This post was authored by Behind the Veil/Digital Collections intern Kristina Zapfe.
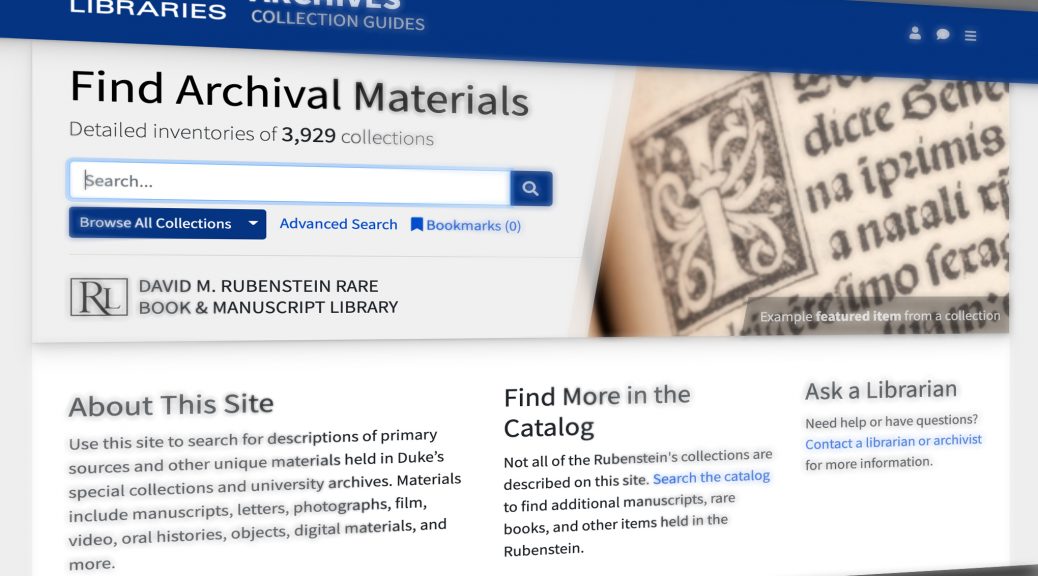
From the outside, viewing digitized items or requesting one yourself is a straightforward activity. Browsing images in the Duke Digital Repository produces instantaneous access to images from the David M. Rubenstein Rare Book and Manuscript Library’s collections, and requesting an item for digitization means that they appear in your email in as little as a few weeks. But what happens between placing that request and receiving your digital copies is a well-mechanized feat, a testament to the hard work and dedication put forth by the many staff members who have a hand in digitizing special collections.
I began at Duke Libraries in July 2022 as the Digital Collections Intern, learning about the workflows and pivots that were made in order to prioritize public access to Rubenstein’s collections during pandemic-era uncertainty. While learning to apply metadata and scan special collection materials, I sketched out an understanding of how digital library systems function together, crafted by the knowledge and skills of library staff who maintain and improve them. This established an appreciation of the collaborative and adaptive nature of the many departments and systems that account for every detail of digitizing items, providing patrons access to Rubenstein’s special collections from afar.
I have filmed short videos before, but none that required the amount of coordination and planning that this one did. Once the concept was formed, I began researching Duke University Libraries’ digital platforms and how they work together in order to overlay where the patron request process dipped into these platforms and when. After some email coordination, virtual meetings, and hundreds of questions, a storyboard was born and filming could begin. I tried out some camera equipment and determined that shooting on my iPhone 13 Pro with a gimbal attachment was a sufficient balance of quality and dexterity. Multiple trips to Rubenstein, Bostock, and Perkins libraries and Smith Warehouse resulted in about 500 video clips, about 35 of which appear in the final video.
Throughout this process, I learned that not everything goes as the storyboard plans, and I enjoyed leaving space for my own creativity as well as input from staff members whose insights about their daily work made for compelling shots and storytelling opportunities. The intent of this video is to tell the story of this process to everyone who uses and appreciates Duke Libraries’ resources and say “thank you” to the library staff who work together to make digital collections available.
Special thanks to all staff who appeared in this video and enthusiastically volunteered their time and Maggie Dickson, who supervised and helped coordinate this project.
Post authored by Jen Jordan, Digital Collections Intern.
Hello, readers. This marks my third and final blog as the Digital Collections intern, a position that I began in June of last year.* Over the course of this internship I have been fortunate to gain experience in nearly every step of the digitization and digital collections processes. One of the things I’ve come to appreciate most about the different workflows I’ve learned about is how well they accommodate the variety of collection materials that pass through. This means that when unique cases arise, there is space to consider them. I’d like to describe one such case, involving a pretty remarkable collection.
Cheyne, C.E. “Booker T. Washington sitting and holding books,” 1903. 2 photographs on 1 mount : gelatin silver print ; sheets 14 x 10 cm. In Washington, D.C., Library of Congress Prints and Photographs Division.
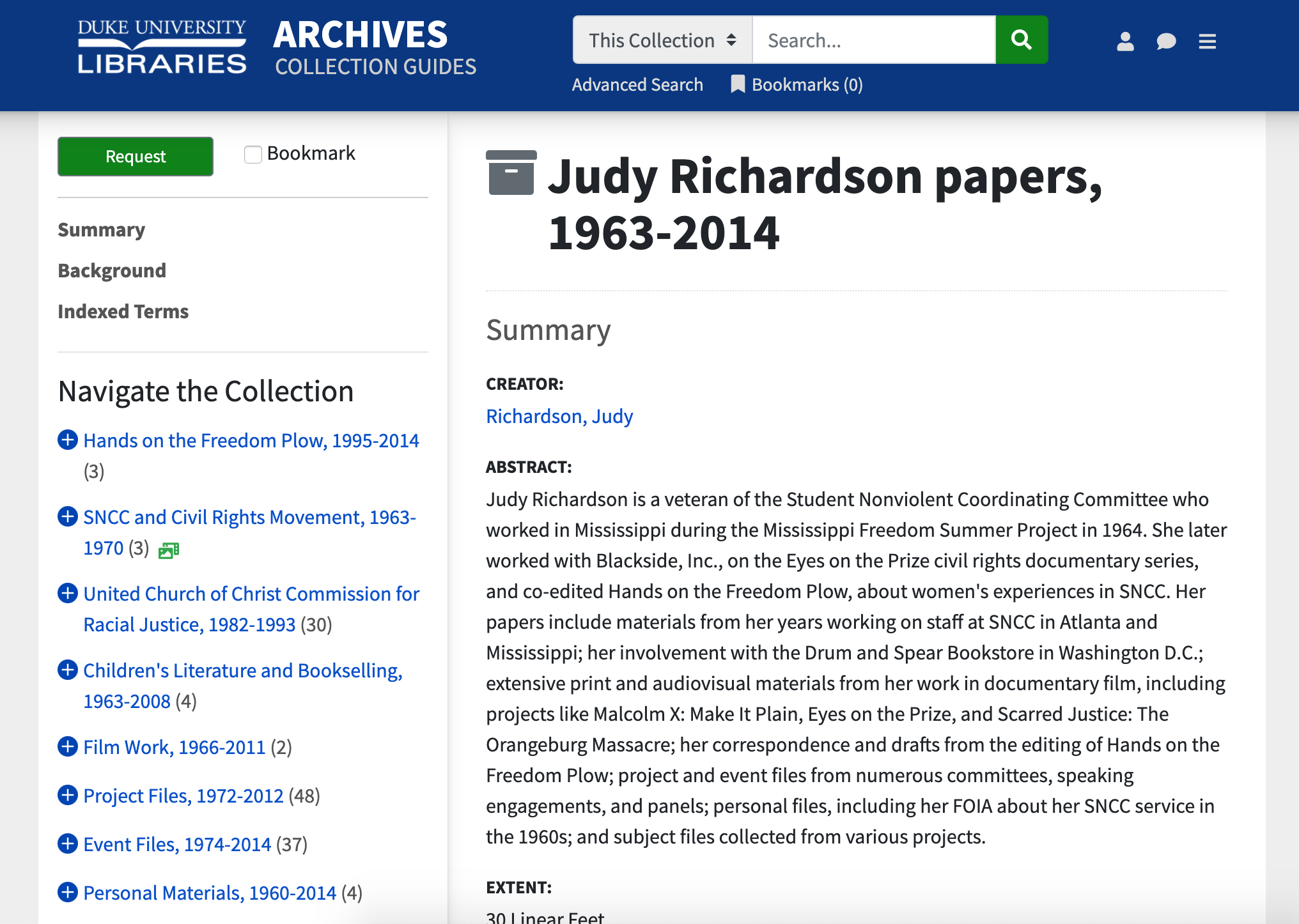
In early October I arrived to work in the Digital Production Center (DPC) and was excited to see the Booker T. Washington correspondence, 1903-1916, 1933 and undated was next up in the queue for digitization. The collection is small, containing mostly letters exchanged between Washington, W. E. B. DuBois, and a host of other prominent leaders in the Black community during the early 1900s. A 2003 article published in Duke Magazine shortly after the Washington collection was donated to the John Hope Franklin Research Center provides a summary of the collection and the events it covers.
Arranged chronologically, the papers were stacked neatly in a small box. Having undergone undergone extensive conservation treatments to remediate water and mildew damage, each letter was sealed in a protective sleeve. As I scanned the pages, I made a note to learn more about the relationship between Washington and DuBois, as well as the events the collection is centered around—the Carnegie Hall Conference and the formation of the short-lived Committee of Twelve for the Advancement of the Interests of the Negro Race. When I did follow up, I was surprised to find that remarkably little has been written about either.
As I’ve mentioned before, there is little time to actually look at materials when we scan them, but the process can reveal broad themes and tone. Many of the names in the letters were unfamiliar to me, but I observed extensive discussion between DuBois and Washington regarding who would be invited to the conference and included in the Committee of Twelve. I later learned that this collection documents what would be the final attempt at collaboration between DuBois and Washington.
Washington to Browne, 21 July 1904, South Weymouth, Massachusetts
Once scanned, the digital surrogates pass through several stages in the DPC before they are prepared for ingest into the Duke Digital Repository (DDR); you can read a comprehensive overview of the DPC digitization workflow here. Fulfilling patron requests is top priority, so after patrons receive the requested materials, it might be some time before the files are submitted for ingest to the DDR. Because of this, I was fortunate to be on the receiving end of the BTW collection in late January. By then I was gaining experience in the actual creation of digital collections—basically everything that happens with the files once the DPC signals that they are ready to move into long term storage.
There are a few different ways that new digital collections are created. Thus far, most of my experience has been with the files produced through patron requests handled by the DPC. These tend to be smaller in size and have a simple file structure. The files are migrated into the DDR, into either a new or existing collection, after which file counts are checked, and identifiers assigned. The collection is then reviewed by one of a few different folks with RL Technical Services. Noah Huffman conducted the review in this case, after which he asked if we might consider itemizing the collection, given the letter-level descriptive metadata available in the collection guide.
