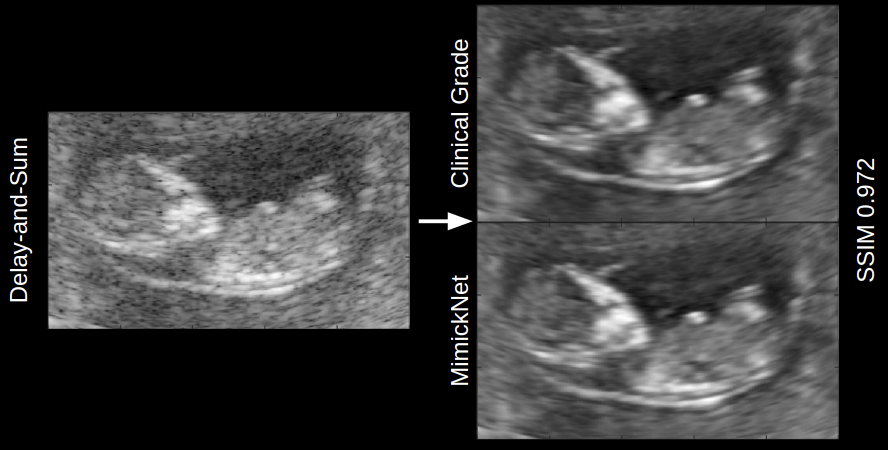
Dr. Palmeri’s research focuses on medical ultrasonic imaging, specifically using acoustic radiation force imaging to characterize the stiffness of tissues. His code and data allow other researchers to calibrate and validate processing protocols, and facilitate training of deep learning algorithms. He recently sat down with the Duke Research Data Repository Curation Team to discuss his thoughts on open science and data publishing.
“It’s one thing to get a publication out there and see it get cited. It’s totally another thing to see people you have no direct professional connection to accessing the data and see it impacting something they’re doing…”
With the new NIH data management and sharing policy on the horizon, many researchers are now considering what sharing data looks like for their own work. Palmeri highlighted some common challenges that many researchers will face, such as the inability to share proprietary data when working with industry partners, de-identifying data for public use (and who actually signs off on this process), the growing scope and scale of data in the digital age, and investing the necessary time to prepare data for public consumption. However, two of his biggest challenges relate to the changing pace of technology and the lack of data standards.
When publishing a dataset, you necessarily have a static version of the dataset established in space and time via a persistent identifier (i.e., DOI); however, Palmeri’s code and software outputs are constantly evolving as are the underlying computational environments. This mismatch can result in datasets becoming out of sync with the coding tools, thereby affecting future reuse and ultimately keeping things up-to-date takes time and effort. As Palmeri notes, in the fast-paced culture of academia “no one has time to keep old project data up to snuff.”
Likewise, while certain types of data in medical imaging have standardized formats (e.g., DICOM), for the images Palmeri is creating from raw signal data there are no ubiquitous standards. This creates problems for data reuse. Palmeri remarks that “There’s no data model that exists to say what metadata should be provided, in what units, what major fields and subfields, so that becomes a major strain on the ability to meaningfully share the data, because if someone can’t open it up and know how to parse it and unwrap it and categorize it, you’re sharing gigabytes of bits that don’t really help anyone.” Currently, Dr. Palmeri is working with the Quantitative Imaging Biomarkers Alliance and the International Electrotechnical Commision (IEC) TC87 (Ultrasonics) WG9 (Shear Wave Elastography) to create a public standard for this technology for clinical use.
Regardless of these challenges, Palmeri sees many benefits to publicly sharing data including enhancing “our internal rigor even just that little bit more” as well as opening “new doors of opportunity for new research questions…and then the scope and impact of the work can be augmented.” Dr. Palmeri appreciates the infrastructure provided by the Duke University Libraries to host his data in a centralized and distributed network as well as the ability to cite his data via the DOI. As he notes “you don’t want to just put up something on Box as those services can change year to year and don’t provide a really good preserved resource.” Beyond the infrastructure, he appreciates how the curation team provides “an objective third party [to] look at things and evaluate how shareable is this.”
