We recently published a blog post outlining our recent decision to drop Basecamp as a project management platform. Several people have asked us to share our new solution(s), and we thought we would take the opportunity to explain at a high level how we approached migrating away from Basecamp.
When DUL decided we would not be renewing our Basecamp subscription, there were about 88 active projects representing work across the entire organization. The owners of these projects would have just over two months to export their content and, if necessarily, migrate it to a new solution.
Exporting Content
Our first step was to form a 3-person migration team to explore different options for exporting content from Basecamp. We identified two main export options: DIY exporting and administrator exporting. For both options, we proactively tested the workflow, made screencasts, and wrote tutorials to ensure staff were well-prepared for either option.
Before explaining the export options, however, we emphasized to staff that they should only export content that is needed for ongoing work or archival purposes. For completed projects that are no longer needed, we encouraged staff to “let it go.”
DIY exporting: We established that any member of a Basecamp project or team could export content from Basecamp. For projects that primarily used Basecamp to create documents or share files, we recommended they use the built-in export functionality within the Docs & Files section of the project. Project members could just go to Docs & Files, click the three dots menu in the upper-right corner, and select “Download this folder.” The download would include all of the same subfolders that were created in Basecamp. Basecamp documents would be saved as HTML files, and additional files would appear in their original format. One note, however, is that the HTML versions of the Basecamp documents would not include the comments added to those documents.
To export documents with their comments, or to export other Basecamp content like Message Boards or To-dos, another option was to save the individual pages as PDFs. While this took more time and didn’t work well for large and complicated projects, it had the added benefit of preserving the look-and-feel of the original Basecamp content. PDF was also preferable to HTML for some situations, like viewing the files in different file storage solutions.
Administrator exporting: If a team really needed a complete export of the current Basecamp content, an administrator for the Basecamp account could generate a full export. This type of export generated an HTML-based set of files that included all components of the project and any comments on documents. Every page available in Basecamp in the browser became a separate HTML file. With this export, however, the HTML files that were created for Docs & Files were stored in the same directory, all in a bunch. End users could still see subfolders when navigating the HTML files in a web browser, but the downloaded files weren’t organized that way anymore.
We decided not to track the DIY exporting but needed to organize the requests for administrator exporting as only a few accounts were “Basecamp Owners.” To organize and facilitate this process, we created an online request form for staff to complete.
To help folks decide what they needed, we created a visual decision tree representing export options.
Alternative Project Management Tools
We realized early on that it was out of scope to complete a formal migration from Basecamp to one specific, alternate tool. We didn’t have staff capacity for that kind of project, and we weren’t inclined to prescribe the same solution for every project or team. To promote reliability and additional support systems, we encouraged teams to take advantage of enterprise solutions already supported by Duke University. The primary alternatives supported by Duke at this time were Box and MS Teams. Box had been in use in the Libraries for several years, but MS Teams was newer and not used in as widespread a manner across all staff.
To help folks decide what tool they wanted to use, we created some documentation comparing the various features of Box and MS Teams with the functionality folks were used to in Basecamp. We also created screencasts that demonstrated how one can use Tasks in Box or the Planner app within Teams for managing projects and assignments.
Basecamp to Teams and Box Features
Basecamp
Teams
Box
Others
Campfire
Chat
Comments on Files, BoxNotes
Message Board
Chat (can thread chats in Teams)
Comments on Files, Box Notes
To-dos
Tasks by Planner and To Do
Task List
Schedule
Channel Calendar, Tasks by Planner and To Do (timelines and due dates for tasks)
Task List (due date scheduling)
Outlook: Resource or Shared Calendar
Automatic Check-ins
Docs & Files
Files tab (add Shortcut to OneDrive for desktop access)
All of Box (add Box Drive for desktop access)
Email Forwards
Card Table
Tasks by Planner and To Do
MeisterTask
Managing Exported HTML Files
To be honest, having all our Basecamp created documents export as HTML files was challenging. In Box, the HTML files would just display the code view when opened online, and this was frustrating to our colleagues who use Box. While Teams would display the rendered web pages of the HTML files very well, any relative links between HTML files would be broken. For staff who wanted, essentially, a clone of their Basecamp project site, we directed them to use Box Drive or to sync a folder in their Team to OneDrive. When opened that way, the exported files would be navigable as normal, so we saw this as more of a challenge of guiding user behavior rather than manipulating the files themselves. Since we had encountered these issues in our preliminary testing of workflows and exports, we built that guidance into the first explanatory screencasts we made. Foregrounding those issues helped many people avoid them altogether.
Supporting Staff through the Transition
Overall, we had a very smooth transition for staff. In terms of time invested in this process, the Basecamp Migration Team spent a lot of time upfront preparing documentation and helpful how-to videos. We set up a centralized space for staff to find all of our documentation and to ask questions, and we also scheduled several blocks of open office hours to offer more personalized help. That work supported staff who were comfortable managing their own export, and the number of teams requiring administrator support or additional training ended up being manageable. The deadline for submitting requests for an administrator export was about one month before the cancellation date, but many teams submitted their requests earlier than that. All of these strategies worked well, and we felt very comfortable cancelling our account on the appointed day. We migrated out of Basecamp, and you can too!
Written by Will Shaw on behalf of the Library Summer Camp organizing committee.
From June to August, most students may be off campus, but summer is still a busy time at Duke Libraries. Between attending conferences, preparing for fall semester, and tackling those projects we couldn’t quite fit into the academic year, Libraries staff have plenty to do. At the same time, summer also means a lull in many regular meetings — as well as remote or hybrid work schedules for many of us. Face-to-face time with our colleagues can be hard to come by. Lucky for all of us, July is when Libraries Summer Camp rolls around.
What is Summer Camp?
Summer Camp began in 2019 with two major goals: to foster peer-to-peer teaching and learning among Libraries staff, and to help build connections across the many units in our organization. Our staff have wide-ranging areas of expertise that deserve a showcase, and we could use a little time together in the summer. Why not try it out?
The first Summer Camp was narrowly focused on digital scholarship and publishing, and we solicited sessions from staff who we knew would already have instructional materials in hand. The response from both instructors and participants was enthusiastic; we ultimately brought staff together for 21 workshops over the course of a week in late summer.
The pandemic scuttled plans for 2020 and 2021 Summer Camps, but we relaunched in 2022 with the theme “Refresh!”—a conscious attempt to help us reconnect (in person, when possible!) after months of physical distance. Across the 2019, 2022, and 2023 iterations, Libraries Summer Camp has brought over 60 workshops to hundreds of attendees.
What did we learn this year?
Professional development workshops are still at the core of Summer Camp. But over the years, Camp has evolved to include a wider range of personal enrichment topics. The evolution has helped us find the right tone: learning together, as always, but having fun and focusing on personal growth, too.
For example, participants in this year’s Summer Camp could learn how to crochet or play the recorder, explore native plants, create memes, or practice Koru meditation. In parallel with those sessions, we had opportunities to discover the essentials of data visualization, try out platforms such as AirTable, discuss ChatGPT in libraries, learn fundraising basics, and improve our group discussions and decision-making, to name just a few.
Like any good Summer Camp, we wrapped things up with a closing circle. We shared our lessons learned, favorite moments, and hopes for future camps over Monuts and coffee.
Photo by Janelle Hutchinson, Lead Designer and Photographer, Duke University Libraries.Libraries staff reflect on Summer Camp 2023 over snacks and coffee. Photo by Janelle Hutchinson, Lead Designer and Photographer, Duke University Libraries
What’s next?
After its third iteration, Summer Camp is starting to feel like a Duke Libraries tradition. Over 100 Libraries staff came together to teach with and learn from each other in 25 sessions this year. Based on both attendance and participant feedback, that’s a success, and it’s one we’d like to sustain. It’s hard not to feel excited for Summer Camp 2024.
As we look ahead, the organizing committee—Angela Zoss, Arianne Hartsell-Gundy, Kate Collins, Liz Milewicz, and Will Shaw—will be actively seeking new members, ideas for Summer Camp sessions, and volunteers to help out with planning. We encourage all Libraries staff to reach out and let us know what you’d like to see next time around!
Coming on board as the new Web Experience Developer in the Assessment and User Experience Services (AUXS) Department in early 2022, one of my first priorities was to get up to speed on Web Accessibility guidelines and testing. I wanted to learn how these standards had been applied to Library websites to date and establish my own processes and habits for ongoing evaluation and improvement. Flash-forward one year, and I’m looking back at the steps that I took and reflecting on lessons learned and projects completed. I thought it might be helpful to myself and others in a similar situation (e.g. new web developers, designers, or content creators) to organize these experiences and reflections into a sort of manual or “Quick Start Guide”. I hope that these 5 steps will be useful to others who need a crash course in this potentially confusing or intimidating–but ultimately crucial and rewarding–territory.
Learn from your colleagues
Fortunately, I quickly discovered that Duke Libraries already had a well-established culture and practice around web accessibility, including a number of resources I could consult.
Two Bitstreams posts from our longtime web developer/designer Sean Aery gave me a quick snapshot of the current state of things, recent initiatives, and ongoing efforts:
Repositories of the Library’s open source software projects proved valuable in connecting broader concepts with specific examples and seeing how other developers had solved problems. For instance, I was able to look at the code for DUL’s “theme” (basically visual styling, color, typography, and other design elements) to better understand how it builds on the ubiquitous Bootstrap CSS framework and implements specific accessibility standards around semantic markup, color contrast, and ARIA roles/attributes:
Equipped with some background and context, I found I was much better prepared to formulate questions for team meetings or the project Slack channel.
Look for guidelines from your institution
Duke’s Web Accessibility Initiative establishes clear web accessibility standards for the University and offers practical information on how to understand and implement them:
The site also offers guides geared towards the needs of different stakeholders (content creators, designers, developers) as well as a step-by-step overview of how to do an accessibility assessment.
