As a recent first-time parent, I’m constantly soliciting advice from other more experienced people I meet about how best to take care of my baby. I thought it might be fun to peruse the Duke Digital Collections to see what words of wisdom could be gleaned from years past.
This 1930 ad, part of the Medicine and Madison Avenue collection, advises that we should make regular visits to the doctor’s office so our baby can be ‘carefully examined, measured, weighed and recorded.’ Excellent – we’ve been doing that!
This one from 1946 offers the ‘newest facts and findings on baby care and feeding.’ Overall the advice largely seems applicable to today. I found this line to be particularly fun:
Let your child participate in household tasks — play at dusting or cooking or bedmaking. It’s more of a hindrance than a help, but it gives the youngster a feeling of being needed and loved.
Baby strollers seem to have many innovative features these days, but more than 100 years ago the Oriole Go-Basket — a ‘combined Go-Cart, High Chair, Jumper and Bassinet’ — let you take your baby everywhere.
I’m a puzzled father of a rather young child — it’s like this 1933 ad was written just for me…
Of all the digitized materials in the collections I searched through, this 1928 booklet from the Emergence of Advertising in America collection seems to hold the most knowledge. On page 15, they offer ‘New Ways to Interest the Whole Family’ and suggest serving ‘Mapl-Flake’ and ‘Checkr-Corn Flake’ — are these really Web startups from 2005?
And finally, thanks to this 1955 ad, I’m glad to know I can give my baby 7-up, especially when mixed in equal parts with milk. ‘It’s a wholesome combination — and it works!’
Did you ever stop to think about how the materials you find in the Library’s catalog search get there? Did you know the Duke Libraries have three staff members dedicated to making sure Duke’s library catalog is working so faculty and students can do their research? The library catalog is the backbone of the library and I hope by the end of this post you will have a new appreciation for some of the people who support this backbone of the library and what is involved to do that.
Functions of a library catalog
Discovery Services is charged with supporting the integrated library system (ILS), aka “the catalog”. What is an “integrated library system”? According to Wikipedia, “an ILS (is used) to order and acquire, receive and invoice, catalog, circulate, track and shelve materials.” Our software is used by every staff person in all the Duke Libraries, including the professional school libraries, the Goodson Law Library, the Ford Library at the Fuqua School of Business, and the Medical Center Library, and the Duke Kunshan University Library. At Duke, we have been using Ex Libris’s Aleph as our ILS since 2004.
Discovery Services staff work with staff in Technical Services who do the acquiring, receiving and invoicing and cataloging of materials. Our support for that department includes setting up vendors who send orders and bibliographic records via the EDIFACT format or the MARC format. Some of our catalogers do original cataloging where they describe the book in the MARC format, and a great many of our records are copy cataloged from OCLC. Our ILS needs to be able to load these records, regardless of format, into our relational database.
We work with staff in Access and Delivery Services/Circulation in all the libraries to set up loan policies so that patrons may borrow the materials in our database. All loan policies are based on the patron type checking out the item, the library that owns the item and the item’s type. We currently have 59 item types for everything from books, to short-term loans, sound CD’s, and even 3D scanners! There are 37 patron types ranging from faculty, grad students, staff, undergrads, alumni and even retired library employees. And we support a total of 12 libraries. Combine all of those patrons, items and libraries, and there are a lot of rules! We edit policies for who may request an item and where they can choose to pick it up, when fines are applied and when overdue and lost notices are sent to patrons. We also load the current course lists and enrollment so students and faculty can use the materials in Course Reserves.
ILS Connections
The ILS is connected with other systems. There was a recent post here on Bitstreams about the work of the Discovery Strategy Team. Our ILS, Aleph, is represented in both the whiteboard photo and the Lucidchart photo. One example of an integration point the Library’s discovery interface. We also connect to the software that is used at the Library Service Center (GFA). When an item is requested from that location, the request is sent from the ILS to the software at the Library Service Center so they can pull and deliver the item. The ILS is also integrated with software outside of the library’s support including the Bursar’s Office, the University’s Identity Management system, and the University’s accounting system.
We also export our data for projects in which the library is involved, such as HathiTrust, Ivy Plus, TRLN Discovery (coming soon!), and SHARE-VDE. These shared collection projects often require extra work from Discovery Services to make sure the data the project wants is included in our export.
Discovery Services spent the fall semester working on upgrading Aleph. We worked with our OIT partners to create new virtual servers, install the Aleph software and upgrade our current data to the new version. There were many configuration changes, and we needed to test all of our custom programs to be sure they worked with the new version. We have been using the Aleph software for a more than a decade, and while we’ve upgraded the software over the years, libraries have continued to change.
We are currently preparing a project to migrate to a new ILS and library services platform, FOLIO. That means moving our eight million bibliographic records and associated information, our two million patron records, hundreds of thousands orders, items, e-resources into the new data format FOLIO will require. We will build new servers, install the software, review and/or recreate all of our custom programs that we currently use. We will integrate FOLIO with all the applications the library uses, as well as applications across campus. It will be a multi-year project that will take thousands of hours of staff time to complete. The Discovery Services staff is involved in some of the FOLIO special interest groups working with people across the world who are working together to develop FOLIO.
We work hard to make it easy for our patrons to find library material, request it or borrow it. The next time you check out a book from the library, take a moment to think about all the work that was required behind the scenes to make that book available to you.
