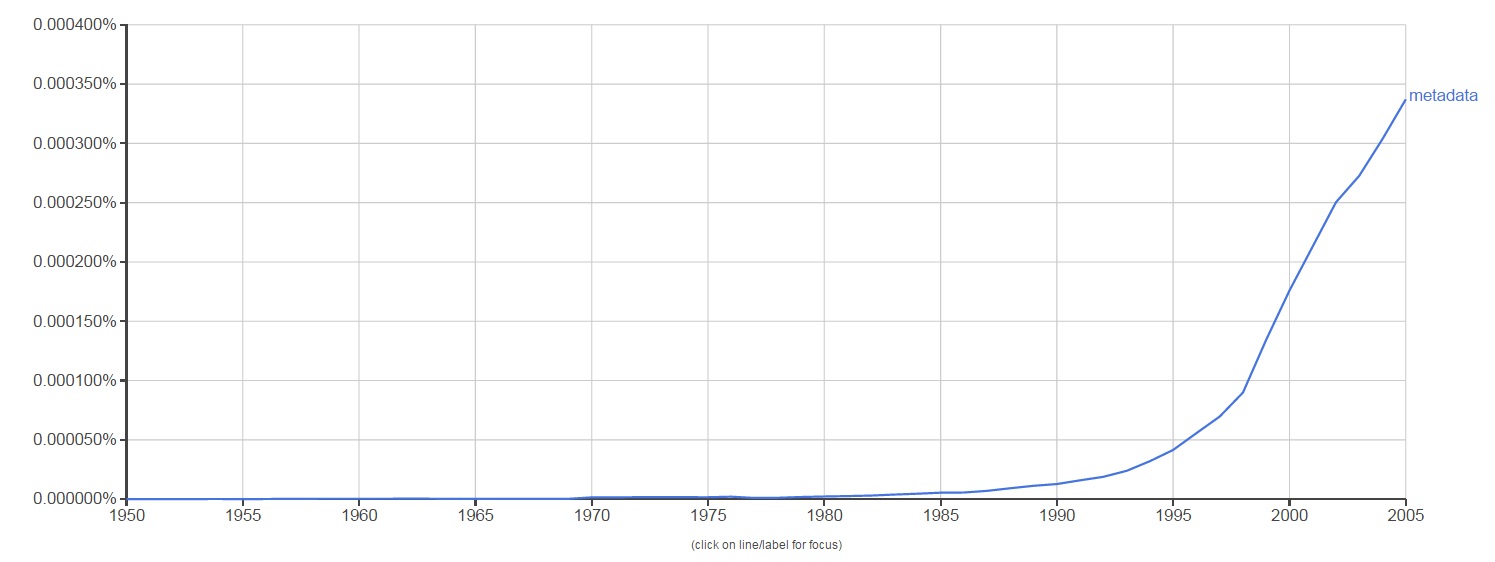The Coronavirus pandemic has me thinking about labor–as a concept, a social process, a political constituency, and the driving force of our economy–in a way that I haven’t in my lifetime. It’s become alarmingly clear (as if it wasn’t before) that we all need food, supplies, and services to survive past next week, and that there are real human beings out there working to produce and deliver these things. No amount of entrepreneurship, innovation, or financial sleight of hand will help us through the coming months if people are not working to provide the basic requirements for life as we know it.
This blog post draws from images in our digitized library collections to pay tribute to all of the essential workers who are keeping us afloat during these challenging times. As I browsed these photographs and mused on our current situation, a few important and oft-overlooked questions came to mind.
Who grows our food? Where does it come from and how is it processed? How does it get to us?
Bell pepper pickers, 1984 June. Paul Kwilecki Photographs.Prisoners at the county farm killing hogs, 1983 Mar. Paul Kwilecki Photographs.Worker atop rail car loading corn from storage tanks, 1991 Sept. Paul Kwilecki Photographs.Manuel Molina, mushroom farm worker, Kennett Square, PA 1981. Frank Espada Photographs.