Know your standards
Duke University has specified the Worldwide Web Consortium Web Content Accessibility Guidelines version 2.0, Level AA Conformance (WCAG 2.0 Level AA) as its preferred accessibility standard for websites. While it was initially daunting to digest and parse these technical documents, at least I had a known, widely-adopted target that I was aiming for–in other words, an achievable goal. Feeling bolstered by that knowledge, I was able to use the other resources mentioned here to fill in the gaps and get hands-on experience and practice solving web accessibility issues.
RTFM, ok?
Find a playground
As I settled into the workflow within our Scrum team (based on Agile software development principles), I found a number of projects that gave me opportunities to test and experiment with how different markup and design decisions affect accessibility. I particularly enjoyed working with updating the Style Guide for our Catalog as part of a Bootstrap 3–>4 migration, updating our DUL Theme across various applications — Library Catalog, Quicksearch, Staff Directory — built on the Ruby on Rails framework, and getting scrappy and creative trying to improve branding and accessibility of some of our vendor-hosted web apps with the limited tools available (essentially jQuery scripts and applying CSS to existing markup).
Build your toolkit
A few well-chosen tools can get you far in assessing and correcting web accessibility issues on your websites.
Browser Tools
The built-in developer tools in your browser are essential for viewing and testing changes to markup and understanding how CSS rules are applied to the Document Object Model. The Deque Systems aXe Chrome Extension (also available for Firefox) adds additional tools for accessibility testing with a slick interface that performs a scan, gives a breakdown of accessibility violations ranked by severity, and tells you how to fix them.
Color Contrast Checkers
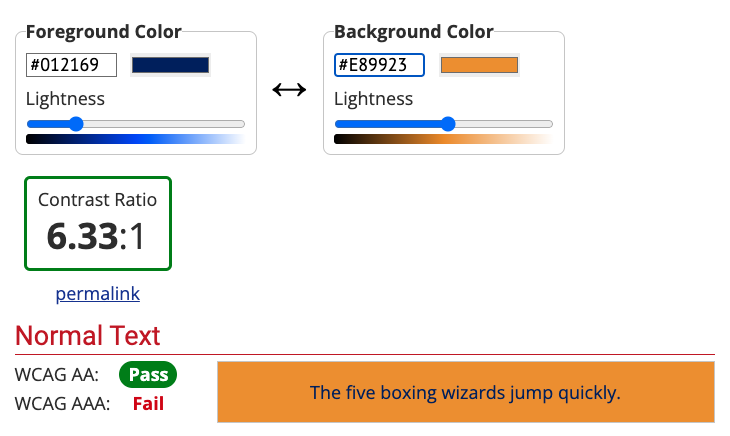
I frequently turned to these two web-based tools for quick tests of different color combinations. It was educational to see what did and didn’t work in various situations and think more about how aesthetic and design concerns interact with accessibility concerns.
While this color combo technically passes WCAG 2.0 AA and uses colors from the Duke Brand Guide, I probably won’t be using it any time soon
Style Guides
These style guides provided a handy reference for default and variant typography, color, and page design elements. I found the color palettes particular helpful as I tried to find creative solutions to color contrast problems while maintaining Duke branding and consistency across various Library pages.
Attempting to navigate our websites using only the TAB, ENTER, SPACE, UP, and DOWN keys on a standard computer keyboard gave me a better understanding of the significance of semantic markup, skip links, and landmarks. This test is essential for getting another “view” of your pages that isn’t as dependent on visual cues to convey meaning and structure and can help surface issues that automated accessibility scanners might miss.
Duke University Libraries (DUL) is recruiting two (2) Repository Services Analysts to ingest and help collaboratively manage content in their digital preservation systems and platforms. These positions will partner with the Research Data Curation, Digital Collections, and Scholarly Communications Programs, as well as other library and campus partners to provide digital curation and preservation services. The Repository Services Analyst role is an excellent early career opportunity for anyone who enjoys managing large sets of data and/or files, working with colleagues across an organization, preserving unique data and library collections, and learning new skills.
DUL will hold an open zoom session where prospective candidates can join anonymously and ask questions. This session will take place on Wednesday January 12 at 1pm EST; the link to join is posted on the libraries’ job advertisement.
The Research Data Curation Program has grown significantly in recent years, and DUL is seeking candidates who want to grow their skills in this area. DUL is a member of the Data Curation Network (DCN), which provides opportunities for cross-institutional collaboration, curation training, and hands-on data curation practice. These skills are essential for anyone who wants to pursue a career in research data curation.
Ideal Repository Services Analyst applicants have been exposed to digital asset management tools and techniques such as command line scripting. They can communicate functional system requirements between groups with varying types of expertise, enjoy working with varied kinds of data and collections, and love solving problems. Applicants should also be comfortable collaboratively managing a shared portfolio of digital curation services and projects, as the two positions work closely together. The successful candidates will join the Digital Collections and Curation Services department (within the Digital Strategies and Technology Division).
Please refer to the DUL’s job posting for position requirements and application instructions.
Quick—when was the last time you went a full day without using a Google product or service? How many years ago was that day?
We all know Google has permeated so many facets of our personal and professional lives. A lot of times, using a Google something-or-other is your organization’s best option to get a job done, given your available resources. If you ever searched the Duke Libraries website at any point over the past seventeen years, you were using Google.
It’s really no secret that when you have a website with a lot of pages, you need to provide a search box so people can actually find things. Even the earliest version of the library website known to the Wayback Machine–from “way back” in 1997–had a search box. Those days, search was powered by the in-house supported Texis Webinator. Google was yet to exist.
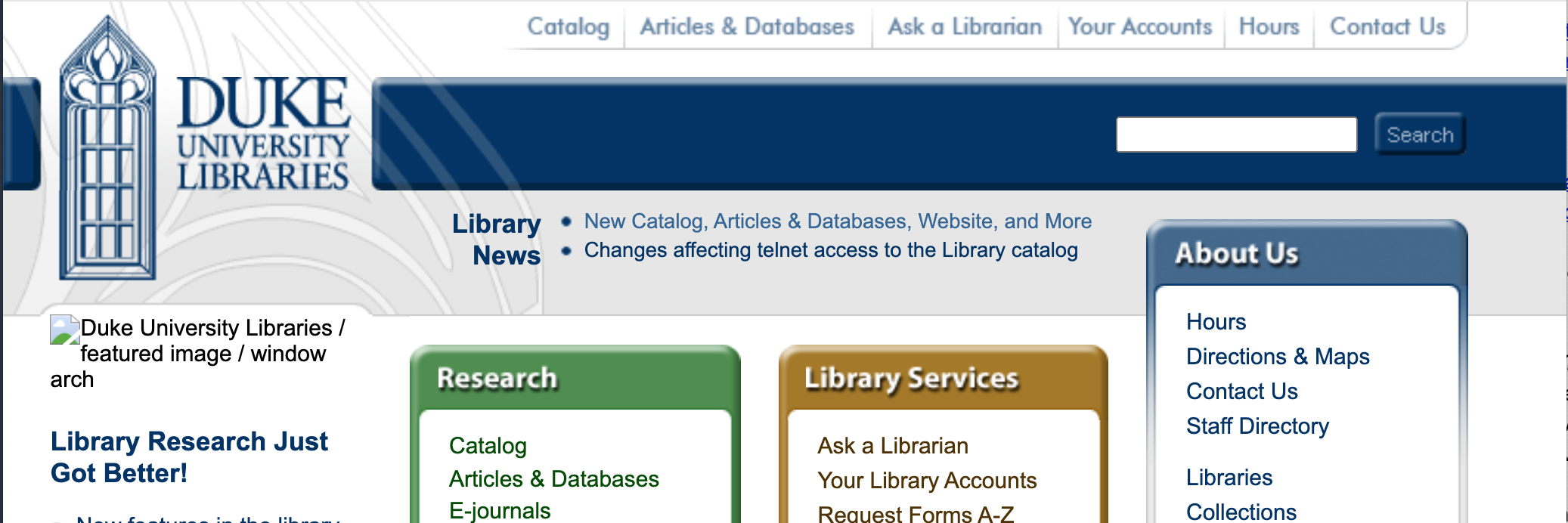
July 24, 2004 was an eventful day for the library IT staff. We went live with a shiny new Integrated Library System from Ex Libris called Aleph (that we are still to this day working to replace). On that very same day, we launched a new library website, and in the top-right corner of the masthead on that site was–for the very first time–a Google search box.
2004 version of the library website, with a Google search box in the masthead.
Years went by. We redesigned the website several times. Interface trends came and went. But one thing remained constant: there was a search box on the site, and if you used it, somewhere on the next page you were going to get search results from a Google index.
That all changed in summer 2021, when we implemented Nutch…
Why Not Google?
Google Programmable Search Engine (recently rebranded from “Google Custom Search Engine”), is easy to use. It’s “free.” It’s fast, familiar, and being a Google thing, it’s unbeatable at search relevancy. So why ditch it now? Well…
The results are capped at 100 per query. Google prioritizes speed and page 1 relevancy, but it won’t give you a precise hit count nor an exhaustive list of results.
It’s a black box. You don’t really get to see why pages get ranked higher or lower than others.
There’s a search API you could potentially build around, but if you exceed 100 searches/day, you have to start paying to use it.
What’s Nutch?
Apache Nutch is open source web crawler software written in Java. It’s been around for nearly 20 years–almost as long as Google. It supports out-of-the-box integration with Apache Solr for indexing.
Solr. Our IT staff have grown quite accustomed to the Solr search platform over the past decade; we already support around ten different applications that use it under the hood.
Self-Hosted. You run it yourself, so you’re in complete control of the data being crawled, collected, and indexed. User search data is not being collected by a third party like Google.
Configurable. You have a lot of control over how it works. All our configs are in a public code repository so we have record of what we have changed and why.
What are the Drawbacks to Using Nutch?
Maintenance. Using open source software requires a commitment of IT staff resources to build and maintain over time. It’s free, but it’s not really free.
Interface. Nutch doesn’t come with a user interface to actually use the indexed data from the crawls; you have to build a web application. Here’s ours.