“you don’t want to just put up something on Box as those services can change year to year and don’t provide a really good preserved resource.”
Within the Duke Research Data Repository, we have a mission to help Duke researchers make their data accessible to enable reproducibility and reuse. Working with researchers, like Dr. Palmeri, to realize a future where open research practices lead to a greater impact for researchers and democratizes knowledge is a core driving motivator. Contact us (datamanagement@duke.edu) with any questions you might have about starting your own data sharing adventure!
Years ago I heard the following quote attributed to Seamus Ross from 2007:
Digital objects do not, in contrast to many of their analog counterparts, respond well to benign neglect.
National Wildlife Property Repository. USFWS Mountain-Prairie. https://flic.kr/p/SYVPBB
Meaning, you cannot simply leave digital files to their bit-rot tendencies while expecting them to be usable in the future. Digital repositories are part of a solution to this problem. But to review, there are many types of repositories, both digital and analog: repositories of bones, insects, plants, books, digital data, etc. Even among the subset of digital repositories there are many types. Some digital repositories keep your data safe for posterity and replication. Some help you manage the distribution of analysis and code. Knowing about these differences will affect not only the ease of your computational workflow, but also the legacy of your published works.
Version-control repositories and their hubs
The most widely known social coding hubs include GitHub, Bitbucket and GitLab. These hubs leverage Git version-control software to track the evolution of project repositories – typically a software or computational analysis project. Importantly, Git and GitHub are not the same thing but they work well together.
GIT Repository. Treviño. https://flic.kr/p/SSras
Version control works by monitoring any designated folder or project directory, making that directory a local repository or repo. Among other benefits, using version control enables “time travel.” Interactions with earlier versions of a project are commonplace. It’s simple to retrieve a deleted paragraph from a report written six months ago. However there are many advanced features as well. For example, unlike common file-syncing tools, it’s easy to recreate an earlier state of an entire project directory and every file from a particular point in time. This feature among others makes Git version-control a handy tool in support of many research workflows and the respective outputs: documents, visualizations, dashboards, slides, analysis, code, software, etc.
Binary. Michael Coghlan. https://flic.kr/p/aYEytM
Git is one of the most popular, open-source, version-control applications; originally developed in 2005 to facilitate the evolution of the world’s most far reaching and successful open-source coding project. Linux is a world-wide collaborative project that spans multiple developers, project managers, natural languages, geographies, and time-zones. While Git can handle large projects, it is extensible and can easily scale up or down to support a wide range of workflows. Additionally, Git is not just for software and code files. Essentially any file on a file system can be monitored with Git: MSWord, PDF files, images, datasets, etc.
There are many ways to share a Git repository and profile your work. The term push refers to a convenient process of synchronizing a repo up to a remote social coding hub. Additional features of a hub include issue tracking, collaboration, hosting documentation, and Kanban Method planning. Conveniently, pushing a repo to GitHub means maintaining a seamless, two-location backup – a push will simultaneously and efficiently synchronize the timeline and file versions. Meanwhile, at a repo editor’s discretion, any collaborator or interested party can be granted access to their GitHub repository.
Many public instances of social-coding hubs operate on a freemium model. At GitHub most users pay nothing. It’s also possible to run a local instance of a coding hub. For example, OIT offers a local instance of GitLab, delivering many of the same features while enabling permissions, authorization, and access Via Duke’s NetID.
While social coding hubs are great tools for distributing files and managing project life-cycles, in and of themselves they do not sufficiently ensure long-term reproducible access to research data. To do that simply synchronize version-control repositories with archival research data repositories.
Research Data Repositories
Preserving the computational artifacts of formal academic works requires a repository focus that is complementary to version-control repositories and social-coding hubs. Nonetheless, version control is not a requirement of a data repository where the goal is long-term preservation. Fortunately, many special-purpose data repositories exist. Discipline-specific research repositories are sometimes associated with academic societies. There also exist more generalized archival research repositories such as Zenodo.org. Additionally, many research universities host institutional research data repositories. Not surprisingly, such a research data repository exists at Duke where the Duke University Libraries promotes and cooperatively shepherds Duke’s Research Data Repository (RDR).