Model for Monument to the Third International, Vladimir Tatlin
Russia has been back in the news of late for a variety of reasons, some, perhaps, more interesting than others. Last year marked the centennial of the 1917 Russian Revolution, arguably one of the foundational events of the 20th century. The 1917 Revolution was the beginning of enormous upheaval that touched all parts of Russian life. While much of this tumult was undeniably and grotesquely violent, some real beauty and lasting works of art emerged from the maelstrom. New forms of visual art and architecture, rooted in a utopian vision for the new, modern society, briefly flourished. One of the most visible of these movements, begun in the years immediately preceding the onset of revolution, was Constructivism.
As first articulated by Vladimir Tatlin, Constructivism as a philosophy held that art should be ‘constructed’; that is to say, art shouldn’t be created as an expression of beauty, but rather to represent the world and should be used for a social purpose. Artists like Tatlin, El Lissitzky, Naum Gabo, and Alexander Rodchenko worked in conversation with the output of the Cubists and Futurists (along with their Russian Suprematist compatriots, like Kazimir Malevich), distilling everyday objects to their most basic forms and materials.
Beat the Whites with the Red Wedge, El Lissitzky, 1919
As the Revolution proceeded, artists of all kinds were rapidly brought on board to help create art that would propagate the Bolshevik cause. Perhaps one of El Lissitzky’s most well-known works, “Beat the Whites with the Red Wedge”, is illustrative of this phenomenon. It uses the new, abstract, constructed forms to convey the image of the Red Army (the Bolsheviks) penetrating and defeating the White Army (the anti-Bolsheviks). Alexander Rodchenko’s similarly well-known “Books” poster, an advertisement for the Lengiz Publishing House, is another informative example, blending the use of geometric forms and bright colors with advertising for a publishing house that produced materials important to the Soviet cause.
Lengiz, Alexander Rodchenko, 1924
Constructivism (and its close kin, Suprematism) would go on to have an enormous impact on Russian and Soviet propaganda and other political materials throughout the existence of the Soviet Union. The Duke Digital Repository has an impressive collection of Russian political posters, spanning almost the entire history of the Soviet Union, from the 1917 Revolution on through to the Perestroika of the 1980s. The collection contains posters and placards emphasizing the benefits of Communism, the achievements of the Soviet Union under Communism, and finally the potential dangers inherent in the reconstruction and openness that characterized the period under Mikhail Gorbachev. I wanted to use this blog post to highlight a few of my favorites below, some of which bear evidence of this broader art historical legacy.
Literacy, the road to Communism, 1920Easter. Contrast of joyous Easter of Long Ago with Serious Workers of Com.[mmunist] Russia, 1930Member of a Religious Sect Is Fooling the People, 1925Young Leninists are the children of Il’ich, 1924Female workers and peasants, make your way to the voting booth! Under the red banner, in the same ranks as the men, we inspire fear in the bourgeoisie!, 1925
Last week, an indefatigable team at Duke University Libraries released an upgraded version of the DukeSpace platform, completing the first phase of the critical project that I wrote about in this space in January. One member of the team remarked that we now surely have “one of the best DSpaces in the world,” and I dare anyone to prove otherwise.
DukeSpace serves as the Libraries’ open-access institutional repository, which makes it a key aspect of our mission to “partner in research,” as outlined in our strategic plan. As I wrote in January, the version of the DSpace platform that underlies the service had been stuck at 1.7, which was released during 2010 – the year the iPad came out, and Lady Gaga wore a meat dress. We upgraded to version 6.2, though the differences between the two versions are so great that it would be more accurate to call the project a migration.
That migration turned out to be one of the more complex technology projects we’ve undertaken over the years. The main complicating factor was the integration with Symplectic Elements, the Research Information Management System (RIMS) that powers the Scholars at Duke site. As far as we know, we are the first institution to integrate Elements with DSpace 6.2. It was a beast to do, and we are happy to share our knowledge gained if it will help any of our peers out there trying to do the same thing.
Meanwhile, feel free to click on over to and enjoy one of the best DSpaces in the world. And congratulations to one of the mightiest teams assembled since Spain won the World Cup!
This Friday and Saturday, March 23 – 24, veterans of the Civil Rights Movement, contemporary activists from the Movement for Black Lives, scholars, librarians, educators, and students are gathering in Durham for the culminating events of the SNCC Digital Gateway Project. We hope you can be there too.
The Student Nonviolent Coordinating Committee (SNCC)—the only youth-led national civil rights group—organized a grassroots movement in the 1960s that empowered Black communities and transformed the nation. Veteran SNCC activists have been collaborating with Duke University to build the SNCC Digital Gateway, a website told from the perspective of the activists themselves that documents SNCC’s work building democracy from the ground up and makes those experiences, thinking, and strategies accessible for the generations to come.
Over 20 SNCC veterans, members of the Durham chapter of BYP100, phillip agnew of Dream Defenders, Ash-Lee Woodard Henderson, co-director of Highlander Center for Research and Education, local activists, educators, students, and more are coming together this weekend to reflect on the creation of the SNCC Digital Gateway and to explore how grassroots organizing work of the past can inform today’s struggles for justice and democracy.
Events on Friday, March 23, taking place in the Richard White Lecture Hall at Duke University, will focus on the partnership between SNCC veterans and the academy and the nuts and bolts of doing collaborative digital humanities work. Then on Saturday, March 24, participants will gather at the Walker Complex at North Carolina Central University to explore how SNCC’s organizing can inform today’s struggles and strategize about electoral politics and power, grassroots organizing, controlling the public narrative, coalition building, and more.
You can find more information about closing events here. Don’t miss this chance to learn from and interact with those who were organizing in the sixties and those who are organizing today. Bring yourselves. Bring others. It’s free, and you’re invited.
