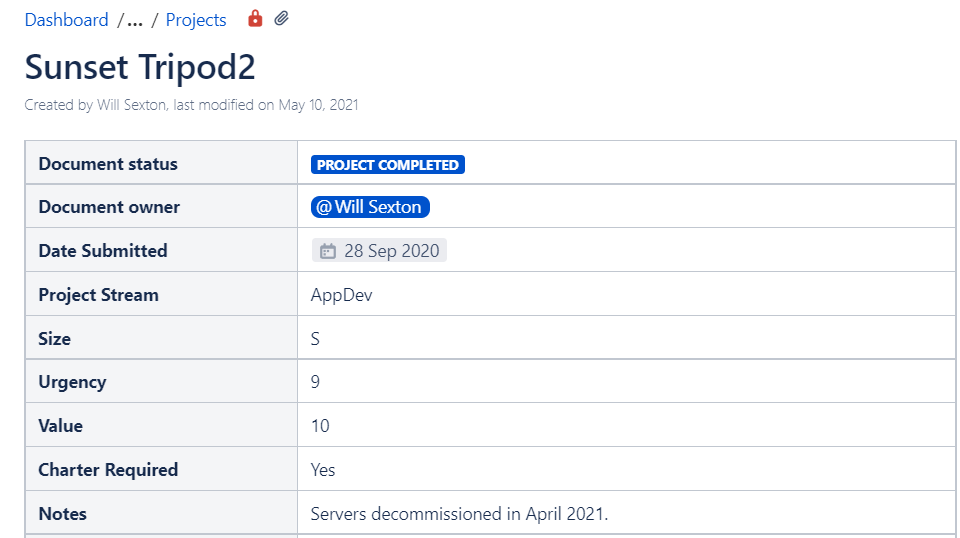
Featured image – screenshot from the Sunset Tripod2 project charter.
Realizing that my most recent post here went up more than a year ago, I pause to reflect. What even happened over these last twelve months? Pandemic and vaccine, election and insurrection, mandates and mayhem – outside of our work bubble, October 2020 to October 2021 has been a churn of unprecedented and often dark happenings. Bitstreams, however, broadcasts from inside the bubble, where we have modeled cooperation and productivity, met many milestones, and kept our collective cool, despite working nearly 100% remotely as a team, with our stakeholders, and across organizational lines.
Last October, I wrote about Sunsetting Tripod2, a homegrown platform for our digital collections and archival finding aids that was also the final service we had running on a physical server. “Firm plans,” I said we had for the work that remained. Still, in looking toward that setting sun, I worried about “all sorts of comical and embarrassing misestimations by myself on the pages of this very blog over the years.” I was optimistic, but cautiously so, that we would banish the ghosts of Django-based systems past.
Reader, I have returned to Bitstreams to tell you that we did it. Sometime in Q1 of 2021, we said so long, farewell, adieu to Tripod2. It was a good feeling, like when you get your laundry folded, or your teeth cleaned, only better.
However, we did more in the past year than just power down exhausted old servers. What follows are a few highlights from the work of the Digital Strategies and Technology division of Duke University Libraries’ software developers, and our collaborators (whom we cannot thank or praise enough) over the past twelve months.
In November, Digital Projects Developer Sean Aery posted on Implementing ArcLight: A Reflection. The work of replacing and improving upon our implementation for the Rubenstein Library’s collection guides was one of the main components that allowed us to turn off Tripod2. We actually completed it in July of 2020, but that team earned its Q4 victory laps, including Sean’s post and a session at Blacklight Summit a few days after my own post last October.
As the new year began, the MorphoSource team rolled out version 2.0 of that platform. MorphoSource Repository Developer Jocelyn Triplett shared a A Preview of MorphoSource 2 Beta in these pages on January 20. The launch took place on February 1.
After more than two years of work, we are happy to announce MorphoSource 2.0 is available! Includes color mesh and CT scan web previews, expanded metadata for non-CT modalities, and a greatly improved UI. Let us know what you think! https://t.co/D0zx9PDDE3
— MorphoSource (@MorphoSource) February 1, 2021
One project we had underway as I was writing last October was the integration of Globus, a transfer service for large datasets, into the Duke Research Data Repository. We completed that work in Q1 of 2021, prompting our colleague, Senior Research Data Management Consultant Sophia Lafferty-Hess, to post Share More Data in the Duke Research Data Repository! in a neighboring location that shares our charming cul-de-sac of library blogs.
The seventeen months since the murder of George Floyd have seen major changes in how we think and talk about race in the Libraries. We committed ourselves to the DUL Racial Justice Roadmap, a pathway for recognizing and attacking the pervasive influence of white supremacy in our society, in higher education, at Duke, in the field of librarianship, in our library, in the field of information technology, and in our own IT practices. During this time, members of our division have also participated broadly in DiversifyIT, a campus-wide group of IT professionals who seek to foster a culture of inclusion “by providing professional development, networking, and outreach opportunities.”
Digital Projects Developer Michael Daul shared his own point of view with great thoughtfulness in his April post, What does it mean to be an actively antiracist developer? He touched on representation in the IT industry, acknowledging bias, being aware of one’s own patterns of communication, and bringing these ideas to the systems we build and maintain.
One of the ideas that Michael identified for software development is web accessibility; as he wrote, we can “promote the benefits of building accessible interfaces that follow the practices of universal design.” We put that idea into action a few months later, as Sean described in precise technical terms in his July post, Automated Accessibility Testing and Continuous Integration. Currently that process applies to the ArcLight platform, but when we have a chance, we’ll see if we can expand it to other services.
The question of when we’ll have that chance is a big one, as it hinges on the undertaking that now dominates our attention. Over the past year we have ramped up on the migration of our website from Drupal 7 to Drupal 9, to head off the end-of-life for 7. This project has transformed into the raging beast that our colleagues at NC State Libraries warned us it would at the Code4Lib Southeast in May of 2019.

We are on a path to complete the Drupal migration in March 2022 – we have “firm plans,” you could say – and I’m certain that its various aspects will come to feature in Bitstreams in due time. For now I will mention that it spawned two sub-projects that have challenged our team over the past six months or so, both of which involve refactoring functionality previously implemented as Drupal modules into standalone Rails applications:
- Quicksearch, aka unified search, aka “Bento search” – see Michael’s Bento is Coming! from 2014 – is now a standalone app; it also uses the open-source tool Apache Nutch, rather than Google CSE.
- The staff directory app that went live in 2019, which Michael wrote about in Building a new Staff Directory, also no longer runs as a Drupal module.
Each of these implementations was necessary to prepare the way for a massive migration of theme and content that will take place over the coming months.
When it’s done, maybe we’ll have a chance to catch our breath. Who can really say? I could not have guessed a year ago where we’d be now, and anyway, the period of the last twelve months gets my nod as the shortest year ever. Assuming we’re here, whatever “here” means in the age of remote/hybrid/flexible work arrangements, then I expect we’ll be burning down backlogs, refactoring this or that, deploying some service, and making firm plans for something grand.