Quick—when was the last time you went a full day without using a Google product or service? How many years ago was that day?
We all know Google has permeated so many facets of our personal and professional lives. A lot of times, using a Google something-or-other is your organization’s best option to get a job done, given your available resources. If you ever searched the Duke Libraries website at any point over the past seventeen years, you were using Google.
It’s really no secret that when you have a website with a lot of pages, you need to provide a search box so people can actually find things. Even the earliest version of the library website known to the Wayback Machine–from “way back” in 1997–had a search box. Those days, search was powered by the in-house supported Texis Webinator. Google was yet to exist.
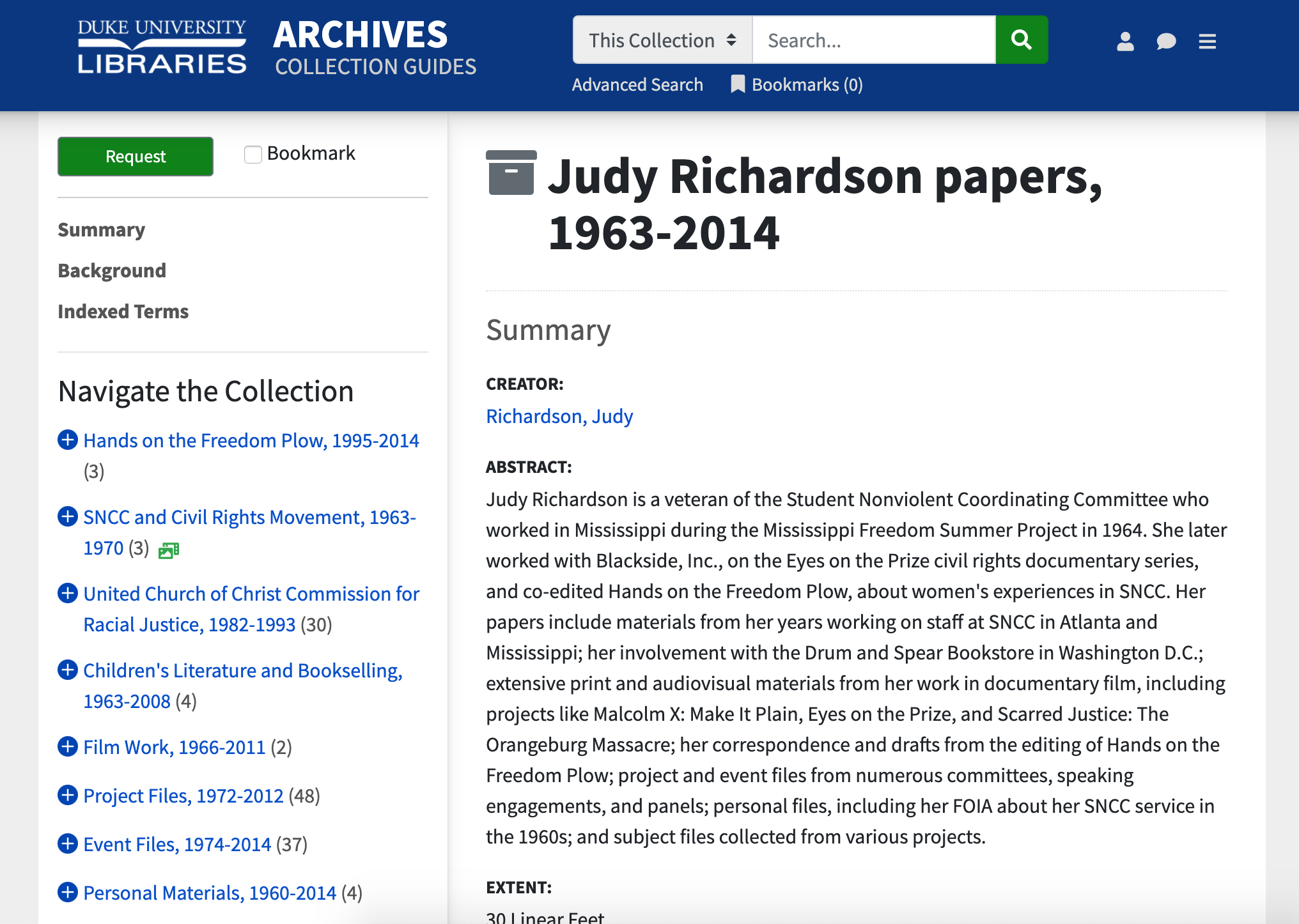
July 24, 2004 was an eventful day for the library IT staff. We went live with a shiny new Integrated Library System from Ex Libris called Aleph (that we are still to this day working to replace). On that very same day, we launched a new library website, and in the top-right corner of the masthead on that site was–for the very first time–a Google search box.
2004 version of the library website, with a Google search box in the masthead.
Years went by. We redesigned the website several times. Interface trends came and went. But one thing remained constant: there was a search box on the site, and if you used it, somewhere on the next page you were going to get search results from a Google index.
That all changed in summer 2021, when we implemented Nutch…
Why Not Google?
Google Programmable Search Engine (recently rebranded from “Google Custom Search Engine”), is easy to use. It’s “free.” It’s fast, familiar, and being a Google thing, it’s unbeatable at search relevancy. So why ditch it now? Well…
The results are capped at 100 per query. Google prioritizes speed and page 1 relevancy, but it won’t give you a precise hit count nor an exhaustive list of results.
It’s a black box. You don’t really get to see why pages get ranked higher or lower than others.
There’s a search API you could potentially build around, but if you exceed 100 searches/day, you have to start paying to use it.
What’s Nutch?
Apache Nutch is open source web crawler software written in Java. It’s been around for nearly 20 years–almost as long as Google. It supports out-of-the-box integration with Apache Solr for indexing.
Solr. Our IT staff have grown quite accustomed to the Solr search platform over the past decade; we already support around ten different applications that use it under the hood.
Self-Hosted. You run it yourself, so you’re in complete control of the data being crawled, collected, and indexed. User search data is not being collected by a third party like Google.
Configurable. You have a lot of control over how it works. All our configs are in a public code repository so we have record of what we have changed and why.
What are the Drawbacks to Using Nutch?
Maintenance. Using open source software requires a commitment of IT staff resources to build and maintain over time. It’s free, but it’s not really free.
Interface. Nutch doesn’t come with a user interface to actually use the indexed data from the crawls; you have to build a web application. Here’s ours.
Relevancy. Though Google considers such factors as page popularity and in-link counts to deem pages as more relevant than others for a particular query, Nutch can’t. Or, at least, its optional features that attempt to do so are flawed enough that not using them gets us better results. So we rely on other factors for our relevancy algorithm, like the segment of the site that a page resides, URL slugs, page titles, subheading text, inlink text, and more.
Documentation. Some open source platforms have really clear, easy to understand instruction manuals online to help you understand how to use them. Nutch is not one of those platforms.
How Does Nutch Work at Duke?
The main Duke University Libraries website is hosted in Drupal, where we manage around 1,500 webpages. But the full scope of what we crawl for library website searching is more than ten times that size. This includes pages from our blogs, LibGuides, exhibits, staff directory, and more. All told: 16,000 pages of content.
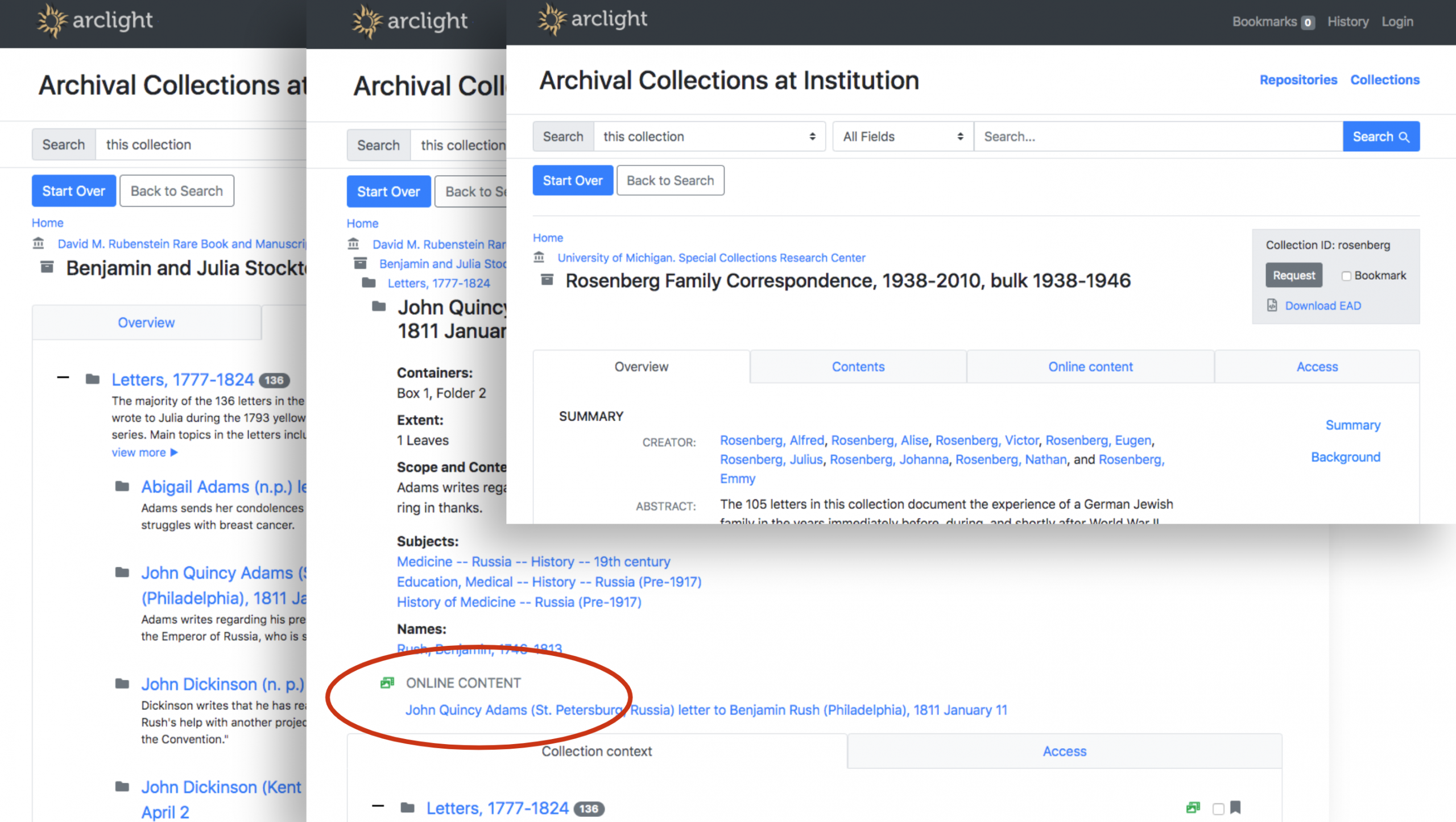
Searching from the website masthead or the default “All” box in the tabbed section on our homepage brings you to QuickSearch results page.
Use either of these search boxes to search QuickSearch.
You’ll see a search results page rendered by our QuickSearch app. It includes sections of results from various places, like articles, books & media, and more. One of the sections is “Our Website” — it shows the relevant pages that we’ve crawled with Nutch.
QuickSearch results page includes a section of results from “Our Website”
You can just search the website specifically if you’re not interested in all those other resources.
An example website-only search.
Three pieces work in concert to enable searching the website: Nutch, Solr, and QuickSearch. Here’s what they do:
Nutch
Crawls web pages that we want to include in the website search.
Parses HTML content; writes it to Solr fields.
Includes configuration for what pages to include/exclude, crawler settings, field mappings
Solr
Index & document store for crawled website content.
Includes configuration for determining relevancy; see parameters in website_searcher.rb
Crawls happen every night to pick up new pages and changes to existing ones. We use an “adaptive fetch schedule” so by default each page gets recrawled every 30 days. If a page changes frequently, it’ll get re-crawled sooner automatically.
Summary
Overall, we’re satisfied with how the switch to Nutch has been working out for us. The initial setup was challenging, but it has been running reliably without needing much in the way of developer intervention. Here’s hoping that continues!
Many thanks to Derrek Croney and Cory Lown for their help implementing Nutch at Duke, and to Kevin Beswick (NC State University Libraries) for consulting with our team.
