Over the past couple of years I’ve written on this blog about the kinds of initiatives libraries are engaging in these days in order to try to wrestle with our past (and sometimes, current) problematic practices when creating the descriptive metadata patrons use to discover and identify library resources. And last spring we hosted an intern in the Digital Collections and Curation Services department, Laurier Cress, who wrote an excellent piece describing her research and investigation into the issues present in library and archival description as well as actions that can be taken to address them.
One of the first steps that institutions can take is to publicly acknowledge that we are aware of the biases in our cataloging practices and the resulting harmful or otherwise problematic metadata in our catalogs and on our websites, and to make a commitment to remediation. These public acknowledgements often take the form of what is typically referred to as a ‘harmful language statement’ on the library’s website (The Cataloging Lab has created what looks to be a pretty comprehensive list of statements on bias in library and archives description). Last spring, our Executive Group convened a working group to develop such a statement for the Duke University Libraries and charged us with: Using harmful language statements drafted by other cultural heritage groups as a reference, draft statements acknowledging harmful language and content within our collections (digital and analog) and metadata.
The working group started by reviewing the Harmful Statement Research Log Laurier had compiled as part of her research, in which she analyzed the content and presentation of harmful language statements from GLAM institutions. This was extremely helpful to us in determining what we wanted to prioritize and emphasize as we developed our own statement. We met biweekly over the course of a few months, while also working asynchronously on verbiage in between meetings. Ultimately, we decided that we wanted our statement to be straightforward, communicating that we know library description is not a neutral space, that we are aware that harmful language exists on our website, and that we are committed to repairing such language as it is identified. We also wanted our statement to be short – no one likes a wall of text! – and we were able to accomplish this by linking from the statement to lengthier, more detailed statements on inclusive description prepared by our Technical Services division and the Rubenstein Libraries Technical Services department.
We also felt it was important that our statement include a mechanism for soliciting feedback from users, and so we created a Qualtrics form, linked from the statement, that allows people who have encountered harmful or otherwise problematic language on our website to report it to us. Responses may be anonymous, if desired, although it is also possible to share contact information in order to be updated about any actions taken to remediate the language. Both the statement and the form were published this week:
And we’re not done here! A third priority of the working group’s, in addition to the creation of the statement and the feedback form, was to ensure that this work be visible. (E.g., ‘if a tree falls in a forest, but no one is there to hear it fall, did it make a sound?’ is not dissimilar to ‘if a Drupal page gets plopped into a vast academic research library website, but nobody can find it, will it make an impact?’) To that end, now that the statement and form are publicly accessible, we will work to add links to the statement throughout our discovery layer (including our catalog, our digital collections, and archival collection guides) so that users will be able to find it at the point at which they are potentially encountering harmful language. This work will be a bit more complicated than creating Drupal pages and Qualtrics forms, however, so please stay tuned!
Back in August I wrote a Bitstreams post about the various ways by which those of us who work with library metadata could attempt to tackle the issue of problematic descriptions and descriptive standards. One of the methods I mentioned was activism, and I highlighted the documentary ‘Change the Subject!’, which follows the story of students and librarians at Dartmouth University as they worked together to lobby the Library of Congress to stop using the term ‘illegal aliens’ to describe undocumented immigrants.
Recently, the Triangle Research Libraries’ Network offered a screening of this documentary to its constituent libraries, who were treated to a special viewing (and free popcorn!) at Durham’s iconic Carolina Theater. I attended this screening and participated in a panel discussion following the film.
By Warren LeMay – Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=81937356
I found the documentary to be both encouraging and disheartening: encouraging, as the student activists’ vision, fortitude, and perseverance is inspiring, but disheartening as ultimately, their campaign to have the term ‘illegal aliens’ removed from the Library of Congress Subject Headings failed, due to intervention from Congress.
However, the panel discussion following the screening restored some of my faith that we could still manage problematic metadata with the tools at our disposal. Some of the ideas that were mentioned included:
Identifying alternative thesauri and vocabularies that better represent diversity, equity, and inclusion, and being proactive in mapping problematic metadata to preferred terms.
Working with library vendors to communicate that this is an issue we care about, and perhaps suggesting the use of more inclusive language in their products.
Working with students and student activist groups to collaborate on identifying and remediating areas for improvement in our descriptive practices (as well as library work and spaces in general).
Continuing to use SACO funnels – formal channels for submitting subject authority records to the Library of Congress – while recognizing that this is time consuming yet important work.
And, of course, we can use the technological solution we have already developed for suppressing problematic subject headings from the shared TRLN discovery layer (eg, Duke, UNC, and NCSU’s catalog). Work has progressed on developing policies and governance to support workflows for implementing this solution, including the formation of a TRLN Discovery Metadata Team, which will focus on the shared discovery layer, and a more broadly focused TRLN Metadata Interest Group. Stay tuned!
Header Image: Collection of extinct and extant turtle skull microCT scans in MorphoSource: bit.ly/3DFossilTurtles
MorphoSource (www.morphosource.org) is a publicly accessible repository for 3D research data, especially data that represents biological specimens. Developers in Evolutionary Anthropology and the Library’s Software Services department have been working to rebuild the application, improving upon the current site’s technology and features. An important part of this rebuild is implementing a more robust data model that will let our users efficiently discover, curate, disseminate, and preserve their data.