Relevancy. Though Google considers such factors as page popularity and in-link counts to deem pages as more relevant than others for a particular query, Nutch can’t. Or, at least, its optional features that attempt to do so are flawed enough that not using them gets us better results. So we rely on other factors for our relevancy algorithm, like the segment of the site that a page resides, URL slugs, page titles, subheading text, inlink text, and more.
Documentation. Some open source platforms have really clear, easy to understand instruction manuals online to help you understand how to use them. Nutch is not one of those platforms.
How Does Nutch Work at Duke?
The main Duke University Libraries website is hosted in Drupal, where we manage around 1,500 webpages. But the full scope of what we crawl for library website searching is more than ten times that size. This includes pages from our blogs, LibGuides, exhibits, staff directory, and more. All told: 16,000 pages of content.
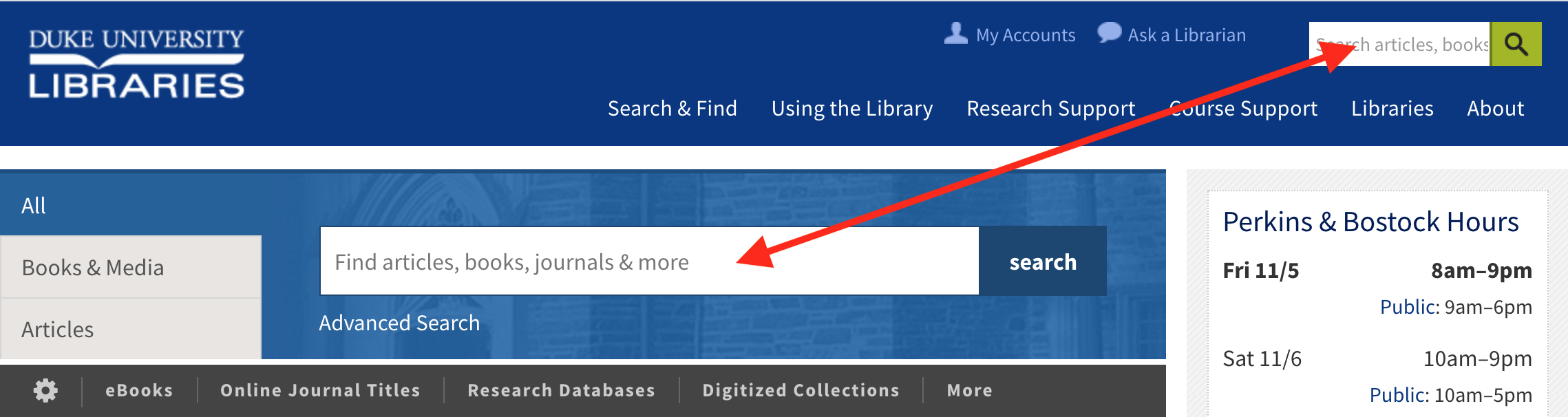
Searching from the website masthead or the default “All” box in the tabbed section on our homepage brings you to QuickSearch results page.
Use either of these search boxes to search QuickSearch.
You’ll see a search results page rendered by our QuickSearch app. It includes sections of results from various places, like articles, books & media, and more. One of the sections is “Our Website” — it shows the relevant pages that we’ve crawled with Nutch.
QuickSearch results page includes a section of results from “Our Website”
You can just search the website specifically if you’re not interested in all those other resources.
An example website-only search.
Three pieces work in concert to enable searching the website: Nutch, Solr, and QuickSearch. Here’s what they do:
Nutch
Crawls web pages that we want to include in the website search.
Parses HTML content; writes it to Solr fields.
Includes configuration for what pages to include/exclude, crawler settings, field mappings
Solr
Index & document store for crawled website content.
Includes configuration for determining relevancy; see parameters in website_searcher.rb
Crawls happen every night to pick up new pages and changes to existing ones. We use an “adaptive fetch schedule” so by default each page gets recrawled every 30 days. If a page changes frequently, it’ll get re-crawled sooner automatically.
Summary
Overall, we’re satisfied with how the switch to Nutch has been working out for us. The initial setup was challenging, but it has been running reliably without needing much in the way of developer intervention. Here’s hoping that continues!
Many thanks to Derrek Croney and Cory Lown for their help implementing Nutch at Duke, and to Kevin Beswick (NC State University Libraries) for consulting with our team.
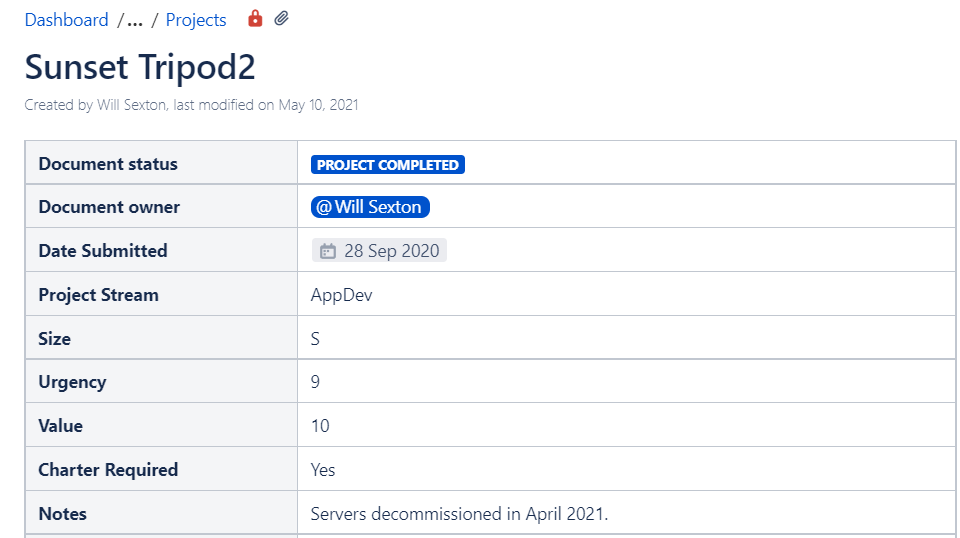
Featured image – screenshot from the Sunset Tripod2 project charter.
Realizing that my most recent post here went up more than a year ago, I pause to reflect. What even happened over these last twelve months? Pandemic and vaccine, election and insurrection, mandates and mayhem – outside of our work bubble, October 2020 to October 2021 has been a churn of unprecedented and often dark happenings. Bitstreams, however, broadcasts from inside the bubble, where we have modeled cooperation and productivity, met many milestones, and kept our collective cool, despite working nearly 100% remotely as a team, with our stakeholders, and across organizational lines.
Last October, I wrote about Sunsetting Tripod2, a homegrown platform for our digital collections and archival finding aids that was also the final service we had running on a physical server. “Firm plans,” I said we had for the work that remained. Still, in looking toward that setting sun, I worried about “all sorts of comical and embarrassing misestimations by myself on the pages of this very blog over the years.” I was optimistic, but cautiously so, that we would banish the ghosts of Django-based systems past.
Reader, I have returned to Bitstreams to tell you that we did it. Sometime in Q1 of 2021, we said so long, farewell, adieu to Tripod2. It was a good feeling, like when you get your laundry folded, or your teeth cleaned, only better.
However, we did more in the past year than just power down exhausted old servers. What follows are a few highlights from the work of the Digital Strategies and Technology division of Duke University Libraries’ software developers, and our collaborators (whom we cannot thank or praise enough) over the past twelve months.
In November, Digital Projects Developer Sean Aery posted on Implementing ArcLight: A Reflection. The work of replacing and improving upon our implementation for the Rubenstein Library’s collection guides was one of the main components that allowed us to turn off Tripod2. We actually completed it in July of 2020, but that team earned its Q4 victory laps, including Sean’s post and a session at Blacklight Summit a few days after my own post last October.
As the new year began, the MorphoSource team rolled out version 2.0 of that platform. MorphoSource Repository Developer Jocelyn Triplett shared a A Preview of MorphoSource 2 Beta in these pages on January 20. The launch took place on February 1.
After more than two years of work, we are happy to announce MorphoSource 2.0 is available! Includes color mesh and CT scan web previews, expanded metadata for non-CT modalities, and a greatly improved UI. Let us know what you think! https://t.co/D0zx9PDDE3
One project we had underway as I was writing last October was the integration of Globus, a transfer service for large datasets, into the Duke Research Data Repository. We completed that work in Q1 of 2021, prompting our colleague, Senior Research Data Management Consultant Sophia Lafferty-Hess, to post Share More Data in the Duke Research Data Repository! in a neighboring location that shares our charming cul-de-sac of library blogs.
The seventeen months since the murder of George Floyd have seen major changes in how we think and talk about race in the Libraries. We committed ourselves to the DUL Racial Justice Roadmap, a pathway for recognizing and attacking the pervasive influence of white supremacy in our society, in higher education, at Duke, in the field of librarianship, in our library, in the field of information technology, and in our own IT practices. During this time, members of our division have also participated broadly in DiversifyIT, a campus-wide group of IT professionals who seek to foster a culture of inclusion “by providing professional development, networking, and outreach opportunities.”
Digital Projects Developer Michael Daul shared his own point of view with great thoughtfulness in his April post, What does it mean to be an actively antiracist developer? He touched on representation in the IT industry, acknowledging bias, being aware of one’s own patterns of communication, and bringing these ideas to the systems we build and maintain.
One of the ideas that Michael identified for software development is web accessibility; as he wrote, we can “promote the benefits of building accessible interfaces that follow the practices of universal design.” We put that idea into action a few months later, as Sean described in precise technical terms in his July post, Automated Accessibility Testing and Continuous Integration. Currently that process applies to the ArcLight platform, but when we have a chance, we’ll see if we can expand it to other services.
The question of when we’ll have that chance is a big one, as it hinges on the undertaking that now dominates our attention. Over the past year we have ramped up on the migration of our website from Drupal 7 to Drupal 9, to head off the end-of-life for 7. This project has transformed into the raging beast that our colleagues at NC State Libraries warned us it would at the Code4Lib Southeast in May of 2019.
They warned us – Screenshot from “Drupal 7 to Drupal 8: Our Journey,” by Erik Olson and Meredith Wynn of NC State Libraries’ User Experience Department, presented at Code4Lib Southeast in May of 2019.