Colossus. Chris Monk. https://flic.kr/p/fJssqg
Unlike social coding hubs, data repositories operate under different funding models and are motivated by different horizons. Coding hubs like GitHub do not promise long-term retention, instead they focus on immediate distribution of version-control repos and offer project management features. Research data repositories take a long view centered closer to the artifacts of formal research and publication.
By archiving the data milestones of publication, a deposit in the RDR links a formal publication – book edition, chapter, or serial article, etc. – with the data and code (i.e., a compendium) used to produce a single tangible instance of publication. In turn, the building blocks of computational thinking and research processes are preserved for posterity because the RDR maintains an assurance of long term sustainability.
Bill Atkinson. creator of MacPaint. painted in MacPaint” Photo by Kyra Rehn. https://flic.kr/p/e9urBF
In the Duke RDR, particular effort is focussed on preserving unique versions of data associated with each formal publication. In this way, authors can associate a digital object identifier, or DOI, with the precise code and data used to draft an accepted paper or research project. Once deposited in the RDR, researchers across the globe can look at these archives to verify, to learn, to refute, to cite, or be inspired toward new avenues of investigation.
By preserving workflow artifacts endemic to publication milestones, research data repositories preserve the record of academic progress. Importantly, the preservation of these digital outcomes or artifacts is strongly encouraged by funding agencies. Increasingly, these archival access points are a requirement for funding, especially among publicly funded research. As such, the Duke RDR exists with aims to preserve and make the academic record accessible, and to create a library of reproducible academic research.
Conclusion
The imperatives for preserving research data are derived from expressly different motives than those driving version-control repositories. Minimally, version-control repositories do not promise academic posterity. However, among the drivers of scholarship is the intentional engagement with the preserved academic record. In reality, while unlikely, your GitHub repository could vanish in the blink of the next Wall Street acquisition. Conversely research data repositories exist with different affordances. These two types of repositories complement each other. Once more, they can be synchronized to enable and preserve digital processes that comprise many forms of data-driven research. Using both types of repositories imply workflows that positively contribute to a scholarly legacy. It is this promise of academic transmission that drives Duke’s RDR, and benefits scholars by enabling access to persistent copies of research.
As we begin the new year, the Center of Data and Visualization Sciences is happy to announce a series of twenty-one data workshops designed to empower you to reach your goals in 2022. With a focus on data management, data visualization, and data science, we hope to provide a diverse set of approaches that can save time, increase the impact of your research, and further your career goals.
While the pandemic has shifted most of our data workshops online, we remain keenly interested in offering workshops that reflect the needs and preferences of the Duke research community. In November, we surveyed our 2021 workshop participants to understand how we can better serve our attendees this spring. We’d like to thank those who participated in our brief email survey and share a few of our observations based on the response that we received.
Workshops Formats
While some of our workshops participants (11%) prefer in-person workshops and others (24%) expressed a preference for hybrid workshops, a little over half of the survey respondents (52%) expressed a preference for live zoom workshops. Our goal for the spring is to continue offering “live” zoom sessions while continuing to explore possibilities for increasing the number of hybrid and in-person options. We hope to reevaluate our workshops communities preferences later this year and will continue to adjust formats as appropriate.
52% of respondents prefer online instruction, while another 24% would like to hybrid options
Participant Expectations
With the rapid shift to online content in the last two years coupled with a growing body of online training materials, we are particularly interested in how our workshop attendees evaluate online courses and their expectations for these courses. More specifically, we were curious about whether registering for an online session includes more than simply the expectation of attending the online workshop.
While we are delighted to learn that the majority of our respondents (87%) intend to attend the workshop (our turnout rate has traditionally been about 50%), we learned that a growing number of participants had other expectations (note: for this question, participants could choose more than one response). Roughly sixty-seven percent of the sample indicated they expected to have a recording of the session available. While another sixty-six percent indicated that they expected a copy of the workshop materials (slides, data, code) even if they were unable to attend.