What kind of physical environment do we work in and how does that affect us?
Maids in a room of the Stephen Decatur Hotel shortly before it was torn down, 1970. Paul Kwilecki PhotographsWorker in pit preparing to weld. Southeastern Minerals Co. Bainbridge, 1991 Aug. Paul Kwilecki PhotographsLoggers in the woods near Attapulgus, 1978 Feb. Paul Kwilecki Photographs.
How do we interact with machines and technology in our work? Can our labor be automated or performed remotely?
Worker signaling for more logs. Elberta Crate and Box. Co. Bainbridge, 1991 Sept. Paul Kwilecki Photographs.Worker, Williamson-Dickie plant. Bainbridge, 1991 Sept. Paul Kwilecki Photographs.Machine operator watching computer controlled lathe, 1991 July. Paul Kwilecki Photographs.Worker at her machine. Elberta Crate and Box Co. Bainbridge, 1981 Nov. Paul Kwilecki Photographs.
What equipment and clothing do we need to work safely and productively?
Cotton gin worker wearing safety glass and ear plugs for noise protection. Decatur Gin Co., 1991 Sept. Paul Kwilecki Photographs.Worker operating bagging machine. Flint River Mills. Bainbridge, 1991 July. Paul Kwilecki Photographs.Worker at State Dock, 1992 July. Paul Kwilecki Photographs.
Are we paid fairly for our work? How do relative wages for different types of work reflect what is valued in our society?
No known title. William Gedney Photographs.
How we think about and respond to these questions will inform how we navigate the aftermath of this ongoing crisis and whether or not we thrive into the future. As we celebrate International Workers’ Day on May 1 and beyond, I hope everyone will take some time to think about what labor means to them and to our society as a whole.
Snow is a major event here in North Carolina, and the University and Library were operating accordingly under a “severe weather policy” last week due to 6-12 inches of frozen precipitation. While essential services continued undeterred, most of the Library’s staff and patrons were asked to stay home until conditions had improved enough to safely commute to and navigate the campus. In celebration of last week’s storm, here are some handy tips for surviving and enjoying the winter weather–illustrated entirely with images from Duke Digital Collections!
Stock up on your favorite vices and indulgences before the storm hits.
2. Be sure to bundle and layer up your clothing to stay warm in the frigid outdoor temperatures.
3. Plan some fun outdoor activities to keep malaise and torpor from settling in.
4. Never underestimate the importance of a good winter hat.
5. While snowed in, don’t let your personal hygiene slip too far.
6. Despite the inconveniences brought on by the weather, don’t forget to see the beauty and uniquity around you.
In the past 3 months, we have launched a number of exciting digital collections! Our brand new offerings are either available now or will be very soon. They are:
International Broadsides (added to migrated Broadsides and Ephemera collection): https://repository.duke.edu/dc/broadsides
Orange County Tax List Ledger, 1875: https://repository.duke.edu/dc/orangecountytaxlist
Radio Haiti Archive, second batch of recordings: https://repository.duke.edu/dc/radiohaiti
William Gedney Finished Prints and Contact Sheets (newly re-digitized with new and improved metadata): https://repository.duke.edu/dc/gedney
A selection from the William Gedney Photographs digital collection
In addition to the brand new items, the digital collections team is constantly chipping away at the digital collections migration. Here are the latest collections to move from Tripod 2 to the Duke Digital Repository (these are either available now or will be very soon):
What we hoped would be a speedy transition is still a work in progress 2 years later. This is due to a variety of factors one of which is that the work itself is very complex. Before we can move a collection into the digital repository it has to be reviewed, all digital objects fully accounted for, and all metadata remediated and crosswalked into the DDR metadata profile. Sometimes this process requires little effort. However other times, especially with older collection, we have items with no metadata, or metadata with no items, or the numbers in our various systems simply do not match. Tracking down the answers can require some major detective work on the part of my amazing colleagues.