We are on a path to complete the Drupal migration in March 2022 – we have “firm plans,” you could say – and I’m certain that its various aspects will come to feature in Bitstreams in due time. For now I will mention that it spawned two sub-projects that have challenged our team over the past six months or so, both of which involve refactoring functionality previously implemented as Drupal modules into standalone Rails applications:
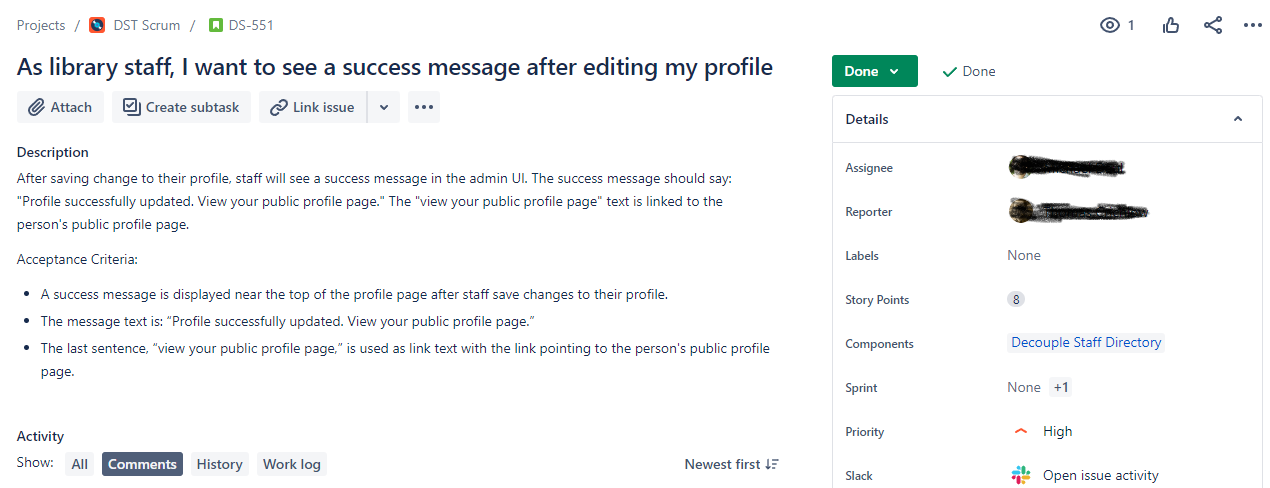
Quicksearch, aka unified search, aka “Bento search” – see Michael’s Bento is Coming! from 2014 – is now a standalone app; it also uses the open-source tool Apache Nutch, rather than Google CSE.
Each of these implementations was necessary to prepare the way for a massive migration of theme and content that will take place over the coming months.
Screenshot of a Jira issue related to the Decouple Staff Directory project.
When it’s done, maybe we’ll have a chance to catch our breath. Who can really say? I could not have guessed a year ago where we’d be now, and anyway, the period of the last twelve months gets my nod as the shortest year ever. Assuming we’re here, whatever “here” means in the age of remote/hybrid/flexible work arrangements, then I expect we’ll be burning down backlogs, refactoring this or that, deploying some service, and making firm plans for something grand.
Due to a battery issue with my work laptop (an Intel-based MacBook pro), I had an opportunity to try using a newer (ARM-based) M1 Mac to do development work. Since roughly a year had passed since these new machines had been introduced I assumed the kinks would have been generally worked out and I was excited to give my speedy new M1 Mac Mini a test run at some serious work. However, upon trying to do make some updates to a recent project (by the way, we launched our new staff directory!) I ran into many stumbling blocks.
M1 Mac Mini ensconced beneath multitudes of cables in my home office
My first step in starting with a new machine was to get my development environment setup. On my old laptop I’d typically use homebrew for managing packages and RVM (and previously rbenv) for ruby version management in different projects. I tried installing the tools normally and ran into multitudes of weirdness. Someguides suggested setting up a parallel version of homebrew (ibrew) using Rosetta (which is a translation layer for running Intel-native code). So I tried that – and then ran into all kinds of issues with managing Ruby versions. Oh and also apparently RVM / rbenv are no longer cool and you should be using chruby or asdf. So I tried those too, and ran into more problems. In the end, I stumbled on this amazing script by Moncef Belyamani. It was really simple to run and it just worked, plain and simple. Yay – working dev environment!
We’ve been using Docker extensively in our recent library projects over the past few years and the Staff Directory was setup to run inside a container on our local machines. So my next step was to get Docker up and running. The light research I’d done suggested that Docker was more or less working now with M1 macs so I dived in thinking things would go smoothly. I installed Docker Desktop (hopefully not a bad idea) and tried to build the project, but bundle install failed. The staff directory project is built in ruby on rails, and in this instance was using therubyracer gem, which embeds the V8 JS library. However, I learned that the particular version of the V8 library used by therubyracer is not compiled for ARM and breaks the build. And as you tend to do when running into questions like these, I went down a rabbit hole of potential work-arounds. I tried manually installing a different version of the V8 library and getting the bundle process to use that instead, but never quite got it working. I also explored using a different gem (like mini racer) that would correctly compile for ARM, or just using Node instead of V8, but neither was a good option for this project. So I was stuck.
Building the Staff Directory app in Docker
My text attempt at a solution was to try setting up a remote Docker host. I’ve got a file server at home running TrueNAS, so I was able to easily spin up a Ubuntu VM on that machine and setup Docker there. You could do something similar using Duke’s VCM service. I followedvarious guides, setup user accounts and permissions, generated ssh keys, and with some trial and error I was finally able to get things running correctly. You can setup a context for a Docker remote host and switch to it (something like: docker context use ubuntu), and then your subsequent Docker commands point to that remote making development work entirely seamless. It’s kind of amazing. And it worked great when testing with a hello-world app like whoami. Running docker run --rm -it -p 80:80 containous/whoami worked flawlessly. But anything that was more complicated, like running an app that used two containers as was the case with the Staff Dir app, seemed to break. So stuck again.
After consulting with a few of my brilliant colleagues, another option was suggested and this ended up being the best work around. Take my same ubuntu VM and instead of setting it up as a docker remote host, use it as the development server and setup a tunnel connection (something like: ssh -N -L localhost:8080:localhost:80 docker@ip.of.VM.machine) to it such that I would be able to view running webpages at localhost:8080. This approach requires the extra step of pushing code up to the git repository from the Mac and then pulling it back down on the VM, but that only takes a few extra keystrokes. And having a viable dev environment is well worth the hassle IMHO!
As apple moves away from Intel-based machines – rumors seem to indicate that the new MacBook Pros coming out this fall will be ARM-only – I think these development issues will start to be talked about more widely. And hopefully some smart people will be able to get everything working well with ARM. But in the meantime, running Docker on a Linux VM via a tunnel connection seems like a relatively painless way to ensure that more complicated Docker/Rails projects can be worked on locally using an M1 Mac.
This post was written by Miriam Shams-Rainey, a third-year undergraduate at Duke studying Computer Science and Linguistics with a minor in Arabic. As a student employee in the Rubenstein’s Technical Services Department in the Summer of 2021, Miriam helped build a tool to audit archival description in the Rubenstein for potentially harmful language. In this post, she summarizes her work on that project.
The Rubenstein Library has collections ranging across centuries. Its collections are massive and often contain rare manuscripts or one of a kind data. However, with this wide-ranging history often comes language that is dated, harmful, often racist, sexist, homophobic, and/or colonialist. As important as it is to find and remediate these instances of potentially harmful language, there is lot of data that must be searched.
With over 4,000 collection guides (finding aids) and roughly 12,000 catalog records describing archival collections, archivists would need to spend months of time combing their metadata to find harmful or problematic language before even starting to find ways to handle this language. That is, unless there was a way to optimize this workflow.
Working under Noah Huffman’s direction and the imperatives of the Duke Libraries’ Anti-Racist Roadmap, I developed a Python program capable of finding occurrences of potentially harmful language in library metadata and recording them for manual analysis and remediation. What would have taken months of work can now be done in a few button clicks and ten minutes of processing time. Moreover, the tools I have developed are accessible to any interested parties via a GitHub repository to modify or expand upon.
Although these gains in speed push metadata language remediation efforts at the Rubenstein forward significantly, a computer can only take this process so far; once uses of this language have been identified, the responsibility of determining the impact of the term in context falls onto archivists and the communities their work represents. To this end, I have also outlined categories of harmful language occurrences to act as a starting point for archivists to better understand the harmful narratives their data uphold and developed best practices to dismantle them.
Building an automated audit tool
The simple, yet user-friendly interface that allows archivists to customize the search audit to their specific needs.