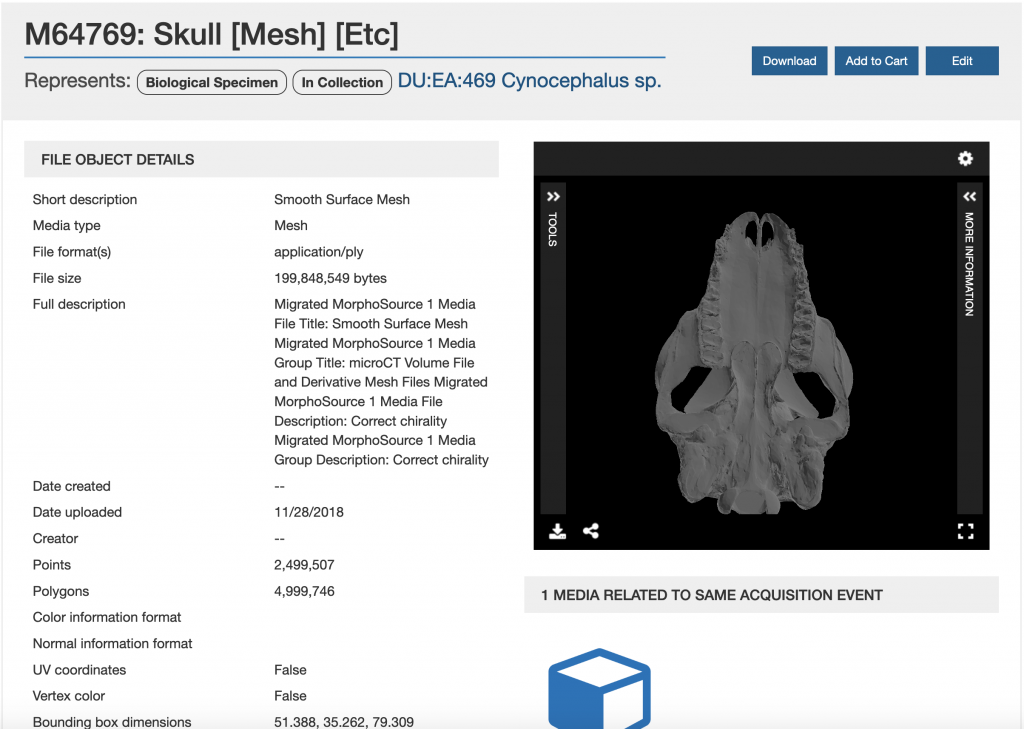
A typical deposit in MorphoSource is a file or files that represent a scan of all or part of an organism – such as a bone, tooth, or entire animal. The files may be a mesh or series of images produced through a CT scan. In order to collect all the information necessary to understand the files, the specimen that the files represent, and the processes that created the data, the improved site will guide the researcher in providing additional context for their deposit at the same time that they upload their files. The following describes what kind of metadata the depositor can expect to provide as part of the submission process.
The first step is to determine whether the researcher’s current deposit is derived in some way from data that is already in MorphoSource, or if the depositor would like to also submit those files and metadata. For example, they may be depositing a mesh file that was created from original photographs that are already available through the site. By including links to the raw data in the repository, users can reprocess the files if needed, or run different processes in the future.
MorphoSource collects metadata to provide context for 3D data in the repository
Next, the researcher is asked to identify or describe the biological specimen that was imaged to create their data, either by entering the information themselves or importing it from another site like iDigBio. Metadata entered at this stage includes the information about the institution that owns the specimen, a taxonomy for the specimen, and additional identifying information such as the institution’s collection or catalog number. When the depositor fills in these fields, other users will be able to search for and compare data sets for the same specimen or species.
Moving on from the description of the organism, the depositor then provides information about the device that was used to image the specimen, either by selecting a device that is already in the repository’s database, or by creating a new record, including the manufacturer, model, and modality (MRI, photography, laser scan, etc.) of the device.
Once they have described the specimen and device used for imaging, the depositor then enters metadata about the imaging event itself, such as the technician who did the imaging, the date, and the software used.
With the imaging of the specimen described, the depositor then enters data about any processing that was done to create the files being deposited, including who was responsible, what software was used, and what the process was – for example, creating a mesh or point cloud from photographs. This metadata is important in case there is a need to reprocess the data in the future.
Finally, the researcher completes their deposit by uploading the files themselves. While some technical metadata is extracted automatically, MorphoSource will rely on data depositors to provide other information that is helpful for display, such as the orientation of the scan, or to identify the files, like an external id number. This technical metadata is important for long term preservation of the data sets.
Screen capture of example media page in MorphoSource
While the submission process asks the researcher to enter quite a bit of metadata, when users view the data on MorphoSource they have an understanding of what the data represents, how it was created, and how it relates to other data in the repository. It becomes easy to discover other media files representing the same specimen, or the same species, or to explore other items from the institution or researcher’s collections.