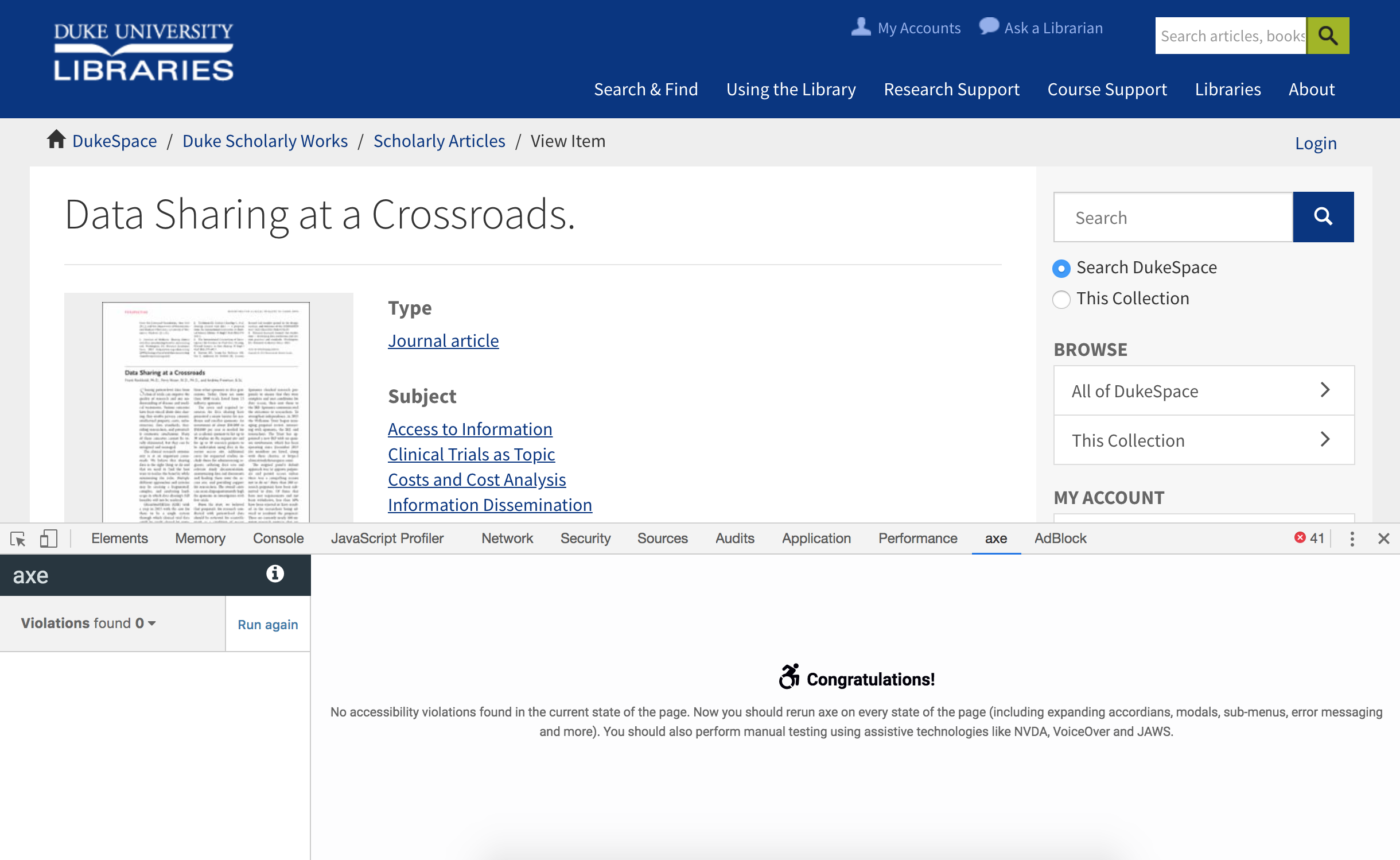
One of our favorite accessibility checking tools in our toolbox is the axe DevTools Browser Extension by Deque Systems. It’s easy to use, whether on a live site, or in our own local development environments while we’re working on building new features for our applications. Simply open your browser’s Developer Tools (F12), click the Scan button, and get an instant report of any violations, complete with recommendations about how to fix them.
An axe DevTools test result for our archival finding aids homepage.
Keeping a website compliant is a continuous effort. Websites are living things. Content changes, features are added. When a site becomes compliant it does not stay compliant.
One of the goals we set out to accomplish in 2021 was to figure out how to add automated, continuous accessibility testing for our ArcLight software, which powers our archival finding aids search and discovery application. We got it implemented successfully a few months ago and we’re pleased with how it has been working so far.
Let me back up a bit and give some background on the concepts and tools upon which this solution depends. Namely: Continuous Integration, RSpec, Capybara, Selenium, and Docker.
Continuous Integration
For any given software project, we may have several developers making multiple changes to a shared codebase in the same day. Continuous Integration is the practice of ensuring that these code changes 1) don’t break any existing functionality, and 2) comply with established guidelines for code quality.
Evidence of a GitLab CI pipeline that has run — and passed all stages — for a code change.
For accessibility testing, we knew we needed to add something to our existing CI pipeline that would check for compliance and flag any issues.
RSpec Testing Framework
Many of our applications are built using Ruby on Rails. We write tests for our code using RSpec, a popular testing framework for Rails applications. Developers write tests (using the framework’s DSL / domain-specific language) to accompany their code changes. Those tests all execute as part of our CI pipeline (see above). Any failing tests will prevent code from being merged or getting deployed to production.
There are many different types of tests. On one end of the spectrum, there are “unit tests,” which verify that one small piece of code (e.g., one method) returns what we expect it to when it is given different inputs. On the other, there are “feature tests,” which typically verify that several pieces of code are working together as intended in different conditions. This often simulates the use of a feature by a person (e.g., when a user clicks this button, test that they get to this page and verify this link gets rendered, etc.). Feature tests might alternatively be called “integration tests,” “acceptance tests,” or even “system tests” — the terminology is both squishy and evolving.
At any rate, accessibility testing is a specific kind of feature test.
Capybara
On its own, RSpec unfortunately doesn’t natively support feature tests. It requires a companion piece of software called Capybara, which can simulate a user interacting with a web interface. Capybara brings with it a DSL to visit pages, fill out forms, or click on elements within RSpec tests, and special matchers to check that the page is behaving as intended.
Homepage for Capybara, featuring an actual capybara.
When configuring Capybara, you set up the driver you want it to use when running different kinds of tests. Its default driver is RackTest, which is fast but it can’t execute JavaScript like a real web browser can. Our ArcLight UI, for instance, uses a bunch of JavaScript. So we knew that any accessibility tests would have to be performed using a driver for an actual browser; the default Capybara alone wouldn’t cut it.
Documentation for Selenium WebDriver for browser automation
The best way we could find to get Capybara to control a real browser in an RSpec test was to add the selenium-webdriver gem to our project’s Gemfile.
Docker
Over the past few years, we have evolved our DevOps practice and embraced containerizing our applications using Docker. Complex applications that have a lot of interwoven infrastructure dependencies used to be quite onerous to build, run, and share. Getting one’s local development environment into shape to successfully run an application used be a whole-day affair. Worse still, the infrastructure on the production server used to bear little resemblance to what developers were working with on their local machines.
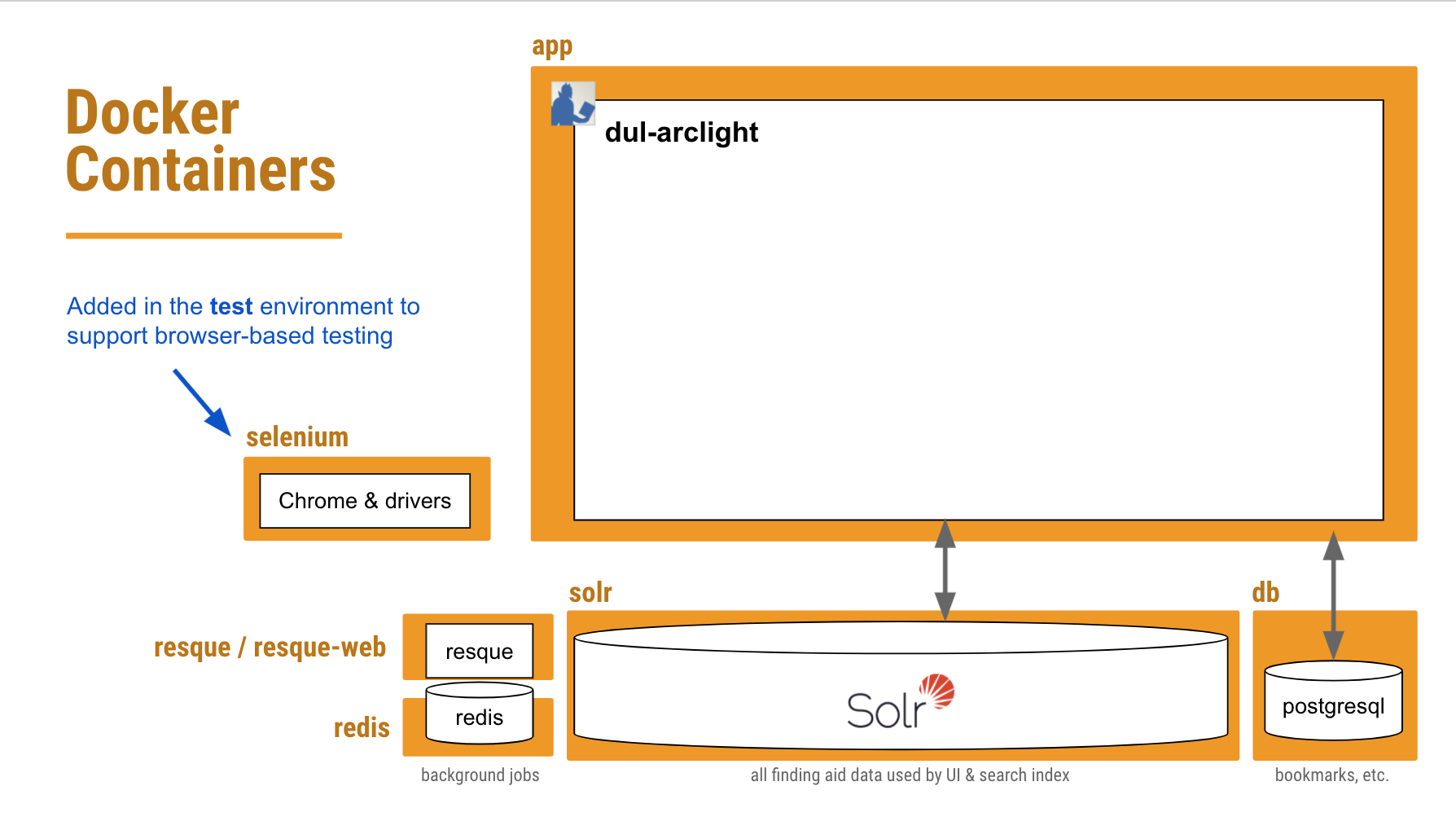
A systems diagram depicting the various services that run to support our ArcLight app.
Docker helps a dev team configure in their codebase all of these system dependencies in a way that that’s easily reproducible in any environment. It builds a network of “containers” on a single host, each running a service that’s crucial to the application. Now a developer can simply check out the code, run a couple commands, wait a few minutes, and they’re good to go.
The same basic setup also applies in a production environment (with a few easily-configurable differences). And that simplicity also carries over to the CI environment where the test suite will run.
Orange boxes depict each service / container we have defined in our Docker configuration.
So what we needed to do was add another container to our existing Docker configuration that would be dedicated to running any JavaScript-dependent feature tests — including accessibility tests — in a browser controlled by Selenium WebDriver.
Keeping this part containerized would hopefully ensure that when a developer runs the tests in their local environment, the exact same browser version and drivers get used in the CI pipeline. We can steer clear of any “well, it worked on my machine” issues.
Putting it All Together
Phew. OK, with all of that background out of the way, let’s look closer at how we put all of these puzzle pieces together.
The folks at Selenium HQ host “standalone” browser Docker images in Docker Hub, complete with the browser software and accompanying drivers. We found a tagged version of their Standalone Chrome image that worked well, and pull that into our newly-defined “selenium” container for our test environments.
Since this is new territory for us, and already fairly complex, we’re starting with just one browser: Chrome. We may be able to add more in the future.
Capybara Driver Configuration
Next thing we needed to do was tell Capybara that whenever it encounters any javascript-dependent feature tests, it should run them in our standalone Chrome container (using a “remote” driver). The Selenium WebDriver gem lets us set some options for how we want Chrome to run.
The key setting here is “headless” — that is, run Chrome, but more efficiently, without all the fancy GUI stuff that a real user might see.
That last URL http://selenium:4444/wd/hub is the location of our Chrome driver within our selenium container.
There are a few other important Capybara settings configured in spec_helper.rbthat are needed in order to get our app and seleniumcontainers to play nicely together.
Capybara.server=:puma,{Threads:'1:1'}Capybara.server_port='3002'Capybara.server_host='0.0.0.0'Capybara.app_host="http://app:#{Capybara.server_port}"Capybara.always_include_port=trueCapybara.default_max_wait_time=30# our ajax responses are sometimes slowCapybara.enable_aria_label=true
[...]
The server_port, server_host and app_host variables are the keys here. Basically, we’re saying:
Capybara (which runs in our app container) should start up Puma to run the test app, listening on http://0.0.0.0:3002 for requests beyond the current host during a test.
The selenium container (where the Chrome browser resides) should access the application under test at http://app:3002 (since it’s in the app container).
Some Actual RSpec Accessibility Tests
Here’s the fun part, where we actually get to write the accessibility tests. The axe-core-rspec gem makes it a breeze. The be_axe_clean matcher ensures that if we have a WCAG 2.0 AA or Section 508 violation, it’ll trip the wire and report a failing test.
require'spec_helper'require'axe-rspec'RSpec.describe'Accessibility (WCAG, 508, Best Practices)',type: :feature,js: true,accessibility: truedodescribe'homepage'doit'is accessible'dovisit'/'expect(page).tobe_axe_cleanendend
[...]
end
With type: :feature and js: true we signal to RSpec that this block of tests should be handled by Capybara and must be run in our headless Chrome Selenium container.
The example above is the simplest case: 1) visit the homepage and 2) do an Axe check. We also make sure to test several different kinds of pages, and with some different variations on UI interactions. E.g., test after clicking to open the Advanced Search modal.
The CI Pipeline
We started out having accessibility tests run along with all our other RSpec tests during the test stage in our GitLab CI pipeline. But we eventually determined it was better to keep accessibility tests isolated in a separate job, one that would not block a code merge or deployment in the event of a failure. We use the accessibility: true tag in our RSpec accessibility test blocks (see the above example) to distinguish them from other feature tests.
No, we don’t condone pushing inaccessible code to production! It’s just that we sometimes get false positives — violations are reported where there are none — particularly in Javascript-heavy pages. There are likely some timing issues there that we’ll work to refine with more configuration.