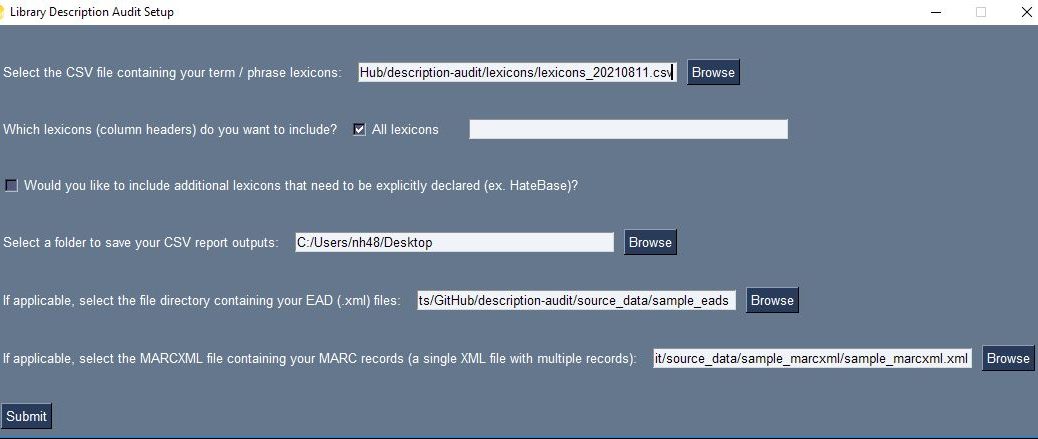
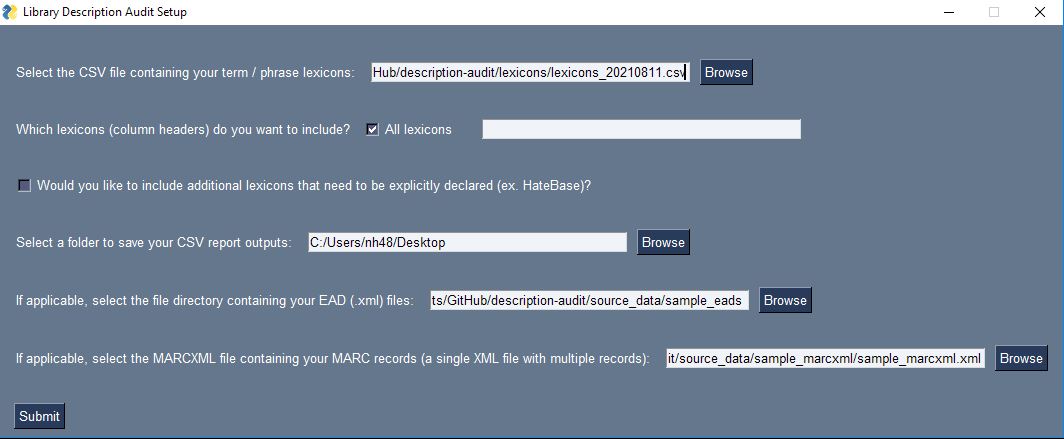
I created an executable that allows users to interact with the program regardless of their familiarity with Python or with using their computer’s command line. With an executable, all that a user must do is simply click on the program (titled “description_audit.exe”) and the script will load with all of its dependencies in a self-contained environment. There’s nothing that a user needs to install, not even Python.
Within this executable, I also created a user interface to allow users to set up the program with their specific audit parameters. To use this program, users should first create a CSV file (spreadsheet) containing each list of words they want to look for in their metadata.
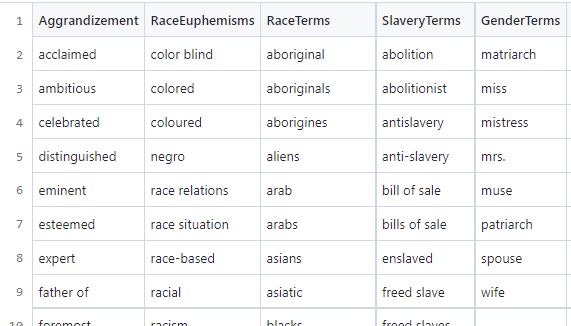
Snippet from a sample lexicon CSV file containing harmful terms to search
In this CSV file of “lexicons”, each category of terms should have its own column, for example RaceTerms could be the first row in a column of terms such as “colored” or “negro,” and GenderTerms could be the first row in a column of gendered terms such as “homemaker” or “wife.” See these lexicon CSV file examples.
Once this CSV has been created, users can select this CSV of lexicons in the program’s user interface and then select which columns of terms they want the program to use when searching across the source metadata. Users can either use all lexicon categories (all columns) by default or specify a subset by typing out those column headers. For the Rubenstein’s purposes, there is also a rather long lexicon called HateBase (from a regional, multilingual database of potential hate speech terms often used in online moderating) that is only enabled when a checkbox is checked; users from other institutions can download the HateBase lexicon for themselves and use it or they can simply ignore it.
In the CSV reports that are output by the program, matches for harmful terms and phrases will be tagged with the specific lexicon category the match came from, allowing users to filter results to certain categories of potentially harmful terms.
Users also need to designate a folder on their desktop where report outputs should be stored, along with the folder containing their source EAD records in .xml format and their source MARCXML file containing all of the MARC records they wish to process as a single XML file. Results from MARC and EAD records are reported separately, so only one type of record is required to use the program, however both can be provided in the same session.
How archival metadata is parsed and analyzed
Once users submit their input parameters in the GUI, the program begins by accessing the specified lexicons from the given CSV file. For each lexicon, a “rule” is created for a SpaCy rule-based matcher, using the column name (e.g. RaceTerms or GenderTerms) as the name of the specific rule. The same SpaCy matcher object identifies matches to each of the several lexicons or “rules”. Once the matcher has been configured, the program assesses whether valid MARC or EAD records were given and starts reading in their data.
To access important pieces of data from each of these records, I used a Python library called BeautifulSoup to parse the XML files. For each individual record, the program parses the call numbers and collection or entry name so that information can be included in the CSV reports. For EAD records, the collection title and component titles are also parsed to be analyzed for matches to the lexicons, along with any data that is in a paragraph (<p>) tag. For MARC records, the program also parses the author or creator of the item, the extent of the collection, and the timestamp of when the description of the item was last updated. In each MARC record, the 520 field (summary) and 545 field (biography/history note) are all concatenated together and analyzed as a single entity.
Data from each record is stored in a Python dictionary with the names of fields (as strings) as keys mapping to the collection title, call number, etc. Each of these dictionaries is stored in a list, with a separate structure for EAD and MARC records.
Once data has been parsed and stored, each record is checked for matches to the given lexicons using the SpaCy rule-based matcher. For each record, any matches that are found are then stored in the dictionary with the matching term, the context of the term (the entire field or surrounding few sentences, depending on length), and the rule the term matches (such as RaceTerms). These matches are found using simple tokenization from SpaCy that allow matches to be identified quickly and without regard for punctuation, capitalization, etc.
Although this process doesn’t necessarily use the cutting-edge of natural language processing that the SpaCy library makes accessible, this process is adaptable in ways that matching procedures like using regular expressions often isn’t. Moreover, identifying and remedying harmful language is a fundamentally human process which, at the end of the day, needs a significant level of input both from historically marginalized communities and from archivists.
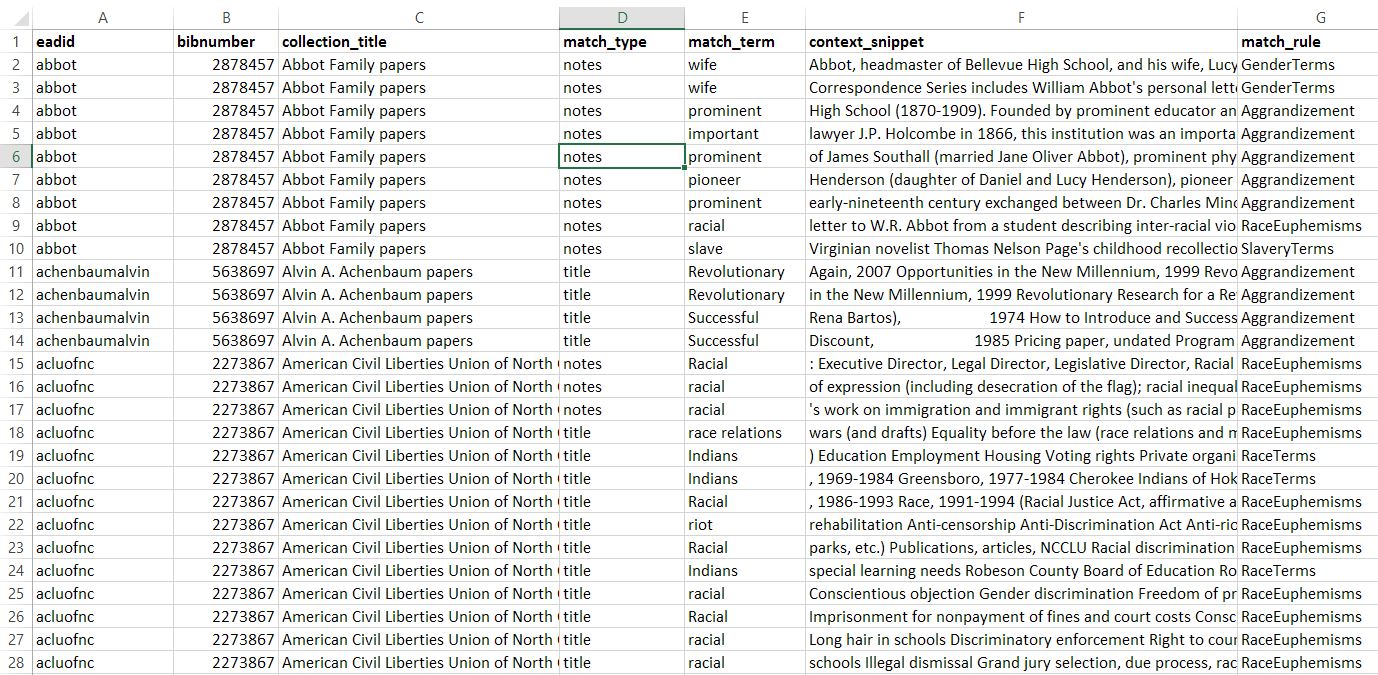
Matches to any of the lexicons, along with all other associated data (the record’s call number, title, etc.) are then written into CSV files for further analysis and further categorization by users. You can see sample CSV audit reports here. The second phase of manual categorization is still a lengthy process, yielding roughly 14600 matches from the Rubenstein Library’s EAD data and 4600 from its MARC data which must still be read through and analyzed by hand, but the process of identifying these matches has been computerized to take a mere ten minutes, where it could otherwise be a months-long process.
Categorizing matches: an archivist and community effort
An excerpt of initial data returned by the audit program for EAD records. This data should be further categorized manually to ensure a comprehensive and nuanced understanding of these instances of potentially harmful language.
To better understand these matches and create a strategy to remediate the harmful language they represent, it is important to consider each match in several different facets.
Looking at the context provided with each match allows archivists to understand the way in which the term was used. The remediation strategy for the use of a potentially harmful term in a proper noun used as a positive, self-identifying term, such as the National Association for the Advancement of Colored People, for example, is vastly different from that of a white person using the word “colored” as a racist insult.
