As we’ve been adding features and refining the public interface to Duke’s Digital Repository, the application has become increasingly slow. Don’t worry, the very slowest versions were never deployed beyond our development servers. This blog post is about how I approached addressing the application’s performance problems before they made their way to our production site.

A modern web application, like the public interface to Duke’s Digital Repository, is a complex beast, relying on layers of software and services just to deliver a bunch of HTML, CSS, and JavaScript to your web browser. A page like this, the front page to the Alex Harris collection takes a lot to build — code to read configuration files, methods that assemble information needed to build the page, requests to Solr to find the images to display, requests to a separate administrative application service that provides contact information for the collection, another request to fetch related blog posts, and requests to our finding aid application to deliver information about the physical collection. All of these requests take time and all of them have to finish before anything gets delivered to your browser.
My main suspects for the slowness: HTTP requests to external services, such as the ones mentioned above; and repeated calls to slow methods in the application. But identifying precisely which HTTP requests are slow and what code needs to be optimized takes a bit of sleuthing.
The first thing I wanted to know was: how slow is this thing, really? Turns out it was getting getting really slow. Too slow. There’s old research (1960s old) about computer system performance and its impact on user perception and task performance that still applies today. This also old (1993 old) article from the Nielsen Norman Group summarizes the issue nicely.
To determine just how slow things were getting I used Chrome’s developer tools. The “Network” tab in Chrome’s developer tools is where the hard truth comes to light about just how bloated and slow your web application is. Or, as my high school teachers used to say when handing back test results: “read ’em and weep.”
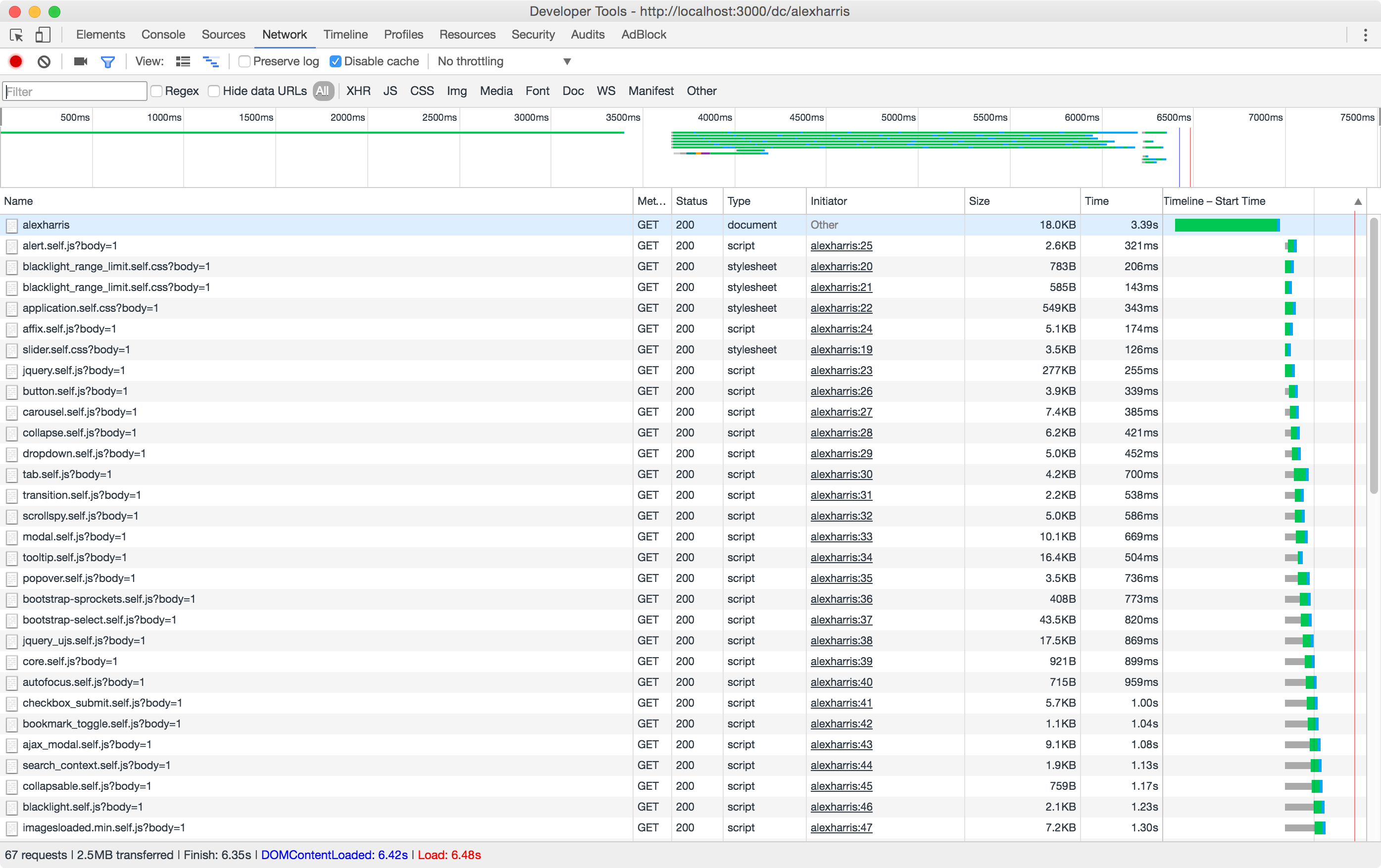
By using the Network tab in Browser Tools I was able to see that the browser was having to wait 15 or more seconds for anything to come back from the server. This is too slow.