As a result of our survey, CDVS will make an increasing amount of our content available online this spring.. In 2021, we launched a new webpage designed to showcase our learning materials. In addition to our online learning site, CDVS maintains a github site (CDVS) as well as site focused on R learning materials (Rfun).
We appreciate your feedback on the data workshops and look forward to working with you in the upcoming year!
Open access journals have been around forseveral decades, and almost all researchers have read them or published in them by now. Perhaps less well known are trends toward more openness in sharing of data, methods, code, and other aspects of research – broadly called open scholarship. There are lots of good reasons to make your research outputs as open as possible, and increasing support at Duke for doing it.
There are manydifferent variants of “open” – including goals of making research accessible to all, making data and methods transparent to increase reproducibility and trust, licensing research to enable broad re-use, and engagement with a variety of stakeholders, among other things. All of these provide benefits to the public and they also provide benefits to Duke researchers. There’s growing evidence that openly available publications and data result in more citations and greater impact (Colavizza 2020), and showing one’s work and making it available for replication helps build greater trust. There’s greater potential economic impact when others can build on research more quickly, and more avenues for collaboration and interdisciplinary engagement.
Recognizing the importance of making research outputs quickly and openly available to other researchers and the public, and supporting greater transparency in research, many funding agencies are now encouraging or requiring it. NIH has had a public access policy for over a decade, and NSF and other agencies have followed with similar policies. NIH has also released a newData Management and Sharing policythat goes into effect in 2023 with more robust and clearer expectations for how to effectively share data. In Europe, government research funders back a program calledPlan S, and in the United States, the recently passed U.S. Innovation and Competition Act (S. 1260) includes provisions that instruct federal agencies to provide free online public access to federally-funded research “not later than 12 months after publication in peer-reviewed journals, preferably sooner.”
The USICA bill aims to maximize the impact of federally-funded research by ensuring that final author manuscripts reporting on taxpayer-funded research are:
Deposited into federally designated or maintained repositories;
Made available in open and machine-readable formats;
Made available under licenses that enable productive reuse and computational analysis; and
Housed in repositories that ensure interoperability and long-term preservation.
Duke got a head start on supporting researchers in making their publications open access in 2010, when Academic Council adopted an open access policy, which since then has been part of theFaculty Handbook (Appendix P). The policy provides the legal basis for Duke faculty to make their own research articles openly available on a personal or institutional website via a non-exclusive license, while also making it possible to comply with any requirements imposed by their journal or funder. Shortly after the policy was adopted, Duke Libraries worked with the Provost’s office to implement a service making open access easy for Duke researchers. DukeSpace, a repository integrated with theScholars@Duke profile system, allows you to add a publication to your profile and deposit it to Duke’s open access archive in a single step, and have the open access link included in your citations alongside the link to the published version.
Duke Libraries also support aresearch data repository and services to help the Duke community organize, describe, and archive their research data for open access. This service, with support from the Provost’s office, provides both the infrastructure and curation staff to help Duke researchers make their dataFAIR (Findable, Accessible, Interoperable, and Reusable). By publishing datasets with digital object identifiers (DOIs) and data citations, we create a value chain where making data available increases their impact and positions them as standalone research objects. The importance of data sharing specifically is also being formalized at Duke through the currentResearch Data Policy Initiative, which has a stated mission to “facilitate efficient and quality research, ensure data quality, and foster a culture of data sharing.” Together the Duke community is working to develop services, processes, procedures, and policies that broaden our contributions to society through public access to the outputs of our research.
We are happy to announce expanded features for the public sharing of large scale data in the Duke Research Data Repository! The importance of open science for the public good is more relevant than ever and scientific research is increasingly happening at scale. Relatedly, journals and funding agencies are requiring researchers to share the data produced during the course of their research (for instance see the newly released NIH Data Management and Sharing Policy). In response to this growing and evolving data sharing landscape, the Duke Research Data Repository team has partnered with Research Computing and OIT to integrate the Globus file transfer system to streamline the public sharing of large scale data generated at Duke. The new RDR features include:
A streamlined workflow for depositing large scale data to the repository
An integrated process for downloading large scale data (datasets over 2GB) from the repository
New options for exporting smaller datasets directly through your browser
New support for describing and using collections to highlight groups of datasets generated by a project or group (see this example)
Additional free storage (up to 100 GB per deposit) to the Duke community during 2021!