I’d like to pause for a moment to discuss the tricky nature of “itemness,” and how the meaning can shift between RL and DCCS. If you reference the collection guide linked in the second paragraph, you will see that the BTW collection received item-level description during processing—with each letter constituting an item in the collection. The physical arrangement of the papers does not reflect the itemized intellectual arrangement, as the letters are grouped together in the box they are housed in. When fulfilling patron reproduction requests, itemness is generally dictated by physical arrangement, in what is called the folder-level model; materials housed together are treated as a single unit. So in this case, because the letters were grouped together inside of the box, the box was treated as the folder, or item. If, however, each letter in the box was housed within its own folder, then each folder would be considered an item. To be clear, the papers were housed according to best practices; my intent is simply to describe how the processes between the two departments sometimes diverge.
Processing archival collections is labor intensive, so it’s increasingly uncommon to see item-level description. Collections can sit unprocessed in “backlog” for many years, and though the depth of that backlog varies by institution, even well-resourced archives confront the problem of backlog. Enter: More Product, Less Process (MPLP), introduced by Mark Greene and Dennis Meissner in a 2005 article as a means to address the growing problem. They called on archivists to prioritize access over meticulous arrangement and description.
The spirit of folder-level digitization is quite similar to MPLP, as it enables the DPC to provide access to a broader selection of collection materials digitized through patron requests, and it also simplifies the process of putting the materials online for public access. Most of the time, the DPC’s approach to itemness aligns closely with the level of description given during processing of the collection, but the inevitable variance found between archival collections requires a degree of flexibility from those working to provide access to them. Numerous examples of digital collections that received item-level description can be found in the DDR, but those are generally tied to planned efforts to digitize specific collections.
Because the BTW collection was digitized as an item, the digital files were grouped together in a single folder, which translated to a single landing page in the DDR’s public user interface. Itemizing the collection would give each item/letter its own landing page, with the potential to add unique metadata. Similarly, when users navigate the RL collection guide, embedded digital surrogates appear for each item. A moment ago I described the utility of More Product Less Process. There are times, however, when it seems right to do more. Given the research value of this collection, as well as its relatively small size, the decision to proceed with itemization was unanimous.
Itemizing the collection was fairly straightforward. Noah shared a spreadsheet with metadata from the collection guide. There were 108 items, with each item’s title containing the sender and recipient of a correspondence, as well as the location and date sent. Given the collection’s chronological physical arrangement, it was fairly simple to work through the files and assign them to new folders. Once that was finished, I selected additional descriptive metadata terms to add to the spreadsheet, in accordance with the DDR Metadata Application Profile. Because there was a known sender and recipient for almost every letter, my goal was to identify any additional name authority records not included in the collection guide. This would provide an additional access point by which to navigate the collection. It would also help me to identify death dates for the creators, which determines copyright status. I think the added time and effort was well worth it.
This isn’t the space for analysis, but I do hope you’re inspired to spend some time with this fascinating collection. Primary source materials offer an important path to understanding history, and this particular collection captures the planning and aftermath of an event that hasn’t received much analysis. There is more coverage of what came after; Washington and DuBois parted ways, after which DuBois became a founding member of the Niagara Movement. Though also short lived, it is considered a precursor to the NAACP, which many members of the Niagara Movement would go on to join. A significant portion of W. E. B. DuBois’s correspondence has been digitized and made available to view through UMass Amherst. It contains many additional letters concerning the Carnegie Conference and Committee of Twelve, offering additional context and perspective, particularly in certain correspondence that were surely not intended for Washington’s eyes. What I found most fascinating, though, was the evidence of less public (and less adversarial) collaboration between the two men.
The additional review and research required by the itemization and metadata creation was such a fascinating and valuable experience. This is true on a professional level as it offered the opportunity to do something new, but I also felt moved to understand more about the cast of characters who appear in this important collection. That endeavor extended far beyond the hours of my internship, and I found myself wondering if this is what the obsessive pursuit of a historian’s work is like. In any case, I am grateful to have learned more, and also reminded that there is so much more work to do.
Click here to view the Booker T. Washington correspondence in the Duke Digital Repository.
*Indeed, this marks my final post in this role, as my internship concludes at the end of April, after which I will move on to a permanent position. Happily, I won’t be going far, as I’ve been selected to remain with DCCS as one of the next Repository Services Analysts!
Sources
Cheyne, C.E. “Booker T. Washington sitting and holding books,” 1903. 2 photographs on 1 mount : gelatin silver print ; sheets 14 x 10 cm. In Washington, D.C., Library of Congress Prints and Photographs Division. Accessed April 5, 2022. https://www.loc.gov/pictures/item/2004672766/
Duke University Libraries (DUL) is recruiting two (2) Repository Services Analysts to ingest and help collaboratively manage content in their digital preservation systems and platforms. These positions will partner with the Research Data Curation, Digital Collections, and Scholarly Communications Programs, as well as other library and campus partners to provide digital curation and preservation services. The Repository Services Analyst role is an excellent early career opportunity for anyone who enjoys managing large sets of data and/or files, working with colleagues across an organization, preserving unique data and library collections, and learning new skills.
DUL will hold an open zoom session where prospective candidates can join anonymously and ask questions. This session will take place on Wednesday January 12 at 1pm EST; the link to join is posted on the libraries’ job advertisement.
The Research Data Curation Program has grown significantly in recent years, and DUL is seeking candidates who want to grow their skills in this area. DUL is a member of the Data Curation Network (DCN), which provides opportunities for cross-institutional collaboration, curation training, and hands-on data curation practice. These skills are essential for anyone who wants to pursue a career in research data curation.
Ideal Repository Services Analyst applicants have been exposed to digital asset management tools and techniques such as command line scripting. They can communicate functional system requirements between groups with varying types of expertise, enjoy working with varied kinds of data and collections, and love solving problems. Applicants should also be comfortable collaboratively managing a shared portfolio of digital curation services and projects, as the two positions work closely together. The successful candidates will join the Digital Collections and Curation Services department (within the Digital Strategies and Technology Division).
Please refer to the DUL’s job posting for position requirements and application instructions.
One of the greatest challenges to digitizing analog moving-image sources such as videotape and film reels isn’t the actual digitization. It’s the enormous file sizes that result, and the high costs associated with storing and maintaining those files for long-term preservation. For many years, Duke Libraries has generated 10-bit uncompressed preservation master files when digitizing our vast inventory of analog videotapes.
Unfortunately, one hour of uncompressed video can produce a 100 gigabyte file. That’s at least 50 times larger than an audio preservation file of the same duration, and about 1000 times larger than most still image preservation files. That’s a lot of data, and as we digitize more and more moving-image material over time, the long-term storage costs for these files can grow exponentially.
To help offset this challenge, Duke Libraries has recently implemented the FFV1 video codec as its primary format for moving image preservation. FFV1 was first created as part of the open-source FFmpeg software project, and has been developed, updated and improved by various contributors in the Association of Moving Image Archivists (AMIA) community.
FFV1 enables lossless compression of moving-image content. Just like uncompressed video, FFV1 delivers the highest possible image resolution, color quality and sharpness, while avoiding the motion compensation and compression artifacts that can occur with “lossy” compression. Yet, FFV1 produces a file that is, on average, 1/3 the size of its uncompressed counterpart.
FFV1 produces a file that is, on average, 1/3 the size of its uncompressed counterpart. Yet, the audio & video content is identical, thanks to lossless compression.
The algorithms used in lossless compression are complex, but if you’ve ever prepared for a fall backpacking trip, and tightly rolled your fluffy goose-down sleeping bag into one of those nifty little stuff-sacks, essentially squeezing all the air out of it, you just employed (a simplified version of) lossless compression. After you set up your tent, and unpack your sleeping bag, it decompresses, and the sleeping bag is now physically identical to the way it was before you packed.
Yet, during the trek to the campsite, it took up a lot less room in your backpack, just like FFV1 files take up a lot less room in our digital repository. Like that sleeping bag, FFV1 lossless compression ensures that the compressed video file is mathematically identical to it’s pre-compressed state. No data is “lost” or irreversibly altered in the process.
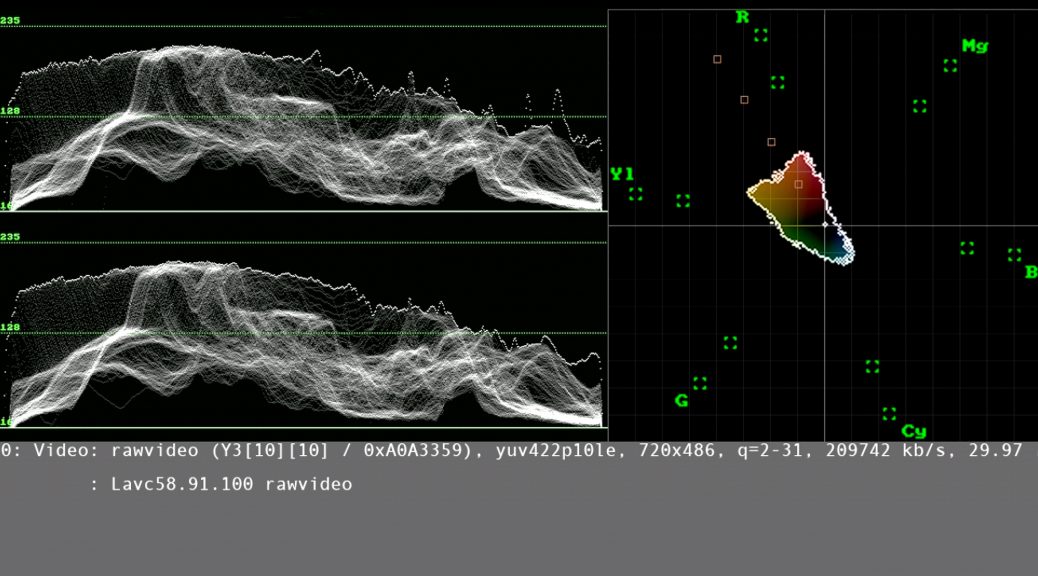
Duke Libraries’ Digital Production Center utilizes a pair of 6-foot-tall video racks, which house a current total of eight videotape decks, comprised of a variety of obsolete formats such as U-matic (NTSC), U-matic (PAL), Betacam, DigiBeta, VHS (NTSC) and VHS (PAL, Secam). Each deck is converted from analog to digital (SDI) using Blackmagic Design Mini Converters.
The SDI signals are sent to a Blackmagic Design Smart Videohub, which is the central routing center for the entire system. Audio mixers and video transcoders allow the Digitization Specialist to tweak the analog signals so the waveform, vectorscope and decibel levels meet broadcast standards and the digitized video is faithful to its analog source. The output is then routed to one of two Retina 5K iMacs via Blackmagic UltraStudio devices, which convert the SDI signal to Thunderbolt 3.
FFV1 video digitization in progress in the Digital Production Center.