The next thing I wanted to know was how many HTTP requests were being made to external services and which ones were being made repeatedly or were taking a long time. For this dose of reality I used the httplog gem, which logs useful information about every HTTP request, including how long the application has to wait for a response.
When added to the project’s Gemfile, httplog starts printing out useful information to the log about HTTP requests, such as this set of entries about the request to fetch finding aid information. I can see that the application is waiting over half a second to get a response back from the finding aid service:
D, [2016-08-06T12:51:09.531076 #2529] DEBUG -- : [httplog] Connecting: library.duke.edu:80
D, [2016-08-06T12:51:09.854003 #2529] DEBUG -- : [httplog] Sending: GET http://library.duke.edu:80/rubenstein/findingaids/harrisalex.xml
D, [2016-08-06T12:51:09.855387 #2529] DEBUG -- : [httplog] Data:
D, [2016-08-06T12:51:10.376456 #2529] DEBUG -- : [httplog] Status: 200
D, [2016-08-06T12:51:10.377061 #2529] DEBUG -- : [httplog] Benchmark: 0.520600972 seconds
As I expected, this request and many others were contributing significantly to the application’s slowness.
It was a bit harder to determine which parts of the code and which methods were also making the application slow. For this, I mainly used two approaches. The first was to look at the application logs which tracks how long different views take to assemble. This helped narrow down which parts of the code were especially slow (and also confirmed what I was seeing with httplog). For instance in the log I can see different partials that make up the whole page and how long each of them takes to assemble. From the log:
12:51:09 INFO: Rendered digital_collections/_home_featured_collections.html.erb (0.8ms)
12:51:09 INFO: Rendered digital_collections/_home_highlights.html.erb (1.3ms)
12:51:10 INFO: Rendered catalog/_show_finding_aid_full.html.erb (953.4ms)
12:51:11 INFO: Rendered catalog/_show_blog_post_feature.html.erb (0.9ms)
12:51:11 INFO: Rendered catalog/_show_blog_posts.html.erb (914.5ms)
(The finding aid and blog posts are slow due to the aforementioned HTTP requests.)
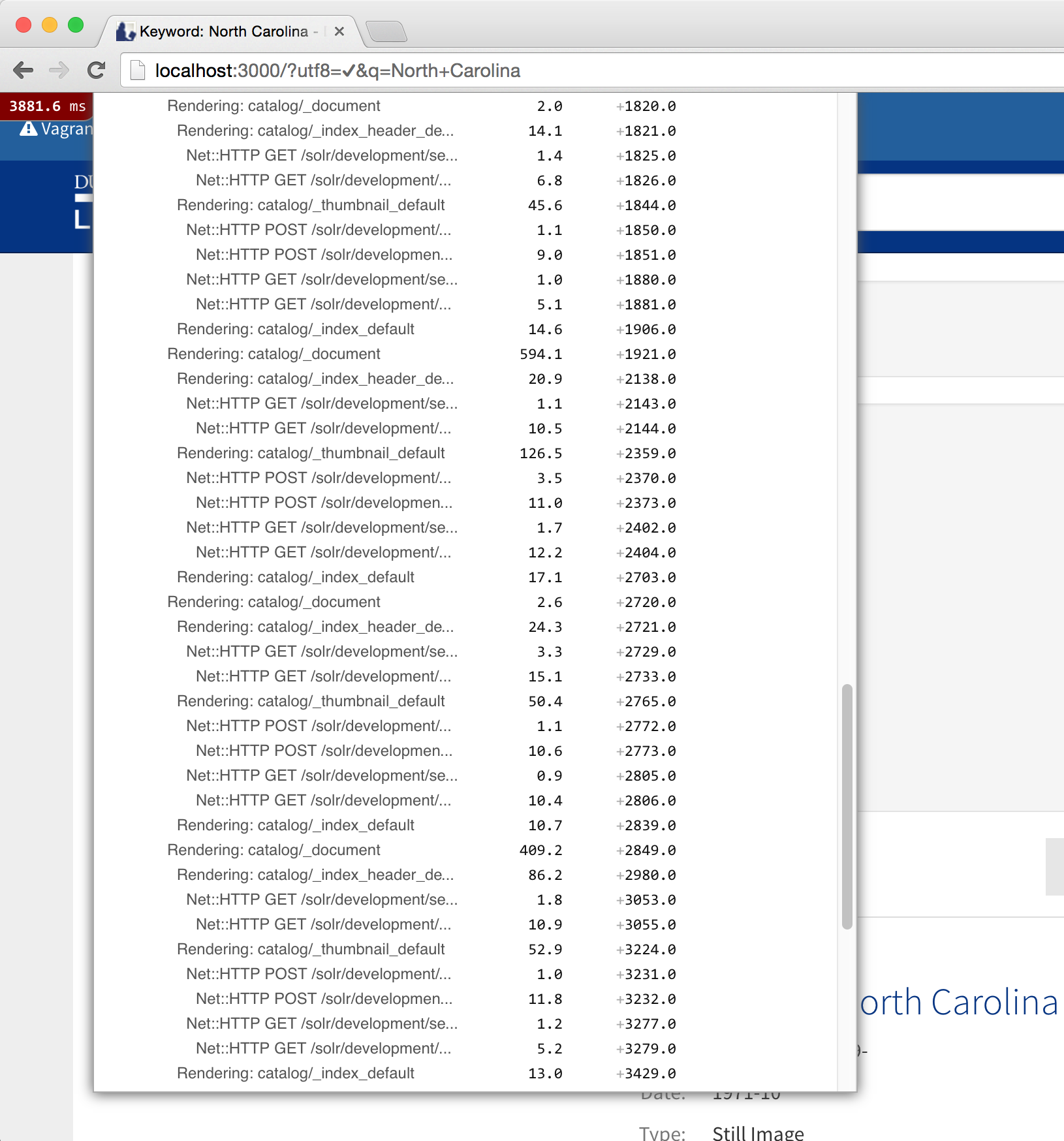
One particular area of concern was extremely slow searches. To identify the problem I turned to yet another tool. Rack-mini-profiler is a gem that when added to your project’s Gemfile adds an expandable tab on every page of the site. When you visit pages of the application in a browser it displays a detailed report of how long it takes to build each section of the page. This made it possible to narrow down areas of the application that were too slow.