A Successful Accessibility Test
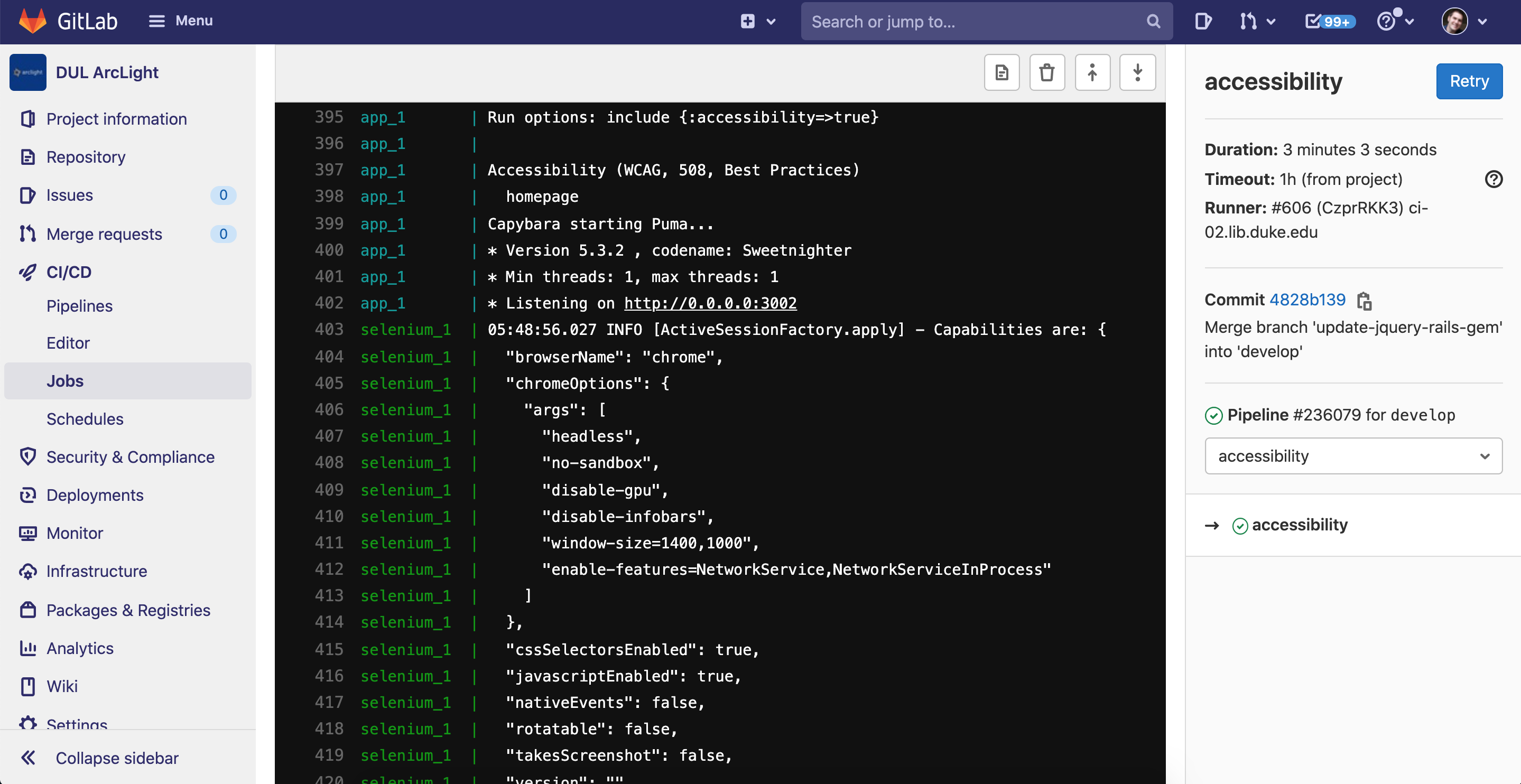
Here’s a completed job in our CI pipeline logs where the accessibility tests all passed:
Output from a successful automated accessibility test job run in a GitLab CI pipeline.
Our GitLab CI logs are not publicly available, so here’s a brief snippet from a successful test.
An Accessibility Test With Failures
Here’s a CI pipeline for a code branch that adds two buttons to the homepage with color contrast and aria-label violations. The axe tests flag the issues as FAILED and recommend revisions (see snippet from the logs).
Concluding Thoughts
Automation and accessibility testing are both rapidly evolving areas, and the setup that’s working for our ArcLight app today might look considerably different within the next several months. Still, I thought it’d be useful to pause and reflect on the steps we took to get automated accessibility testing up and running. This strategy would be reasonably reproducible for many other applications we support.
A lot of what I have outlined could also be accomplished with variations in tooling. Don’t use GitLab CI? No problem — just substitute your own CI platform. The five most important takeaways here are:
Accessibility testing is important to do, continually
Use continuous integration to automate testing that used to be manual
Containerizing helps streamline continuous integration, including testing
You can run automated browser-based tests in a ready-made container
Deque’s open source Axe testing tools are easy to use and pluggable into your existing test framework
Many thanks to David Chandek-Stark (Duke) for architecting a large portion of this work. Thanks also to Simon Choy (Duke), Dann Bohn (Penn St.), and Adam Wead (Penn St.) for their assistance helping us troubleshoot and understand how these pieces fit together.
REVISION 7/29/21: This post was updated, adding links to snippets from CI logs that demonstrate successful accessibility tests vs. those that reveal violations.
Now that we have been live for awhile, I thought it’d be worthwhile to summarize what we accomplished, and reflect a bit on how it’s going.
Working Among Peers
I had the pleasure of presenting about ArcLight at the Oct 2020 Blacklight Summit alongside Julie Hardesty (Indiana University) and Trey Pendragon (Princeton University). The three of us shared our experiences implementing ArcLight at our institutions. Though we have the same core ArcLight software underpinning our apps, we have each taken different strategies to build on top of it. Nevertheless, we’re all emerging with solutions that look polished and fill in various gaps to meet our unique local needs. It’s exciting to see how well the software holds up in different contexts, and to be able to glean inspiration from our peers’ platforms.
Slides from ArcLight@Duke presentation, 10/7/2020
A lot of content in this post will reiterate what I shared in the presentation.
This is one of the hardest things to get right in a finding aids UI, so our solution has evolved through many iterations. We created a context sidebar with lightly-animated loading indicators matching the number of items currently loading. The nav sticks with you as you scroll down the page and the Request button stays visible. We also decided to present a list of direct child components in the main page body for any parent component.
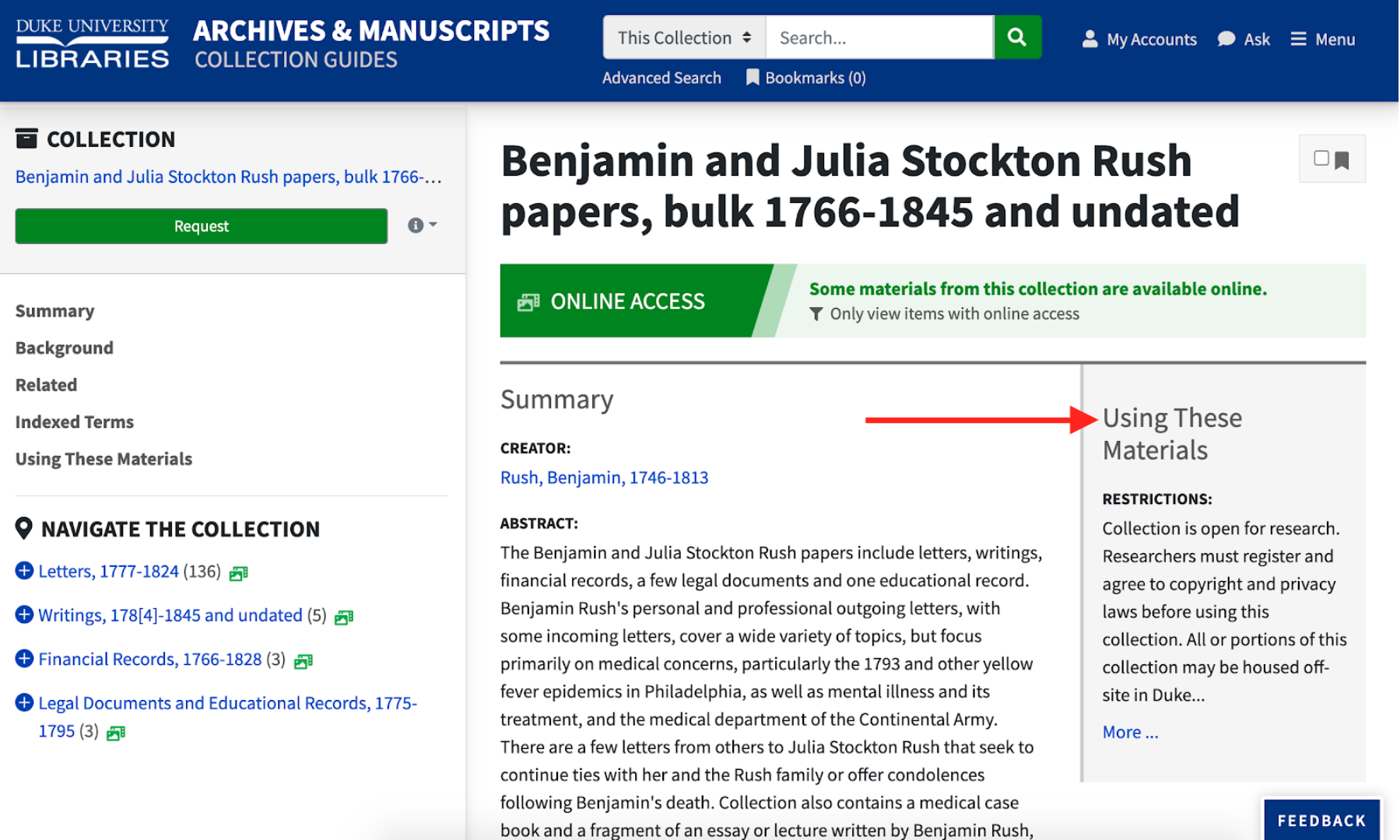
Restrictions
At the collection level, we wanted to ensure that users didn’t miss any restrictions info, so we presented a taste of it at the top-right of the page that jumps you to the full description when clicking “More.”
We changed how access and use restriction indexing so components can inherit their restrictions from any ancestor component. Then we made bright yellow banners and icons in the UI to signify that a component has restrictions.
ArcLight exists among a wide constellation of other applications supporting and promoting discovery in the library, so integrating with these other pieces was an important part of our implementation. In April, I showed the interaction between ArcLight and our Requests app, as well as rendering digital object viewers/players inline via the Duke Digital Repository (DDR).
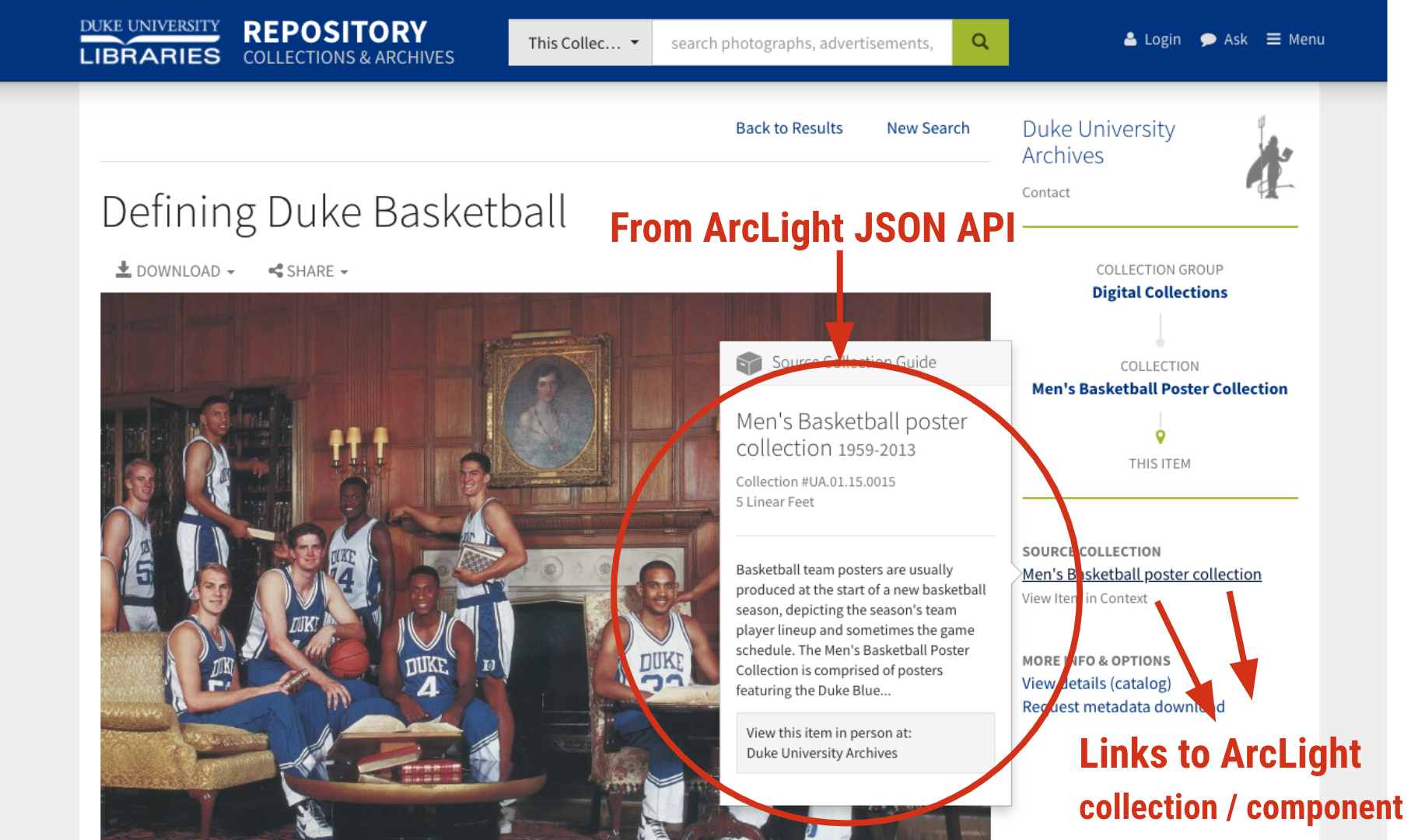
Two other locations external to our application now use ArcLight’s APIs to retrieve archival information. The first is the Duke Digital Repository (DDR). When viewing a digital collection or digital object that has a physical counterpart in the archives, we pull archival information for the item into the DDR interface from ArcLight’s JSON API.