Because no major company (Apple, Microsoft, Adobe, Blackmagic, etc.) has yet adopted the FFV1 codec, multiple foundational layers of mostly open-source systems software had to be installed, tested and tweaked on our iMacs to make FFV1 work: Apple’s Xcode, Homebrew, AMIA’s vrecord, FFmpeg, Hex Fiend, AMIA’s ffmprovisr, GitHub Desktop, MediaInfo, and QCTools.
FFV1 operates via terminal command line prompts, so some understanding of programming language is helpful to enter the correct prompts, and be able to decipher the terminal logs.
The FFV1 files are “wrapped” in the open source Matroska (.mkv) media container. Our FFV1 scripts employ several degrees of quality-control checks, input logs and checksums, which ensure file integrity. The files can then be viewed using VLC media player, for Mac and Windows. Finally, we make an H.264 (.mp4) access derivative from the FFV1 preservation master, which can be sent to patrons, or published via Duke’s Digital Collections Repository.
An added bonus is that, not only can Duke Libraries digitize analog videotapes and film reels in FFV1, we can also utilize the codec (via scripting) to target a large batch of uncompressed video files (that were digitized from analog sources years ago) and make much smaller FFV1 copies, that are mathematically lossless. The script runs checksums on both the original uncompressed video file, and its new FFV1 counterpart, and verifies the content inside each container is identical.
Now, a digital collection of uncompressed masters that took up 9 terabytes can be deleted, and the newly-generated batch of FFV1 files, which only takes up 3 terabytes, are the new preservation masters for that collection. But no data has been lost, and the content is identical. Just like that goose-down sleeping bag, this helps the Duke University budget managers sleep better at night.
Now that we have been live for awhile, I thought it’d be worthwhile to summarize what we accomplished, and reflect a bit on how it’s going.
Working Among Peers
I had the pleasure of presenting about ArcLight at the Oct 2020 Blacklight Summit alongside Julie Hardesty (Indiana University) and Trey Pendragon (Princeton University). The three of us shared our experiences implementing ArcLight at our institutions. Though we have the same core ArcLight software underpinning our apps, we have each taken different strategies to build on top of it. Nevertheless, we’re all emerging with solutions that look polished and fill in various gaps to meet our unique local needs. It’s exciting to see how well the software holds up in different contexts, and to be able to glean inspiration from our peers’ platforms.
Slides from ArcLight@Duke presentation, 10/7/2020
A lot of content in this post will reiterate what I shared in the presentation.
This is one of the hardest things to get right in a finding aids UI, so our solution has evolved through many iterations. We created a context sidebar with lightly-animated loading indicators matching the number of items currently loading. The nav sticks with you as you scroll down the page and the Request button stays visible. We also decided to present a list of direct child components in the main page body for any parent component.
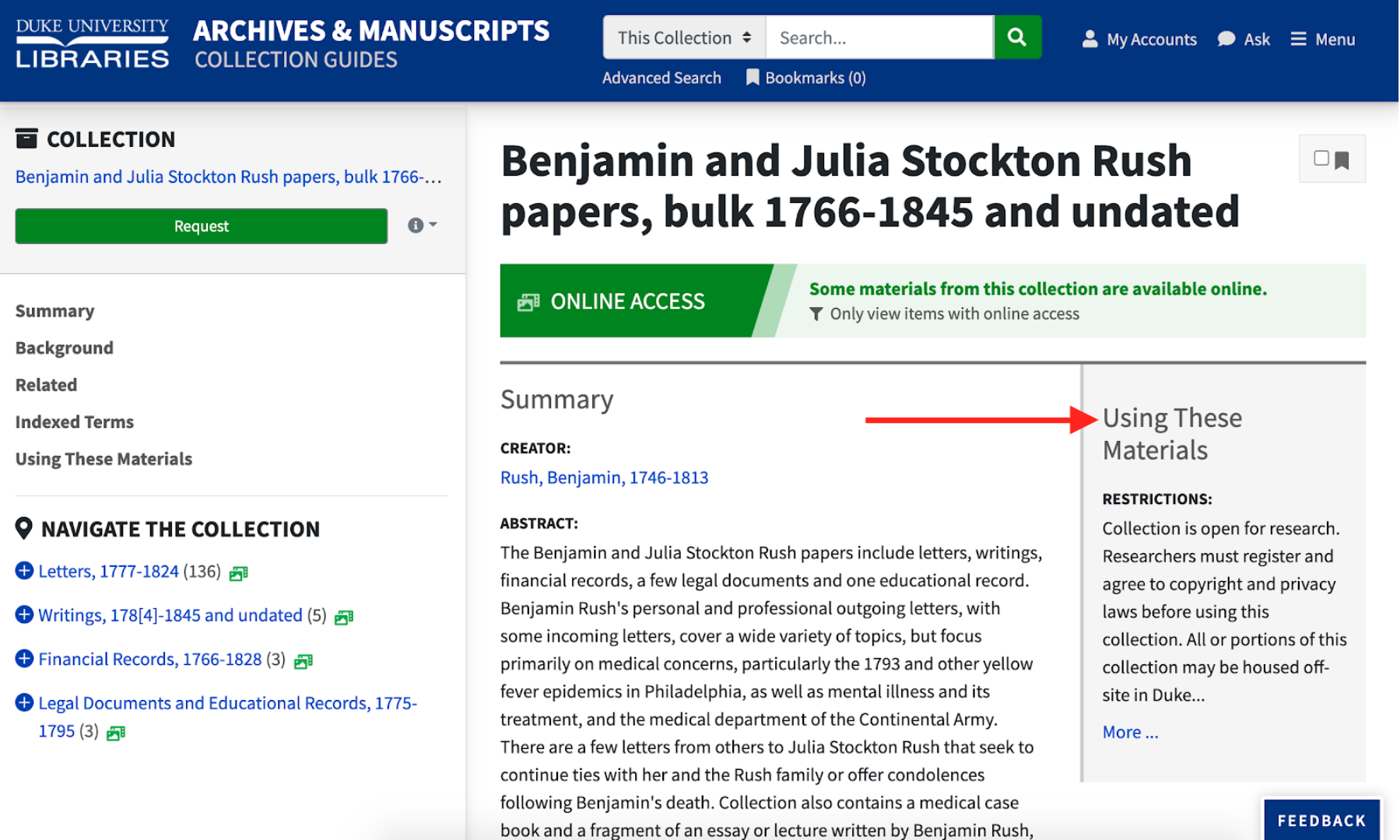
Restrictions
At the collection level, we wanted to ensure that users didn’t miss any restrictions info, so we presented a taste of it at the top-right of the page that jumps you to the full description when clicking “More.”
We changed how access and use restriction indexing so components can inherit their restrictions from any ancestor component. Then we made bright yellow banners and icons in the UI to signify that a component has restrictions.
ArcLight exists among a wide constellation of other applications supporting and promoting discovery in the library, so integrating with these other pieces was an important part of our implementation. In April, I showed the interaction between ArcLight and our Requests app, as well as rendering digital object viewers/players inline via the Duke Digital Repository (DDR).
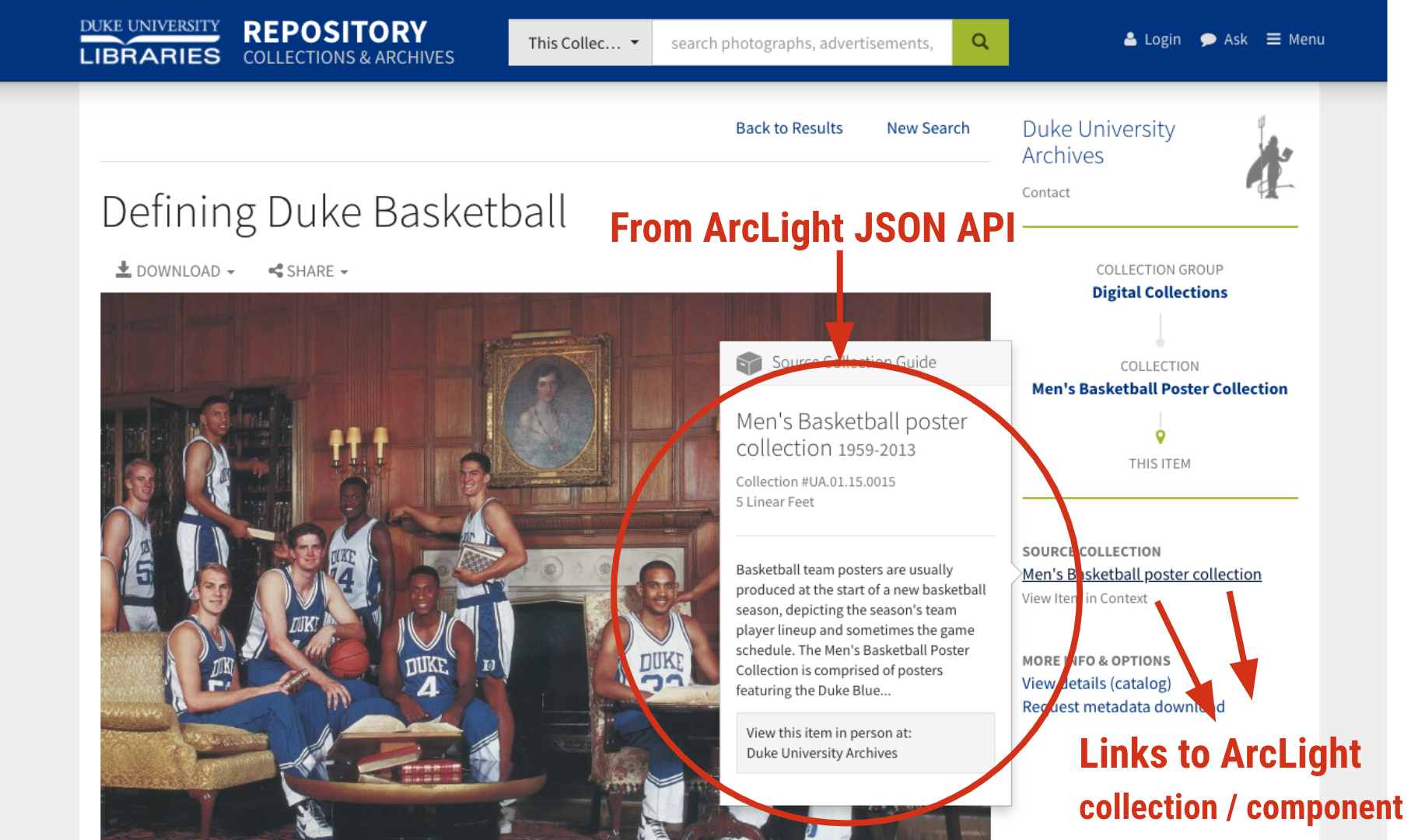
Two other locations external to our application now use ArcLight’s APIs to retrieve archival information. The first is the Duke Digital Repository (DDR). When viewing a digital collection or digital object that has a physical counterpart in the archives, we pull archival information for the item into the DDR interface from ArcLight’s JSON API.