The three ways in which I proposed we evaluate context are as follows:
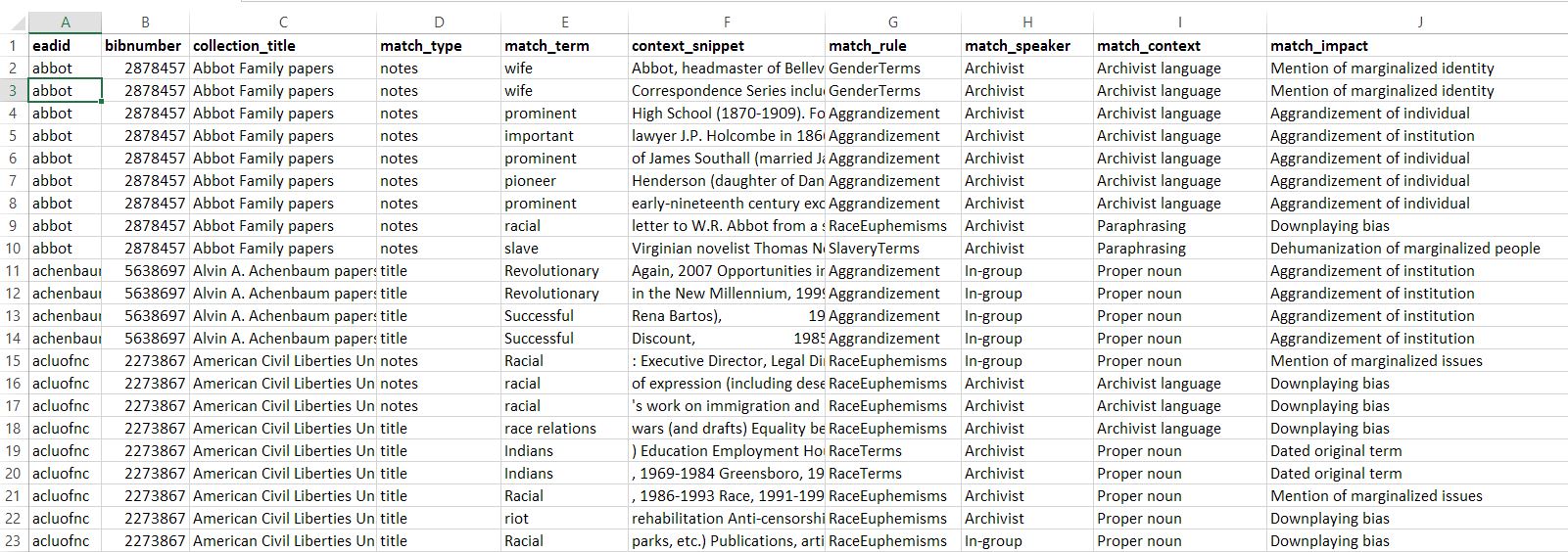
Match speaker: who was using the term? Was the sensitive term being used as a form of self-identification or reclaiming by members of a marginalized group, was it being used by an archivist, or was it used by someone with privilege over the marginalized group the term targets (e.g. a white person using an anti-Black term or a cisgender straight person using an anti-LGBTQ+ term)? Within this category, I proposed three potential categories for uses of a term: in-group, out-group, and archivist. If a term is used by a member (or members) of the identity group it references, its use is considered an in-group use. If the term is used by someone who is not a member of the identity group the term references, that usage of the term is considered out-group. Paraphrasing or dated term use by archivists is designated simply as archivist use.
Match context: how was the term in question being used? Modifying the text used in a direct quote or a proper noun constitutes a far greater liberty by the archivist than removing a paraphrased section or completely archivist-written section of text that involved harmful language. Although this category is likely to evolve as more matches are categorized, my initial proposed categories are: proper noun, direct quote, paraphrasing, and archivist narrative.
Match impact: what was the impact of the term? Was this instance a false positive, wherein the use of the term was in a completely unrelated and innocuous context (e.g. the use of the word “colored” to describe the colors used in visual media), or was the use of the term in fact harmful? Was the use of the term derogatory, or was it merely a mention of politicized identities? In many ways, determining the impact of a particular term or use of potentially harmful language is a community effort; if a community member with a marginalized identity says that the use of a term in that particular context is harmful to people with that identity, archivists are in no position to disagree or invalidate those feelings and experiences. The categories that I’ve laid out initially–dated original term, dated Rubenstein term, mention of marginalized issues, mention of marginalized identity, downplaying bias (e.g. calling racism and discrimination an issue with “race relations”), dehumanization of marginalized people, false positive–only hope to serve as an entry point and rudimentary categorization of these nuances to begin this process.
Categorizing each of these instances of potentially harmful language remains a time-consuming, meticulous process. Although much of this work can be computerized, decolonization is a fundamentally human and fundamentally community-centered practice. No computer can dismantle the colonial, white supremacist narratives that archival work often upholds. This work requires our full attention and, for better or for worse, a lot of time, even with the productivity boost technology gives us.
Once categories have been established, at least on a preliminary level, I found that about 100-200 instances of potentially harmful language could be manually parsed and categorized in an hour.
Conclusion
Decolonization and anti-racist efforts in archival work are an ongoing process. It is bound to take active learning, reflection, and lots of remediation. However, using technology to start this process creates a much less daunting entry point. Anti-racism work is essential in archival spaces.
The ways we talk about history can either work to uphold traditional white supremacist, racist, ableist, etc. narratives, or they can work to dismantle them. In many ways, archival work has often upheld these narratives in the past, however this audit represents the sincere beginnings of work to further equitable narratives in the future.
Back in the summer of 2018, calls for applications for the National Web Privacy Forum started circulating around the library community. I’ll be honest — at that point I knew almost nothing about how libraries protect patron privacy. That summer I’d been conducting a library data inventory, interviewing stakeholders of various data systems across the library, and I had just gotten my first hints of some of the processes we use to protect the data we collect from patrons.
Long story short, Duke Libraries submitted an application to the Forum, we were selected, and I attended. The experience was really meaningful, and it gave me a nice overview of the various issues that affect a library’s ability to protect patron privacy. The following spring (2019), the leaders of the National Forum released an action handbook that recommended conducting a data privacy audit, and DUL undertook such an audit during the Fall of 2019. The results of that audit suggested that we still have a bit of work to do to make sure all of our systems are working together to protect our patrons.
Forming a task force
In response to the audit report, Duke Libraries charged a task force called the Data Privacy and Retention Task Force. Despite the pandemic and lockdown, this task force started meeting in the spring of 2020, and we met biweekly for the rest of the year. Our goals were to develop guiding principles and priorities around data privacy and retention, as well as to recommend specific project work that should be undertaken to improve our systems.
The task force included staff members from across the various divisions of the library. Pretty quickly, we determined that we all come with different experiences around patron privacy. We decided to begin with a sort of book club, identifying and reviewing introductory materials related to different components of patron privacy, from web analytics to the GDPR to privacy in archives and special collections. Once we all felt a bit more knowledgeable, we turned our attention to creating a statement of our priorities and principles.
Defining our values
There are a lot of existing statements of library values, and many make mention of patron privacy. Other documents that cover privacy values include regulatory documents and organizational privacy statements. Some of the statements we reviewed include:
While these statements are all relevant, the task force found some of them far too general to truly guide action for an organization. We were looking to create a document that outlined more specifics, helped us make decisions about how to organize our work. At Duke Libraries, we already have one document we use to organize our work and make decisions — our strategic plan.
When we reviewed the strategic plan, we noticed that for each section of the plan, a focus on patron privacy resulted in a set of implications for our work. To express these implications, we devised a rough hierarchy of directed action, indicating our ability and obligation to undertake certain actions. We use the following terms in our final report:
For actions within our sphere of influence:
obligation: DUL should devote significant time and resources toward this work
responsibility: DUL should make a concerted effort toward this work, but the work may not receive the same attention and resources as that devoted to our obligations
For actions outside our sphere of influence:
commitment: DUL will need to partner with other groups to perform this work and thus cannot promise to accomplish all tasks
An example of our principles and priorities
One section from our strategic plan is Strategic Priority #2: Our Libraries Teach and Support Emerging Literacies. Within this priority, the strategic plan identifies the following goals:
Expand the presence of library staff in the student experience in order to understand and support emerging scholarship, information, data, and literacy needs
Mentor first-year students in scholarly research and learning practices, embracing and building upon their diverse backgrounds, prior knowledge, literacies, and expectations as they begin their Duke experience.
Partner with faculty to develop research methods, curricula, and collaborative projects connecting their courses to our collections.
Enhance the library instruction curriculum, focusing on standards and best practices for pedagogy that will prepare users for lifelong learning in a global and ever-changing research environment.
We have an obligation to communicate in plain language what data we and our partners collect while providing our services.
We have a responsibility to provide education, tools, and collection materials to shed light on the general processes of information exchange behind technology systems.
We commit to partnering with researchers seeking to understand the effects of information exchange processes and related policy interventions.
We now have the strategic plan, which outlines types of activities we might undertake, and the new report on protecting patron privacy, which adds to that list new activities and methods to achieve patron privacy protections in each area.
Next steps
The final work of the task force was to propose new project work based on our identified priorities and principles. The task force will share a list of recommended projects with library administration, who will start the hard work of evaluating these projects and identifying staff to undertake them. In the meantime, we hope the report will offer immediate guidance to staff for considerations they should be taking in different areas of their work, as well as serving as a model for future documents that guide our efforts.
One of our favorite accessibility checking tools in our toolbox is the axe DevTools Browser Extension by Deque Systems. It’s easy to use, whether on a live site, or in our own local development environments while we’re working on building new features for our applications. Simply open your browser’s Developer Tools (F12), click the Scan button, and get an instant report of any violations, complete with recommendations about how to fix them.
An axe DevTools test result for our archival finding aids homepage.
Keeping a website compliant is a continuous effort. Websites are living things. Content changes, features are added. When a site becomes compliant it does not stay compliant.