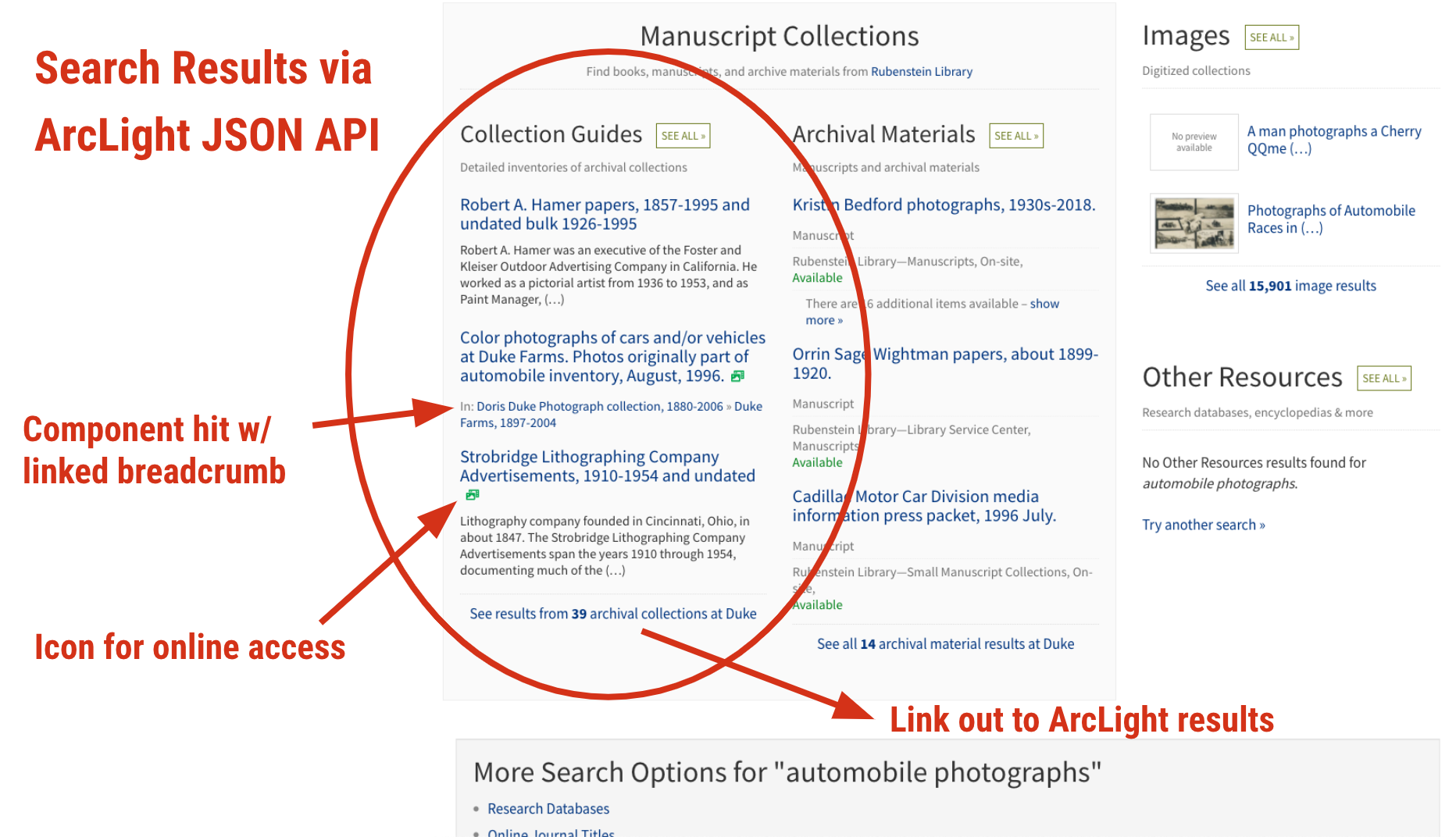
The other is our “Bento” search application powering the default All search available from the library website. Now when your query finds matches in ArcLight, you’ll see component-level results under a Collection Guides bento box. Components are contextualized with a linked breadcrumb trail.
Bookmarks Export CSV
COVID-19 brought about many changes to how staff at Duke Libraries retrieve materials for faculty and student research. You may have heard Duke’s Library Takeout song (819K YouTube views & counting!), and if you have, you probably can’t ever un-hear it.
But with archival materials, we’re talking about items that could never be taken out of the building. Materials may only be accessed in a controlled environment in the Rubenstein Reading Room, which remains highly restricted. With so much Duke instruction moving online during COVID, we urgently needed to come up with a better workflow to field an explosion of requests for digitizing archival materials for use in remote instruction.
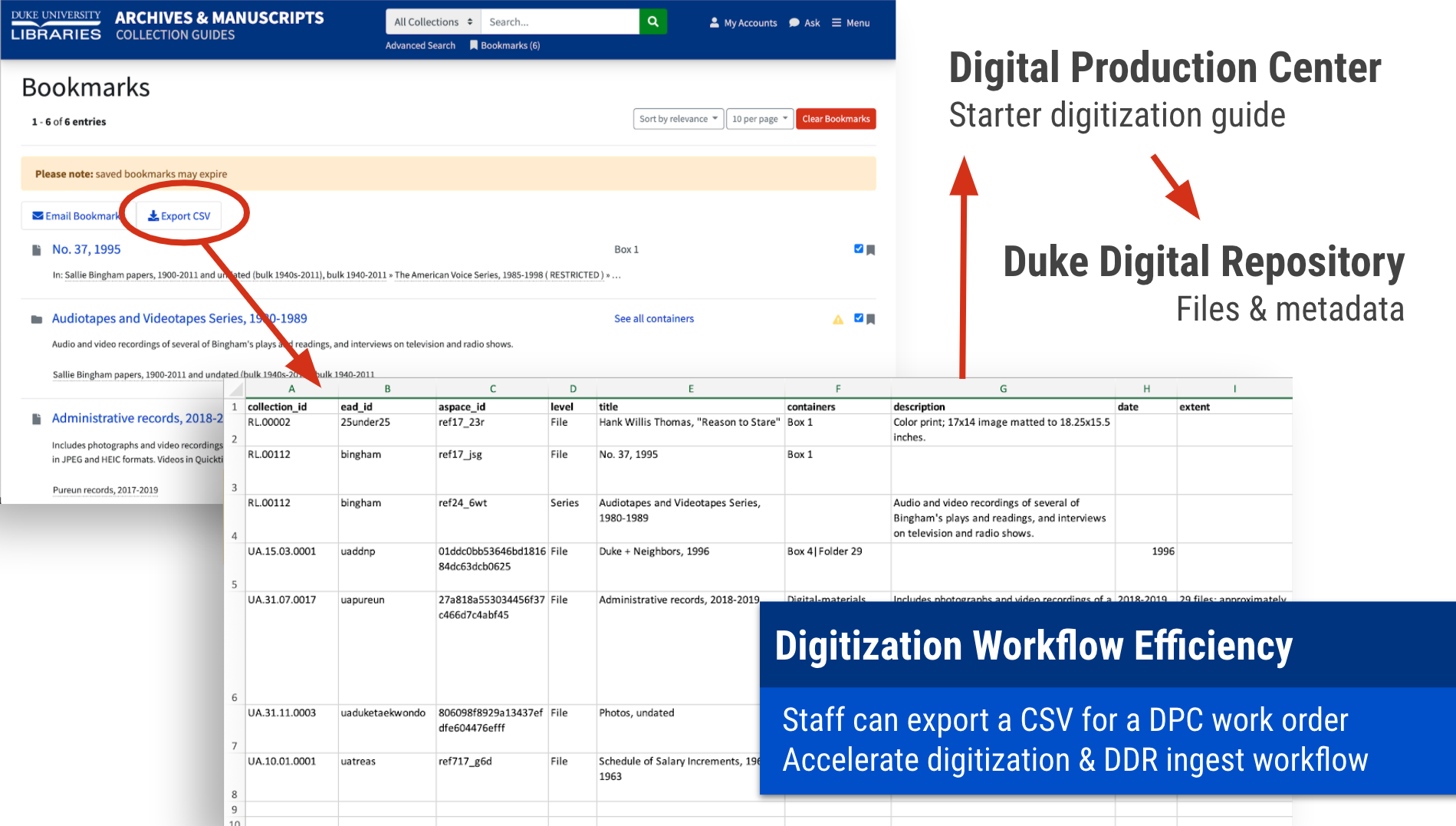
ArcLight’s Bookmarks feature (which comes via Blacklight) proved to be highly valuable here. We extended the feature to add a CSV export. The CSV is constructed in a way that makes it function as a digitization work order that our Digital Collections & Curation Services staff use to shepherd a request through digitization, metadata creation, and repository ingest. Over 26,000 images have now been digitized for patron instruction requests using this new workflow.
More Features
Here’s a list of several other custom features we completed after the April midway point.
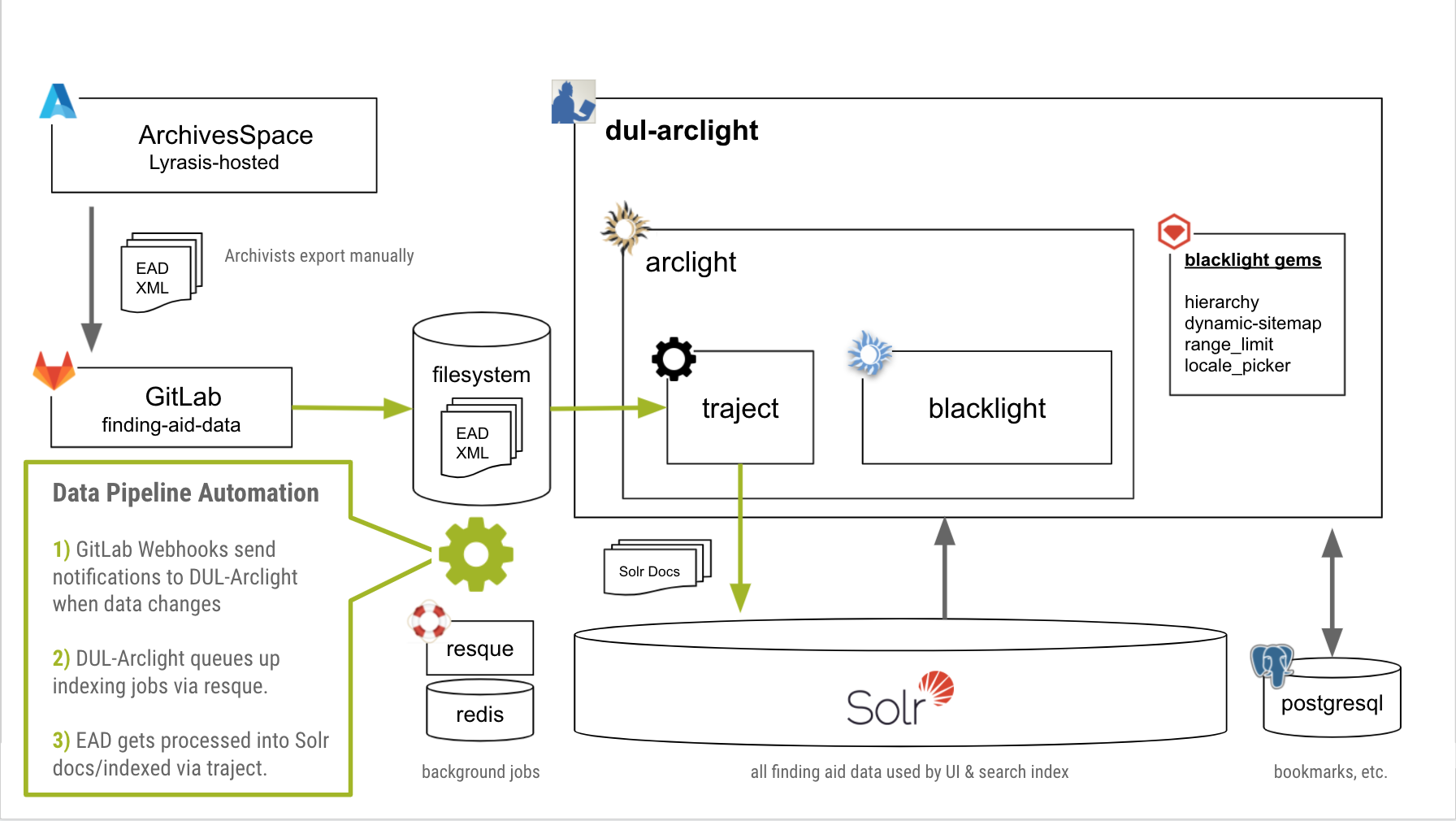
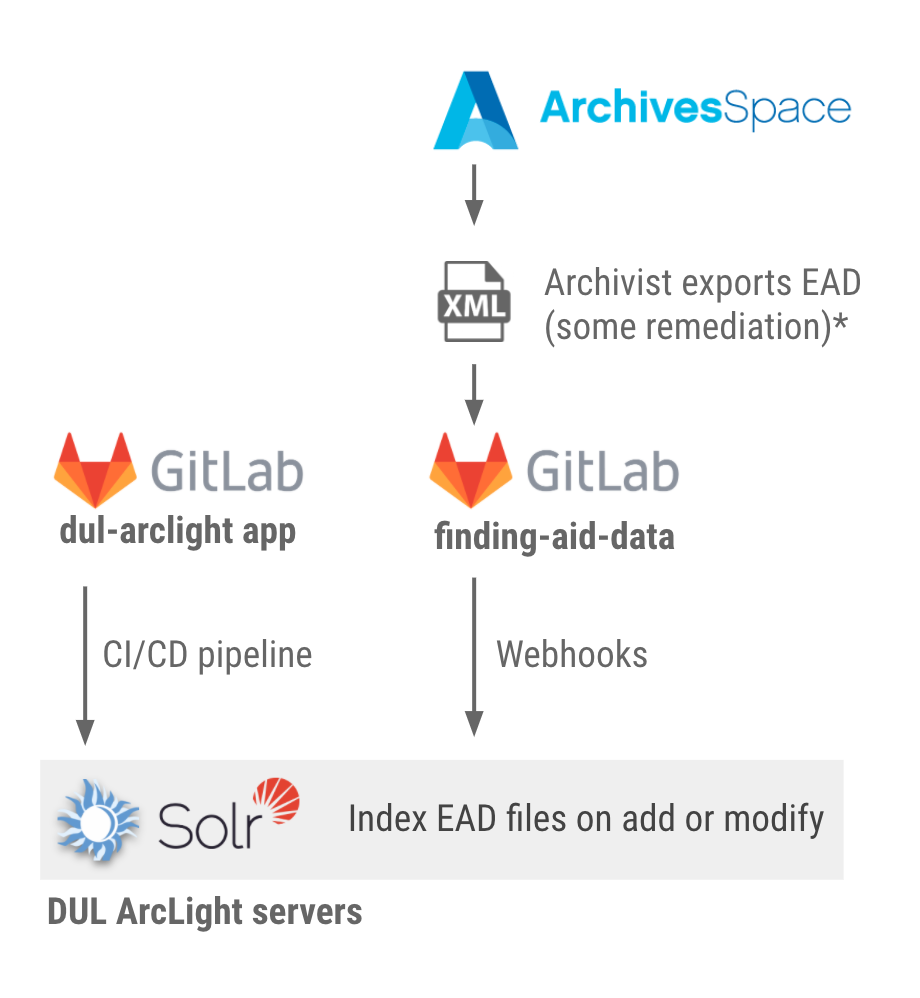
Bringing ArcLight online required some major rearchitecting of our pipeline to preview and publish archival data. Our archivists have been using ArchivesSpace for several years to manage the source data, and exporting EAD2002 XML files when ready to be read by the public UI. Those parts remain the same for now, however, everything else is new and improved.