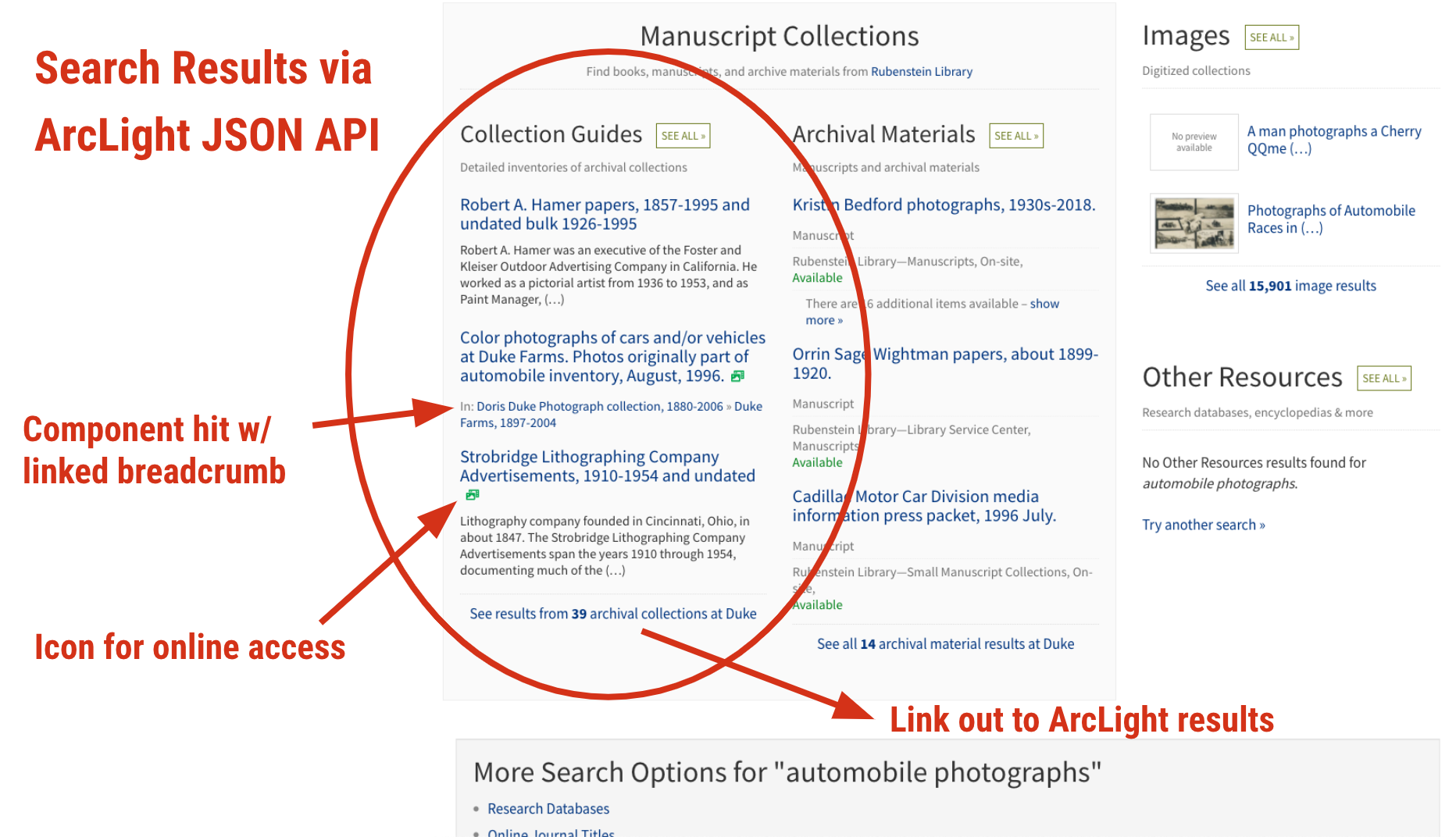
The other is our “Bento” search application powering the default All search available from the library website. Now when your query finds matches in ArcLight, you’ll see component-level results under a Collection Guides bento box. Components are contextualized with a linked breadcrumb trail.
Bookmarks Export CSV
COVID-19 brought about many changes to how staff at Duke Libraries retrieve materials for faculty and student research. You may have heard Duke’s Library Takeout song (819K YouTube views & counting!), and if you have, you probably can’t ever un-hear it.
But with archival materials, we’re talking about items that could never be taken out of the building. Materials may only be accessed in a controlled environment in the Rubenstein Reading Room, which remains highly restricted. With so much Duke instruction moving online during COVID, we urgently needed to come up with a better workflow to field an explosion of requests for digitizing archival materials for use in remote instruction.
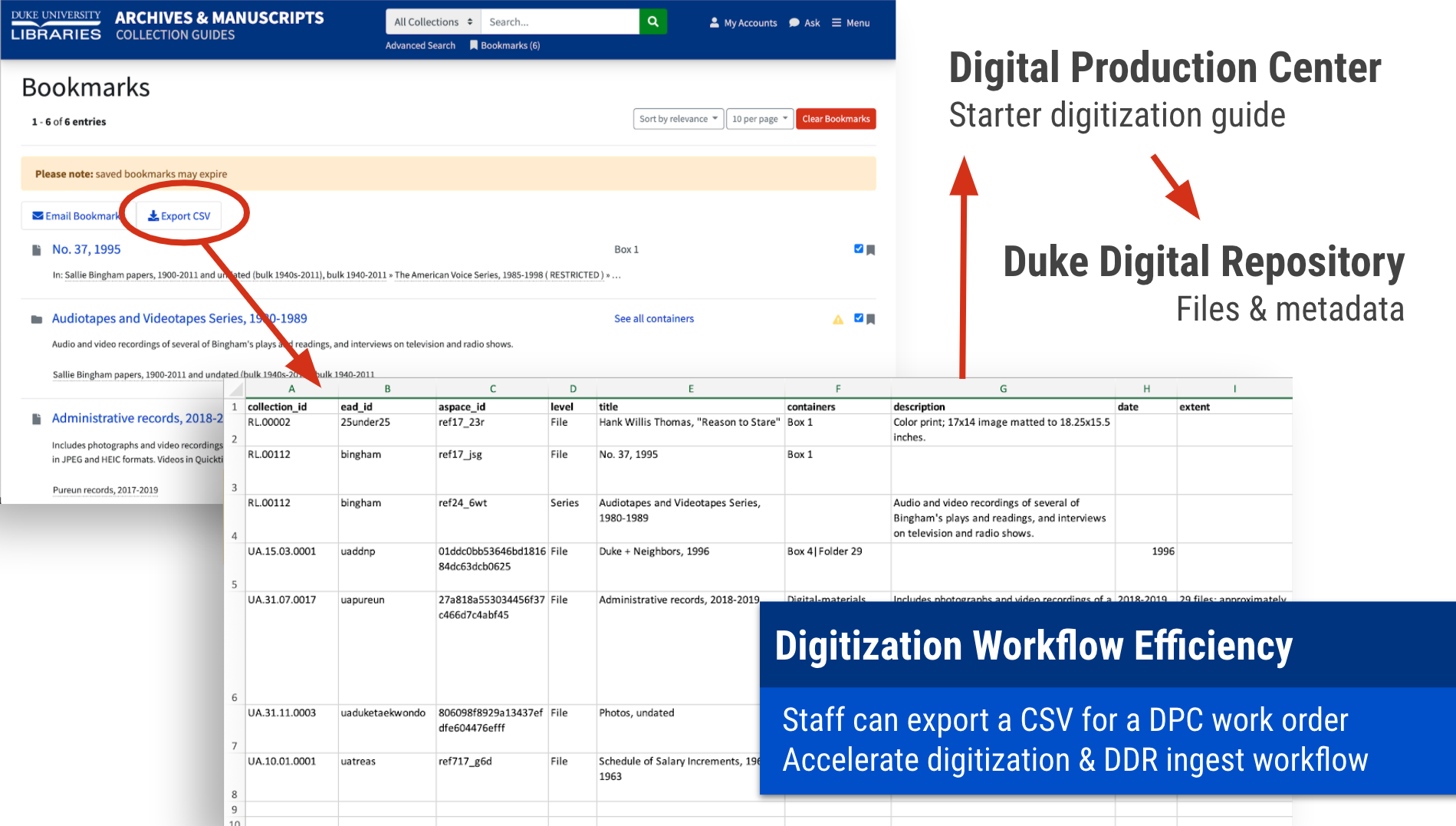
ArcLight’s Bookmarks feature (which comes via Blacklight) proved to be highly valuable here. We extended the feature to add a CSV export. The CSV is constructed in a way that makes it function as a digitization work order that our Digital Collections & Curation Services staff use to shepherd a request through digitization, metadata creation, and repository ingest. Over 26,000 images have now been digitized for patron instruction requests using this new workflow.
More Features
Here’s a list of several other custom features we completed after the April midway point.
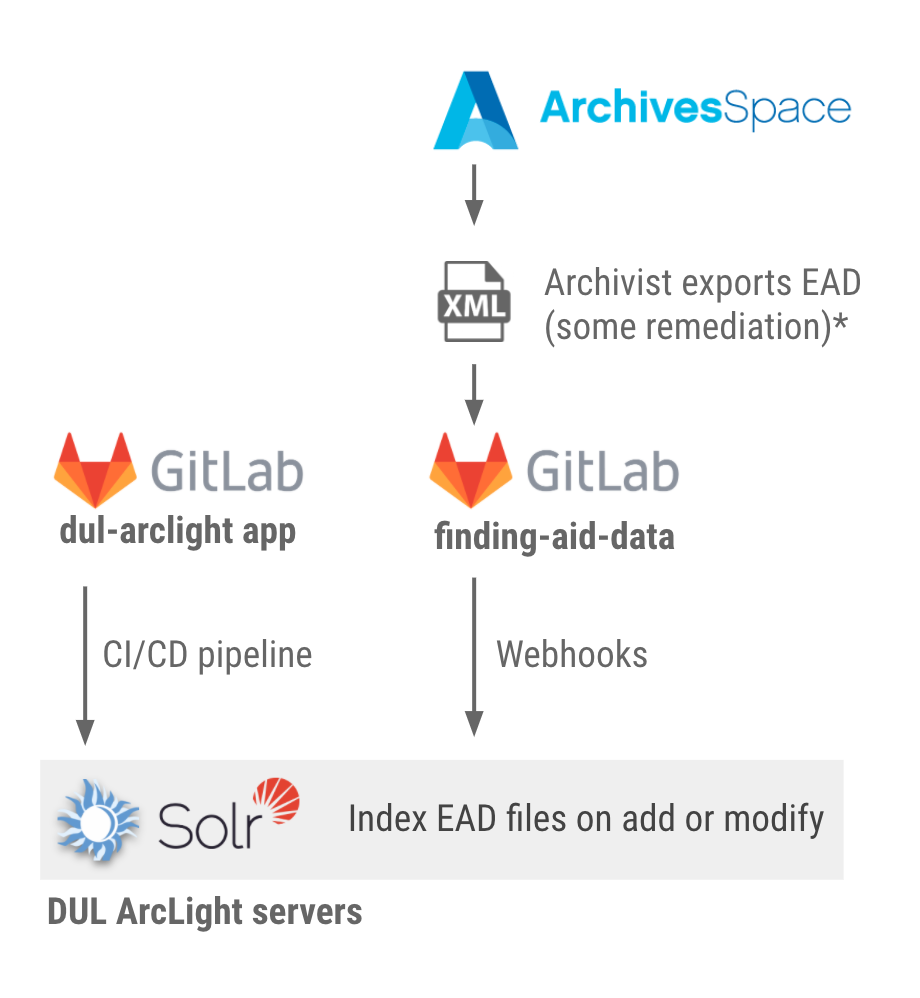
Bringing ArcLight online required some major rearchitecting of our pipeline to preview and publish archival data. Our archivists have been using ArchivesSpace for several years to manage the source data, and exporting EAD2002 XML files when ready to be read by the public UI. Those parts remain the same for now, however, everything else is new and improved.
