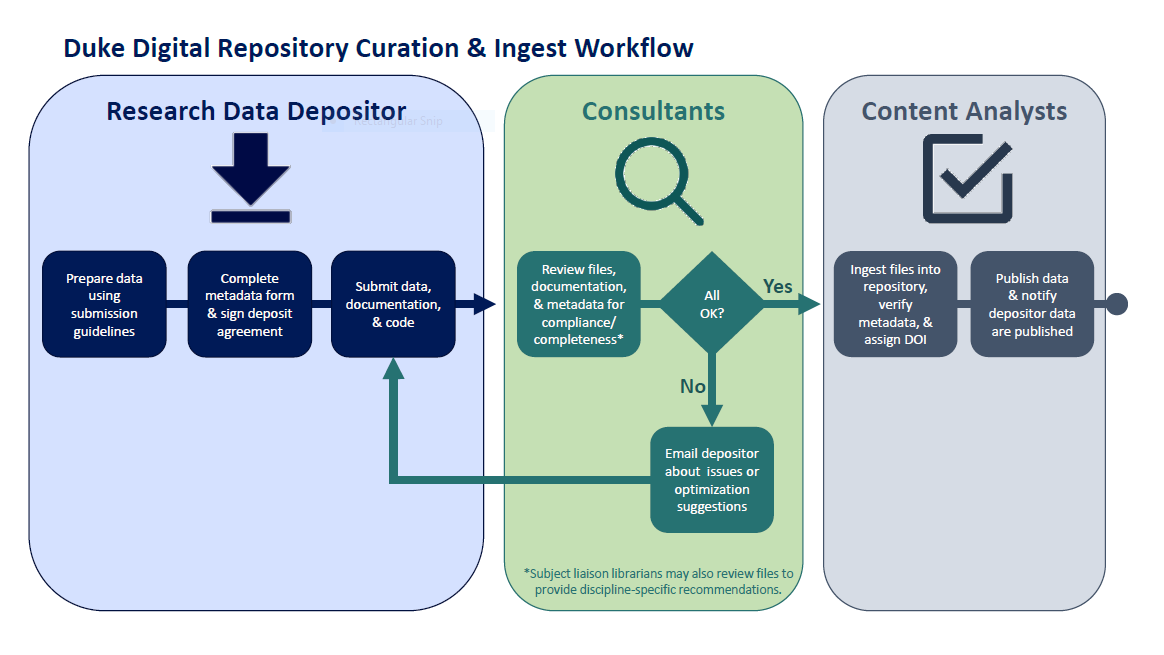
At DUL, we talk quite a lot about the value of research data curation. The Libraries provide a curatorial review of all data packages submitted to the Research Data Repository for publication. This review can help to enhance a researcher’s dataset by enabling a second or third pair of eyes to look over the data and ensure that all documentation is as complete as possible and that the dataset as a whole has been optimized for long term reuse. Although it’s not necessary to have expertise in the domain of the data under review, it can be helpful to give the curator a fuller picture of what is needed to help make those data FAIR. While data curators working in the Libraries possess a wealth of knowledge about general research data-related best practices, and are especially well-versed in the vagaries of social sciences data, they may not always have the all the information they need to sufficiently assess the state of a dataset from a researcher.
As I discussed in a blog post back in 2019, for the last few years, Duke has been a part of a project designed to address gaps in domain proficiency that are a natural part of a curation program of our size. The Data Curation Network has functioned as grant-supported consortium of data curation professionals located in research institutions who have pooled their knowledge to provide enhanced review for data that fall outside the expertise of local curators. Partner institutions can submit datasets to the Network and they will be matched with a DCN curator with the relevant domain experience. Beyond providing curation services, the DCN generates a variety of community resources pertaining to data curation, including a standardized set of curation steps and workflow, a list of essential data curation activities, and a growing roster of instructional primers to support the curation of various kinds of data.
The DCN has grown since my last post, and now includes curators from 11 institutions and the Dryad research data repository. DCN curators work with data from disciplines ranging from aerospace engineering to urban and regional planning and tackle data types from qualitative survey responses to machine learning model training datasets.


Although two members have worked with the DCN for a few years, the rest of the DUL research data curation team is now getting in on the action. Last week, the two Repository Services Analysts embedded with the curation team began the process of onboarding to serve as DCN curators. While we have been able to contribute to local curation of datasets for the RDR, this new opportunity presents us with a chance to not only gain valuable experience working with some practiced curators, but also to contribute back to the community that has helped to support our work. We are very excited to expand and deepen our DCN participation!