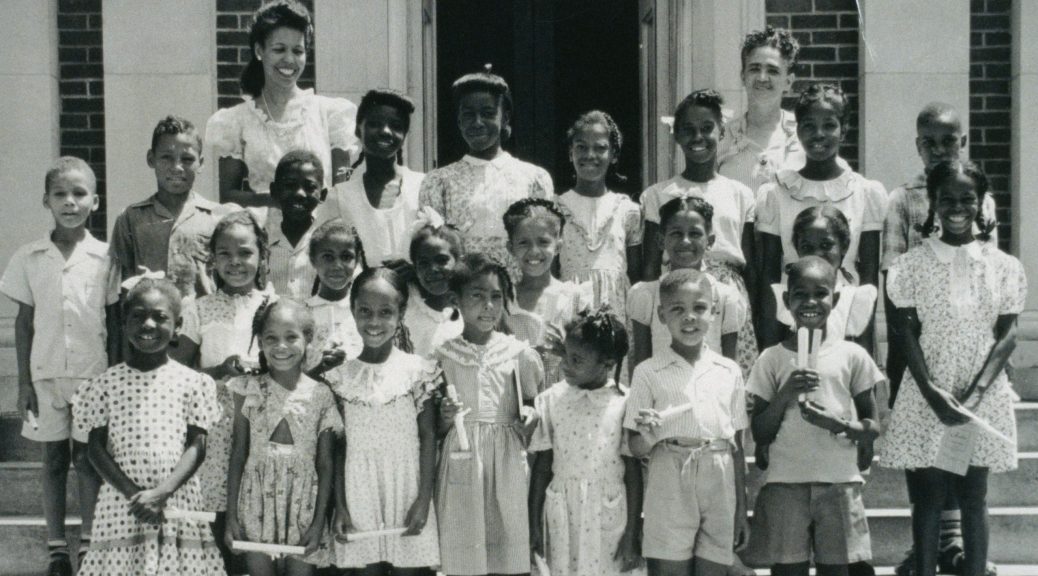Admit it, you have been wondering what your favorite digital collections team has been up to. Well after 2.5 years, the wait is over.
So. Many. Digitization. Requests.
When I last shared a digital collections update, it was the end of 2020, and the digital collections team was focusing on managing and refining our folder level patron request digitization workflow. This workflow has two main goals:
- simplify the patron request process in the Rubenstein Library;
- preserve and make accessible files from patron requests in the Duke Digital Repository (DDR).
Note that in this context, our patrons are generally folks that want to access Rubenstein Library materials without making the trip to Durham. Anyone, regardless of their researcher or academic status, can request digital copies of Rubenstein collections.
Moving digitization requests through this workflow continues to be the major focus for the digital collections team and the Digital Production Center (DPC). Given the folder level nature of the process (whole folders of manuscript material at preservation quality), more requests are digitized by the DPC than under our previous workflow. Additionally, the new request process became an essential tool to serving remote researchers during the pandemic. It continues to be a valuable service, and we have not seen demand lessen significantly since the peak of the pandemic. Below is a chart showing the number of patron requests managed by the DPC since before the pandemic (note that we track our statistics by fiscal year or FY, which in Duke’s case is July – June).
| FY18 | FY19 | FY20 | FY21 | FY22 | FY23 | |
|---|---|---|---|---|---|---|
| # of requests | 81 | 77 | 39 | 394 | 438 | 469 |
| Files produced | 1,323 | 676 | 1092 | 79,519 | 74,517 | 73,705 |
Patron requests received and files produced from said requests by the DPC.
As a result of the new patron request workflow, the digital collections team has made portions of hundreds of collections accessible in the digital repository. We also see new materials from the existing collections requested periodically, so individual digital collections grow over time. Our statistics for new digital collections are in the chart below.
| FY21 | FY22 | FY23 | |
|---|---|---|---|
| New digital collections from patron requests | 36 | 154 | 119 |
| Additions to existing collections from patron requests | 4 | 12 | 6 |
| Print items digitized for patron requests | 16 | 21 | 30 |
| Non-patron based new digital collections | 131 | 15 | 80 |
| Additions to digital collections (not patron request oriented) | 4 | 4 | 5 |
Numbers of collections launched in the Duke Digital Repository since 2020.
The patron request workflow, like all other digital collections projects, is carried out by the cross-departmental Duke Libraries Digital Collections Implementation Team (DCIT). DCIT members include representatives from Conservation Services, Digital Curation Services, the Digital Production Center, a Digital Projects Developer (from the Assessment and User Experience Strategy department), Rubenstein Library Research Services, and Rubenstein Library Technical Services. The group’s membership shows how varied the needs are to develop and sustain digital collections.