Our new process involves two GitLab repositories: one for the EAD data, and another for the ArcLight-based application. The data repo uses GitLab Webhooks to send POST requests to the app to queue up reindexing jobs automatically whenever the data changes. We have a test/preview branch for the data that updates our dev and test servers for the application, so archivists can easily see what any revised or new finding aids will look like before they go live in production.
We use GitLab CI/CD to easily and automatically deploy changes to the application code to the various servers. Each code change gets systematically checked for passing unit and feature tests, security, and code style before being integrated. We also aim to add automated accessibility testing to our pipeline within the next couple months.
A lot of data gets crunched while indexing EAD documents through Traject into Solr. Our app uses Resque-based background job processing to handle the transactions. With about 4,000 finding aids, this creates around 900,000 Solr documents; the index is currently a little over 1GB. Changes to data get reindexed and reflected in the UI near-instantaneously. If we ever need to reindex every finding aid, it takes only about one hour to complete.
What We Have Learned
We have been live for just over four months, and we’re really ecstatic with how everything is going.
Usability
In September 2020, our Assessment & User Experience staff conducted ten usability tests using our ArcLight UI, with five experienced archival researchers and five novice users. Kudos to Joyce Chapman, Candice Wang, and Anh Nguyen for their excellent work. Their report is available here. The tests were conducted remotely over Zoom due to COVID restrictions. This was our first foray into remote usability testing.
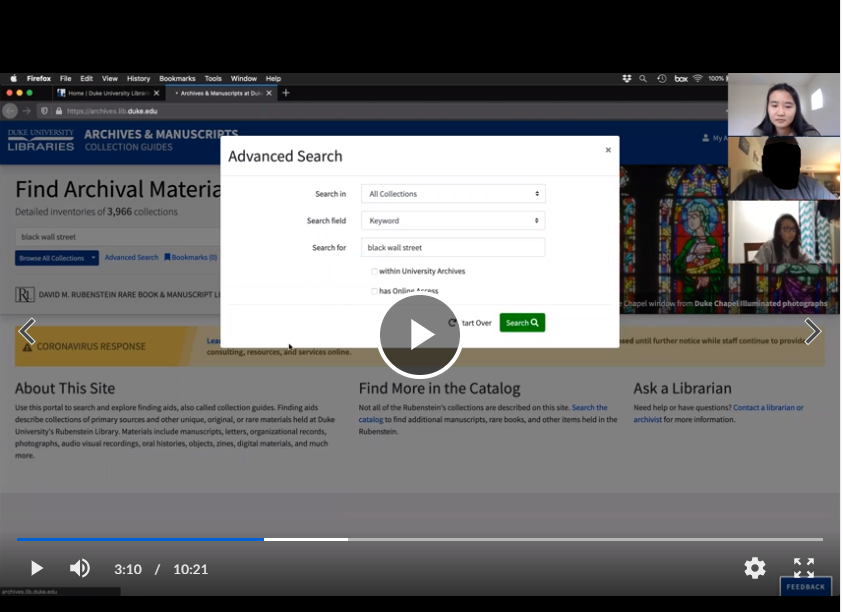
Novice and advanced participants alike navigated the site fairly easily and understood the contextual elements in the UI. We’re quite pleased with how well our custom features performed (especially the context sidebar, contents lists, and redesigned breadcrumb trail). The Advanced Search modal got more use than we had anticipated, and it too was effective. We were also somewhat surprised to find that users were not confused by the All Collections vs. This Collection search scope selector when searching the site.
“The interface design does a pretty good job of funneling me to what I need to see… Most of the things I was looking for were in the first place or two I’d suspect they’d be.” — Representative quote from a test participant
A few improvements were recommended as a result of the testing:
make container information clearer, especially within the requesting workflow
improve visibility of the online access facet
make the Show More links in the sidebar context nav clearer
better delineate between collections and series in the breadcrumb
replace jargon with clearer labels, especially “Indexed Terms“
We recently implemented changes to address 2, 3, and 5. We’re still considering options for 1 and 4. Usability testing has been invaluable part of our development process. It’s a joy (and often a humbling experience!) to see your design work put through the paces with actual users in a usability test. It always helps us understand what we’re doing so we can make things better.
Usage
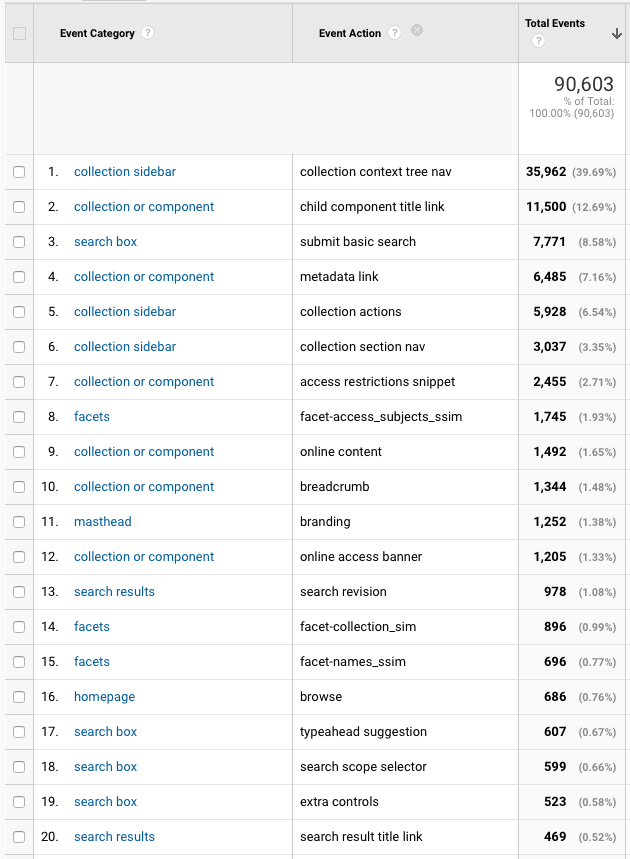
We want to learn more about how often different parts of the UI are used, so we implemented Google Analytics event tracking to anonymously log interactions. We use the Anonymize IP feature to help protect patron privacy.
Top Google Analytics event categories & actions, Jul 1 – Nov 20, 2020.
Some observations so far:
The context nav sidebar is by far the most interacted-with part of the UI.
Browsing the Contents section of a component page (list of direct child components) is the second-most frequent interaction.
Subject, Collection, & Names are the most-used facets, in that order. That does not correlate with the order they appear in the sidebar.
Links presented in the Online Access banners were clicked 5x more often than the limiter in the Online Access facet (which matches what we found in usability testing)
Basic keyword searches happen 32x more frequently than advanced searches
Search Engine Optimization (SEO)
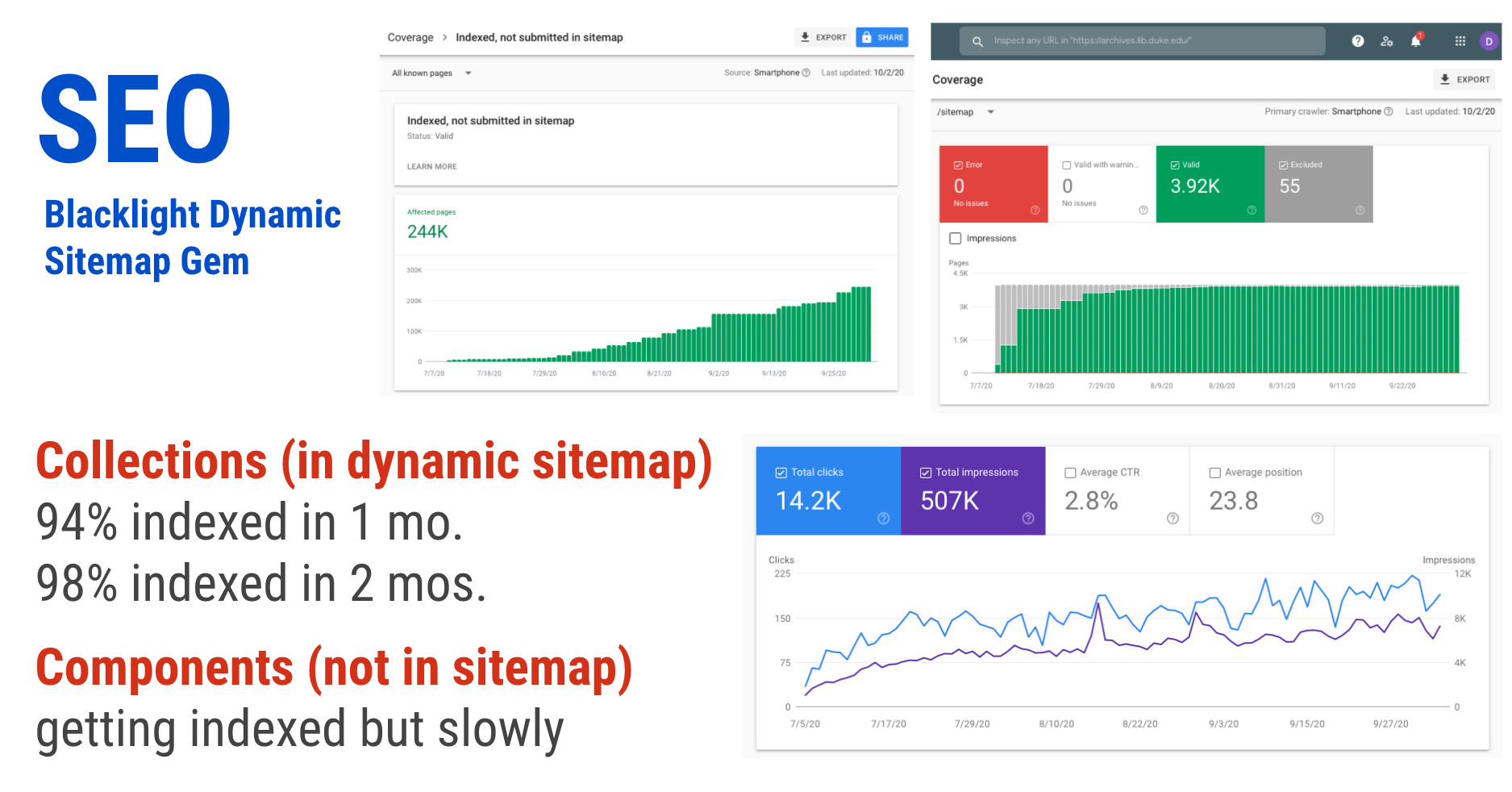
We want to be sure that when people search Google for terms that appear in our finding aids, they discover our resources. So when several Blacklight community members combined forces to create a Blacklight Dynamic Sitemaps gem this past year, it caught our eye. We found it super easy to set up, and it got the vast majority of our collection records Google-indexed within a month or so. We are interested in exploring ways to get it to include the component records in the sitemap as well.