In April 2018 I attended an excellent NISO webinar entitled “Can there be neutrality in cataloging?”. Initially this struck me as a somewhat quaint title, as though there could be any answer other than ‘no’. Happily, the webinar came to pretty much the same conclusion, and I think it’s fair to say that at this point in time there is a broad understanding in the metadata and cataloging community that libraries are not neutral spaces, and therefore, neither is the description we create, manage, store, and display.
It takes intentionality and cultural humility to do descriptive work in a way that respects the diversity of our society and multitudinous perspectives of our patrons. I think we’re now in a moment where practitioners are recognizing the importance of approaching our work with diversity, equity, and inclusion (DEI) values in mind.
But we must also reckon with the fact that there hasn’t always this kind of focus on inclusivity in regards to our descriptive practices, and so we are left with the task of deciding how best to manage existing metadata and legacy practices that don’t reflect our values as librarians and archivists. So, we have to figure out how to appropriately “decolonize” our description.
Over the past few years I’ve encountered a number of ideas and initiatives aimed at addressing this issue by both reexamining and remediating existing metadata as well as updating and improving descriptive practices.
Institutional work & messaging
We can leverage our institutional structures.
The University of Alberta formed a ‘Decolonizing Description Working Group’ to investigate, document, and propose a plan for more accurately and respectfully representing Indigenous peoples and contexts through descriptive practices.
We can participate in activism to make broad changes.
Students and librarians at Dartmouth University worked together to lobby the Library of Congress to stop using the term ‘illegal aliens’ to describe undocumented immigrants. The documentary ‘Change the Subject!’ describes their campaign.
Programmatic Analysis
We can develop tools and techniques for analyzing our existing metadata.
Noah Geraci, a librarian at the University of California Riverside, presented at Code4Lib 2019 on their project to identify problematic metadata and remediate it programmatically.
Implement Inclusive Vocabulary and Thesauri
We can identify and implement inclusive alternative vocabulary and thesauri in our systems.
As part of the Hyrax project, developers and stakeholders have identified vocabularies and thesauri that are more inclusive and representative, listed here in a spreadsheet managed by Julie Hardesty.
Develop technical solutions
We can develop technical solutions for managing the presence of problematic metadata in our systems.
And here’s something we’re working on locally! As part of TRLN Discovery (a recent and successful project to develop a shared Blacklight discovery interface for the Triangle Research Libraries Network consortium) developers incorporated code for re-mapping problematic subject headings to preferred terms. Problematic terms may still be searched, but only the preferred term will display in the record. We’re still working out how to implement this tool however, from a policy standpoint, e.g., who decides what is ‘problematic’, and how should those decisions be communicated across our organizations.
This is but a smattering out of many projects and ideas metadata practitioners are engaged in. Eradicating inaccurate, insensitive, and potentially harmful description from our library systems is a heavy and entrenched problem to tackle, but lots of smart folks are on it. Together we can address and remediate our existing metadata, reexamine and improve current descriptive practices, and work toward creating an environment that is more inclusive and representative of our communities.
In 2016, after we launched the first iteration of the Duke Chapel Recordings Digital Collection in the Duke Digital Repository (DDR), we began a collaborative project between Digital Collections and Curation Services, University Archives, and the Duke Divinity School to enhance the metadata. The original metadata was fairly basic and allowed users to identify individual written, audio, and video sermons based on speaker, date, title, and format. All good stuff, but it didn’t allow for discovery based on the intellectual content of the sermons themselves. So, it was decided that, at the same time Divinity School staff listened to and corrected machine-generated transcripts for each sermon, they would also capture information that is useful from a homileticperspective.
At the very beginning of the project, the Divinity School convened two focus groups of preachers from a variety of denominations and backgrounds to ask them how they would like to be able to discover and use a digital collection of sermons. These groups developed a set of terms/categories based on which they would like to be able to identify sermons. From there I worked with the project team to begin thinking about what kinds of fields they would want to capture, and determine whether or how those fields could map to the existing metadata application profile that we use in the DDR.
It quickly became clear that this project was going to require the creation of new metadata fields in the DDR application. I try to be really judicious about creating new fields (because otherwise, you end up doing this), but in this case, I felt that the need was justified: homiletic metadata is fairly specialized, and given Duke’s commitment to this collecting area, making adjustments to accommodate it seemed more than reasonable. Since I always like to work with best practices, I attempted to identify any extant metadata schemas that might already exist for working with biblical metadata. I felt pretty confident that I would find one, considering that the Bible is actually one of the oldest books out there. While I did find some resources, they were pretty old (think last-updated-in-2006), and all of them were oriented towards marking up actual Biblical texts, rather than the encoding of metadata about those texts.
Screen capture of the OSIS (Open Scripture Information Standard) in the Wayback Machine.
With no established standards to work with, we set about determining what the fields should be, using the practice of homiletics itself as a guide. We also developed a workflow for the capturing of this metadata, using a google spreadsheet with conditional formatting and pre-developed drop-down lists to control and facilitate data entry. And starting from the set of terms/categories developed during the focus groups, we came up with a normalized set of Library of Congress Subject Headings (LCSH) for staff to choose from or add to, as needs arose.