Not Just Patron Requests
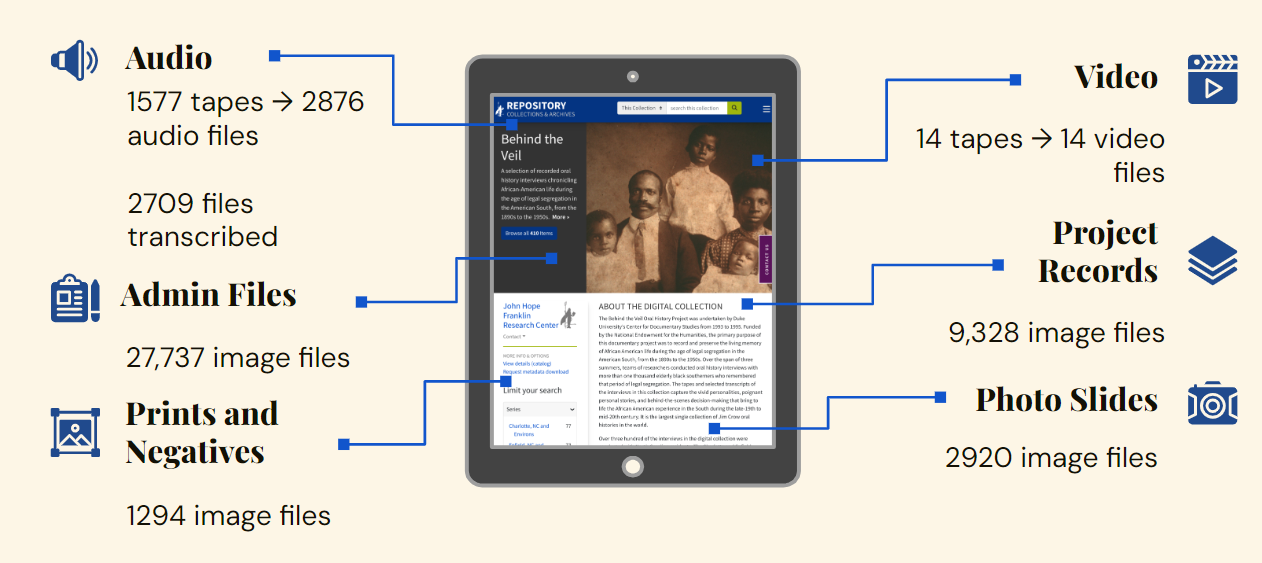
Although the digital collections team shelved strategic projects when the pandemic began, we have still managed to complete some project work. One of our highest priorities in this area has been the Documenting African American Life in the Jim Crow South: Digital Access to the Behind the Veil Project Archive project (funded by the National Endowment for the Humanities). Work on this project was just featured on Bitstreams, so I won’t share too many details here. Stay tuned for more news about this incredible effort.
We have also been making slow progress on the “Section A” mass digitization project. This project is named for an old Rubenstein Library shelving location, and contains over 3000 small manuscript collections. Many of the collections document life in the South in the 19th Century. Since 2020, we have been able to make 210 Section A collections accessible online. Many of these were scanned before the pandemic began, however the DPC continues to scan Section A when time permits. We have also seen at least 25 Section A collections come all the way through the patron request workflow, and there are more in progress. I’ve included embedded links to 3 Section A collections below.
Here are a few other project highlights from the past 2.5 years.


- The Pan American World Airways Advertisements digital collection launched in June 2021. This project was made possible by a Digitizing Hidden Collections grant from the Council on Library and Information Resources with funding from the Andrew W. Mellon Foundation. Read more about the project on the Devil’s Tale blog.
- Metadata created during a Rubenstein Library re-cataloging project has been transformed and applied to the American Slavery Documents digital collection, thus making this collection and the identities of the enslaved persons documented therein more discoverable.
- The Memory Project grew to include more oral histories in September 2021.
- We added digitized films to the Sidney D. Gamble Photographs collection; these were filmed primarily in China 1926-1933 (February 2023).
- New films have also been added to the Men’s Basketball Game Film Collection to get you ready for the upcoming season (note: these films are silent – June 2023).
- More photographs are accessible in the Darrin Zammit Lupi collection as of June; this new set documents migrants and refugees in the Balkans in 2016.
Looking ahead
Digital Collections has a lot to look forward to in 2023-2024. Along with the John Hope Franklin Research Center we expect to wrap up the Behind the Veil grant in 2024 (lots more news to come on that). The digital collections team also plans to continue refining the patron request workflow. We are hoping to find a new balance in our portfolio that allows us to continue serving the needs of remote researchers while also completing more project based digitization. How will we actually do that without significantly changing our staffing? When we figure it out, we will be happy to share.
In the meantime, all digital collections are available through the Duke Digital Repository.
Happy Browsing!