Launching ArcLight: Retrospective
We’re pretty proud of how this all turned out. We have accomplished a lot in a relatively short amount of time. And the core software will only improve as the community grows.
At Duke, we already use Blacklight to power a bunch of different discovery applications in our portfolio. And given that the responsibility of supporting ArcLight falls to the same staff who support all of those other apps, it has been unquestionably beneficial for us to be able to work with familiar tooling.
We did encounter a few hurdles along the way, mostly because the software is so new and not yet widely adopted. There are still some rough edges that need to be smoothed out in the core software. Documentation is pretty sparse. We found indexing errors and had to adjust some rules. Relevancy ranking needed a lot of work. Not all of the EAD elements and attributes are accounted for; some things aren’t indexed or displayed in an optimal way.
Still, the pros outweigh the cons by far. With ArcLight, you get an extensible Blacklight-based core, only catered specifically to archival data. All the things Blacklight shines at (facets, keyword highlighting, autosuggest, bookmarks, APIs, etc.) are right at your fingertips. We have had a very good experience finding and using Blacklight plugins to add desired features.
Finally, while the ArcLight community is currently small, the larger Blacklight community is not. There is so much amazing work happening out in the Blacklight community–so much positive energy! You can bet it will eventually pay dividends toward making ArcLight an even better solution for archival discovery down the road.
Acknowledgments
Many thanks go out to our Duke staff members who contributed to getting this project completed successfully. Especially:
Product Owner: Noah Huffman
Developers/DevOps: Sean Aery, David Chandek-Stark, Michael Daul, Cory Lown (scrum master)
Project Sponsors: Will Sexton & Meghan Lyon
Redesign Team: Noah Huffman (chair), Joyce Chapman, Maggie Dickson, Val Gillispie, Brooke Guthrie, Tracy Jackson, Meghan Lyon, Sara Seten Berghausen
And thank you as well to the Stanford University Libraries staff for spearheading the ArcLight project.
This post was updated on 1/7/21, adding the embedded video recording of the Oct 2020 Blacklight Summit ArcLight presentation.
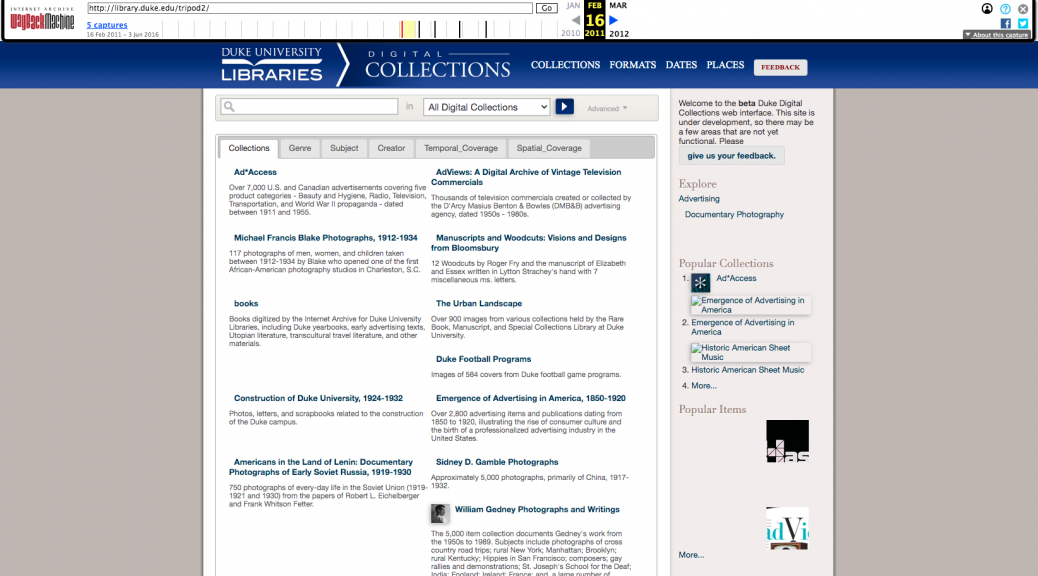
Featured image – Wayback Machine capture of the Tripod2 beta site in February, 2011.
We all design and create platforms that work beautifully for us, that fill us with pride as they expand and grow to meet our programmatic needs, and all the while the world changes around us, the programs scale beyond what we envisioned, and what was once perfectly adaptable becomes unsustainable, appearing to us all of the sudden as a voracious, angry beast, threatening to consume us, or else a rickety contraption, teetering on the verge of a disastrous collapse. I mean, everyone has that experience, right?
In March of 2011, a small team consisting primarily of me and fellow developer Sean Aery rolled out a new, homegrown platform, Tripod2. It became the primary point of access for Duke Digital Collections, the Rubenstein Library’s collection guides, and a handful of metadata-only datasets describing special collections materials. Within a few years, we had already begun talking about migrating all the Tripod2 stuff to new platforms. Yet nearly a decade after its rollout, we still have important content that depends on that platform for access.
Nevertheless, we have made significant progress. Sunsetting Tripod2 became a priority for one of the teams in our Digital Preservation and Publishing Program last year, and we vowed to follow through by the end of 2020. We may not make that target, but we do have firm plans for the remaining work. The migration of digital collections to the Duke Digital Repository has been steady, and nears its completion. This past summer, we rolled out a new platform for the Rubenstein collection guides, based on the ArcLight framework. And now have a plan to handle the remaining instances of metadata-only databases, a plan that itself relies on the new collection guides platform.
We built Tripod2 on the triptych of Python/Django, Solr, and a document base of METS files. There were many areas of functionality that we never completely developed, but it gave us a range of capability that was crucial in our thinking about digital collections a decade ago – the ability to customize, to support new content types, and to highlight what made each digital collection unique. In fact, the earliest public statement that I can find revealing the existence of Tripod2 is Sean’s blog post, “An increasingly diverse range of formats,” from almost exactly ten years ago. As Sean wrote then, “dealing with format complexity is one of our biggest challenges.”
As the years went by, a number of factors made it difficult to keep Tripod2 current with the scope of our programs and the changing of web technology. The single most prevalent factor was the expanding scope of the Duke Digital Collections program, which began to take on more high-volume digitization efforts. We started adding all of our new digital collections to the Duke Digital Repository (DDR) starting in 2015, and the effort to migrate from Tripod2 to the repository picked up soon thereafter. That work was subject to all sorts of comical and embarrassing misestimations by myself on the pages of this very blog over the years, but thanks to the excellent work by Digital Collections and Curation Services, we are down to the final stages.
Collection and item counters from the Duke Digital Repository’s homepage for Duke Digital Collections, taken from the Internet Archive’s Wayback Machine, approximately a year apart in 2018, 2019, and 2020. The volume of digital collections has roughly doubled in that time, due to both the addition of new collections, and the migration of collections from Tripod2.
Moving digital collections to the DDR went hand-in-hand with far less customization, and far less developer intervention to publish a new collection. Where we used to have developers dedicated to individual platforms, we now work together more broadly as a team, and promote redundancy in our development and support models as much as we can. In both our digital collections program and our approach to software development, we are more efficient and more process-driven.
Given my record of predictions about our work on this blog, I don’t want to be too forward in announcing this transition. We all know that 2020 doesn’t suffer fools gladly, or maybe it suffers some of them but not others, and maybe I shouldn’t talk about 2020 just like this, right out in the open, where 2020 can hear me. So I’ll just leave it here – in recent times, we have done a lot of work toward saying goodbye to Tripod2. Perhaps soon we shall.
Last week the Duke University Libraries (DUL) development team released a new version of the Duke Digital Repository (DDR), which is the preservation and access platform for digitized, born digital, and purchased library collections. DDR is developed and maintained by DUL staff and it is built using Samvera, Valkyrie and Blacklight components (read all about our migration to Valkyrie which concluded in early 2020).
Look at that beautiful technical metadata!
The primary goal of our new repository features are to provide better support for and access to born digital records. The planning for this work began more than 2 years ago, when the Rubenstein Libraries’ Digital Records Archivist joined the Digital Collections Implementation Team (DCIT) to help us envision how DDR and our workflows could better support born digital collections. Conversations on this topic began between the Rubenstein Library and Digital Strategies and Technology well before that.
Back in 2018, DCIT developed a list of user stories to address born digital records as well as some other longstanding needs. At the time we evaluated each need based on its difficult and impact and then developed a list of high, medium and low priority features. Fast forward to late 2019, and we designated 3 folks from DCIT to act as product owners during development. Those folks are our Metadata Architect (Maggie Dickson), Digital Records Archivist ([Matthew] farrell), and me (Head of Digital Collections and Curation Services). Development work began in earnest in Jan/February and now after many meetings, user story refinements, more meetings, and actual development work here we are!
Notable new features include:
Metadata only view of objects: restrict the object but allow the public to search and discover its metadata
Expose technical metadata for components in the public interface
Better access to full text search in CONTENTdm from DDR
As you can see above we were able to fit in a few non-born digital records related features. This is because one of our big priorities is finishing the migration from our legacy Tripod 2 platform to DDR in 2020. One of the impediments to doing so (in addition migrating the actual content) is that Tripod 2 connects with our CONTENTdm instance, which is where we provide access to digitized primary sources that require full text search (newspapers and publications primarily). The new DDR features therefor include enhanced links to our collections in CONTENTdm.
We hope these new features provide a better experience for our users as well as a safe and happy home for our born digital records!