While using Globus for both upload and download requires a few configuration steps by end users, we have strived to simplify this process with new user documentation and video walk-throughs. This is the perfect time to share those large(r) datasets (although smaller datasets are also welcome!).
While the library may be physically closed, the Duke Research Data Repository (RDR) is open and accepting data deposits. If you have a data sharing requirement you need to meet for a journal publisher or funding agency we’ve got you covered. If you have COVID-19 data that can be openly shared, we can help make these vital research materials available to the public and the research community today. Or if you have data that needs to be under access restrictions, we can connect you to partner disciplinary repositories that support clinical trials data, social science data, or qualitative data.
Speaking of the RDR, we just completed a refresh on the platform and added several features!
Image files can now be previewed via a built in Image Viewer
In-line with data sharing standards, we also assign a digital object identifier (DOI) to all datasets, provide structured metadata for discovery, curate data to further enhance datasets for reuse and reproducibility, provide safe archival storage, and a standardized citation for proper acknowledgement.
Openness supports the acceleration of science and the generation of knowledge. Within the libraries we look forward to partnering with Duke researchers to disseminate their research data! Visit https://research.repository.duke.edu/ to learn more or contact datamanagement@duke.edu with any questions.
Duke University Libraries has partnered with the Qualitative Data Repository (QDR) as an institutional member to provide qualitative data sharing, curation, and preservation services to the Duke community. QDR is located at Syracuse University and has staff and infrastructure in place to specifically address some of the unique needs of qualitative data including curating data for future reuse, providing mediated access, and assisting with Data Use Agreements.
Duke University Libraries has long been committed to helping our scholars make their research openly accessible and stewarding these materials for the future. Over the past few years, this has included launching a new data repository and curation program, which accepts data from any discipline as well as joining the Data Curation Network. Now through our partnership with QDR we can further enhance our support for sharing and archiving qualitative data.
Qualitative data come in a variety of forms including interviews, focus groups, archival materials, textual documents, observational data, and some surveys. QDR can help Duke researchers have a broader impact through making these unique data more widely accessible.
“Founded and directed by qualitative researchers, QDR is dedicated to helping researchers share their qualitative data,” says Sebastian Karcher, QDR’s associate director. “Informed by our deep understanding of qualitative research, we help researchers share their data in ways that reflect both their ethical commitments and do justice to the richness and diversity of qualitative research. We couldn’t be more excited to continue our already fruitful partnership with Duke University Libraries”
Through this partnership, Duke University Libraries will have representation on the governance board of QDR and be involved in the latest developments in managing and sharing qualitative data. The libraries will also be partnering with QDR to provide virtual workshops in the spring semester at Duke to enhance understanding around the sharing and management of qualitative research data.
If you are interested in learning more about this partnership, contact datamanagement@duke.edu.
As data driven research has grown at Duke, Data and Visualization Services receives an increasing number of requests for partnerships, instruction, and consultations. These requests have deepened our relationships with researchers across campus such that we now regularly interact with researchers in all of Duke’s schools, disciplines, and interdepartmental initiatives.
In order to expand the Libraries commitment to partnering with researchers on data driven research at Duke, Duke University Libraries is elevating the Data and Visualization Services department to the Center for Data and Visualization Sciences (CDVS). The change is designed to enable the new Center to:
Expand partnerships for research and teaching
Augment the ability of the department to partner on grant, development, and funding opportunities
Develop new opportunities for research, teaching, and collections – especially in the areas of data science, data visualization, and GIS/mapping research
Recognize the breadth and demand for the Libraries expertise in data driven research support
Enhance the role of CDVS activities within Bostock Libraries’ Edge Research Commons
We believe that the new Center for Data and Visualization Sciences will enable us to partner with an increasingly large and diverse range of data research interests at Duke and beyond through funded projects and co-curricular initiatives at Duke. We look forward to working with you on your next data driven project!