You might or might not have noticed a TRLN Discovery feature announcement in the February TRLN News Roundup. It mentioned that we are now indexing variant names from the Library of Congress Name Authority File in TRLN Discovery. I thought in this post I would expand on what this change means for Duke’s Books & Media catalog, add some details about the technical implementation, and discuss some related features we might add in the future based on this work.
What is it?
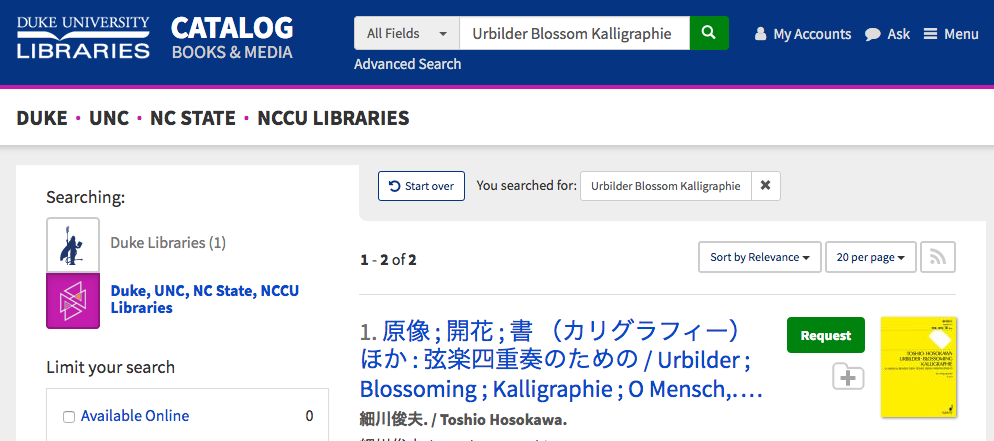
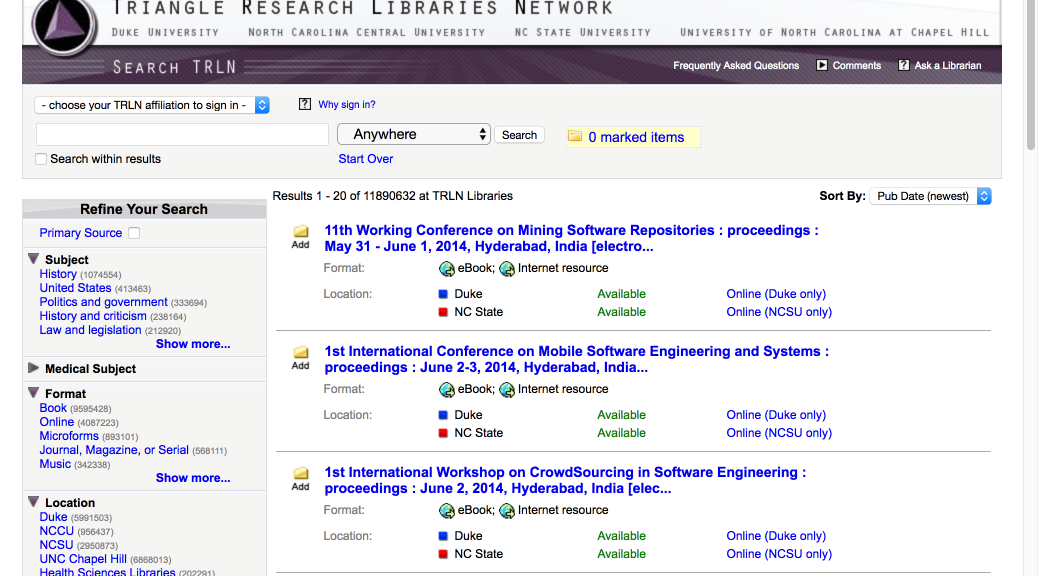
First, the practical matter: what does this feature mean for people who search the catalog? Our catalog records contain authoritative forms of creator names. This is the specific form of the person’s name chosen as the authoritative form by the Library of Congress. For example, the authoritative form of Emily Dickinson’s name is “Dickinson, Emily, 1830-1886.” If you search the Books & Media catalog using this form of the poet’s name you will find all records associated with her name (example search with the authoritative name). Previously, if you had searched the catalog and added the poet’s middle name, “Elizabeth,” it’s likely you would have missed many relevant results because “Elizabeth” is not included in the authoritative form of the name. It is, however, included in one of the variant names in the LC Name Authority File. The full list of variant names for Emily Dickinson is:
- Dickinson, Emilia, 1830-1886
- Dickinson, Emily Elizabeth, 1830-1886
- Dickinson, Emily (Emily Elizabeth), 1830-1886
- Dikinson, Ėmili, 1830-1886
- D̲ikinson, Emily, 1830-1886
- Ti-chin-sen, Ai-mi-li, 1830-1886
- דיקינסון, אמילי, 1830־1886
- דיקינסון, אמילי, 1886־1830
- Dykinsan, Ėmili, 1830-1886

Since we are now indexing these forms in TRLN Discovery you now get much better results if you happen to add Emily Dickinson’s middle name to your search (example search including a variant form of the name). Additionally, various romanizations and vernacular forms are indexed (example search for “דיקינסון, אמילי”).
If you clicked through to the example searches you may have noticed that the result counts and result order are slightly different when searching the authoritative form vs. the variant forms.
The variant forms are only indexed on records that include a URI that references the LC Name Authority File. If this URI reference is missing the variant names are not indexed for that record. Additionally, some records may not have been updated since we implemented this feature. In time all records that include URIs for names will have variant names indexed.