Example of subject headings applied to a sermon, available at https://idn.duke.edu/ark:/87924/r41r6nf5b
Working with LCSH was in itself a challenge, as it required us to navigate the tension between the need to use a standardized set of headings while also include concepts that weren’t themselves well represented in the vocabulary. In some cases we diverged from LCSH in the interest of using terms that would be familiar, expected, and recognizable to practitioners of homiletics. One example of this is the term ‘Community’, which has a particular meaning in a Biblical context, but which, were we to have used the LCSH term ‘Communities’, loses its intent.
We rolled out the new metadata properties and values in early August so they could be available for use by attendees at the international homiletics conference, Societas Homiletica, which was held at Duke University August 3-8, 2018. Now, users of the digital collection can facet and browse by: Liturgical Calendar, Biblical Book, Chapter and Verse, and Subject. We’ve also added curated abstracts, and key quotations from the sermons, which are free-text searchable.
New facets!
The enhanced metadata makes for a much more meaningful experience using the Duke Chapel Recordings, and future plans involve the inclusion of sermon transcripts, as well as the development of a complimentary website, maintained by the Duke Divinity School, to provide even more information about the speakers and their sermons. With these enrichments, we are well on our way to having an unparalleled free and open resource for the study of homiletics, and hopefully, in so doing, we will facilitate the discovery and study of preachers whose voices have traditionally been underheard.
Last spring, we were awfully excited to see the DPLA/Europeana release of RightStatements.org, a suite of standardized rights statements for describing the copyright and re-use status of digital resources. We have never had a comprehensive approach towards rights management for the Duke Digital Repository, but with the release of RightsStatements.org, we now feel we are equipped to wrestle that beast.
Managing and communicating rights statuses for digital collections has long been a challenge for us. The DDR currently allows for the application and display of Creative Commons licenses, which can be used for situations where the copyright holders themselves can assert the rights statuses for their own resources. RightsStatements.org fills a giant gap for us, in that it allow us to assign machine-readable rights to repository resources for which we know something about the rights status but do not hold the copyrights for. Additionally, these statements accommodate for the often fluid and ambiguous nature of copyrights for cultural heritage materials.
So, it’s been nearly a year since the statements were published, and during that time a community best practice has started to develop. The approach we have decided on for rights management in the Duke Digital Repository follows this emerging best practice, and involves using one field – Dublin Core Rights, as that is the metadata standard our repository uses – to store either a Creative Commons or RightsStatements.org URI, and nothing but that URI, and another field – a local property which we are calling ‘Rights Note’ – to store free text contextual information relating to the rights status of the resource (as long as it’s not in conflict with rights statement applied). Having machine-processable rights statuses means we will have a much better rights management strategy (we don’t currently have a way to report on the rights status of repository materials), as well as the ability to clearly communicate to users what they can and cannot do with resources they find.
Now that we’ve got a strategy for doing rights management, however, we need to develop a strategy for implementing it. We’ll tackle the low-hanging fruit first – collections that have a single, identifiable creator or for which the date ranges put them into the public domain – and then move on to the trickier stuff – for example, collections representing multiple or unidentified creators. Digital collections of archival materials present especially difficult challenges, as the the repository ‘itemness’ is frequently at the folder-level, meaning that the ‘item’, in these cases, might contain works by multiple creators of varying rights statuses (think of a folder of correspondence, for example).
The good news is, there are a lot of smart people working on addressing these challenges. Laura Capell and Elliott Williams of the University of Miami published a helpful poster, Assigning Rights Statements to Legacy Digital Collections describing the the decision matrix they developed to help them apply rights statements to their digital collections, and as I was writing this blog post, the Society of American Archivists circulated their Guide to Implementing Rights Statements from RightsStatements.org (nice timing, SAA!). I’m hoping to find some good nuggets of wisdom in its pages. We feel especially well-positioned to tackle rights management here at Duke, as Dave Hansen, who was deeply involved in the development of RightsStatements.org, joined us as our Director of Copyright and Scholarly Communications last year. We’d love to hear from other organizations as they develop their own local implementations – we know we’re not in this alone!
Last fall, I wrote about how we were embarking on a large-scale remediation of our digital collections metadata in preparation for migrating those collections to the Duke Digital Repository. I started remediation at the beginning of this calendar year, and it’s been at times a slow-going but ultimately pretty satisfying experience. I’m always interested in hearing about how other people working with metadata actually do their work, so I thought I would share some of the tools and techniques I have been using to conduct this project.
First things first: documentation
The metadata task group charged with this work undertook a broad review and analysis of our data, and created a giant google spreadsheet containing all of the fields currently in use in our collections to document the following:
What collections used the field?
Was usage consistent within/across collections?
What kinds of values were used? Controlled vocabularies or free text?
How many unique values?
Based on this analysis, the group made recommendations for remediation of fields and values, which were documented in the spreadsheet as well.
