
This post is part of the Duke Research Data Curation Team’s ‘Researcher Highlight’ series.
In the field of engineering, a key driving motivator is the urge to solve problems and provide tools to the community to address those problems. For Dr. Mark Palmeri, Professor in Biomedical Engineering at Duke University, open research practices support the ultimate goals of this work, and helps get the data into the hands of those solving problems: “It’s one thing to get a publication out there and see it get cited. It’s totally another thing to see people you have no direct professional connection to accessing the data and see it impacting something they’re doing…”
urge to solve problems and provide tools to the community to address those problems. For Dr. Mark Palmeri, Professor in Biomedical Engineering at Duke University, open research practices support the ultimate goals of this work, and helps get the data into the hands of those solving problems: “It’s one thing to get a publication out there and see it get cited. It’s totally another thing to see people you have no direct professional connection to accessing the data and see it impacting something they’re doing…”
Dr. Palmeri’s research focuses on medical ultrasonic imaging, specifically using acoustic radiation force imaging to characterize the stiffness of tissues. His code and data allow other researchers to calibrate and validate processing protocols, and facilitate training of deep learning algorithms. He recently sat down with the Duke Research Data Repository Curation Team to discuss his thoughts on open science and data publishing.
“It’s one thing to get a publication out there and see it get cited. It’s totally another thing to see people you have no direct professional connection to accessing the data and see it impacting something they’re doing…”
With the new NIH data management and sharing policy on the horizon, many researchers are now considering what sharing data looks like for their own work. Palmeri highlighted some common challenges that many researchers will face, such as the inability to share proprietary data when working with industry partners, de-identifying data for public use (and who actually signs off on this process), the growing scope and scale of data in the digital age, and investing the necessary time to prepare data for public consumption. However, two of his biggest challenges relate to the changing pace of technology and the lack of data standards.
 When publishing a dataset, you necessarily have a static version of the dataset established in space and time via a persistent identifier (i.e., DOI); however, Palmeri’s code and software outputs are constantly evolving as are the underlying computational environments. This mismatch can result in datasets becoming out of sync with the coding tools, thereby affecting future reuse and ultimately keeping things up-to-date takes time and effort. As Palmeri notes, in the fast-paced culture of academia “no one has time to keep old project data up to snuff.”
When publishing a dataset, you necessarily have a static version of the dataset established in space and time via a persistent identifier (i.e., DOI); however, Palmeri’s code and software outputs are constantly evolving as are the underlying computational environments. This mismatch can result in datasets becoming out of sync with the coding tools, thereby affecting future reuse and ultimately keeping things up-to-date takes time and effort. As Palmeri notes, in the fast-paced culture of academia “no one has time to keep old project data up to snuff.”
Likewise, while certain types of data in medical imaging have standardized formats (e.g., DICOM), for the images Palmeri is creating from raw signal data there are no ubiquitous standards. This creates problems for data reuse. Palmeri remarks that “There’s no data model that exists to say what metadata should be provided, in what units, what major fields and subfields, so that becomes a major strain on the ability to meaningfully share the data, because if someone can’t open it up and know how to parse it and unwrap it and categorize it, you’re sharing gigabytes of bits that don’t really help anyone.” Currently, Dr. Palmeri is working with the Quantitative Imaging Biomarkers Alliance and the International Electrotechnical Commision (IEC) TC87 (Ultrasonics) WG9 (Shear Wave Elastography) to create a public standard for this technology for clinical use.
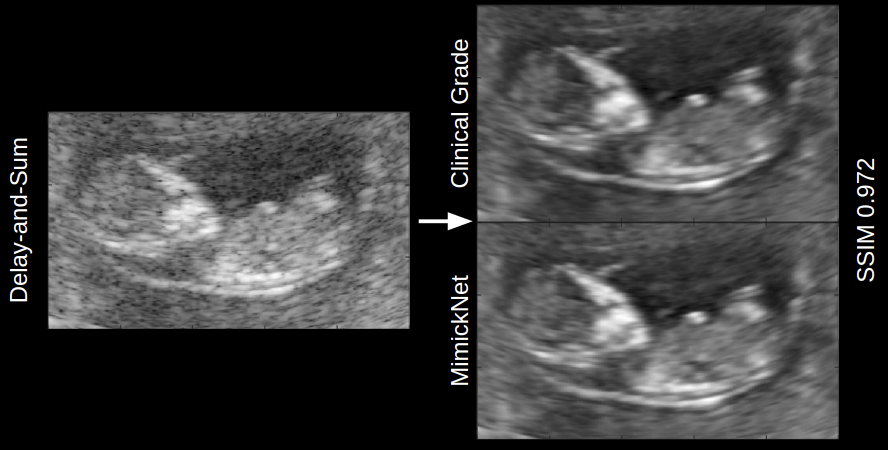
Regardless of these challenges, Palmeri sees many benefits to publicly sharing data including enhancing “our internal rigor even just that little bit more” as well as opening “new doors of opportunity for new research questions…and then the scope and impact of the work can be augmented.” Dr. Palmeri appreciates the infrastructure provided by the Duke University Libraries to host his data in a centralized and distributed network as well as the ability to cite his data via the DOI. As he notes “you don’t want to just put up something on Box as those services can change year to year and don’t provide a really good preserved resource.” Beyond the infrastructure, he appreciates how the curation team provides “an objective third party [to] look at things and evaluate how shareable is this.”
“you don’t want to just put up something on Box as those services can change year to year and don’t provide a really good preserved resource.”
Within the Duke Research Data Repository, we have a mission to help Duke researchers make their data accessible to enable reproducibility and reuse. Working with researchers, like Dr. Palmeri, to realize a future where open research practices lead to a greater impact for researchers and democratizes knowledge is a core driving motivator. Contact us (datamanagement@duke.edu) with any questions you might have about starting your own data sharing adventure!









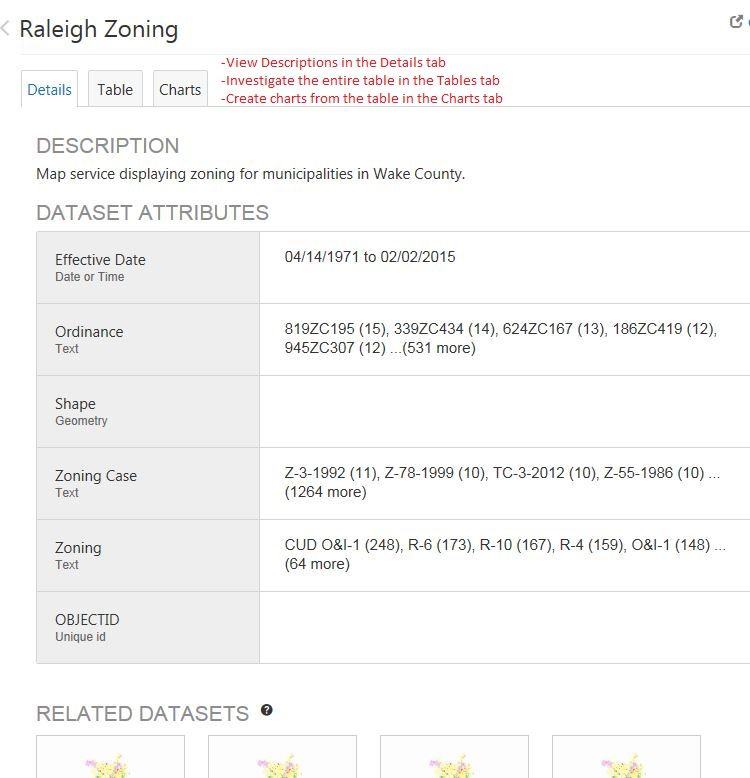
 Data visualization and data management represented the core themes of the
Data visualization and data management represented the core themes of the 