Despite these challenges, we eagerly press on. As each collection moves we get a little closer to having all of our digital collections under preservation control and providing access to all of them from a single platform. Onward!
The initial thought I had for this blog post was to describe a slice of my day that revolved around the work of William Gedney. I was going to spin a tale about being on the hunt for a light meter to take lux (luminance) readings used to help calibrate the capture environment of one of our scanners. On my search for the light meter I bumped into the new exhibit of William Gedney’s handmade books displayed in the Chappell Family Gallery in the Perkins Library. I had digitized a number of these books a few months ago and enjoyed pretty much every image in the books. One of the books on display was opened to a particular photograph. To my surprise, I had just digitized a finished print of the same image that very morning while working on a larger project to digitize all of Gedney’s finished prints, proof prints, contact sheets and other material. Once the project is complete (a year or so from now) I will have personally seen, handled and digitized over 20,000 of Gedney’s photographs. Whoa! Would I be able to recognize Gedney images whenever one presented itself just like the book in the gallery? Maybe.
Once the collection is digitized and published through Duke Digital Collections the whole world will be able to see this amazing body of work. Instead of boring you with the details of that story I thought I would just leave you with a few images from the collection. For me, many of Gedney’s photographs have a kinetic energy to them. It seems as if I can almost feel the air. My imagination may be working overtime to achieve this and the reality of what was happening when the photograph was taken may be wholly different but the fact is these photographs spin up my imagination and transport me to the moments he has captured. These photographs inspire me to dust off my enlarger and set up a darkroom.
It may take some time to complete this particular project but there are other William Gedney related projects, materials and events available at Duke.
Life in Duke University Libraries has been even more energetic than usual these past months. Our neighbors in Rubenstein just opened their newly renovated library and the semester is off with a bang. As you can read over on Devil’s Tale, a lot of effort went on behind the scenes to get that sparkly new building ready for the public. In following that theme, today I am sharing some thoughts on how producing digital collections both blesses and curses my perspective on our finished products.
When I write a Bitstreams post, I look for ideas in my calendar and to-do list to find news and projects to share. This week I considered writing about “Ben”, those prints/negs/spreadsheets, and some resurrected proposals I’ve been fostering (don’t worry, these labels shouldn’t make sense to you). I also turned to my list of favorite items in our digital collections; these are items I find particularly evocative and inspiring. While reviewing my favorites with my possible topics in mind (Ben, prints/negs/spreadsheets, etc), I was struck by how differently patrons and researchers must relate to Duke Digital Collections than I do. Where they see a polished finished product, I see the result of a series of complicated tasks I both adore and would sometimes prefer to disregard.
Let me back up and say that my first experience with Duke digital collections projects isn’t always about content or proper names. Someone comes to me with an idea and of course I want to know about the significance of the content, but from there I need to know what format? How many items? Is the collection processed? What kind of descriptive data is available? Do you have a student to loan me? My mind starts spinning with logistics logistics logistics. These details take on a life of their own separate from the significant content at hand. As a project takes off, I come to know a collection by its details, the web of relationships I build to complete the project, and the occasional nickname. Lets look at a few examples.
There are so many Gedney favorites to choose from, here is just one of mine.
Parts of this collection are published, but we are expanding and improving the online collection dramatically.
What the public sees: poignant and powerful images of everyday life in an array of settings (Brooklyn, India, San Francisco, Rural Kentucky, and others).
What I see: 50,000 items in lots of formats; this project could take over DPC photographic digitization resources, all publication resources, all my meetings, all my emails, and all my thoughts (I may be over dramatizing here just a smidge). When it all comes together, it will be amazing.
Benjamin Rush Papers We have just begun working with this collection, but the Devil’s Tale blog recently shared a sneak preview.
What people will see: letters to and from fellow founding fathers including Thomas Jefferson (Benjamin Rush signed the Declaration of Independence), as well as important historical medical accounts of a Yellow Fever outbreak in 1793.