OpenRefine
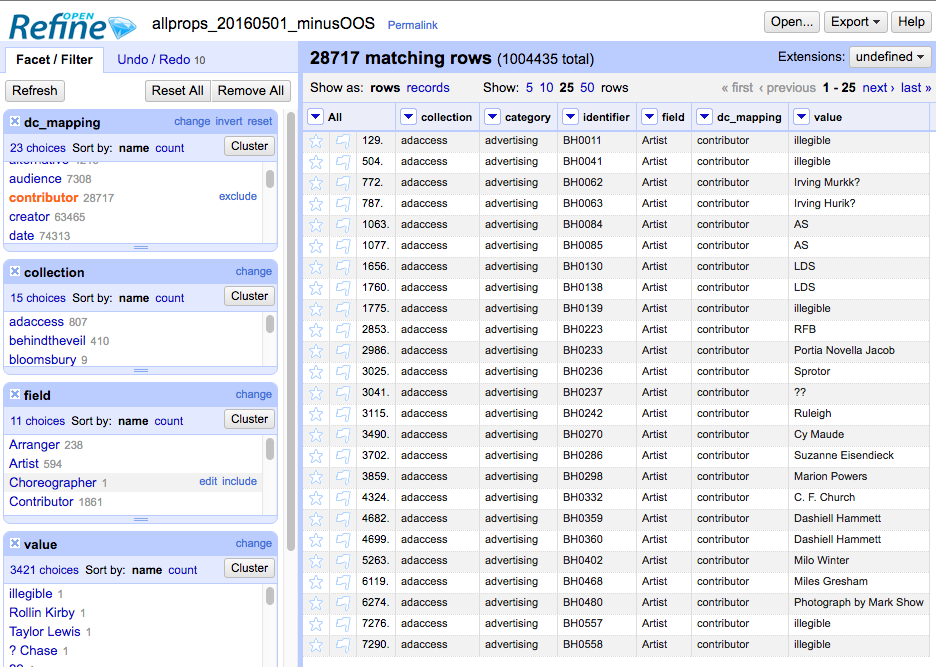
I often compose little love notes in my head to OpenRefine, because my life would be much harder without it in that I would have to harass my lovely developer colleagues for a lot more help. OpenRefine is a powerful tool for analyzing and remediating messy data, and allows me to get a whole lot done without having to do much scripting. It was really useful for doing the initial review and analysis: here’s a screen shot of how I could use the facets to, for example, limit by the Dublin Core contributor property, see which fields are mapped to contributor, which collections use contributor fields, and what the array of values looks like.
The facet feature is also great for performing batch level operations like changing field names and editing values. The cluster and edit feature has been really useful for normalizing values so that they will function well as facetable fields in the user interface. OpenRefine also allows for bulk transformations using regular expressions, so I can make changes based on patterns, rather than specific strings. Eventually I want to take advantage of it’s ability to reconcile data against external sources, too, but it will be more effective if we get through the cleaning process first.
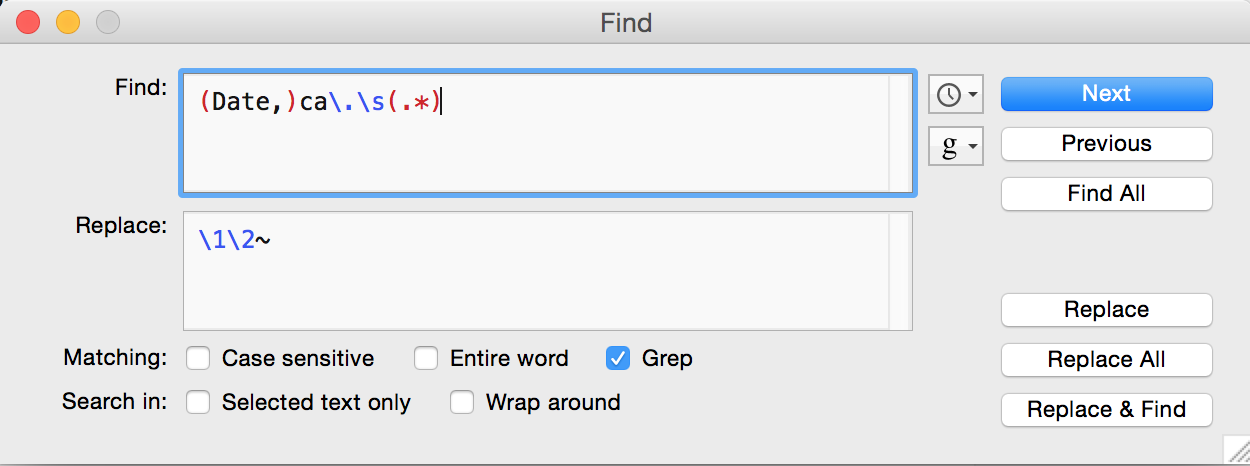
TextWrangler
For some of the more complex transformations I’ve found it is easier and faster to use regular expressions in a text editor – I’ve been using Text Wrangler, which is free and very handy. Here’s an example of one of the regular expressions I used when converting date values to the Extended Date Time Format, which we’ve covered on this blog here and here, and, um, here (what can I say? We love EDTF):
Ruby Scripting
And in a few cases, like where I’ve needed to swap out a lot of individual values with other ones, I’ve had to dip my toes into Ruby scripting. I’ve done some self educating on Ruby via Duke’s access to Lynda.com courses, but I mostly have benefited from the very kind and patient developer on our task group. I also want to make a shout out to RailsBridge, which is an organization dedicated to making tech more diverse by teaching free workshops on Rails and Ruby for underrepresented groups of people in tech. I attended a full day Ruby on Rails workshop organized by RailsBridge Triangle here in Raleigh N.C . and found it to be really approachable and informative, and would encourage anyone interested in building out her/his tech skills to look for local opportunities.