Search full text link on a collection landing page.Example of the search within an item interface
On January 20, 2020, we kicked off our first development sprint for implementing ArcLight at Duke as our new finding aids / collection guides platform. We thought our project charter was solid: thorough, well-vetted, with a reasonable set of goals. In the plan was a roadmap identifying a July 1, 2020 launch date and a list of nineteen high-level requirements. There was nary a hint of an impending global pandemic that could upend absolutely everything.
The work wasn’t supposed to look like this, carried out by zooming virtually into each other’s living rooms every day. Code sessions and meetings now require navigating around child supervision shifts and schooling-from-home responsibilities. Our new young office-mates occasionally dance into view or within earshot during our calls. Still, we acknowledge and are grateful for the privilege afforded by this profession to continue to do our work remotely from safe distance.
So, a major shoutout is due to my colleagues in the trenches of this work overcoming the new unforeseen constraints around it, especially Noah Huffman, David Chandek-Stark, and Michael Daul. Our progress to date has only been possible through resilience, collaboration, and willingness to keep pushing ahead together.
Three months after we started the project, we remain on track for a summer 2020 launch.
As a reminder, we began with the core open-source ArcLight platform (demo available) and have been building extensions and modifications in our local application in order to accommodate Duke needs and preferences. With the caveat that there’ll be more changes coming over the next couple months before launch, I want to provide a summary of what we have been able to accomplish so far and some issues we have encountered along the way. Duke staff may access our demo app (IP-restricted) for an up-to-date look at our work in progress.
Homepage
Homepage design for Duke’s ArcLight finding aids site.
Duke Branding. Aimed to make an inviting front door to the finding aids consistent with other modern Duke interfaces, similar to–yet distinguished enough from–other resources like the catalog, digital collections, or Rubenstein Library website.
Featured Items. Built a configurable set of featured items from the collections (with captions), to be displayed randomly (actual selections still in progress).
Dynamic Content. Provided a live count of collections; we might add more indicators for types/counts of materials represented.
Layout
A collection homepage with a sidebar for context navigation.
Sidebar. Replaced the single-column tabbed layout with a sidebar + main content area.
Persistent Collection Info. Made collection & component views more consistent; kept collection links (Summary, Background, etc.) visible/available from component pages.
Width. Widened the largest breakpoint. We wanted to make full use of the screen real estate, especially to make room for potentially lengthy sidebar text.
Navigation
Component pages contextualized through a sidebar navigator and breadcrumb above the main title.
Hierarchical Navigation. Restyled & moved the hierarchical tree navigation into the sidebar. This worked well functionally in ArcLight core, but we felt it would be more effective as a navigational aid when presented beside rather than below the content.
Tooltips & Popovers. Provided some additional context on mouseovers for some navigational elements.
Mouseover context in navigation.
List Child Components. Added a direct-child list in the main content for any series or other component. This makes for a clear navigable table of what’s in the current series / folder / etc. Paginating it helps with performance in cases where we might have 1,000+ sibling components to load.
Breadcrumb Refactor. Emphasized the collection title. Kept some indentation, but aimed for page alignment/legibility plus a balance of emphasis between current component title and collection title.
Breadcrumb trail to show the current component’s nesting.
Search Results
Search results grouped by collection, with keyword highlighting.
“Group by Collection” as the default. Our stakeholders were confused by atomized components as search results outside of the context of their collections, so we tried to emphasize that context in the default search.
Revised search result display. Added keyword highlighting within result titles in Grouped or All view. Made Grouped results display checkboxes for bookmarking & digitized content indicators.
Advanced Search. Kept the global search box simple but added a modal Advanced search option that adds fielded search and some additional filters.
Digital Objects Integration
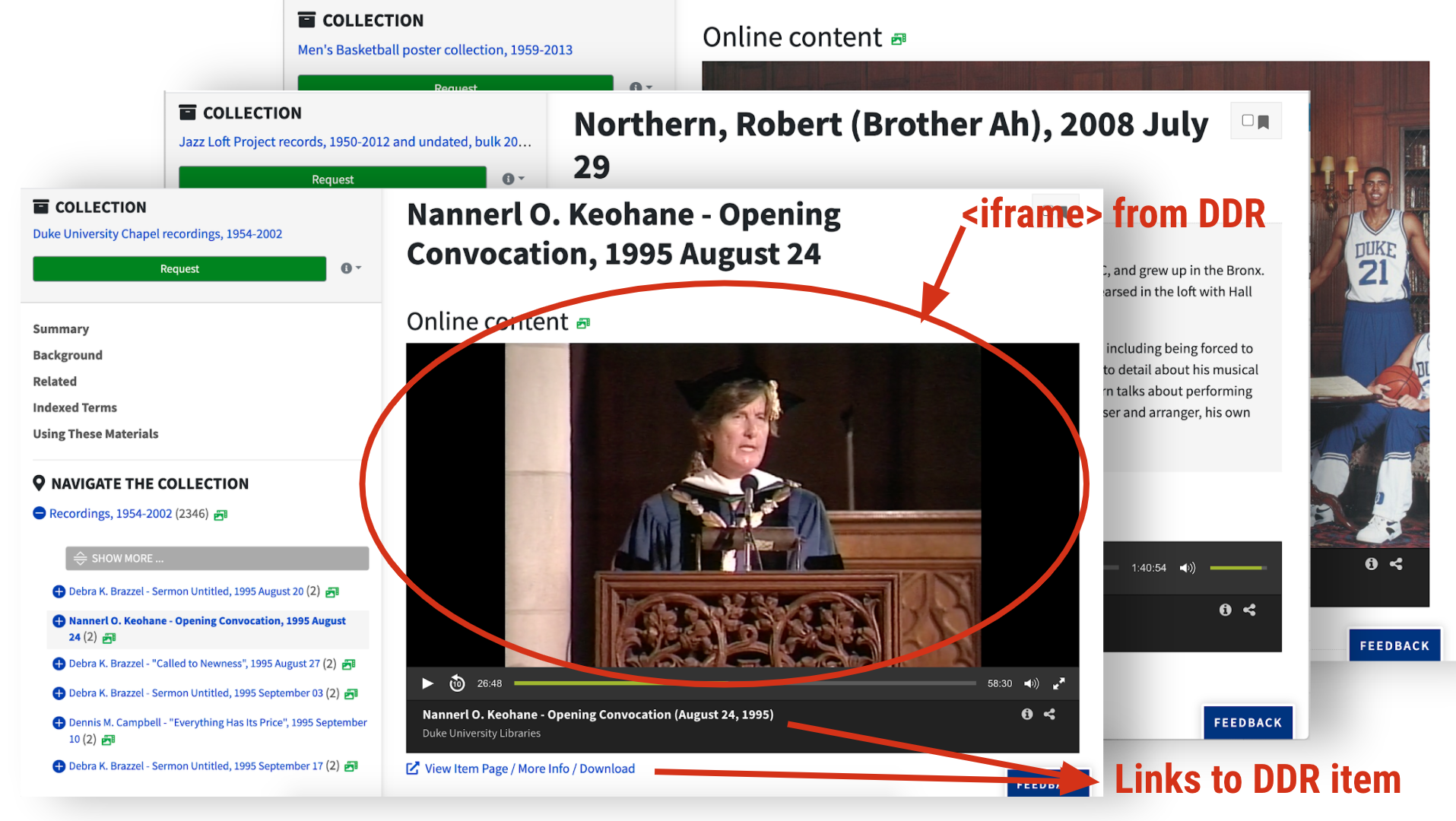
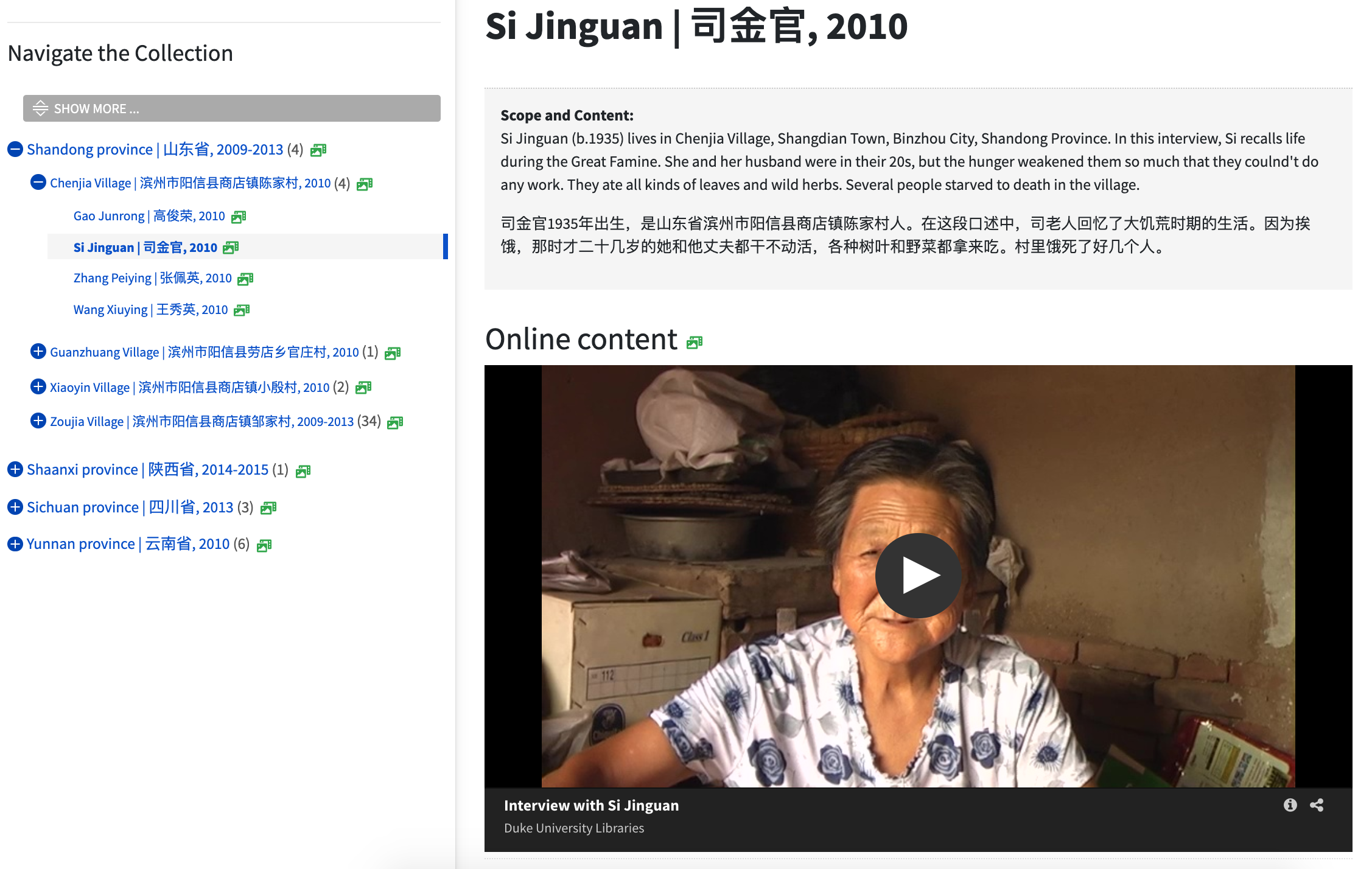
Digital objects from the Duke Digital Repository are presented inline in the finding aid component page.