The difference in result order is due to how the variant names are indexed. For the authoritative form of the name we distinguish between creators, editors, contributors, etc. and give matches in these categories different boosts in the relevance ranking. At the moment, the variant names from the LCNAF file are indexed in a single field and so we lose the nuance needed for more granular relevance ranking. This is something that could be revised in the future if needed.
How does it work?
This feature relies on the fact that our MARC records include URI references to the LC Name Authority File. As an example, here’s a MARC XML 100 Main Entry-Personal Name field for Emily Dickinson with a URI reference to the authority file.
<datafield tag="100" ind1="1" ind2=" "> <subfield code="a">Dickinson, Emily,</subfield> <subfield code="d">1830-1886.</subfield> <subfield code="0">http://id.loc.gov/authorities/names/n79054166</subfield> </datafield>
We store this URI reference in the TRLN Discovery name field and then use this URI reference at ingest time to lookup and index the variant names from a local cache of the variant names. Here’s the stored name for Emily Dickinson in TRLN Discovery index.
names_a: ["{\"name\":\"Dickinson, Emily, 1830-1886\",\"rel\":\"author\",\"type\":\"creator\",\"id\":\"http://id.loc.gov/authorities/names/n79054166\"}"]
The TRLN Discovery ingest service keeps its own cache of the name identifiers and variant names for efficient lookup at ingest time. We use Redis, an open-source, in-memory (very fast) data store to make the variant names available when records are ingested. This local cache is built from the LC Name Authority File. Since the name authority file changes over time we will refresh our local cache of the data every 3 months to keep it up to date. We’ve written a script (Rails Rake task) that automates this update process.
What’s next?
The addition of stored name authority URIs in the TRLN Discovery index opens up opportunities to add more features in the future. I’m especially interested in displaying more contextual information about creators in our catalog. We could also expose “See also” references from the authority files to make it easier to find works by the same person published under different names (“Twain, Mark, 1835-1910” being a good example):
- Clemens, Samuel Langhorne, 1835-1910
- Conte, Louis de, 1835-1910
- Snodgrass, Quintus Curtius, 1835-1910

As always, we continue to add features and make incremental improvements to TRLN Discovery, and your feedback is critical. Please let us know how things are working for you using the feedback form available on every page of the Books & Media Catalog.