Just over one year ago, Duke University Library’s Web Experience team charged a new subgroup – the Discovery Strategy Team – with “providing cohesion for the Libraries’ discovery environment and facilitate discussion and activity across the units responsible for the various systems and policies that support discovery for DUL users.” Jacquie Samples, head of the Metadata and Discovery Strategy Department in our Technical Services Unit, and I teamed up to co-chair the group, and we were excited to take on this critical work along with 8 of our colleagues from across the libraries.
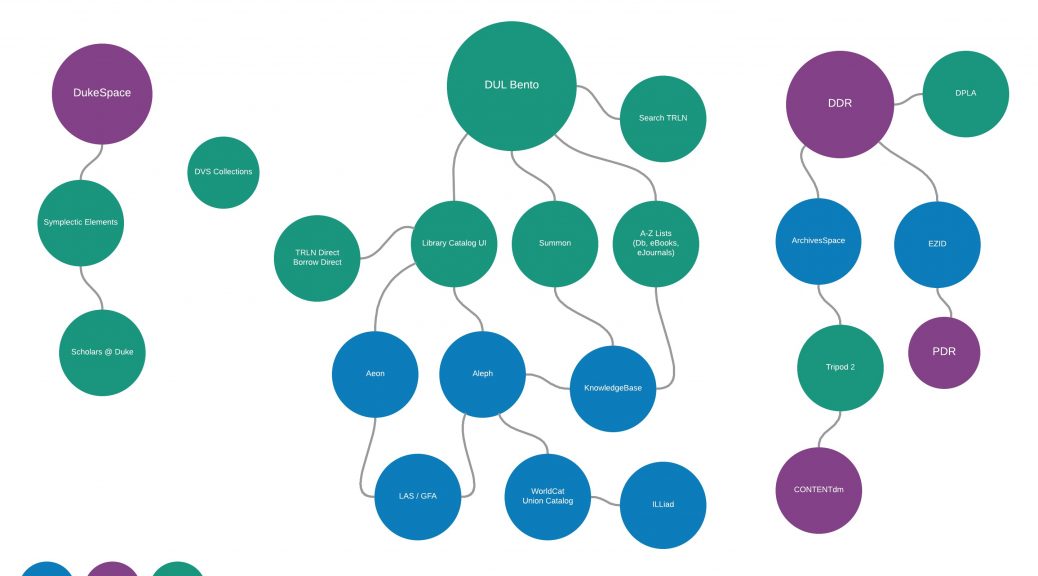
Our first task was one that had long been recognized as a need by many people throughout the library – to create an up-to-date visualization of the systems that underpin DUL’s discovery environment, including the data sources, data flows, connections, and technical/functional ownership for each of these systems. Our goal was not to depict an ideal discovery landscape but rather to depict things as they are now (ideal could come later).
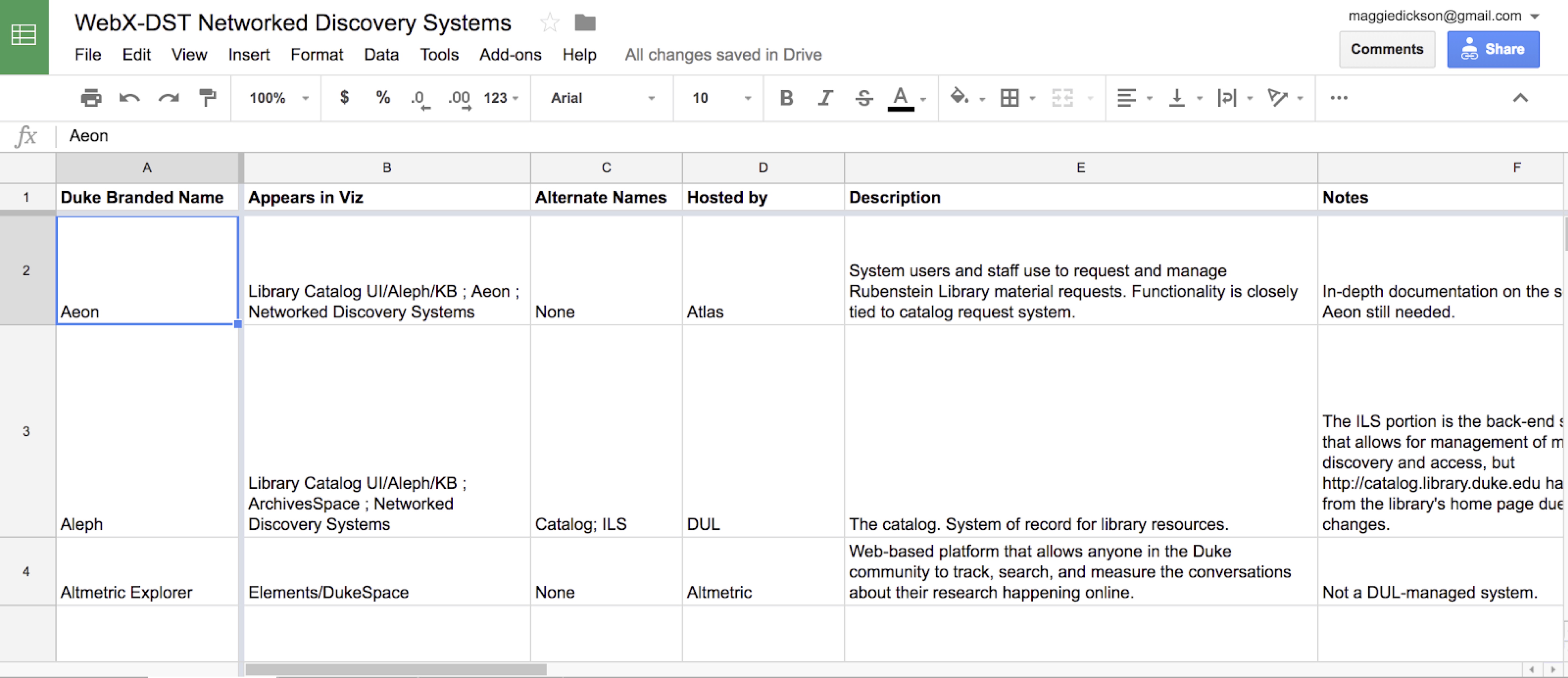
Before we could create a visualization of these systems and how they interacted, however, we realized we needed to identify what they were!This part of the process involved creating a giant laundry list of all of systems in the form of a google spreadsheet, so we could work on it collaboratively and iteratively. This spreadsheet became the foundation of the document we eventually produced, containing contextual information about the systems including:
Name(s) of the system
Description/Notes