One of the goals we set out to accomplish in 2021 was to figure out how to add automated, continuous accessibility testing for our ArcLight software, which powers our archival finding aids search and discovery application. We got it implemented successfully a few months ago and we’re pleased with how it has been working so far.
Let me back up a bit and give some background on the concepts and tools upon which this solution depends. Namely: Continuous Integration, RSpec, Capybara, Selenium, and Docker.
Continuous Integration
For any given software project, we may have several developers making multiple changes to a shared codebase in the same day. Continuous Integration is the practice of ensuring that these code changes 1) don’t break any existing functionality, and 2) comply with established guidelines for code quality.
Evidence of a GitLab CI pipeline that has run — and passed all stages — for a code change.
For accessibility testing, we knew we needed to add something to our existing CI pipeline that would check for compliance and flag any issues.
RSpec Testing Framework
Many of our applications are built using Ruby on Rails. We write tests for our code using RSpec, a popular testing framework for Rails applications. Developers write tests (using the framework’s DSL / domain-specific language) to accompany their code changes. Those tests all execute as part of our CI pipeline (see above). Any failing tests will prevent code from being merged or getting deployed to production.
There are many different types of tests. On one end of the spectrum, there are “unit tests,” which verify that one small piece of code (e.g., one method) returns what we expect it to when it is given different inputs. On the other, there are “feature tests,” which typically verify that several pieces of code are working together as intended in different conditions. This often simulates the use of a feature by a person (e.g., when a user clicks this button, test that they get to this page and verify this link gets rendered, etc.). Feature tests might alternatively be called “integration tests,” “acceptance tests,” or even “system tests” — the terminology is both squishy and evolving.
At any rate, accessibility testing is a specific kind of feature test.
Capybara
On its own, RSpec unfortunately doesn’t natively support feature tests. It requires a companion piece of software called Capybara, which can simulate a user interacting with a web interface. Capybara brings with it a DSL to visit pages, fill out forms, or click on elements within RSpec tests, and special matchers to check that the page is behaving as intended.
Homepage for Capybara, featuring an actual capybara.
When configuring Capybara, you set up the driver you want it to use when running different kinds of tests. Its default driver is RackTest, which is fast but it can’t execute JavaScript like a real web browser can. Our ArcLight UI, for instance, uses a bunch of JavaScript. So we knew that any accessibility tests would have to be performed using a driver for an actual browser; the default Capybara alone wouldn’t cut it.
Documentation for Selenium WebDriver for browser automation
The best way we could find to get Capybara to control a real browser in an RSpec test was to add the selenium-webdriver gem to our project’s Gemfile.
Docker
Over the past few years, we have evolved our DevOps practice and embraced containerizing our applications using Docker. Complex applications that have a lot of interwoven infrastructure dependencies used to be quite onerous to build, run, and share. Getting one’s local development environment into shape to successfully run an application used be a whole-day affair. Worse still, the infrastructure on the production server used to bear little resemblance to what developers were working with on their local machines.
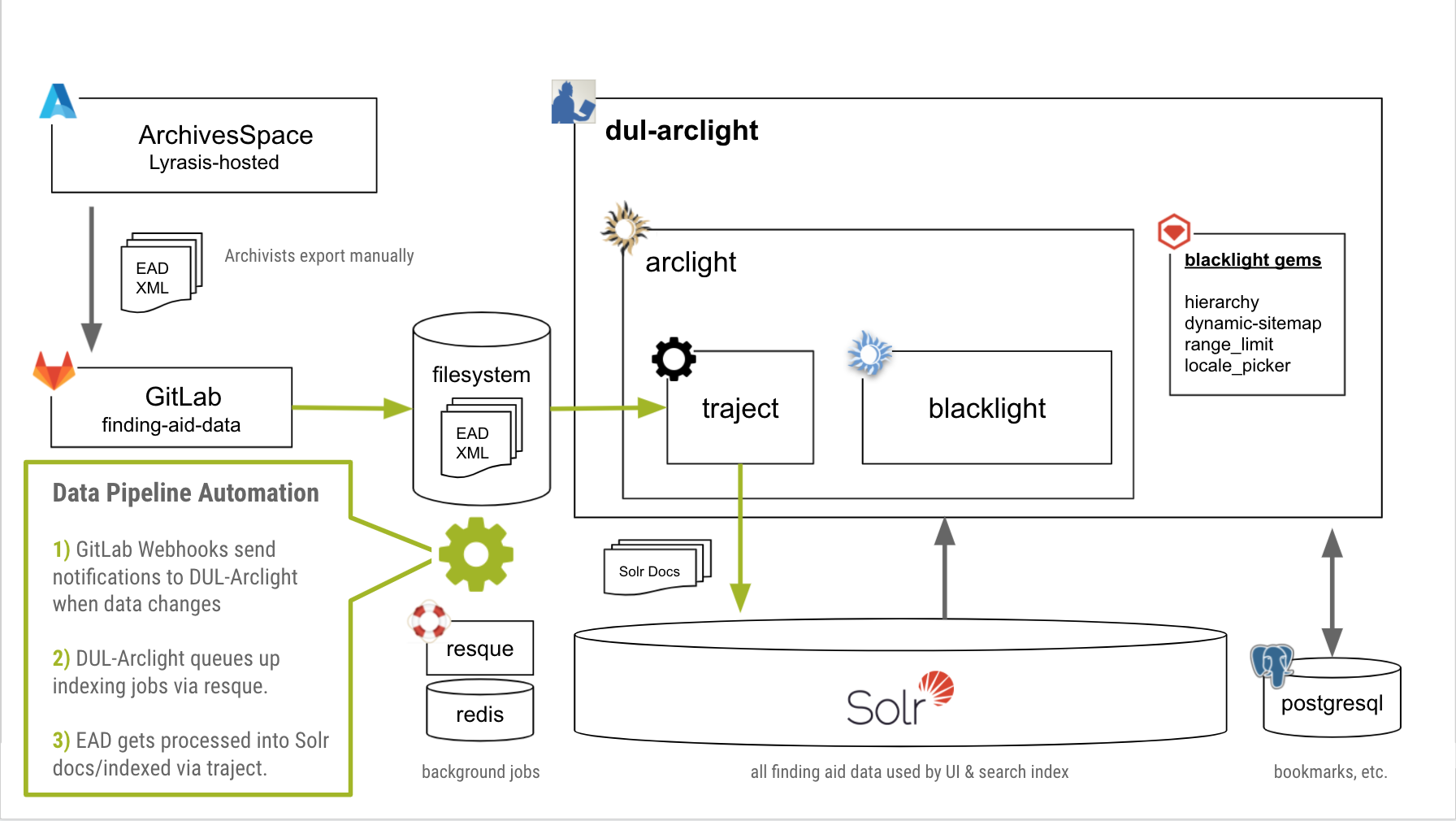
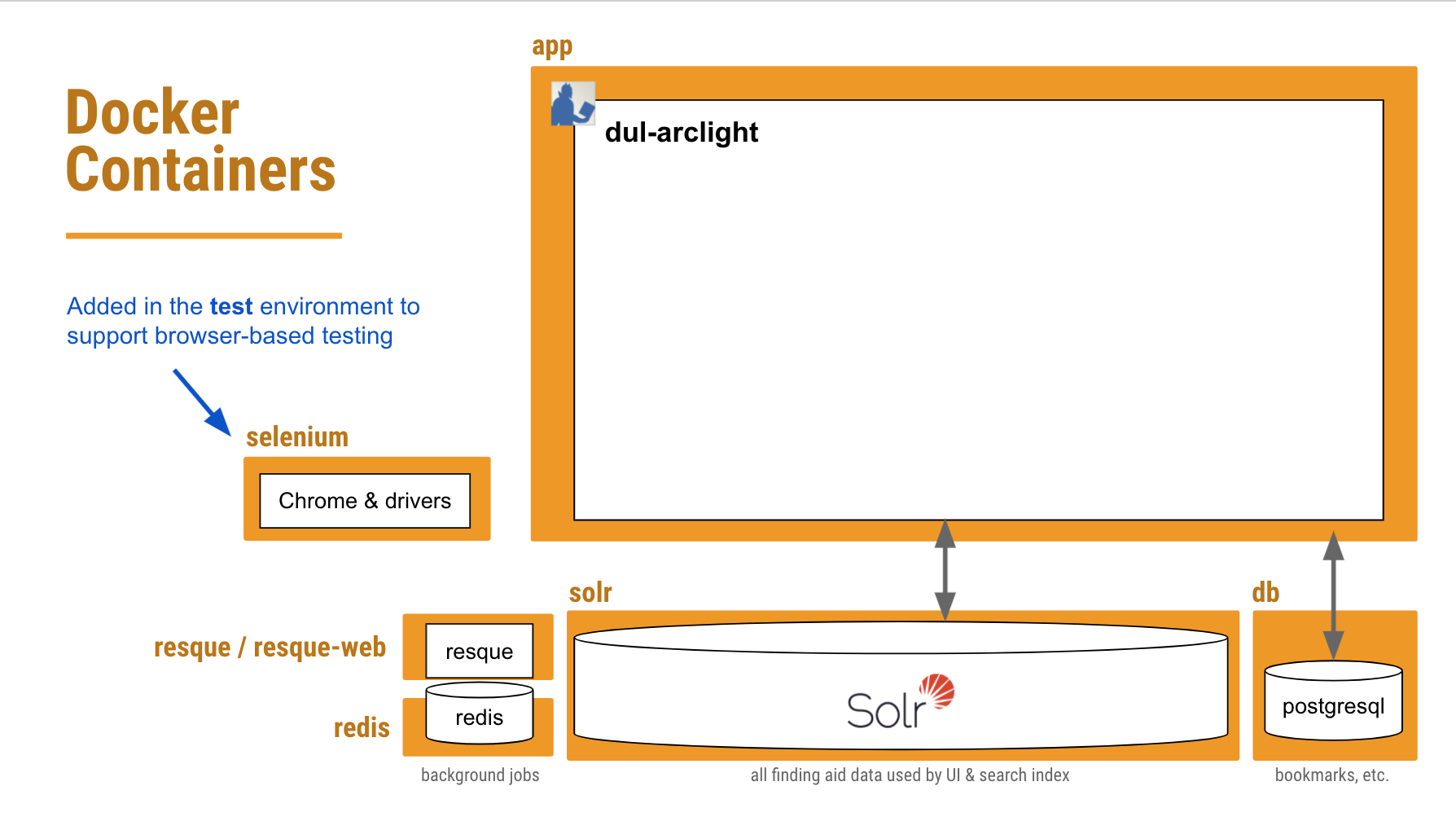
A systems diagram depicting the various services that run to support our ArcLight app.