A broadside is a single-sheet notice or advertisement, often textual rather than pictorial. The historical type of broadsides called ephemera (the Latin word, inherited from Greek, referred to things that do not last long) are temporary documents created for a specific purpose and intended to be thrown away.
The Broadsides and Ephemera Collection (David M. Rubenstein Rare Book & Manuscript Library, Duke University) captures written and printed materials of widespread and short-lived use; items, such as event announcements, letters, tickets, posters, social notices, or printouts on current political affairs whose impact was not meant to sustain the test of time. These are the materials that I want to bring to your attention.
The collection includes items from more than 28 countries. The material is quite heterogeneous in terms of content and historical periods. From the Viceroyalty of Peru, to the tensions between Japanese and American soldiers in the early 1940s in the Philippines, one feels a bit like a time traveler without much of a compass, navigating across a sea of material of daunting complexity. After the first scroll through the many rows and tabs in the collection’s Excel sheet, I began questioning, amidst gallons of coffee, the romantic view of the cataloging librarian as a detective of knowledge long lost. Voltaire’s words at the beginning of The Age of Louis XIV regained strength: “Not everything that is done deserves recording”.
Feria de Abril 1932. Sevilla ( Spring Festival 1932)
Yet, as I delved deeper into the collection, I quickly discovered that Ephemera provides a unique window to understand much about the working of human communities all over the world. In fact, the range of common themes emerging is sort of striking given its geographical and temporal scope. It is actually fun. Let me focus on three themes that consistently emerge across the different sections of the international broadsides.
Ephemera work first as a record of the basic organization of social communities. In these instances art becomes a tool to highlight key moments in the everyday life of very diverse communities. The contrast between the 1932 poster for the “Feria de Abril” in Seville, Spain and the 1946 University of Oxford’s Almanac is very telling in this regard. The former serves to mark the most important week in any given year in Seville’s life: around Easter, the city turns into a mixture of art, devotion, and excess in a perfectly balanced and stratified way (different sectors, businesses and social classes get together to party at night after taking part in the parades or processions thanking and honoring the patrons/matrons of the different churches in the city).
The Oxford Almanac, for the year of our Lord God MDCCCCXLVI.
The Almanac provides a list of the head of colleges and the university calendar, making public the key milestones in the life of the university. While the purpose and activities highlighted by these two items could not be more different, their basic function is the same. Both convey useful knowledge about the life of two cities driven by very different pursuits. I know where I would rather study, but it is also quite clear where one ought to go to have some real fun.
Order for taking off the Chimney-Money. In this document is addressed the suppression by the king of the hearth tax in England, and the reaction of the citizens, very grateful of have being liberated from this onerous duty.
A second function of the sort of items included in the international broadsides is to offer a glimpse of political and social relations in many different places. The records on England, for instance, include a letter from subjects to the new King, William of Orange, thanking him for the removal of a the “hearth tax” in 1689, or a piece capturing neatly the scope and goals of the chartist movement in their quest for universal male suffrage, the secret ballot, and annual Parliament elections among other things.
Birmingham Reform petition, part of a working-class movement for political reform in Britain, called Chartism.
The contrast between these two documents (William of Orange order for taking off the Chimney-Money, and the Birmingham Reform Petition) captures nicely the road traveled in England from the Glorious Revolution at the end of the 17th century, to the forefront of economic and political modernization in the 19th century, when the Chartism took place.
On a grimmer note, the records on Germany capture effectively the rise of the National Socialist German Workers’ Party (commonly referred to in English as the Nazi Party) in the interwar period in cities like Heidelberg, and the consequences that ensued in terms of mass casualties for ones or exile for others.
Heidelberg in 1930, festooned with Nazi flags, giving evidence of the transformation of Germany under fascism.
Photograph of a mass grave at Bergen-Belsen concentration camp in Germany with thousand of emanciated and tortured bodies.
To live again! Photograph of Jewish children, survivors, arriving to Palestine.
But the richest and most comprehensive theme that gives coherence to the records across different countries is the one of war and political persuasion/propaganda. Persuasion comes in very different forms. It can be intellectually driven and directed to small circles: the English records feature letters from American activists to English political philosophers such as John Stuart Mill in a quest for support for the anti-slavery movement. Or it can be emotionally driven and directed to broad populations. It is in this particular variety of ephemera where Duke’s International Broadsides Collection really shines.