What I found was that the thumbnail section of the page — which can appear up to twenty times or more on a search result page was very slow. And it wasn’t loading the images that was slow but running the code to select the correct thumbnail image took a long time to run. (Thumbnail selection is complicated in the repository because there are various types and sources for thumbnails.)
Having identified several contributors to the site’s poor performance (expensive thumbnail selection, and frequent and costly HTTP requests to various services) I could now work to address each of the issues.
I used three different approaches to improving the application’s performance: fragment caching, memoization, and code optimization.
Caching

I decided to use fragment caching to address the slow loading of finding aid information. The benefit of caching is that it’s really fast. Once Rails has the snippet of HTML cached (either in memory or on disk, depending on how it’s configured) it can use that fragment of cached markup, bypassing a lot of code and, in this case, that slow HTTP request. One downside to caching is that if something in the finding aid changes the application won’t reflect the change until the cache is cleared or expires (after 7 days in this case).
<% cache("finding_aid_brief_#{document.ead_id}", expires_in: 7.days) do %>
<%= source_collection({ :document => document, :placement => 'left' }) %>
<% end %>
Memoization
Memoization is similar to caching in that you’re storing information to be used repeatedly rather then recalculated every time. This can be a useful technique to use with expensive (slow) methods that get called frequently. The parent_collection_count method returns the total number of collections in a portal in the repository (such as the Digital Collections portal). This method is somewhat expensive because it first has to run a query to get information about all of the collections and then count them. Since this gets used more than once, I’m using Ruby’s conditional assignment operator (||=) to tell Ruby not to recalculate the value of @parent_collection_count every time the method is called. With memoization, if the value is already stored Ruby just reuses the previously calculated value. (There are some gotchas with this technique, but it’s very useful in the right circumstances.)
def parent_collections_count
@parent_collections_count ||= response(parent_collections_search).total
end
Code Optimization
One of the reasons thumbnails were slow to load in search results is that some items in the repository have hundreds of images. The method used to find the thumbnail path was loading image path information for all the item’s images rather than just the first one. To address this I wrote a new method that fetches just the item’s first image to use as the item’s thumbnail.
Combined, these changes made a significant improvement to the site’s performance. Overall application speed and performance will remain one of our priorities as we add features to the Duke Digital Repository.