What I see: Ben or when I’m really feeling it, Benny. We are going to test out an amazing new workflow between ArchivesSpace and DPC digitization guides with Ben.
Mangum’s negatives show a diverse range of subjects. I highly recommend his exterior images as well.
This collection of photographs was published in 2008. Since then we have added more images to it, and enhanced portions of the collection’s metadata.
What others see: a striking portfolio of a Southern itinerant photographer’s portraits featuring a diverse range of people. Mangum also had a studio in Durham at the beginning of his career.
What I see: HMP. HMP is the identifier for the collection included in every URL, which I always have to remind myself when I’m checking stats or typing in the URL (at first I think it should be Mangum). HMP is sneaky, because every now and then the popularity of this collection spikes. I really want more people to get to know HMP.
They may not be orphans but they are “cave children”.
The Orphans
The orphans are not literal children, but they come in all size and shapes, and span multiple collections.
What the public sees: the public doesn’t see these projects.
What I see: orphans – plain and simple. The orphans are projects that started, but then for whatever reason didn’t finish. They have complicated rights, metadata, formats, or other problems that prevent them from making it through our production pipeline. These issues tend to be well beyond my control, and yet I periodically pull out my list of orphans to see if their time has come. I feel an extra special thrill of victory when we are able to complete an orphan project; the Greek Manuscripts are a good example. I have my sights set on a few others currently, but do not want to divulge details here for fear of jinxing the situation.
Don’t we all want to be in a digital collections land where the poppies bloom?
I could go on and on about how the logistics of each project shapes and re-shapes my perspective of it. My point is that it is easy to temporarily lose sight of the digital collections garden given how entrenched (and even lost at times) we are in the weeds. For my part, when I feel like the logistics of my projects are overwhelming, I go back to my favorites folder and remind myself of the beauty and impact of the digital artifacts we share with the world. I hope the public enjoys them as much as I do.
We experience a number of different cycles in the Digital Projects and Production Services Department (DPPS). There is of course the project lifecycle, that mysterious abstraction by which we try to find commonalities in work processes that can seem unique for every case. We follow the academic calendar, learn our fate through the annual budget cycle, and attend weekly, monthly, and quarterly meetings.
The annual reporting cycle at Duke University Libraries usually falls to departments in August, with those reports informing a master library report completed later. Because of the activities and commitments around the opening of the Rubenstein Library, the departments were let off the hook for their individual reports this year. Nevertheless, I thought I would use my turn in the Bitstreams rotation to review some highlights from our 2014-15 cycle.
In a recent feature on their blog, our colleagues at NCSU Libraries posted some photographs of dogs from their collections. Being a person generally interested in dogs and old photographs, I became curious where dogs show up in Duke’s Digital Collections. Using very unsophisticated methods, I searched digital collections for “dogs” and thought I’d share what I found.
Of the 60 or so collections in Digital Collections 19 contain references to dogs. The table below lists the collections in which dogs or references to dogs appear most frequently.
As you might guess, not all the results for my search were actually photographs of dogs. Many from the advertising collections were either advertisements for dog food or hot dogs. There were quite a few ads and other materials where the word “dog” was used idiomatically. The most surprising finding to me was number of songs that are about or reference dogs. These include, “Old Dog Tray” and “The Whistler and His Dog” from Historic American Sheet Music, as well as “A Song for Dogs” and “Bull Dog an’ de Baby” from American Song Sheets.
Here’s a sampling of some photographs of dogs from Digital Collections, and a few cats as well.
Children are smoking in two of my favorite images from our digital collections.
One of them comes from the eleven days in 1964 that William Gedney spent with the Cornett family in Eastern Kentucky. A boy, crusted in dirt, clutching a bent-up Prince Albert can, draws on a cigarette. It’s a miniature of mawkish masculinity that echoes and lightly mocks the numerous shots Gedney took of the Cornett men, often shirtless and sitting on or standing around cars, smoking.