Our new process involves two GitLab repositories: one for the EAD data, and another for the ArcLight-based application. The data repo uses GitLab Webhooks to send POST requests to the app to queue up reindexing jobs automatically whenever the data changes. We have a test/preview branch for the data that updates our dev and test servers for the application, so archivists can easily see what any revised or new finding aids will look like before they go live in production.
We use GitLab CI/CD to easily and automatically deploy changes to the application code to the various servers. Each code change gets systematically checked for passing unit and feature tests, security, and code style before being integrated. We also aim to add automated accessibility testing to our pipeline within the next couple months.
A lot of data gets crunched while indexing EAD documents through Traject into Solr. Our app uses Resque-based background job processing to handle the transactions. With about 4,000 finding aids, this creates around 900,000 Solr documents; the index is currently a little over 1GB. Changes to data get reindexed and reflected in the UI near-instantaneously. If we ever need to reindex every finding aid, it takes only about one hour to complete.
What We Have Learned
We have been live for just over four months, and we’re really ecstatic with how everything is going.
Usability
In September 2020, our Assessment & User Experience staff conducted ten usability tests using our ArcLight UI, with five experienced archival researchers and five novice users. Kudos to Joyce Chapman, Candice Wang, and Anh Nguyen for their excellent work. Their report is available here. The tests were conducted remotely over Zoom due to COVID restrictions. This was our first foray into remote usability testing.
Novice and advanced participants alike navigated the site fairly easily and understood the contextual elements in the UI. We’re quite pleased with how well our custom features performed (especially the context sidebar, contents lists, and redesigned breadcrumb trail). The Advanced Search modal got more use than we had anticipated, and it too was effective. We were also somewhat surprised to find that users were not confused by the All Collections vs. This Collection search scope selector when searching the site.
“The interface design does a pretty good job of funneling me to what I need to see… Most of the things I was looking for were in the first place or two I’d suspect they’d be.” — Representative quote from a test participant
A few improvements were recommended as a result of the testing:
make container information clearer, especially within the requesting workflow
improve visibility of the online access facet
make the Show More links in the sidebar context nav clearer
better delineate between collections and series in the breadcrumb
replace jargon with clearer labels, especially “Indexed Terms“
We recently implemented changes to address 2, 3, and 5. We’re still considering options for 1 and 4. Usability testing has been invaluable part of our development process. It’s a joy (and often a humbling experience!) to see your design work put through the paces with actual users in a usability test. It always helps us understand what we’re doing so we can make things better.
Usage
We want to learn more about how often different parts of the UI are used, so we implemented Google Analytics event tracking to anonymously log interactions. We use the Anonymize IP feature to help protect patron privacy.
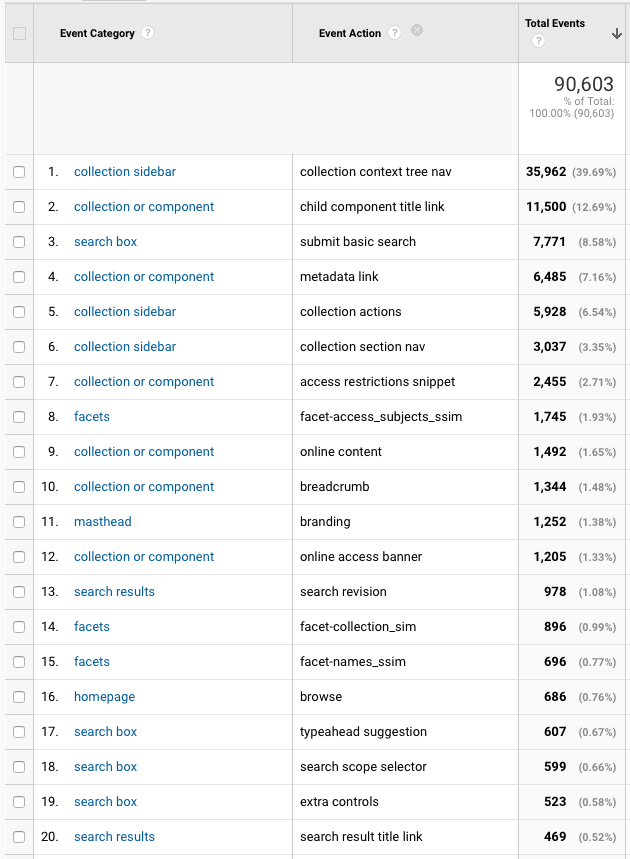
Top Google Analytics event categories & actions, Jul 1 – Nov 20, 2020.
Some observations so far:
The context nav sidebar is by far the most interacted-with part of the UI.
Browsing the Contents section of a component page (list of direct child components) is the second-most frequent interaction.
Subject, Collection, & Names are the most-used facets, in that order. That does not correlate with the order they appear in the sidebar.
Links presented in the Online Access banners were clicked 5x more often than the limiter in the Online Access facet (which matches what we found in usability testing)
Basic keyword searches happen 32x more frequently than advanced searches
Search Engine Optimization (SEO)
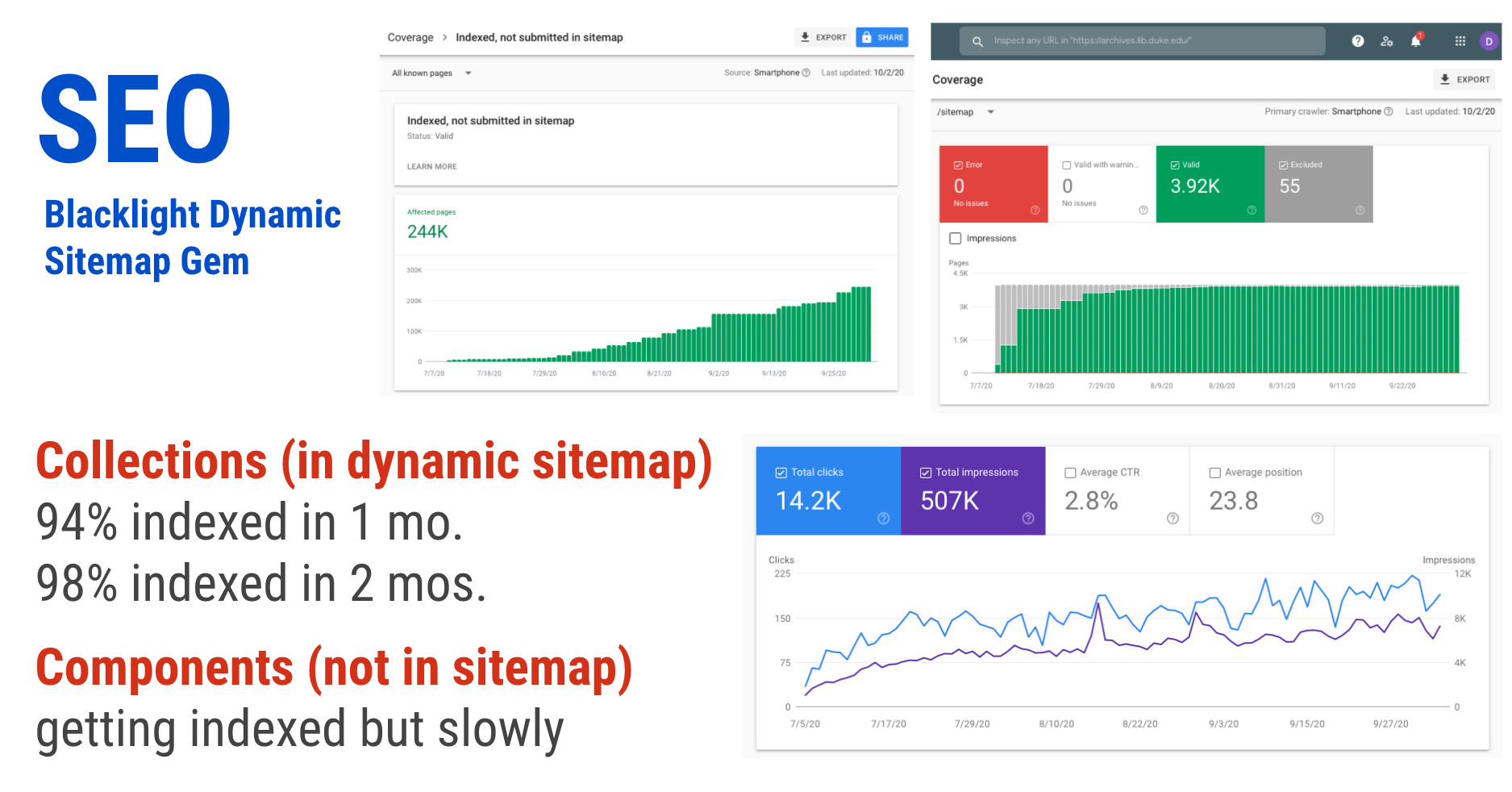
We want to be sure that when people search Google for terms that appear in our finding aids, they discover our resources. So when several Blacklight community members combined forces to create a Blacklight Dynamic Sitemaps gem this past year, it caught our eye. We found it super easy to set up, and it got the vast majority of our collection records Google-indexed within a month or so. We are interested in exploring ways to get it to include the component records in the sitemap as well.
Launching ArcLight: Retrospective
We’re pretty proud of how this all turned out. We have accomplished a lot in a relatively short amount of time. And the core software will only improve as the community grows.
At Duke, we already use Blacklight to power a bunch of different discovery applications in our portfolio. And given that the responsibility of supporting ArcLight falls to the same staff who support all of those other apps, it has been unquestionably beneficial for us to be able to work with familiar tooling.
We did encounter a few hurdles along the way, mostly because the software is so new and not yet widely adopted. There are still some rough edges that need to be smoothed out in the core software. Documentation is pretty sparse. We found indexing errors and had to adjust some rules. Relevancy ranking needed a lot of work. Not all of the EAD elements and attributes are accounted for; some things aren’t indexed or displayed in an optimal way.
Still, the pros outweigh the cons by far. With ArcLight, you get an extensible Blacklight-based core, only catered specifically to archival data. All the things Blacklight shines at (facets, keyword highlighting, autosuggest, bookmarks, APIs, etc.) are right at your fingertips. We have had a very good experience finding and using Blacklight plugins to add desired features.
Finally, while the ArcLight community is currently small, the larger Blacklight community is not. There is so much amazing work happening out in the Blacklight community–so much positive energy! You can bet it will eventually pay dividends toward making ArcLight an even better solution for archival discovery down the road.
Acknowledgments
Many thanks go out to our Duke staff members who contributed to getting this project completed successfully. Especially:
Product Owner: Noah Huffman
Developers/DevOps: Sean Aery, David Chandek-Stark, Michael Daul, Cory Lown (scrum master)
Project Sponsors: Will Sexton & Meghan Lyon
Redesign Team: Noah Huffman (chair), Joyce Chapman, Maggie Dickson, Val Gillispie, Brooke Guthrie, Tracy Jackson, Meghan Lyon, Sara Seten Berghausen
And thank you as well to the Stanford University Libraries staff for spearheading the ArcLight project.
This post was updated on 1/7/21, adding the embedded video recording of the Oct 2020 Blacklight Summit ArcLight presentation.
On January 20, 2020, we kicked off our first development sprint for implementing ArcLight at Duke as our new finding aids / collection guides platform. We thought our project charter was solid: thorough, well-vetted, with a reasonable set of goals. In the plan was a roadmap identifying a July 1, 2020 launch date and a list of nineteen high-level requirements. There was nary a hint of an impending global pandemic that could upend absolutely everything.
The work wasn’t supposed to look like this, carried out by zooming virtually into each other’s living rooms every day. Code sessions and meetings now require navigating around child supervision shifts and schooling-from-home responsibilities. Our new young office-mates occasionally dance into view or within earshot during our calls. Still, we acknowledge and are grateful for the privilege afforded by this profession to continue to do our work remotely from safe distance.
So, a major shoutout is due to my colleagues in the trenches of this work overcoming the new unforeseen constraints around it, especially Noah Huffman, David Chandek-Stark, and Michael Daul. Our progress to date has only been possible through resilience, collaboration, and willingness to keep pushing ahead together.
Three months after we started the project, we remain on track for a summer 2020 launch.
As a reminder, we began with the core open-source ArcLight platform (demo available) and have been building extensions and modifications in our local application in order to accommodate Duke needs and preferences. With the caveat that there’ll be more changes coming over the next couple months before launch, I want to provide a summary of what we have been able to accomplish so far and some issues we have encountered along the way. Duke staff may access our demo app (IP-restricted) for an up-to-date look at our work in progress.
Homepage
Homepage design for Duke’s ArcLight finding aids site.
Duke Branding. Aimed to make an inviting front door to the finding aids consistent with other modern Duke interfaces, similar to–yet distinguished enough from–other resources like the catalog, digital collections, or Rubenstein Library website.
Featured Items. Built a configurable set of featured items from the collections (with captions), to be displayed randomly (actual selections still in progress).
Dynamic Content. Provided a live count of collections; we might add more indicators for types/counts of materials represented.
Layout
A collection homepage with a sidebar for context navigation.
Sidebar. Replaced the single-column tabbed layout with a sidebar + main content area.
Persistent Collection Info. Made collection & component views more consistent; kept collection links (Summary, Background, etc.) visible/available from component pages.
Width. Widened the largest breakpoint. We wanted to make full use of the screen real estate, especially to make room for potentially lengthy sidebar text.
Navigation
Component pages contextualized through a sidebar navigator and breadcrumb above the main title.
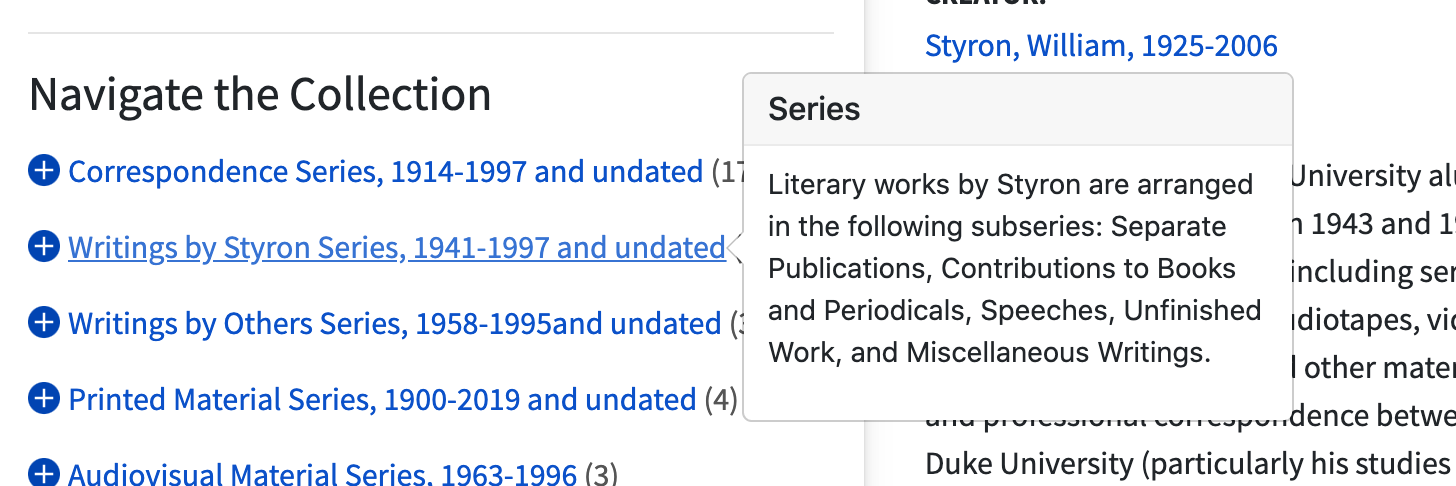
Hierarchical Navigation. Restyled & moved the hierarchical tree navigation into the sidebar. This worked well functionally in ArcLight core, but we felt it would be more effective as a navigational aid when presented beside rather than below the content.
Tooltips & Popovers. Provided some additional context on mouseovers for some navigational elements.
Mouseover context in navigation.
List Child Components. Added a direct-child list in the main content for any series or other component. This makes for a clear navigable table of what’s in the current series / folder / etc. Paginating it helps with performance in cases where we might have 1,000+ sibling components to load.
Breadcrumb Refactor. Emphasized the collection title. Kept some indentation, but aimed for page alignment/legibility plus a balance of emphasis between current component title and collection title.
Breadcrumb trail to show the current component’s nesting.
Search Results
Search results grouped by collection, with keyword highlighting.
“Group by Collection” as the default. Our stakeholders were confused by atomized components as search results outside of the context of their collections, so we tried to emphasize that context in the default search.
Revised search result display. Added keyword highlighting within result titles in Grouped or All view. Made Grouped results display checkboxes for bookmarking & digitized content indicators.
Advanced Search. Kept the global search box simple but added a modal Advanced search option that adds fielded search and some additional filters.
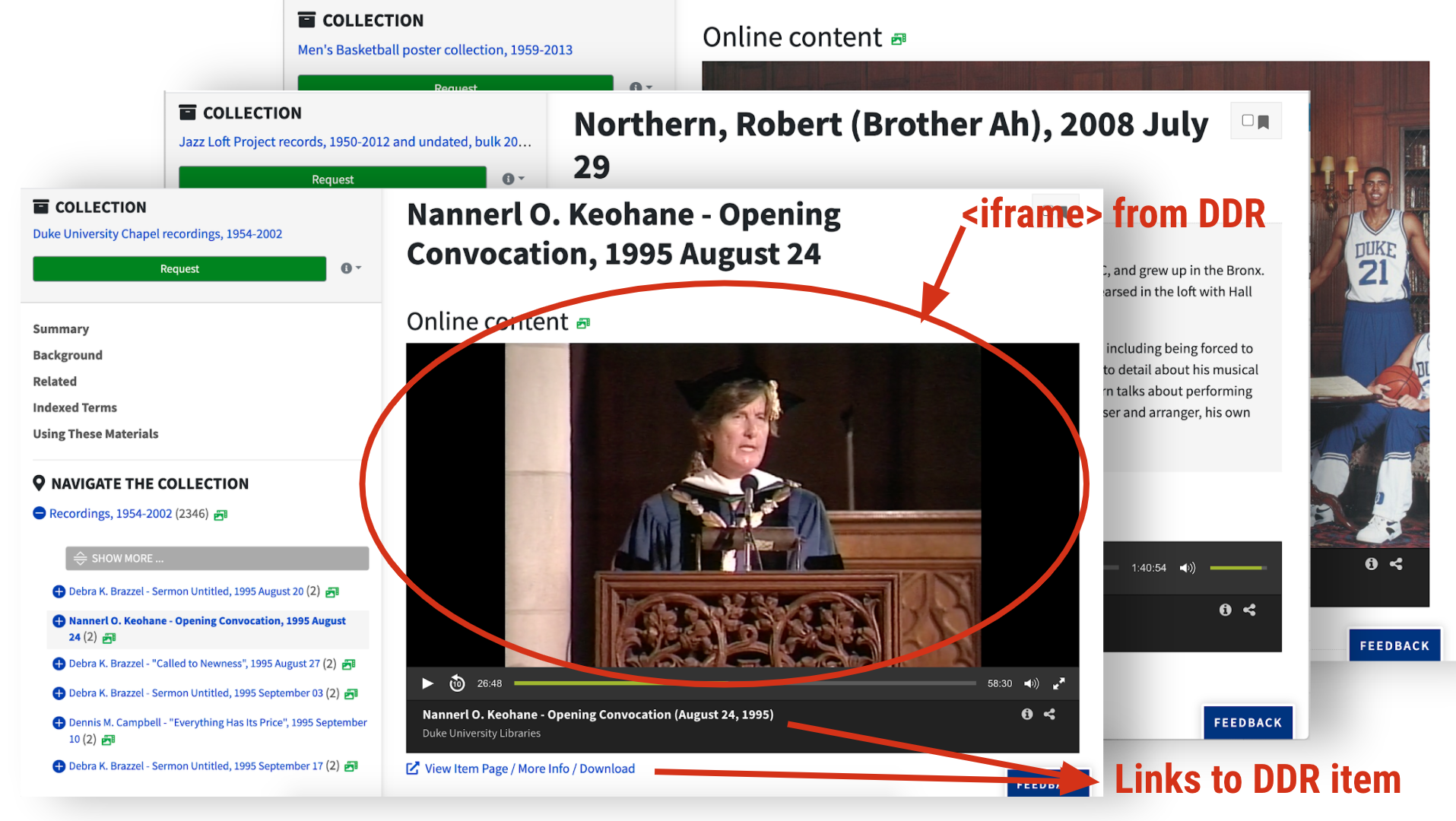
Digital Objects Integration
Digital objects from the Duke Digital Repository are presented inline in the finding aid component page.
DAO Roles. Indexed the @role attribute for <dao> elements; we used that to call templates for different kinds of digital content
Embedded Object Viewers. Used the Duke Digital Repository’s embed feature, which renders <iframe>s for images and AV.
Indexing
Whitespace compression. Added a step to the pipeline to remove extra whitespace before indexing. This seems to have slightly accelerated our time-to-index rather than slow it down.
More text, fewer strings. We encountered cases where note-like fields indexed as strings by ArcLight core (e.g., <scopecontent>) needed to be converted to text because we had more than 32,766 bytes of data (limit for strings) to put in them. In those cases, finding aids were failing to index.
Underscores. For the IDs that end up in a URL for a component, we added an underscore between the finding aid slug and the component ID. We felt these URLs would look cleaner and be better for SEO (our slugs often contain names).
Dates. Changed the date normalization rules (some dates were being omitted from indexing/display)
Bibliographic ID. We succeeded in indexing our bibliographic IDs from our EADs to power a collection-level Request button that leads a user to our homegrown requests system.
Formatting
EAD -> HTML. We extended the EAD-to-HTML transformation rules for formatted elements to cover more cases (e.g., links like <extptr> & <extref> or other elements like <archref> & <indexentry>)
Additional formatting and link render rules applied.
Formatting in Titles. We preserved bold or italic formatting in component titles.
ArcLight Core Contributions
We have been able to contribute some of our code back to the ArcLight core project to help out other adopters.
Setting the Stage
The behind-the-scenes foundational work deserves mention here — it represents some of the most complex and challenging aspects of the project. It makes the application development driving the changes I’ve shared above possible.
Gathered a diverse set of 40 representative sample EADs for testing
Dockerized our Duke ArcLight app to simplify developer environment setup
Provisioned a development/demo server for sharing progress with stakeholders
Automated continuous integration and deployment to servers using GitLabCI
Performed targeted data cleanup
Successfully got all 4,000 of our finding aids indexed in Solr on our demo server
Our team has accomplished a lot in three months, in large part due to the solid foundation the ArcLight core software provides. We’re benefiting from some amazing work done by many, many developers who have contributed their expertise and their code to the Blacklight and ArcLight codebases over the years. It has been a real pleasure to be able to build upon an open source engine– a notable contrast to our previous practice of developing everything in-house for finding aids discovery and access.
Still, much remains to be addressed before we can launch this summer.
The Road Ahead
Here’s a list of big things we still plan to tackle by July (other minor revisions/bugfixes will continue as well)…
ASpace -> ArcLight. We need a smoother publication pipeline to regularly get data from ArchivesSpace indexed into ArcLight.
Access & Use Statements. We need to revise the existing inheritance rules and make sure these statements are presented clearly. It’s especially important when materials are indeed restricted.
Relevance Ranking. We know we need to improve the ranking algorithm to ensure the most relevant results for a query appear first.
Analytics. We’ll set up some anonymized tracking to help monitor usage patterns and guide future design decisions.
Sitemap/SEO. It remains important that Google and other crawlers index the finding aids so they are discoverable via the open web.
Accessibility Testing / Optimization. We aim to comply with WCAG2.0 AA guidelines.
Single-Page View. Many of our stakeholders are accustomed to a single-page view of finding aids. There’s no such functionality baked into ArcLight, as its component-by-component views prioritize performance. We might end up providing a downloadable PDF document to meet this need.
More Data Cleanup. ArcLight’s feature set (especially around search/browse) reveals more places where we have suboptimal or inconsistent data lurking in our EADs.
More Community Contributions. We plan to submit more of our enhancements and bugfixes for consideration to be merged into the core ArcLight software.
If you’re a member of the Duke community, we encourage you toexplore our demo and provide feedback. To our fellow future ArcLight adopters, we would love to hear how your implementations or plans are shaping up, and identify any ways we might work together toward common goals.
Archival collection guides—also known as finding aids—are a critical part of the researcher experience when finding and accessing materials from the David M. Rubenstein Rare Book & Manuscript Library and the Duke University Archives. At present, we have guides for nearly 4,000 collections with upwards of one million components that have some level of description. Our collection guides site is visited by researchers about 400 times per day.
An example collection guide.
In 2020, we’ll be making significant changes to our systems supporting archival discovery and access. The main impetus for this shift is that our current platform has grown outdated and is no longer sustainable going forward. We intend to replace our platform with ArcLight, open source software backed by a community of peer institutions.
Finding Aids at Duke: Innovations Past
At Duke, we’re no strangers to pushing the boundaries of archival discovery through advances in technology. Way back in the mid 1990s, Duke was among pioneers rendering SGML-encoded finding aids into HTML. For most of the 90s and aughts we used a commercial platform, but we decided to develop our own homegrown finding aids front-end in 2007 (using the Apache Cocoon framework). We then replaced it in 2012 with another in-house platform built on the Django web framework.
Since going home-grown in 2007, we have been able to find some key opportunities to innovate within our platforms. Here are a few examples:
2013. Added inline digital object viewing, as part of a consortium-wide collaborative foray into large-scale manuscript digitization.
2014. Crosswalked metadata using Schema.org markup and used different Google APIs to power rich snippet search results (since deprecated).
Example archival component with inline embedded digital object and sticky navigation.
So, Why Migrate Now?
Our current platform was pretty good for its time, but a lot has changed in eight years. The way we build web applications today is much different than it used to be. And beyond desiring a modern toolset, there are major concerns going forward around size, search/indexing, and support.
Size
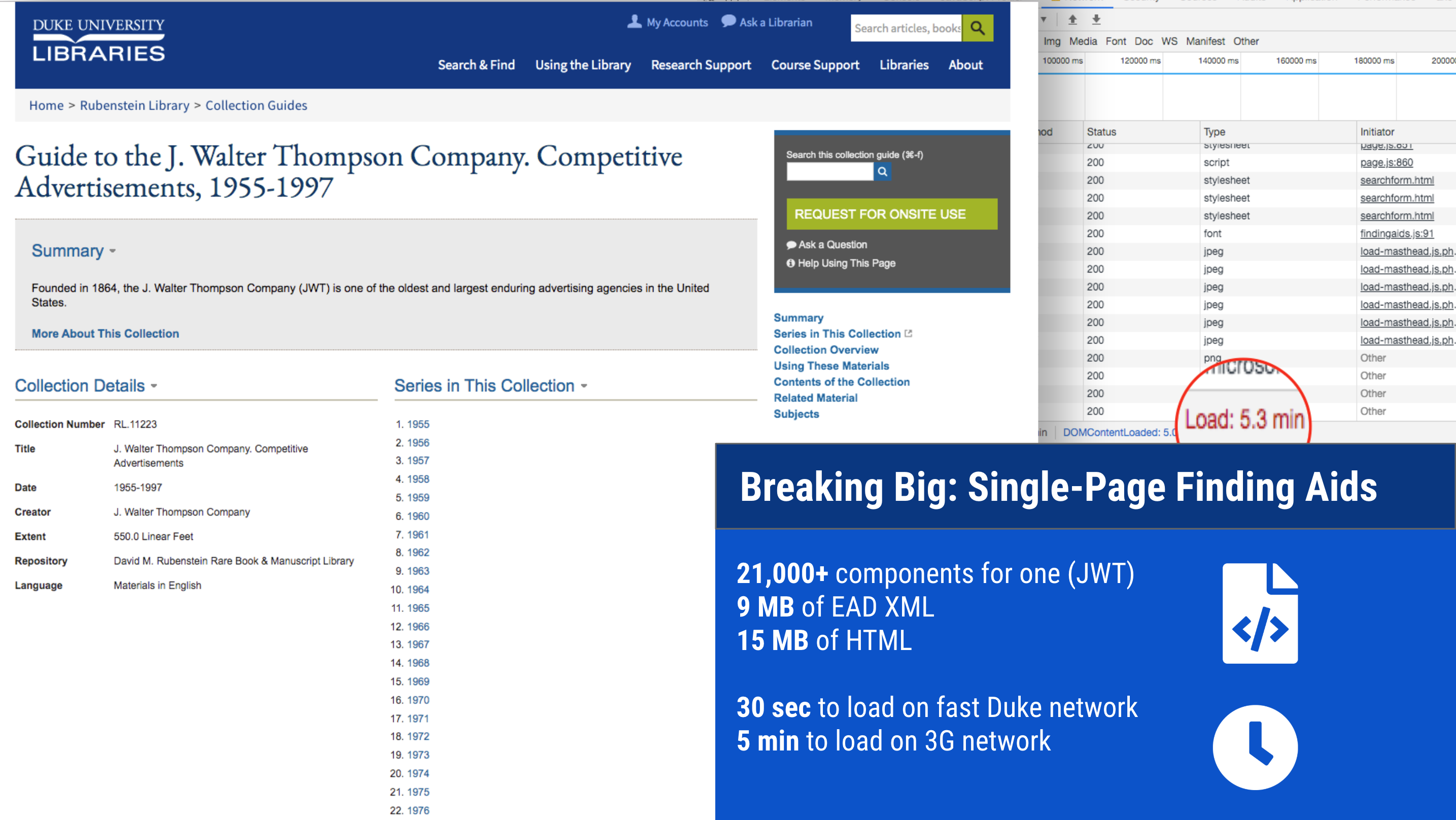
We have some enormous finding aids. And we have added more big ones over the years. This causes problems of scale, particularly with an interface like ours that renders each collection as a single web page with all of the text of its contents written in the markup. One of our finding aids contains over 21,000 components; all told it is 9MB of raw EAD transformed into 15MB of HTML.
A large finding aid — 15MB of HTML in a single page.
No amount of caching or server wizardry can change the fact that this is simply too much data to be delivered and rendered in a single webpage, especially for researchers in lower-bandwidth conditions. We need a solution that divides the data for any given finding aid into smaller payloads.
Search
Google Custom Search does a pretty nice job of relevance ranking and highlighting where in a finding aid a term matches (after all, that’s Google’s bread-and-butter). However, when used to power search in an application like this, it has some serious limitations. It only returns a maximum of one hundred results per query. Google doesn’t index 100% of the text, especially for our larger finding aids. And some finding aids are just mysteriously omitted despite our best efforts optimizing our markup for SEO and providing a sitemap.
Search Results powered by Google Custom Search
We need search functionality where we have complete control of what gets indexed, when, and how. And we need assurance that the entirety of the materials described will be discoverable.
Support
This is a familiar story. Homegrown applications used for several years by organizations with a small number of developers and a large number of projects to support become difficult to sustain over time. We have only one developer remaining who can fix our finding aids platform when it breaks, or prevent it from breaking when the systems around it change. Many of the software components powering the system are at or nearing end-of-life and they can’t be easily upgraded.
Where to Go From Here?
It has been clear for awhile that we would soon need a new platform for finding aids, but not as clear what platform we should pursue. We had been eyeing the progress of two promising open source community-built solutions emerging from our peer institutions: the ArchivesSpace Public UI (PUI), and ArcLight.
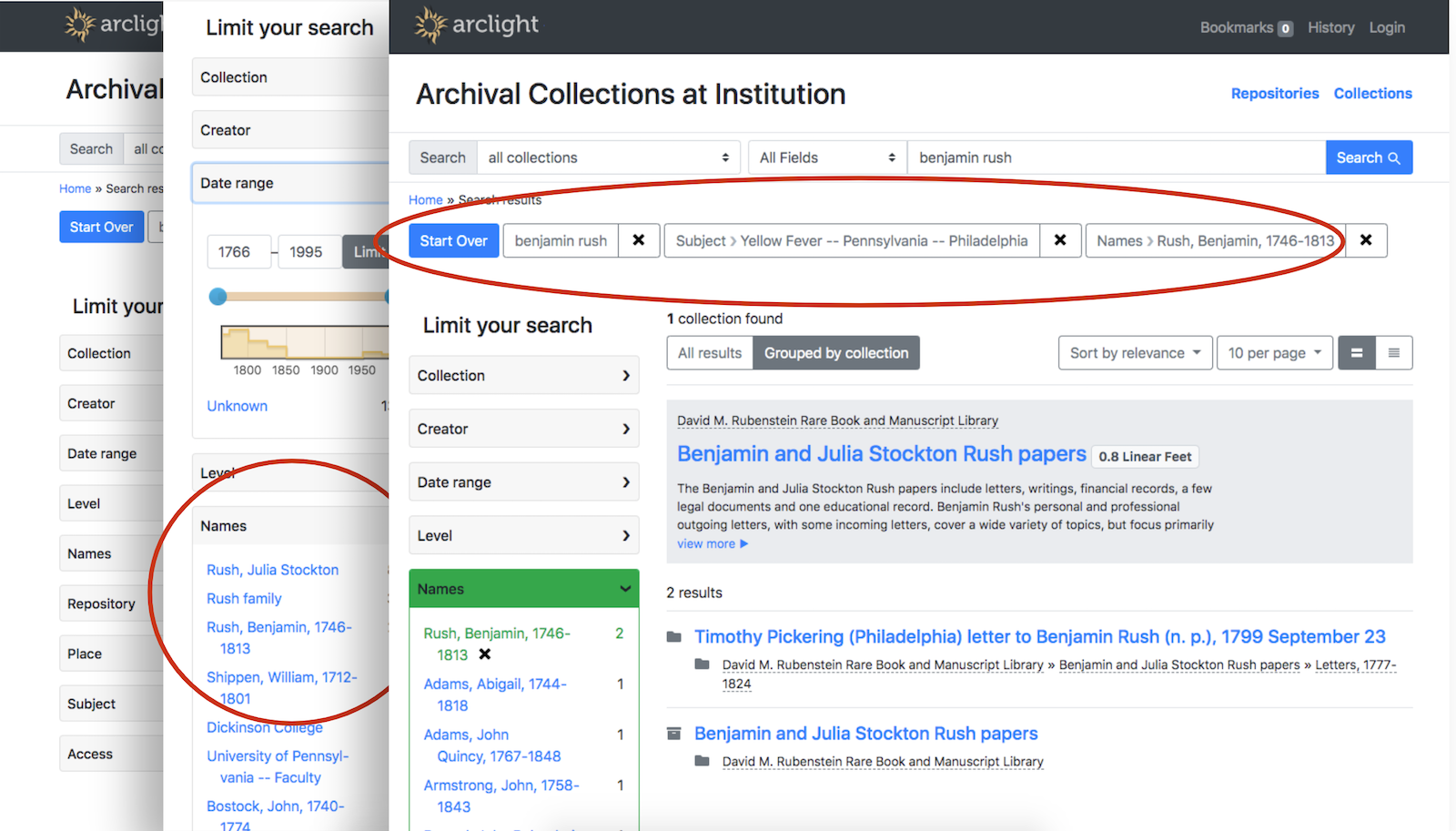
Over 2018-19, my colleague Noah Huffman and I co-led a project to install pilot instances of the ASpace PUI and ArcLight, index all of our finding aids in them, and then evaluate the platforms for their suitability to meet Duke’s needs going forward. The project involved gathering feedback from Duke archivists, curators, research services staff, and our digital collections implementation team. We looked at six criteria: 1) features; 2) ease of migration/customization; 3) integration with other systems; 4) data cleanup considerations; 5) impact on existing workflows; 6) sustainability/maintenance.
Comparison of the ASpace PUI and ArcLight, out-of-the-box UI.
There’s a lot to like about both the ASpace PUI and ArcLight. Feature-wise, they’re fairly comparable. Both are backed by a community of talented, respected peers, and either would be a suitable foundation for a usable, accessible interface to archives. In the end, we recommended that Duke pursue ArcLight, in large part due to its similarity to so much of the other software in our IT portfolio.
Duke is certainly not alone in our desire to replace an outdated, unsustainable homegrown finding aids platform, and intention to use ArcLight as a replacement.
This fall, with tremendous leadership from Stanford University Libraries, five universities collaborated on developing the ArcLight software further to address shared needs. Over a nine week work cycle from August to October, we had the good fortune of working alongside Stanford, Princeton, Michigan, and Indiana. The team addressed needs on several fronts, especially: usability, accessibility, indexing, context/navigation, and integrations.
Duke joined Stanford, Princeton, Michigan, and Indiana for Arclight Community Work Cycle II in fall 2019.
Three Duke staff members participated: I was a member of the Development Team, Noah Huffman a member of the Product Owners Team, and Will Sexton on the Steering Group.
The work cycle is complete and you can try out the current state of the core ArcLight demo application. It includes several finding aids from each of the participating partner institutions. Here are just a few highlights that have us excited about bringing ArcLight to Duke:
Search results can be grouped by collection. Faceted navigation helps pinpoint items of interest from deep within a finding aid.
Components are individually discoverable and have their own pages. Integrations with online content viewers and request systems such as Aeon are possible.
Here’s a final demo video (37 min) that nicely summarizes the work completed in the fall 2019 work cycle.
Lighting the Way
With some serious momentum from the fall ArcLight work cycle and plans taking shape to implement the software in 2020, the Duke Libraries intend to participate in the Stanford-led, IMLS grant-funded Lighting the Way project, a platform-agnostic National Forum on Archival Discovery and Delivery. Per the project website:
Lighting the Way is a year-long project led by Stanford University Libraries running from September 2019-August 2020 focused on convening a series of meetings focused on improving discovery and delivery for archives and special collections.