Host
Path
Links to documentation
Technical & functional owners
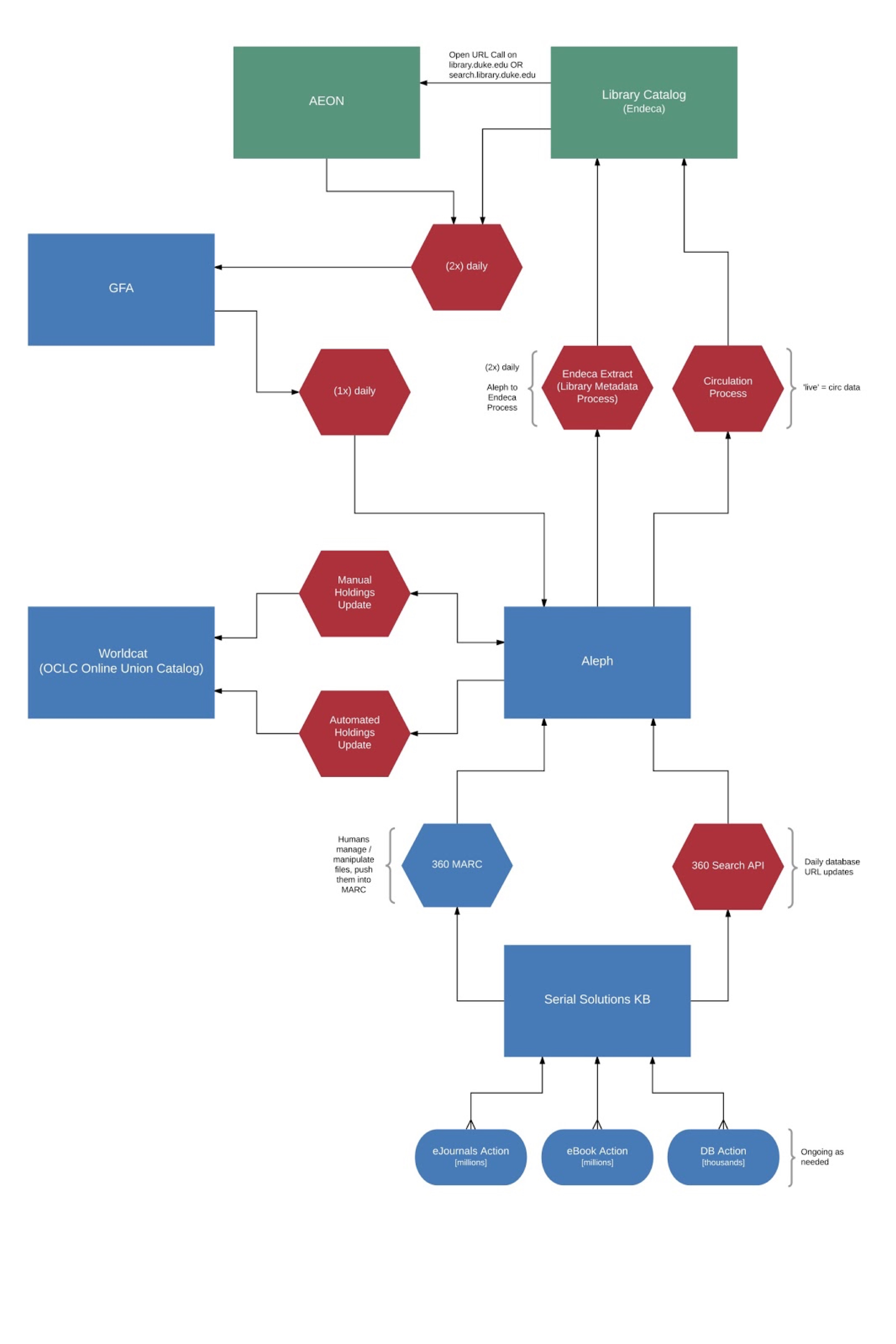
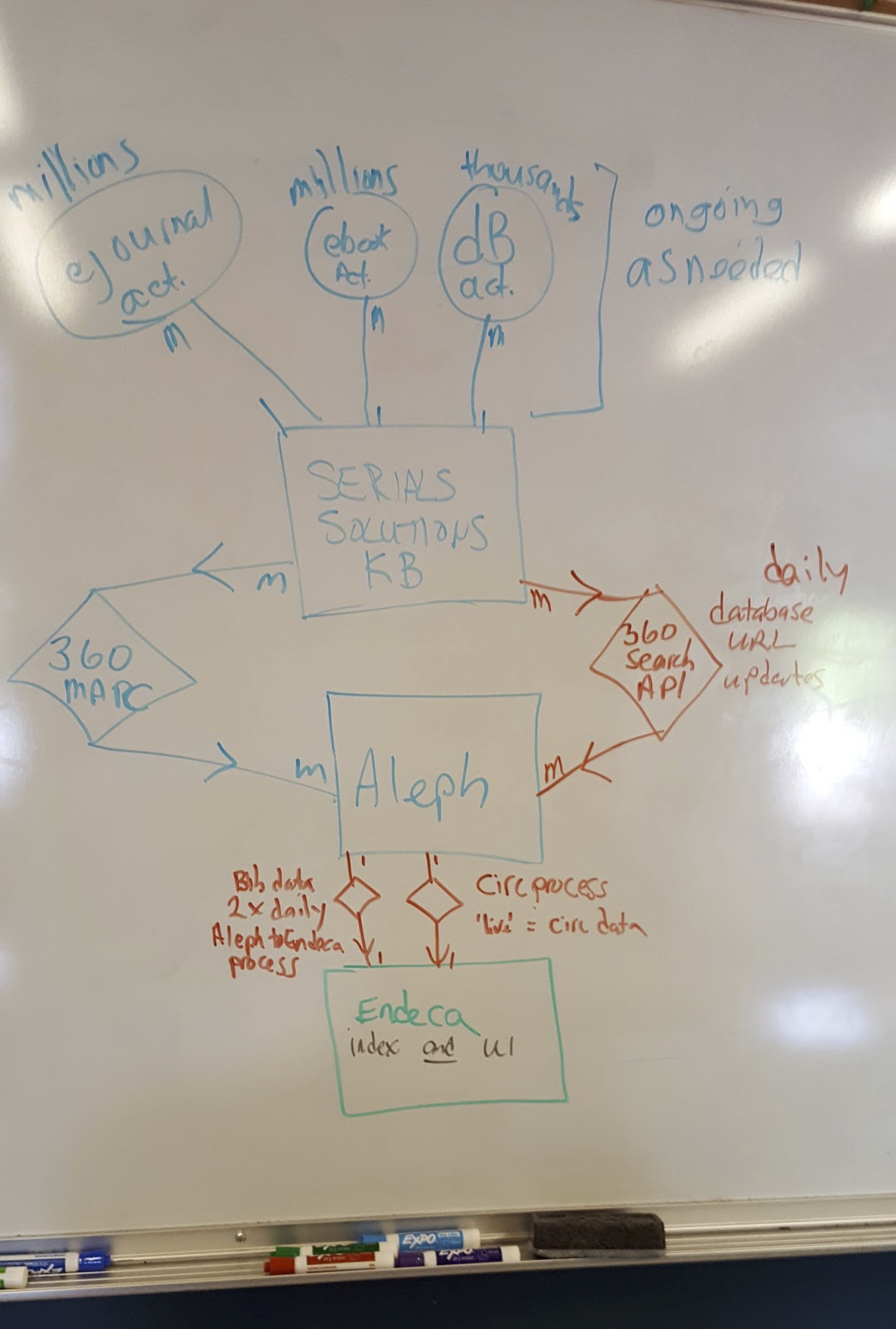
Once we had our list of systems to work from, we began the process of visualizing how they work here at DUL. Each meeting of the team involved doing a lot of drawing on the whiteboard as we hashed out how a given system works – how staff & other systems interact with it, whether processes are automated or not, frequency of those processes, among other attributes. At the end of these meetings we would have a messy whiteboard drawing like this one:
We were very lucky to have the talented (and patient!) developer and designer Michael Daul on the team for this project, and his role was to take our whiteboard drawings and turn them into beautiful, legible visualizations using Lucidchart:
Once we had created visualizations that represented all of the systems in our spreadsheet, and shared them with stakeholders for feedback, we (ahem, Michael) compiled them into an interactive PDF using Adobe InDesign. We originally had high hopes of creating a super cool interactive and zoomable website where you could move in and out to create dynamic views of the visualizations, but ultimately realized this wouldn’t be easily updatable or sustainable. So, PDF it is, which may not be the fanciest of vehicles but is certainly easily consumed.