At some point in the now-distant past, while developing and testing our digital collections platform, I stumbled on “smoking dirt boy” as a phrase to use in testing for cases when a search returns only a single result. We kind of adopted him as an unofficial mascot of the digital collections program. He was a mini-meme, one we used within our team to draw chuckles, and added into conference presentations to get some laughs. Everyone loves smoking dirt boy.
It was probably 3-4 years ago that I stopped using the image to elicit guffaws, and started to interrogate my own attitude toward it. It’s not one of Gedney’s most powerful photographs, but it provokes a response, and I had become wary of that response. There’s a very complicated history of photography and American poverty that informs it.
Screen shot from a genealogy site discussion forum, regarding the Cornett family and William Gedney’s involvement with them.
While preparing this post, I did some research into the Cornett family, and came across the item from a discussion thread on a genealogy site, shown here in a screen cap. “My Mother would not let anyone photograph our family,” it reads. “We were all poor, most of us were clean, the Cornetts were another story.” It captures the attitudes that intertwine in that complicated history. The resentment toward the camera’s cold eye on Appalachia is apparent, as is the disdain for the family that implicitly wasn’t “clean,” and let the photographer shoot. These attitudes came to bear in an incident just this last spring, in which a group in West Virginia confronted traveling photographers whom they claimed photographed children without permission.
The photographer Roger May has undertaken an effort to change “this visual definition of Appalachia.” His “Looking at Appalachia” project began with a series of three blog posts on William Gedney’s Kentucky photographs (Part 1, Part 2, Part 3). The New York Times’ Lens blog wrote about the project last month. His perspective is one that brings insight and renewal to Gedney’s work
Gedney’s photographs have taken on a life as a digital collection since they were published on the Duke University Libraries’ web site in 1999. It has become a high-use collection for the Rubenstein Library; that use has driven a recent project we have undertaken in the library to re-process the collection and digitize the entire corpus of finished prints, proof prints, and contact sheets. We expect the work to take more than a year and produce more than 20,000 images (compared to the roughly 5000 available now), but when it’s complete, it should add whole new dimensions to the understanding of Gedney’s work.
Another collection given life by its digitization is the Sidney Gamble Photographs. The nitrate negatives are so flammable that the library must store them off site, making access impossible without some form of reproduction. Digitization has made it possible for anyone in the world to experience Gamble’s remarkable documentation of China in the early 20th Century. Since its digitization, this collection has been the subject of a traveling exhibit, and will be featured in the Photography Gallery of the Rubenstein Library’s new space when it opens in August.
The photograph of the two boys in the congee distribution line is another favorite of mine. Again, a child is seen smoking in a context that speaks of poverty. There’s plenty to read in the picture, including the expressions on the faces of the different boys, and the way they press their bowls to their chests. But there are two details that make this image rich with implicit narrative – the cigarette in the taller boy’s mouth, and the protective way he drapes his arm over the shorter one. They have similar, close-cropped haircuts, which are also different from the other boys, suggesting they came from the same place. It’s an immediate assumption that the boys are brothers, and the older one has taken on the care and protection of the younger.
Still, I don’t know the full story, and exploring my assumptions about the congee line boys might lead me to ask probing questions about my own attitudes and “visual definition” of the world. This process is one of the aspects of working with images that makes my work rewarding. Smoking dirt boy and the congee line boys are always there to teach me more.
Before you let your eyes glaze over at the thought of metadata, let me familiarize you with the term and its invaluable role in the creation of the library’s online Digital Collections. Yes, metadata is a rather jargony word librarians and archivists find themselves using frequently in the digital age, but it’s not as complex as you may think. In the most simplistic terms, the Society of American Archivists defines metadata as “data about data.” Okay, what does that mean? According to the good ol’ trusty Oxford English Dictionary, it is “data that describes and gives information about other data.” In other words, if you have a digitized photographic image (data), you will also have words to describe the image (metadata).