Docker helps a dev team configure in their codebase all of these system dependencies in a way that that’s easily reproducible in any environment. It builds a network of “containers” on a single host, each running a service that’s crucial to the application. Now a developer can simply check out the code, run a couple commands, wait a few minutes, and they’re good to go.
The same basic setup also applies in a production environment (with a few easily-configurable differences). And that simplicity also carries over to the CI environment where the test suite will run.
Orange boxes depict each service / container we have defined in our Docker configuration.
So what we needed to do was add another container to our existing Docker configuration that would be dedicated to running any JavaScript-dependent feature tests — including accessibility tests — in a browser controlled by Selenium WebDriver.
Keeping this part containerized would hopefully ensure that when a developer runs the tests in their local environment, the exact same browser version and drivers get used in the CI pipeline. We can steer clear of any “well, it worked on my machine” issues.
Putting it All Together
Phew. OK, with all of that background out of the way, let’s look closer at how we put all of these puzzle pieces together.
The folks at Selenium HQ host “standalone” browser Docker images in Docker Hub, complete with the browser software and accompanying drivers. We found a tagged version of their Standalone Chrome image that worked well, and pull that into our newly-defined “selenium” container for our test environments.
Since this is new territory for us, and already fairly complex, we’re starting with just one browser: Chrome. We may be able to add more in the future.
Capybara Driver Configuration
Next thing we needed to do was tell Capybara that whenever it encounters any javascript-dependent feature tests, it should run them in our standalone Chrome container (using a “remote” driver). The Selenium WebDriver gem lets us set some options for how we want Chrome to run.
The key setting here is “headless” — that is, run Chrome, but more efficiently, without all the fancy GUI stuff that a real user might see.
That last URL http://selenium:4444/wd/hub is the location of our Chrome driver within our selenium container.
There are a few other important Capybara settings configured in spec_helper.rbthat are needed in order to get our app and seleniumcontainers to play nicely together.
Capybara.server=:puma,{Threads:'1:1'}Capybara.server_port='3002'Capybara.server_host='0.0.0.0'Capybara.app_host="http://app:#{Capybara.server_port}"Capybara.always_include_port=trueCapybara.default_max_wait_time=30# our ajax responses are sometimes slowCapybara.enable_aria_label=true
[...]
The server_port, server_host and app_host variables are the keys here. Basically, we’re saying:
Capybara (which runs in our app container) should start up Puma to run the test app, listening on http://0.0.0.0:3002 for requests beyond the current host during a test.
The selenium container (where the Chrome browser resides) should access the application under test at http://app:3002 (since it’s in the app container).
Some Actual RSpec Accessibility Tests
Here’s the fun part, where we actually get to write the accessibility tests. The axe-core-rspec gem makes it a breeze. The be_axe_clean matcher ensures that if we have a WCAG 2.0 AA or Section 508 violation, it’ll trip the wire and report a failing test.
require'spec_helper'require'axe-rspec'RSpec.describe'Accessibility (WCAG, 508, Best Practices)',type: :feature,js: true,accessibility: truedodescribe'homepage'doit'is accessible'dovisit'/'expect(page).tobe_axe_cleanendend
[...]
end
With type: :feature and js: true we signal to RSpec that this block of tests should be handled by Capybara and must be run in our headless Chrome Selenium container.
The example above is the simplest case: 1) visit the homepage and 2) do an Axe check. We also make sure to test several different kinds of pages, and with some different variations on UI interactions. E.g., test after clicking to open the Advanced Search modal.
The CI Pipeline
We started out having accessibility tests run along with all our other RSpec tests during the test stage in our GitLab CI pipeline. But we eventually determined it was better to keep accessibility tests isolated in a separate job, one that would not block a code merge or deployment in the event of a failure. We use the accessibility: true tag in our RSpec accessibility test blocks (see the above example) to distinguish them from other feature tests.
No, we don’t condone pushing inaccessible code to production! It’s just that we sometimes get false positives — violations are reported where there are none — particularly in Javascript-heavy pages. There are likely some timing issues there that we’ll work to refine with more configuration.
A Successful Accessibility Test
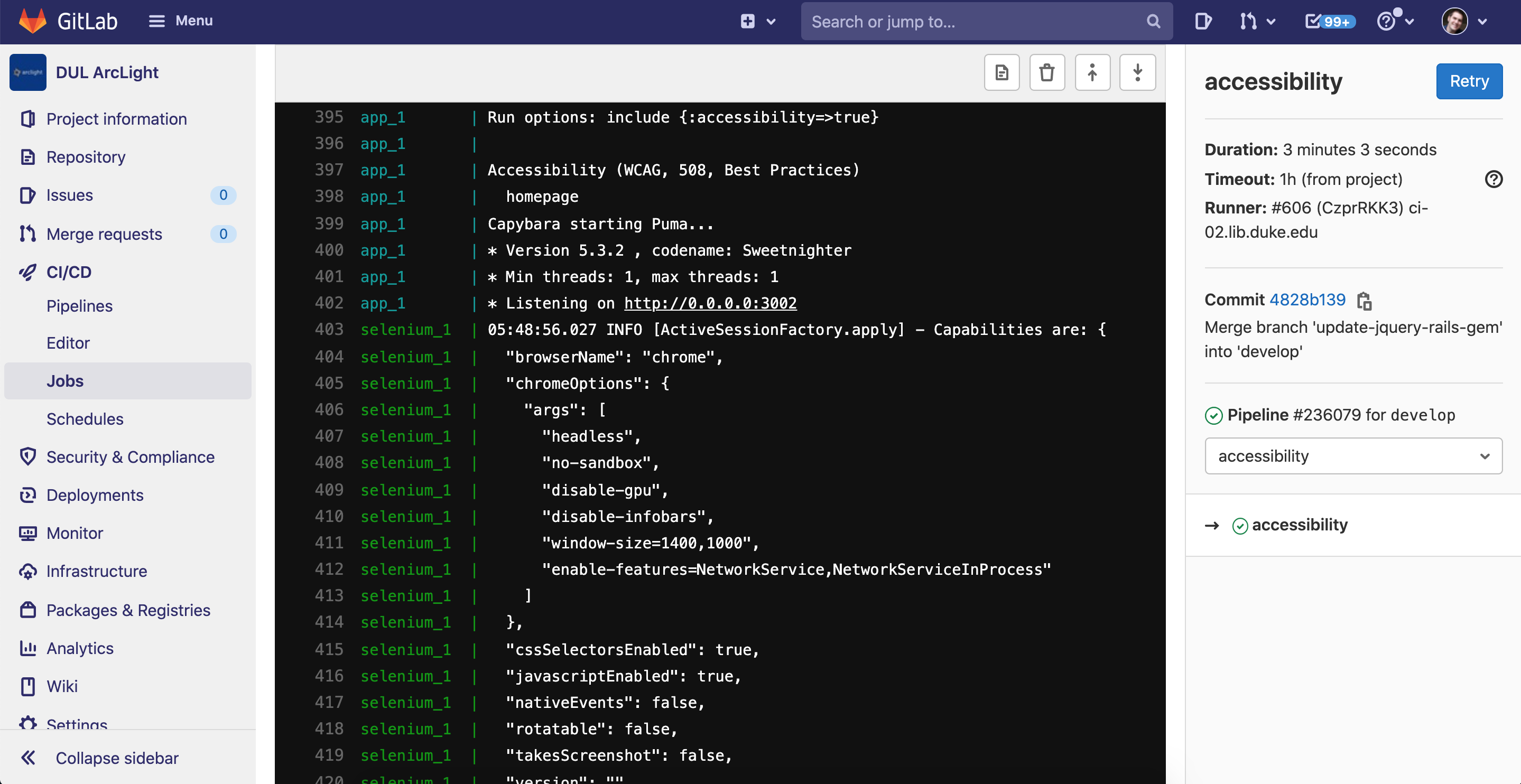
Here’s a completed job in our CI pipeline logs where the accessibility tests all passed:
Output from a successful automated accessibility test job run in a GitLab CI pipeline.
Our GitLab CI logs are not publicly available, so here’s a brief snippet from a successful test.
An Accessibility Test With Failures
Here’s a CI pipeline for a code branch that adds two buttons to the homepage with color contrast and aria-label violations. The axe tests flag the issues as FAILED and recommend revisions (see snippet from the logs).
Concluding Thoughts
Automation and accessibility testing are both rapidly evolving areas, and the setup that’s working for our ArcLight app today might look considerably different within the next several months. Still, I thought it’d be useful to pause and reflect on the steps we took to get automated accessibility testing up and running. This strategy would be reasonably reproducible for many other applications we support.
A lot of what I have outlined could also be accomplished with variations in tooling. Don’t use GitLab CI? No problem — just substitute your own CI platform. The five most important takeaways here are:
Accessibility testing is important to do, continually
Use continuous integration to automate testing that used to be manual
Containerizing helps streamline continuous integration, including testing
You can run automated browser-based tests in a ready-made container
Deque’s open source Axe testing tools are easy to use and pluggable into your existing test framework
Many thanks to David Chandek-Stark (Duke) for architecting a large portion of this work. Thanks also to Simon Choy (Duke), Dann Bohn (Penn St.), and Adam Wead (Penn St.) for their assistance helping us troubleshoot and understand how these pieces fit together.
REVISION 7/29/21: This post was updated, adding links to snippets from CI logs that demonstrate successful accessibility tests vs. those that reveal violations.
Notes from the Duke University Libraries Digital Projects Team