We’ve titled our document ‘Networked Discovery Systems at DUL”, and it contains two main sections: the visualizations that graphically depict the systems, and documentation derived from the spreadsheet we created to provide more information and context for each system. Users can click from a high-level view of the discovery system universe to documentation pages, to granular views of particular ‘constellations’ of systems. Anyone interested in checking it out can download it from this link.
We’ve identified a number of potential use cases for this documentation, and hope that others will surface:
New staff orientation
Systems transparency
Improved communication
Planning
Troubleshooting
We’re going to keep iterating and updating the PDF as our discovery environment shifts and changes, and hope that having this documentation will help us to identify areas for improvement and get us closer to achieving that ideal discovery environment.
As regular Bitstreams readers know, a cross departmental team within Duke University Libraries has been exploring Multispectral Imaging and its potential to make Duke collections more accessible to researchers in the Duke scholarly community and beyond since 2015. After spending 2017 developing MSI workflows, building expertise, writing documentation, and responding to experimental imaging requests, we are now ready to unveil the first version of Duke University Libraries MSI service for researchers!
Our first service model version accommodates small requests that are not urgent. The MSI team wants to partner with researchers to facilitate their requests as well as hear feedback about our current service and any other needs for MSI. We are offering MSI services for free for the next few months, but will institute a fee structure this Summer.