Italiani, l’inverno è alle porte (Italians, winter is coming.)… a dir le mie virtu basta un sorriso…. (…a smile is enough to show my virtues…)Difendilo! (Defend it!) Fascist propaganda poster, alludes at the need to protect the Italian children from the dangers of Communism, Judaism and Freemasonry.
The records contain dozens of art manifestations from pro-Axis actors in Italy, Germany, and Japan, as well as efforts from the British and U.S. armies to undermine the morale and support of Japanese troops in the Philippines after 1945. Among the former, who knew that the motto of House Stark in Game of Thrones (Winter is coming) was to be found in a piece of political propaganda from Italian fascists against the Allies? Or that Franklin Delano Roosevelt’s virtuous smile was wider the more missiles fell on the Italian cities? Or that the good children of Italy were at risk of being pulled apart by the three evils of Communism, Judaism and Freemasonry? Or that the Australian soldiers would do better to return home to protect their women from the American soldiers’ predatory behavior? Australia screams. Japanese anti-American leaflet trying to persuade the Australians to go home because the American soldiers staged in Australia were seducing their wives.
Finally, another good example is this tricky Japanese leaflet. At first, it appears to show just an soldier and his wife embracing under the beautiful moon, but when it is unfolded, although we can still see the soldier’s undamaged legs, we see that he is dead on the battlefield near a barbed wire.
This Japanese war propaganda leaflet shows a soldier and his wife embracing under the beautiful moon… ….but when the leaflet is unfolded, you still see the soldier’s undamaged legs, however he is dead on the battlefield near a barbed wire.
Regardless of their goals, values, and motives, and our views about them, it is remarkable to observe how all parties involved use popular forms of art and imagery to appeal to their constituencies’ worst fears and prejudices about the other and to present themselves as the more humane side.
As you can see there is much to learn and enjoy by delving in collections such as the international broadsides. Along the process, the metadata librarian confronts an important trade-off between efficiency and usefulness, between speed in processing and detail in the amount of information provided for the prospective user. If we want the collection to be useful for students and scholars, it is necessary to provide a minimum of contextual information for them to be able to locate each item and make the best of it. Yet in many instances this proves a challenging task, one that may well require hours, if not days, of digging into every possible angle that may prove helpful. At the extreme, this is bound to pose too much of a burden in terms of processing time. At this point, I do not have a magic formula to balance this trade-off but I tend to lean on the side of providing as much detail as required for a proper understanding of each piece. Otherwise, the digitally processed item will fail to meet Voltaire’s criteria for what deserves to be recorded. A record in a vacuum, whether in bites or ink, hardly allows users to appreciate those “little things” that, as Conan Doyle’s axiom has it, “are infinitely the most important”.
Back in the fall, we convened a Metadata Task Group (which I chair) charged, in part, with defining, overseeing, and performing the work necessary to remediate Duke University Libraries’ digital collections metadata in preparation for migration from our old technical platform to the Duke Digital Repository. This involved an intensive analysis and review of our existing metadata field usage, and documentation of that analysis as well as recommendations for remediation. Before we truly engaged with this work, however, we defined a set of guiding principles to provide ourselves with a context for completing our tasks.
The first guiding principle we defined was that of Fitness for Purpose. As applied to metadata work, fitness for purpose entails that metadata be appropriate for user and system needs, both now and, in as much as it can be predetermined, in the future. This is an overarching principle which informs subsequent guiding principles. It seems like a pretty basic concept, but I think it is all too easy to lose sight of who will be using the collections we create metadata for (which is a difficult question to answer anyways), and of course, it’s always important to ensure that the metadata specifications take into account the technical environment in which it will live.
Our next guiding principle is Broad Applicability. Over the past 20 years, digital collections at Duke were developed often in an ad hoc way, each digital collection’s metadata specifications being created in a somewhat isolated fashion. Now that we have a dedicated staff person (me!) to take a comprehensive look at metadata practices at DUL, we are very interested in developing guidelines and specifications that can be applied broadly, across a variety of collections and materials. This is especially important considering the breadth and variety of collections that will live together in the Duke Digital Repository.
Along with Broad Applicability, Broad Shareability is equally important. With the formation of metadata aggregators such as the Digital Public Library of America, the possibilities for sharing our metadata and thus our resources broadly is much greater than in the past, and therefore metadata must be remediated, created, and mapped to widely used standards in ways that allow for clear, meaningful sharing. As much as possible, we are aligning our metadata practices with the DPLA’s Metadata Application Profile.
And, of course, our guiding principles wouldn’t be complete without a nod toward the future: our last principle is that we be Forward-Thinking. Change is a constant when working with metadata/digital resources, and so we must do our best to develop recommendations and guidelines that allow for this eventuality, e.g., adopting standards and practices that have the greatest staying power and allow for the adoption of new technologies. Specifically, we should be aware of linked data technologies and make recommendations that are linked-data aware and/or ready.
At the outset of this project it had felt a little bit like, “well, duh”, to develop these broad guiding principles, but at 6+ months in, I am really glad we took the time to define them – I have referred back to them periodically as we tackle each task in our charge, and find them helpful not just when communicating outside our group but as a way to provide a sort of intellectual context internally as well.