Better yet, think of it this way. If that image were of a large family gathering and grandma lovingly wrote the date and names of all the people on the backside, that is basic metadata. Without that information those people and the image would suddenly have less meaning, especially if you have no clue who those faces are in that family photo. It is the same with digital projects. Without descriptive metadata, the items we digitize would hold less meaning and prove less valuable for researchers, or at least be less searchable. The better and more thorough the metadata, the more it promotes discovery in search engines. (Check out the metadata from this Cornett family photo from the William Gedney collection.)
The term metadata was first used in the late 1960s in computer programming language. With the advent of computing technology and the overabundance of digital data, metadata became a key element to help describe and retrieve information in an automated way. The use of the word metadata in literature over the last 45 years shows a steeper increase from 1995 to 2005, which makes sense. The term became used more and more as technology grew more widespread. This is reflected in the graph below from Google’s Ngram Viewer, which scours over 5 million Google Books to track the usage of words and phrases over time.
Google Ngram Viewer for “metadata”
Because of its link with computer technology, metadata is widely used in a variety of fields that range from computer science to the music industry. Even your music playlist is full of descriptive metadata that relates to each song, like the artist, album, song title, and length of audio recording. So, libraries and archives are not alone in their reliance on metadata. Generating metadata is an invaluable step in the process of preserving and documenting the library’s unique collections. It is especially important here at the Digital Production Center (DPC) where the digitization of these collections happens. To better understand exactly how important a role metadata plays in our job, let’s walk through the metadata life cycle of one of our digital projects, the Duke Chapel Recordings.
The Chapel Recordings project consists of digitizing over 1,000 cassette and VHS tapes of sermons and over 1,300 written sermons that were given at the Duke Chapel from the 1950s to 2000s. These recordings and sermons will be added to the existing Duke Chapel Recordings collection online. Funded by a grant from the Lilly Foundation, this digital collection will be a great asset to Duke’s Divinity School and those interested in hermeneutics worldwide.
Before the scanners and audio capture devices are even warmed up at the DPC, preliminary metadata is collected from the analog archival material. Depending on the project, this metadata is created either by an outside collaborator or in-house at the DPC. For example, the Duke Chronicle metadata is created in-house by pulling data from each issue, like the date, volume, and issue number. I am currently working on compiling the pre-digitization metadata for the 1950s Chronicle, and the spreadsheet looks like this:
1950s Duke Chronicle preliminary metadata
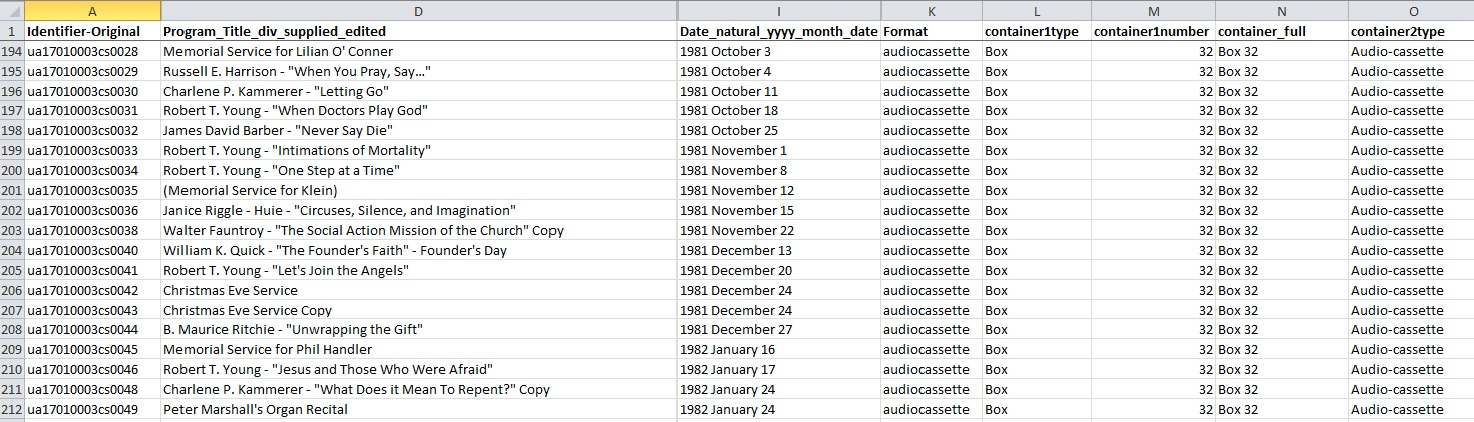
As for the Chapel Recordings project, the DPC received an inventory from the University Archives in the form of an Excel spreadsheet. This inventory contained the preliminary metadata already generated for the collection, which is also used in Rubenstein Library‘s online collection guide.
Chapel Recordings inventory metadata
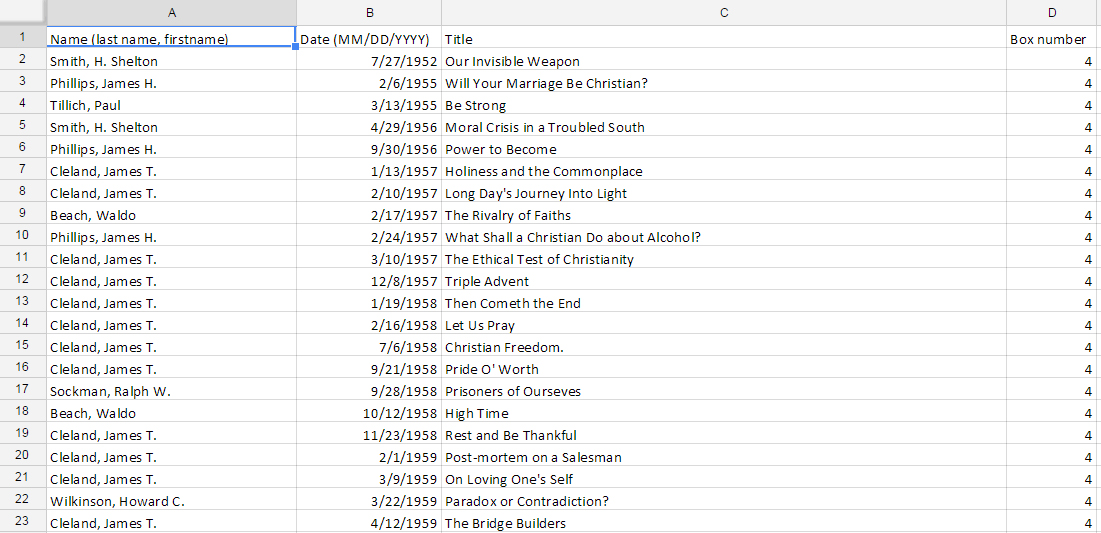
The University Archives also supplied the DPC with an inventory of the sermon transcripts containing basic metadata compiled by a student.
Duke Chapel Records sermon metadata
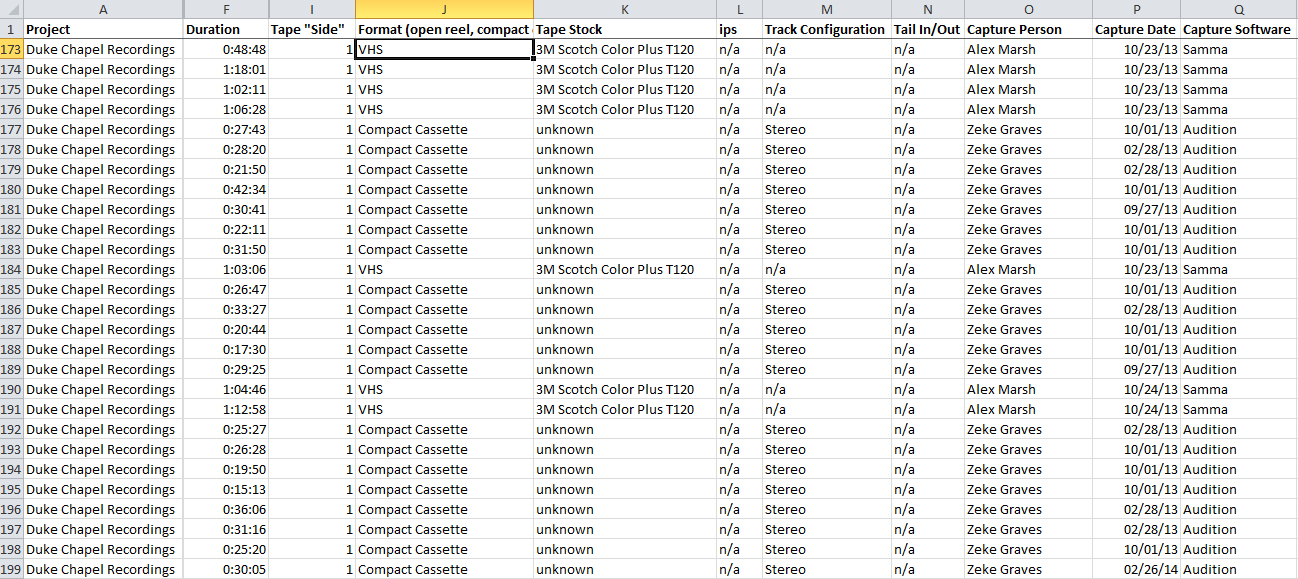
Here at the DPC, we convert this preliminary metadata into a digitization guide, which is a fancy term for yet another Excel spreadsheet. Each digital project receives its own digitization guide (we like to call them digguides) which keeps all the valuable information for each item in one place. It acts as a central location for data entry, but also as a reference guide for the digitization process. Depending on the format of the material being digitized (image, audio, video, etc.), the digitization guide will need different categories. We then add these new categories as columns in the original inventory spreadsheet and it becomes a working document where we plug in our own metadata generated in the digitization process. For the Chapel Recordings audio and video, the metadata created looks like this:
Chapel Recordings digitization metadata
Once we have digitized the items, we then run the recordings through several rounds of quality control. This generates even more metadata which is, again, added to the digitization guide. As the Chapel Recordings have not gone through quality control yet, here is a look at the quality control data for the 1980s Duke Chronicle:
1980s Duke Chronicle quality control metadata
Once the digitization and quality control is completed, the DPC then sends the digitization guide filled with metadata to the metadata archivist, Noah Huffman. Noah then makes further adds, edits, and deletes to match the spreadsheet metadata fields to fields accepted by the management software, CONTENTdm. During the process of ingesting all the content into the software, CONTENTdm links the digitized items to their corresponding metadata from the Excel spreadsheet. This is in preparation for placing the material online. For even more metadata adventures, see Noah’s most recent Bitstreams post.
In the final stage of the process, the compiled metadata and digitized items are published online at our Digital Collections website. You, the researcher, history fanatic, or Sunday browser, see the results of all this work on the page of each digital item online. This metadata is what makes your search results productive, and if we’ve done our job right, the digitized items will be easily discovered. The Chapel Recordings metadata looks like this once published online:
Chapel Recordings metadata as viewed online
Further down the road, the Duke Divinity School wishes to enhance the current metadata to provide keyword searches within the Chapel Recordings audio and video. This will allow researchers to jump to specific sections of the recordings and find the exact content they are looking for. The additional metadata will greatly improve the user experience by making it easier to search within the content of the recordings, and will add value to the digital collection.
On this journey through the metadata life cycle, I hope you have been convinced that metadata is a key element in the digitization process. From preliminary inventories, to digitization and quality control, to uploading the material online, metadata has a big job to do. At each step, it forms the link between a digitized item and how we know what that item is. The life cycle of metadata in our digital projects at the DPC is sometimes long and tiring. But, each stage of the process creates and utilizes the metadata in varied and important ways. Ultimately, all this arduous work pays off when a researcher in our digital collections hits gold.