The service breaks down into 4 general steps:
First, researchers submit a request for MSI services using a webform. The form prompts requesters to share their research question and details about what they want imaged. We also want to know where researchers are from, as we are expecting both Duke and non-Duke affiliated patrons.
Second, the MSI team will review all requests, as MSI is not the ideal imaging solution for all materials and research questions. Requests that will not benefit from MSI will not be approved.
Third, we schedule approved requests for imaging and processing. We plan to conduct 1 imaging and processing day per month, so it may take several weeks to a month for approved requests to make it though our full process.
Fourth, we deliver the processed files to our patrons along with a report that details the imaging and processing procedures and outcomes.
Please note the following:
We are currently only imaging Duke University Library holdings.
We are limiting requests to 1-3 individual items or 1-3 pages within a bound item (which is the number of items we can generally image and process in 1 day).
Allow 2-4 weeks for vetting and up to a month for imaging.
If you are interested in requesting MSI services, but your needs do not fit the service described here, we still want to hear from you! Please do not hesitate to fill out our researcher request form to get the process started, or contact Susan Ivey directly.
If you want to learn more about MSI, check out the recent talk we gave at the Friday Visualization Forum on February 23.
Apache Solr is behind many of our systems that provide a way to search and browse via a web application (such as the Duke Digital Repository, parts of our Bento search application, and the not yet public next generation TRLN Discovery catalog). It’s a tool for indexing data and provides a powerful query API. In this post I will document a few Solr querying techniques that might be interesting or useful. In some cases I won’t be able to provide live links to queries because we restrict direct access to Solr. However, many of these Solr querying techniques can be used directly in an application’s search box. In those cases, I will include live links to example queries in the Duke Digital Repository.
Find a list of items from their identifiers.
With this query you can specify exactly what items you want to appear in a search result from a list of identifiers.
Find all records that have a value (any value) in a specific field.
This query will find all the items in the repository that have a value in the product field. (As with most of these queries, you must know the field name in Solr.)
Find items using a begins-with (left-anchored) query.
I want to see all items that have a subject term that begins with “Soviet Union.” The example is a left-anchored query and will exactly match fields that begin with “Soviet Union.” (Note, the field must not be tokenized for this to work as expected.)
The following examples require direct access to Solr, which is restricted to authorized users and applications. Instead of providing live links, I’ll show the basic syntax, a complete example query using http://localhost:8983/solr/core/* as the sample URL for a Solr index, and a sample response from Solr.
Count instances of values in a field.
I want to know how many items in the repository have a workflow state of published and how many are unpublished. To do that I can write a facet query that will count instances of each value in the specified field. (This is another query that will only work as expected with an untokenized field.)
Collapse multiple records into one result based on a shared field value.
This one is somewhat advanced and likely only useful in particular circumstance. But if you had multiple records that were slight variants of each other, and wanted to collapse each variant down to a single result you can do that with a collapse query — as long as the records you want to collapse share a value.
!collapse instructs Solr to use the Collapsing Query Parser.
field=oclc_number instructs Solr to collapse records that share the same value in the oclc_number field.
nullPolicy=expand instructs Solr to return any document without a matching OCLC as part of the result set. If this is excluded then records that don’t share an oclc_number with another record will be excluded from the results.
max=termfreq(institution,duke) instructs Solr to select as the representative record when collapsing multiple records the one that has the value “duke” in institution field.
CSV response writer (or JSON, Ruby, etc.)
Solr has a number of tricks up its sleeve when it comes to returning results. By default it will return results as XML. You can also specify JSON, or Ruby. You specify a response writer by adding the wt parameter to the URL (wt=json or wt=ruby, etc.).
Solr will also return results as a CSV file, which can then be opened in an Excel spreadsheet — a useful feature for working with metadata.
id,title_tesim
duke:194006,Sun Bowl...Sun City...
duke:194002,Sun Bowl...Sun City...
duke:194009,Sun Bowl...Sun City.
duke:194019,Sun Bowl...Sun City.
duke:194037,"Sun City\, Sun Bowl"
duke:194036,"Sun City\, Sun Bowl"
duke:194030,Sun City
duke:194073,Sun City
duke:335601,Sun Control
duke:355105,Proved! Fast starts at 30° below zero!
This is just a small sample of useful ways you can query Solr.
When it comes to moving image digitization, Duke Libraries’ Digital Production Center primarily deals with obsolete videotape formats like U-matic, Betacam, VHS and DV, which are in standard-definition (SD). We typically don’t work with high-definition (HD) or ultra-high-definition (UHD) video because that’s “born digital,” and doesn’t need any kind of conversion from analog, or real-time migration from magnetic tape. It’s already in the form of a digital file.
However, when I’m not at Duke, I do like to watch TV at home, in high-definition. This past Christmas, the television in my living room decided to kick the bucket, so I set out to get a new one. I went to my local Best Buy and a few other stores, to check out all the latest and greatest TVs. The first thing I noticed is that just about every TV on the market now features 4K ultra-high-definition (UHD), and many have high dynamic range (HDR).
Before we dive into 4K, some history is in order. Traditional, standard-definition televisions offered 480 lines of vertical resolution, with a 4:3 aspect ratio, meaning the height of the image display is 3/4 the dimension of the width. This is how television was broadcast for most of the 20th century. Full HD television, which gained popularity at the turn of the millennium, has 1080 pixels of vertical resolution (over twice as much as SD), and an aspect ratio of 16:9, which makes the height barely more than 1/2 the size of the width.
16:9 more closely resembles the proportions of a movie theater screen, and this change in TV specification helped to usher in the “home theater” era. Once 16:9 HD TVs became popular, the emergence of Blu-ray discs and players allowed consumers to rent or purchase movies, watch them in full HD and hear them in theater-like high fidelity, by adding 5.1 surround sound speakers and subwoofers. Those who could afford it started converting their basements and spare rooms into small movie theaters.
4K UHD has 3840 horizontal pixels and 2160 vertical pixels, twice as much resolution as HD, and almost five times more resolution than SD.
The next step in the television evolution was 4Kultra-high-definition (UHD) TVs, which have flooded big box stores in recent years. 4K UHD has an astounding resolution of 3840 horizontal pixels and 2160 vertical pixels, twice as much resolution as HD, and almost five times more resolution than SD. Gazing at the images on these 4K TVs in that Best Buy was pretty disorienting. The image is so sharp and finely-detailed, that it’s almost too much for your eyes and brain to process.
For example, looking at footage of a mountain range in 4K UHD feels like you’re seeing more detail than you would if you were actually looking at the same mountain range in person, with your naked eye. And high dynamic range (HDR) increases this effect, by offering a much larger palette of colors and more levels of subtle gradation from light to dark. The latter allows for more detail in the highlight and shadow areas of the image. The 4K experience is a textbook example of hyperreality, which is rapidly encroaching into every aspect of our modern lives, from entertainment to politics.
The next thing that dawned on me was: If I get a 4K TV, where am I going to get the 4K content? No television stations or cable channels are broadcasting in 4K and my old Blu-ray player doesn’t play 4K. Fortunately, all 4K TVs will also display 1080p HD content beautifully, so that warmed me up to the purchase. It meant I didn’t have to immediately replace my Blu-ray player, or just stare at a black screen night after night, waiting for my favorite TV stations to catch up with the new technology.
The salesperson that was helping me alerted me to the fact that Best Buy also sells 4K UHD Blu-ray discs and 4K-ready Blu-ray players, and that some content providers, like Netflix, are streaming many shows in 4K and in HDR, like “Stranger Things,” “Daredevil” and “The Punisher,” to name a few. So I went ahead with the purchase and brought home my new 4K TV. I also picked up a 4K-enabled Roku, which allows anyone with a fast internet connection and subscription to stream content from Netflix, Amazon and Hulu, as well as accessing most cable-TV channels via services like DirecTV Now,YouTube TV, Sling and Hulu.
I connected the new TV (a 55” Sony X800E) to my 4K Roku, ethernet, HD antenna and stereo system and sat down to watch. The 1080p broadcasts from the local HD stations looked and sounded great, and so did my favorite 1080p shows streaming from Netflix. I went with a larger TV than I had previously, so that was also a big improvement.
To get the true 4K HDR experience, I upgraded my Netflix account to the 4K-capable version, and started watching the new Marvel series, “The Punisher.” It didn’t look quite as razor sharp as the 4K images did in Best Buy, but that’s likely due to the fact that the 4K Netflix content is more compressed for streaming, whereas the TVs on the sales floor are playing 4K video in-house, that has very little, if any, compression.
As a test, I went back and forth between watching The Punisher in 4K UHD, and watching the same Punisher episodes in HD, using an additional, older Roku though a separate HDMI port. The 4K version did have a lot more detail than its HD counterpart, but it was also more grainy, with horizons of clear skies showing additional noise, as if the 4K technology is trying too hard to bring detail out of something that is inherently a flat plane of the same color.
Also, because of the high dynamic range, the image loses a bit of overall contrast when displaying so many subtle gradations between dark and light. 4K streaming also requires a fast internet connection and it downloads a lot of data, so if you want to go 4K, you may need to upgrade your ISP plan, and make sure there are no data caps. I have a 300 Mbps fiber connection, with ethernet cable routed to my TV, and that works perfectly when I’m streaming 4K content.
I have yet to buy a 4K Blu-ray player and try out a 4K Blu-ray disc, so I don’t know how that will look on my new TV, but from what I’ve read, it more fully takes advantage of the 4K data than streaming 4K does. One reason I’m reluctant to buy a 4K Blu-ray player gets back to content. Almost all the 4K Blu-ray discs for sale or rent now are recently-made Hollywood movies. If I’m going to buy a 4K Blu-ray player, I want to watch classics like “2001: A Space Odyssey,”“The Godfather,”“Apocalypse Now” and “Vertigo” in 4K, but those aren’t currently available because the studios have yet to release them in 4K. This requires going back to the original film stock and painstakingly digitizing and restoring them in 4K.
Some older films may not have enough inherent resolution to take full advantage of 4K, but it seems like films such as “2001: A Space Odyssey,” which was originally shot in 65 mm, would really be enhanced by a 4K restoration. Filmmakers and the entertainment industry are already experimenting with 8K and 16K technology, so I guess my 4K TV will be obsolete in a few years, and we’ll all be having seizures while watching TV, because our brains will no longer be able to handle the amount of data flooding our senses.
This week Duke Digital Collections added our first set of interactive transcripts to one of our newest digital collections: the Silent Vigil (1968) and Allen Building Takeover (1969) collection of audio recordings. This marks an exciting milestone in the accessibility efforts Duke University Libraries has been engaged in for the past 2.5 years. Last October, my colleague Sean wrote about our new accessibility features and the technology powering them, and today I’m going to tell you a little more about why we started these efforts as well as share some examples.