To recap, EDTF is a machine readable date encoding standard that enables us to record dates with various levels of precision and certainty — important for cultural heritage collections.
One challenge of working with EDTF formatted dates is that it’s not necessarily obvious to humans what they mean. To the best of my knowledge, the available tools for working with EDTF dates are intended for parsing EDTF strings into objects that are understandable to programming languages. This is great for working with EDTF dates if you want to have the software do things like sort a list of items into date order or provide a searchable index of years. These tools are less helpful for outputting human readable versions of EDTF encoded dates, such as for an item’s metadata record display.
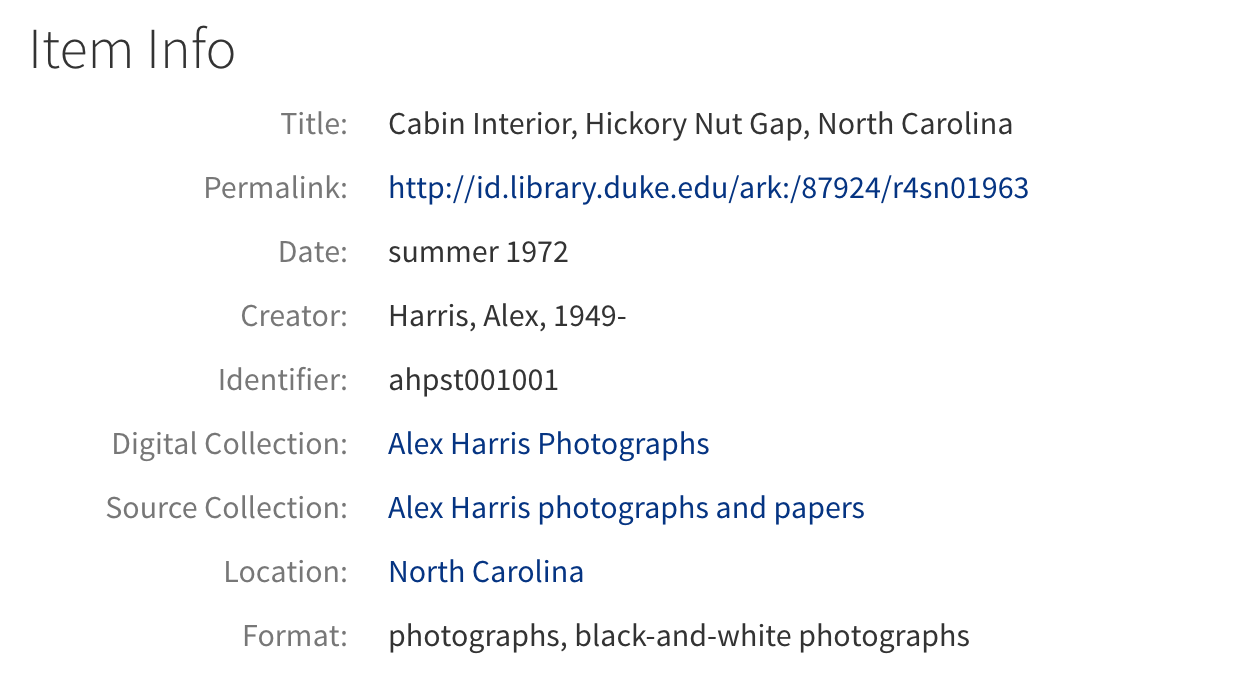
For instance, many of the photographs in the Alex Harris collection are dated with a season and year, such as “summer 1972.” EDTF specifies that “summer 1972” should be encoded as “1972-22.” This is great for our digital collections software, which knows what “1972-22” means (thanks to the EDTF gem). However, people unfamiliar with the EDTF standard will likely not understand what the date means.
But in the metadata display in the digital repository’s public interface we want to display the date in a more human friendly format:
Because EDTF is machine readable it’s possible to create a set of rules for transforming the dates for display. These rules can get complicated so I wrote a Ruby Gem that masks some of the complexity and adds a humanize method to any EDTF date object. This makes it simple to transform any EDTF encoded date to a human readable string.
> Date.edtf('1972-22').humanize
=> "summer 1972"
Although more work could be done to make it more flexible, the gem is somewhat configurable. For instance, an uncertain date with year precision is encoded in EDTF as “1972~”. The humanize method will by default output this as “circa 1972”:
> Date.edtf('1972~').humanize
=> "circa 1972"
But if for some reason I wanted a different output for an uncertain date with year precision I could modify the edtf-humanize configurations:
The humanize method that edtf-humanize adds to EDTF objects makes it much easier to display EDTF encoded date metadata in configurable human friendly formats.
The edtf-humanize gem is available on GitHub and RubyGems.org so it can be included in any Rails project’s gemfile. It should be considered an early release and could use some enhancement for use cases beyond Duke’s Digital Repository where it was originally designed to be used.
Notes from the Duke University Libraries Digital Projects Team





 Header Image: Collection of extinct and extant turtle skull microCT scans in MorphoSource:
Header Image: Collection of extinct and extant turtle skull microCT scans in MorphoSource: