
Felipe Álvarez de Toledo López-Herrera is a Ph.D. candidate in the Art, Art History, and Visual Studies Department at Duke University and a Digital Humanities Graduate Assistant for Humanities Unbounded, 2019-2020. Contact him at askdata@duke.edu.
[This blogpost introduces a GitHub Repository that provides resources for developing NER projects in historical languages. Please do not hesitate to use the code and ideas made available there, or contact me if there are any issues we could discuss .]
Understanding Historical Art Markets: an Automated Approach
When the Sevillian painters’ guild archive was lost in the 19th century, with it vanished lists of master painters, journeymen, apprentices and possibly dealers recorded in the guilds’ registration books. Nevertheless, researchers working for over a century in other Sevillian archives have published almost twenty volumes of archival documents. These transcriptions, excerpts and summaries reflect the activities of local painters, sculptors, and architects, among other artisans. I use this evidence as a source of data on early modern Seville’s art market in my dissertation research. For this, I have to extract information from many documents in order to query and discern larger patterns.

Instead of manually keying this information into a spreadsheet or other form of data storage, I chose to scan my sources and test an automated approach using Natural Language Processing. Last semester, within the context of the Humanities Unbounded Digital Humanities Graduate Assistantship, I worked with Named-Entity Recognition (NER), a technique in which computers can be taught to identify named real-world objects in texts. NER models underperform on historical texts because they are trained on modern documents such as news or Wikipedia articles. Furthermore, NLP developers have focused most of their efforts on English language models, resulting in underdeveloped models for other languages. For these reasons, I had to retrain a model to be useful for my purposes. In this blogpost, I give an overview of the process of adapting NER tools for use on non-English historical sources.
Defining Named-Entity Recognition
Named-Entity Recognition (NER) is a set of processes in which a computer program is trained to identify and categorize real-world objects with proper names in a corpus of texts. It can be used to tag names in documents without a standardized structure and label them as people, locations or organizations, among other categories.
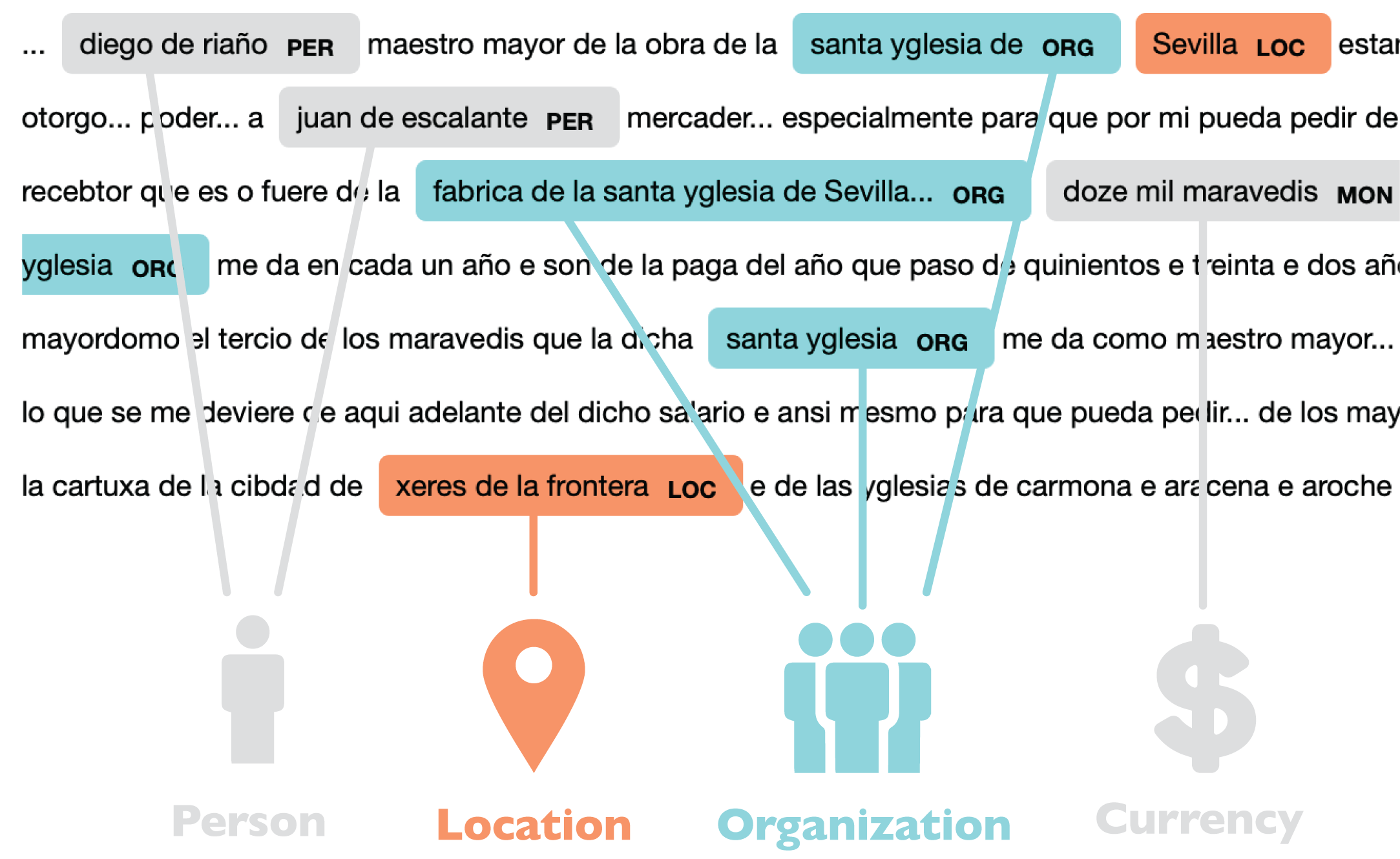
Code libraries such as Spacy, NLTK or Stanford CoreNLP provide widely-tested toolkits for NER. I decided that Spacy would be the best choice for my purposes. Though its Spanish model included less label categories, they performed better out-of-the-box. Importantly, the model worked better for certain basic language structures such as recognizing compound names (last names with several components, such as my own). The Spacy library also proved user-friendly for those of us with little coding knowledge. Its pre-programmed data processing pipeline is easy to modify, given that you have a basic understanding of Python. In my case, I had the time and motivation to acquire this literacy.
I sought to improve the model’s performance in two ways. First, I retrained it on a subset of my own data. This improved performance and allowed me to add new label categories such as dates, monetary amounts and objects. Additionally, I added a component that modernized my texts’ spelling to make them more conducive to proper tagging.
Training NER on Historical Spanish Text: Process and Results
To improve the model, I needed training data – a “gold standard” of perfectly-tagged text. First, I ran the model on a set of 400 documents, which resulted in a set of preliminary tags. Then, I corrected these tags with a tool called Dataturks and reformatted the output to work with Spacy. Once this data was ready, I split it 80-20, which means running a training loop on 80% of correctly-tagged texts to adjust the performance of the model, and reserving 20% for testing or evaluating the model on data it had not yet seen.

Finally, I evaluated whether all these changes actually improved the model’s performance, saved the updated model, and exported the output in a format that worked for my own database. For my texts, the model initially worked at around 36% recall (the percentage of true entities that were identified by the model), compared to an 89% recall with modern texts as evaluated by Spacy. After training, recall has increased to 64%. Some tags, such as person or location, perform especially well (85% and 81%, respectively). Though the numbers are not perfect, they show a marked improvement, generated with little training data.
For the 8,607 documents processed, the process has resulted in 59,191 tags referring to people, locations, organizations, dates, objects and money. Next steps include finding descriptors of entities within the text, and modeling relationships between entities appearing in the same document. For now, a look at the detected tags underscores the potential of NER for automating data collection in data-driven humanities research.