Interactive Transcript in the Silent Vigil (1968) and Allen Building Takeover (1969) Audio Recordings
Providing access to captions and transcripts is not new for digital collections. We have been able to provide access to pdf transcripts and caption both in digital collections and finding aids for years. See items from the Behind the Veil and Memory Project digital collections for examples.
In recent years however, we stepped our efforts in creating captions and transcripts. Our work began in response to a 2015 lawsuit brought against Harvard and MIT by the National Association of the Deaf. The lawsuit triggered many discussions in the library, and the Advisory Council for Digital Collections eventually decided that we would proactively create captions or transcripts for all new A/V digital collections assuming it is feasible and reasonable to do so. The feasible and reasonable part of our policy is key. The Radio Haiti collection for example is composed of thousands of recordings primarily in Haitian Creole and French. The costs to transcribe that volume of material in non-English languages make it unreasonable (and not feasible) to transcribe. In addition to our work in the library, Duke has established campus wide web accessibility guidelines that includes captioning and transcription. Therefore our work in digital collections is only one aspect of campus wide accessibility efforts.
To create transcripts and captions, we have partnered with several vendors since 2015, and we have seen the costs for these services drop dramatically. Our primary vendor right now is Rev, who also works with Duke’s Academic Media Services department. Rev guarantees 99% accurate captions or transcripts for $1/minute.
Early on, Duke Digital Collections decided to center our captioning efforts around the WebVTT format, which is a time-coded text based file and a W3C standard. We use it for both audio and video captions when possible, but we can also accommodate legacy transcript formats like pdfs. Transcripts and captions can be easily replaced with new versions if and when edits need to be made.
Examples from the Silent Vigil (1968) and Allen Building Takeover (1969) Audio Recordings
When WebVTT captions are present, they load in the interface as an interactive transcript. This transcript can be used for navigation purposes; click the text and the file moves to that portion of the recording.
Click the image above to see the full item and transcript.
In addition to providing access to transcripts on the screen, we offer downloadable versions of the WebVTT transcript as a text file, a pdf or in the original webVTT format.
An advantage of the WebVTT format is that it includes “v” tags, which can be used to note changes in speakers and one can even add names to the transcript. This can require additional manual work if the names of the speakers is not obvious to the vendor, but we are excited to have this opportunity.
As Sean described in his blog post, we can also provide access to legacy pdf documents. They cannot be rendered into an interactive version, but they are still accessible for download.
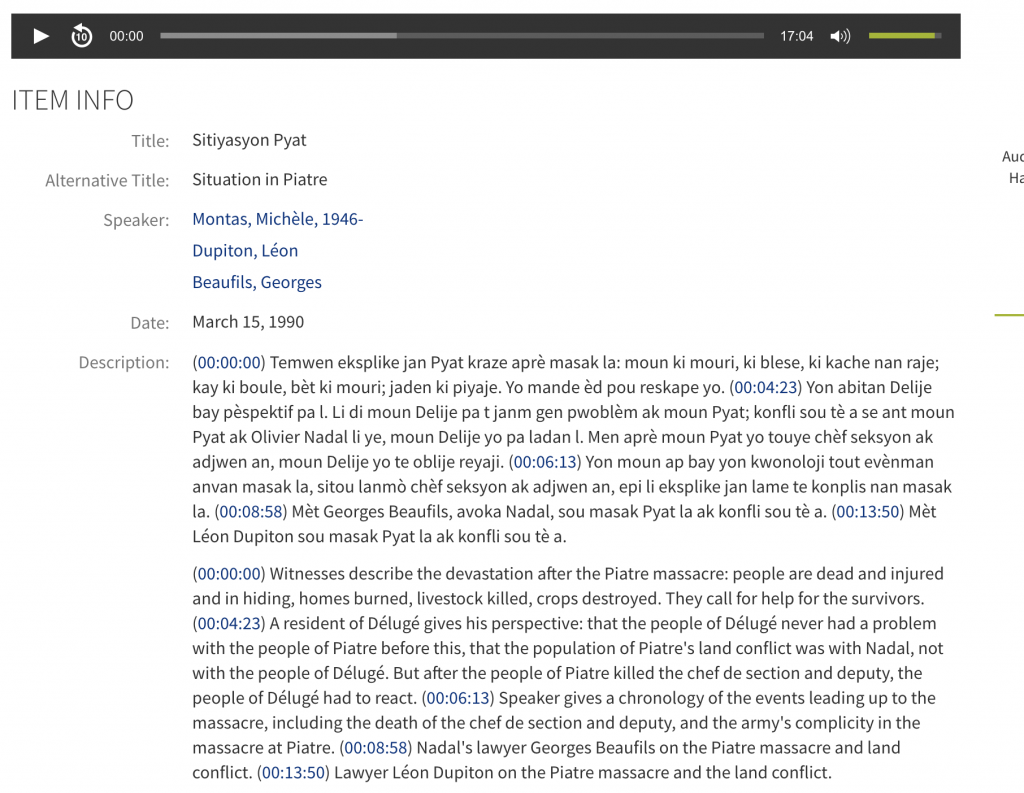
On a related note, we also have a new feature that links time codes listed in the description metadata field of an item to the corresponding portion of the audio or video file. This enables librarians to describe specific segments of audio and/or video items. The Radio Haiti digital collection is the first to utilize this feature, but the feature will be a huge benefit to the H. Lee Waters and Chapel Recordings digital collections as well as many others.
Click the image above to interact with linked time codes.
As mentioned at the top of this post, the Duke Vigil and Allen Building Takeover collection includes our first batch of interactive transcripts. We plan to launch more this Spring, so stay tuned!!
Notes from the Duke University Libraries Digital Projects Team