DAO Roles. Indexed the @role attribute for <dao> elements; we used that to call templates for different kinds of digital content
Embedded Object Viewers. Used the Duke Digital Repository’s embed feature, which renders <iframe>s for images and AV.
Indexing
Whitespace compression. Added a step to the pipeline to remove extra whitespace before indexing. This seems to have slightly accelerated our time-to-index rather than slow it down.
More text, fewer strings. We encountered cases where note-like fields indexed as strings by ArcLight core (e.g., <scopecontent>) needed to be converted to text because we had more than 32,766 bytes of data (limit for strings) to put in them. In those cases, finding aids were failing to index.
Underscores. For the IDs that end up in a URL for a component, we added an underscore between the finding aid slug and the component ID. We felt these URLs would look cleaner and be better for SEO (our slugs often contain names).
Dates. Changed the date normalization rules (some dates were being omitted from indexing/display)
Bibliographic ID. We succeeded in indexing our bibliographic IDs from our EADs to power a collection-level Request button that leads a user to our homegrown requests system.
Formatting
EAD -> HTML. We extended the EAD-to-HTML transformation rules for formatted elements to cover more cases (e.g., links like <extptr> & <extref> or other elements like <archref> & <indexentry>)
Additional formatting and link render rules applied.
Formatting in Titles. We preserved bold or italic formatting in component titles.
ArcLight Core Contributions
We have been able to contribute some of our code back to the ArcLight core project to help out other adopters.
Setting the Stage
The behind-the-scenes foundational work deserves mention here — it represents some of the most complex and challenging aspects of the project. It makes the application development driving the changes I’ve shared above possible.
Gathered a diverse set of 40 representative sample EADs for testing
Dockerized our Duke ArcLight app to simplify developer environment setup
Provisioned a development/demo server for sharing progress with stakeholders
Automated continuous integration and deployment to servers using GitLabCI
Performed targeted data cleanup
Successfully got all 4,000 of our finding aids indexed in Solr on our demo server
Our team has accomplished a lot in three months, in large part due to the solid foundation the ArcLight core software provides. We’re benefiting from some amazing work done by many, many developers who have contributed their expertise and their code to the Blacklight and ArcLight codebases over the years. It has been a real pleasure to be able to build upon an open source engine– a notable contrast to our previous practice of developing everything in-house for finding aids discovery and access.
Still, much remains to be addressed before we can launch this summer.
The Road Ahead
Here’s a list of big things we still plan to tackle by July (other minor revisions/bugfixes will continue as well)…
ASpace -> ArcLight. We need a smoother publication pipeline to regularly get data from ArchivesSpace indexed into ArcLight.
Access & Use Statements. We need to revise the existing inheritance rules and make sure these statements are presented clearly. It’s especially important when materials are indeed restricted.
Relevance Ranking. We know we need to improve the ranking algorithm to ensure the most relevant results for a query appear first.
Analytics. We’ll set up some anonymized tracking to help monitor usage patterns and guide future design decisions.
Sitemap/SEO. It remains important that Google and other crawlers index the finding aids so they are discoverable via the open web.
Accessibility Testing / Optimization. We aim to comply with WCAG2.0 AA guidelines.
Single-Page View. Many of our stakeholders are accustomed to a single-page view of finding aids. There’s no such functionality baked into ArcLight, as its component-by-component views prioritize performance. We might end up providing a downloadable PDF document to meet this need.
More Data Cleanup. ArcLight’s feature set (especially around search/browse) reveals more places where we have suboptimal or inconsistent data lurking in our EADs.
More Community Contributions. We plan to submit more of our enhancements and bugfixes for consideration to be merged into the core ArcLight software.
If you’re a member of the Duke community, we encourage you toexplore our demo and provide feedback. To our fellow future ArcLight adopters, we would love to hear how your implementations or plans are shaping up, and identify any ways we might work together toward common goals.
There is a particular fondness that I hold for digital photograph collections. If I had to pinpoint when this began, then I would have to say it started while digitizing material on a simple Epson flatbed scanner as an undergraduate student worker in the archives.
Witnessing the physical become digital is a wonder that never gets old.
Every day we are generating digital content. Pet pics. Food pics. Selfies. Gradually building a collection of experiences as we document our lives in images. Sporadic born digital collections stored on devices and in the cloud.
I do not remember the last time I printed a photograph.
My parents have photo albums that I love. Seeing images of them, then us. The tacky adhesive and the crinkle of thin plastic film as it is pulled back to lift out a photo. That perfect square imprint left behind from where the photo rested on the page.
Pretty sure that Polaroid camera is still around somewhere.
Time bound up in a book.
Beyond their visual appeal, I appreciate how photos capture time. Nine months have passed since I moved to North Carolina. I started 2019 in Chicago and ended it in Durham. These photos of my Winter in both places illustrate that change well.
Sometimes I want to pull down my photos from the cloud and just print everything. Make my own album. Have something with heft and weight to share and say, “Hey, hold and look at this.” That sensory experience is invaluable.
Yet, I also value the convenience of being able to view hundreds of photos with the touch of a button.
Duke University Libraries offers access to thousands of images through its Digital Collections.
Here’s a couple photo collections to get you started:
After nearly a year of work, the libraries recently launched an updated version of the software stack that powers parts the Duke Digital Repository. This work primarily centered around migrating the underlying software in our Samvera implementation — which we use to power the DDR — from ActiveFedora to Valkyrie. Moving to Valkyrie gives us the benefits of improved stability along with the flexibility to use different storage solutions, which in turn provides us with options and some degree of future-proofing. Considerable effort was also spent on updating the public and administrative interfaces to use more recent versions of blacklight and supporting software.
Administrative interface for the DDR
We also used this opportunity to revise the repository landing page at repository.duke.edu and I was involved in building a new version of the home page. Our main goals were to make use of a header implementation that mirrored our design work in other recent library projects and that integrated our ‘unified’ navigation, while also maintaining the functionality required by the Samvera software.
DDR home page before the redesign
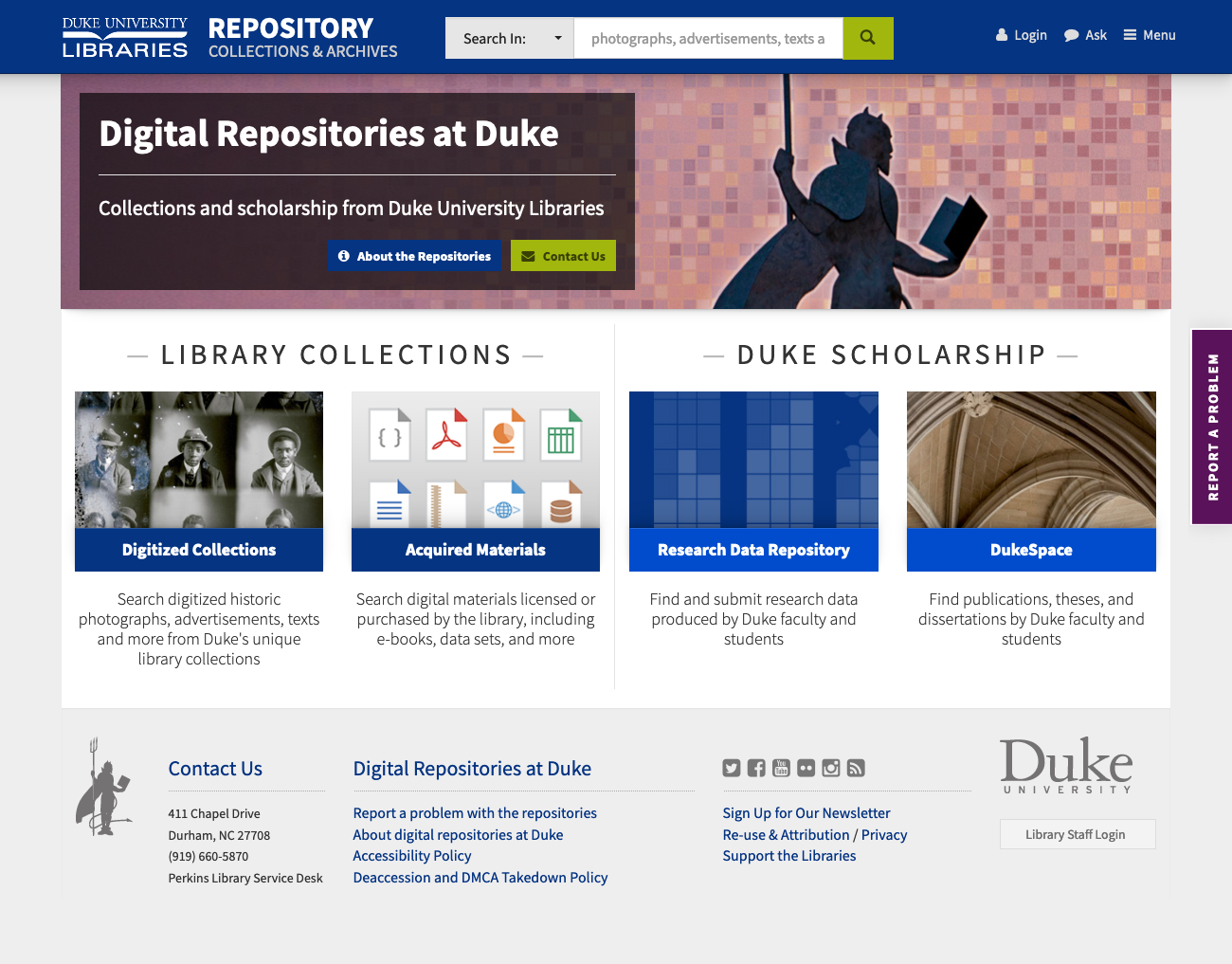
We also spent a lot of time thinking about how best to illustrate the components of the Duke Digital Repository while trying to keep the content simple and streamlined. In the end we went with a design that emphasizes the two branches of the repository; Library Collections and Duke Scholarship. Each branch in turn links to two destinations — Digitized Collections / Acquired Materials and the Research Data Repository / DukeSpace. The overall design is more compact than before and hopefully an improvement aesthetically as well.
Redesigned DDR home page
We also incorporated a feedback form that is persistent across the interface so that users can more readily report any difficulties they encounter while using the platform. And finally, we updated the content in the footer to help direct users to the content they are more than likely looking for.
Future plans include incorporating our header and footer content more consistently across the repository platforms along with bringing a more unified look and feel to interface components.
Check out the new design and let us know what you think!
Notes from the Duke University Libraries Digital Projects Team