Coming in 2020: ArcLight Implementation at Duke
There’ll be much more share about this in the new year, but we are gearing up now for a 2020 ArcLight launch at Duke. As good as the platform is now out-of-the-box, we’ll have to do additional development to address some local needs, including:
Duke branding
An efficient preview/publication workflow
Digital object viewing / repository integration
Sitemap generation
Some data cleanup
Building these local customizations will be time well-spent. We’ll also look for more opportunities to collaborate with peers and contribute code back to the community. The future looks bright for Duke with ArcLight lighting the way.
One of the biggest and most important barriers for us to tackle is the accessibility of our web content. Duke University’s Web Accessibility site sums it up well:
Duke believes web content needs to be accessible to people with a wide range of abilities, including visual, auditory, physical, speech, cognitive, language, learning, and neurological abilities.
The Duke Web Accessibility website is a tremendous resource for the Duke community.
As one of the largest research libraries in the U.S., we have a whole lot of content on the web to consider.
Our website alone comprises over a thousand pages with more than fifty staff contributors. The library catalog interface displays records for over 13 million items at Duke and partner libraries. Our various digital repositories and digital exhibits platforms host hundreds of thousands of interactive digital objects of different types, including images, A/V, documents, datasets, and more. The list goes on.
Any attempt to take a full inventory of the library’s digital content reveals potentially several million web pages under the library’s purview, and all that content is managed and rendered via a dizzying array of technology platforms. We have upwards of a hundred web applications with public-facing interfaces. We built some of these ourselves, some are community-developed (with local customizations), and others we have licensed from vendors. Some interfaces are new, some are old. And some are really old, dating all the way back to the mid-90s.
Ensuring that this content is equally accessible to everyone is important, and it is indeed a significant undertaking. We must also be vigilant to ensure that it stays accessible over time.
With that as our context, I’d like to highlight a few recent efforts in the library to improve the accessibility of our digital resources.
Style Guide With Color Contrast Checks
In January 2019, we launched a new catalog, replacing a decade-old platform and its outdated interface. As we began developing the front-end, we knew we wanted to be consistent, constrained, and intentional in how we styled elements of the interface. We were especially focused on ensuring that any text in the UI had sufficient contrast with its background to be accessible to users with low vision or color-blindness.
We tried out a few existing “living style guide” frameworks. But none of them proved to be a good fit, particularly for color contrast management. So we ended up taking a DIY approach and developed our own living style guide using Javascript and Ruby.
The library catalog’s living style guide dynamically checks for color contrast accessibility.
Here’s how it works. In our templates we specify the array of color variable names for each category. Then we use client-side Javascript to dynamically measure the hex & RGB values and the luminance of each color in the guide. From those figures, we return score labels for black and white contrast ratios, color-coded for WCAG 2.0 compliance.
This style guide is “living” in that it’s a real-time up-to-date reflection of how elements of the UI will appear when using particular color variable names and CSS classes. It helps to guide developers and other project team members to make good decisions about colors from our palette to stay in compliance with accessibility guidelines.
Audiovisual Captions & Interactive Transcripts
In fall 2017, I wrote about an innovative, custom-developed feature in our Digital Repository that renders interactive caption text for A/V within and below our media player. At that time, however, none of our A/V items making use of that feature were available to the public. In the months since then, we have debuted several captioned items for public access.
We extended these features in 2018, including: 1) exporting captions on-the-fly as Text, PDF, or original WebVTT files, and 2) accommodating transcript files that originated as documents (PDF, Word)
WebVTT caption files for A/V are rendered as interactive HTML transcripts and can be exported into text or PDF.
In the course of this assessment, we were able to identify (and then fix!) several accessibility issues in DukeSpace. I’ll share two strategies in particular from the guide that proved to be really effective. I highly recommend using them frequently.
The Keyboard Test
How easy is it to navigate your site using only your keyboard? Can you get where you want to go using TAB, ENTER, SPACE, UP, and DOWN? Is it clear which element of the page current has the focus?
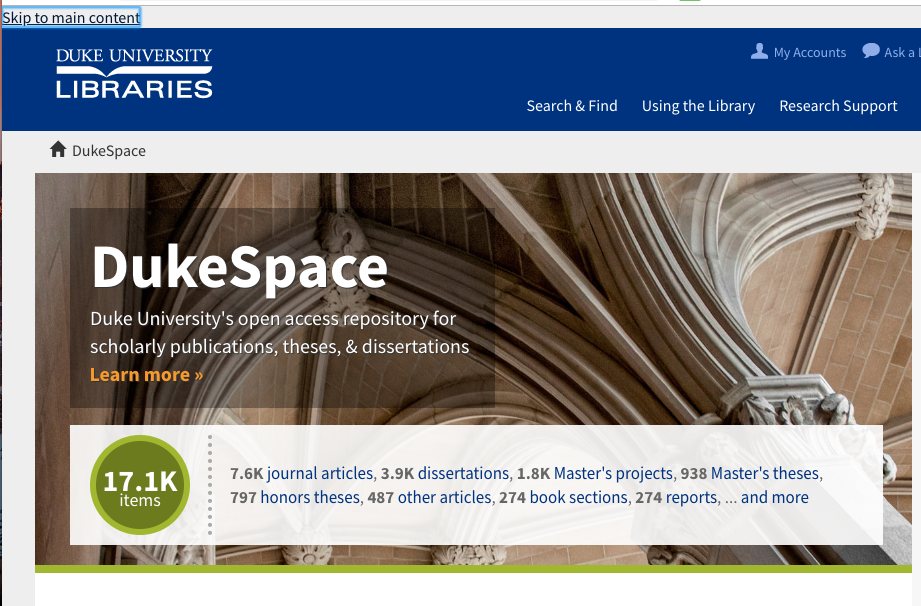
A “Skip to main content” feature in DukeSpace improves navigation via keyboard or assistive devices.
This test illuminated several problems. But with a few modest tweaks to our UI markup, we were able to add semantic markers to designate page sections and a skip to main content link, making the content much more navigable for users with keyboards and assistive devices alike.
A Browser Extension
If you’re a developer like me, chances are you already spend a lot of time using your browser’s Developer Tools pane to look under the hood of web pages, reverse-engineer UIs, mess with styles and markup, or troubleshoot problems.
The Deque Systems aXe Chrome Extension (also available for Firefox) integrates seamlessly into existing Dev Tools. It’s a remarkably useful tool to have in your toolset to help quickly find and fix accessibility issues. Its interface is clear and easy to understand. It finds and succinctly describes accessibility problems, and even tells you how to fix them in your code.
An image from the Deque aXe Chrome extension site showing the tool in action.
With aXe testing, we quickly learned we had some major issues to fix. The biggest problems revealed were missing form labels and page landmarks, and low contrast on color pairings. Again, these were not hard to fix since the tool explained what to do, and where.
Turning away from DSpace for a moment, see this example article published on a popular academic journal’s website. Note how it fares with an automated aXe accessibility test (197 violations of various types found). And if you were using a keyboard, you’d have to press Tab over 100 times in order to download a PDF of the article.
UI for a published journal article in a publisher’s website after running the aXe accessibility test. Violations found: 197.
Open access copy of an article in DukeSpace: No accessibility violations found.
Here’s another example of an open access article in DukeSpace vs. its published counterpart in the website of a popular journal (PNAS). While the publisher’s site markup addresses many common accessibility issues, it still shows seven violations in aXe. And perhaps most concerning is that it’s completely unnavigable via a keyboard: the stylesheets have removed all focus styles from displaying.
Concluding Thoughts
Libraries are increasingly becoming champions for open access to scholarly research. The overlap in aims between the open access movement and web accessibility in general is quite striking. It all boils down to removing barriers and making access to information as inclusive as possible.
Our open access repository UIs may never be able to match all the feature-rich bells and whistles present in many academic journal websites. But accessibility, well, that’s right up our alley. We can and should do better. It’s all about being true to our values, collaborating with our community of peers, and being vigilant in prioritizing the work.
Look for many more accessibility improvements throughout many of the library’s digital resources as the year progresses.
2018 has featured several monumental changes in the library’s technology platforms. One of the most impactful shifts this year was revitalizing DukeSpace, our DSpace-based institutional repository (IR) software, home to over 16,000 open-access articles, theses, and dissertations from Duke scholars.
Back in March, we celebrated a successful multi-version upgrade for DSpace, and along with it, a major upgrade to the integral Symplectic Elements Research Information Management platform. On the heels of that project, we decided to capitalize on the project team’s momentum and invest two more months of focused attention (four “sprints” in developer-speak).
The goals for that period? First, tie up the loose ends from the upgrade. Then, seize some clear opportunities to build upon our freshly-rearchitected metadata, creating innovative features in the UI to benefit scholars. By scholars, we mean — in part — the global audience of researchers openly discovering and using the articles in DukeSpace. But we especially mean the scholars at Duke who created them in the first place.
We are excited to share the results of our work with the Duke community and beyond. Here are the noteworthy additions:
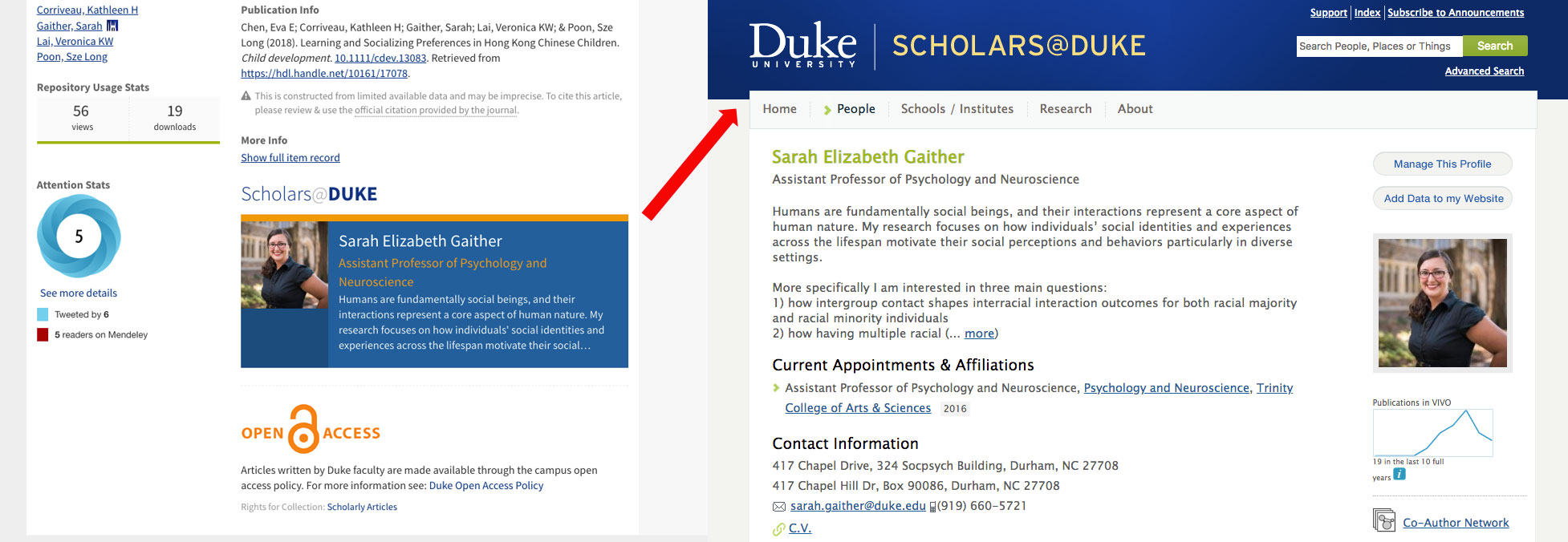
Scholars@Duke Author Profiles
Item pages now display a brief embedded profile for each Duke author, featuring their preferred name, a photo, position title, and brief description of their research interests. This information comes from the scholars themselves, who manage their profiles via Scholars@Duke (powered by the open-source VIVO platform).
A brief author profile in a DukeSpace item leads to the full profile in Scholars@Duke.
Scholars@Duke provides a handy SEO-friendly profile page (example) for each scholar. It aggregates their full list of publications, courses taught, news articles in which they’re mentioned, and much more. It also has useful APIs for building widgets to dynamically repurpose the data for display elsewhere. Departments throughout Duke (example) use these APIs to display current faculty information on their web sites without requiring anyone to manually duplicate or update it. And now, the library does, too.
Scholars’ own descriptions of their research interests entice a visitor to learn more about their work.
Featuring researchers in this manner adds several other benefits, including:
Uses a scholar’s own preferred current version of their name and title; that may not be identical to what is stored in the item’s author metadata.
Puts users one click away from the author’s full profile at Scholars@Duke, where one can discover the entirety of the author’s publications, open-access or not.
Helps search engines make stronger semantic connections between an author’s profile information and their works available online.
Introduces a unique value-add feature for our open-access copy of an article that’s unlikely to ever be possible to replicate for the published version on the academic journal’s website.
Makes the DukeSpace item pages look better, warmer, and more inviting.
Profiles for multi-author articles
With this feature, we are truly pushing beyond the boundaries of what an institutional repository traditionally does. And likewise, we feel we’re raising the bar for how academic research libraries can showcase the members of their communities alongside their collected works.
Other New Features
Beyond these new author profiles, we managed to fit in a few more enhancements around citations, the homepage, and site navigation. Here’s a quick rundown:
Citations
We now present an easily copyable citation, composed from the various metadata available for each item. This includes the item’s permalink.
DukeSpace citation for a dissertation
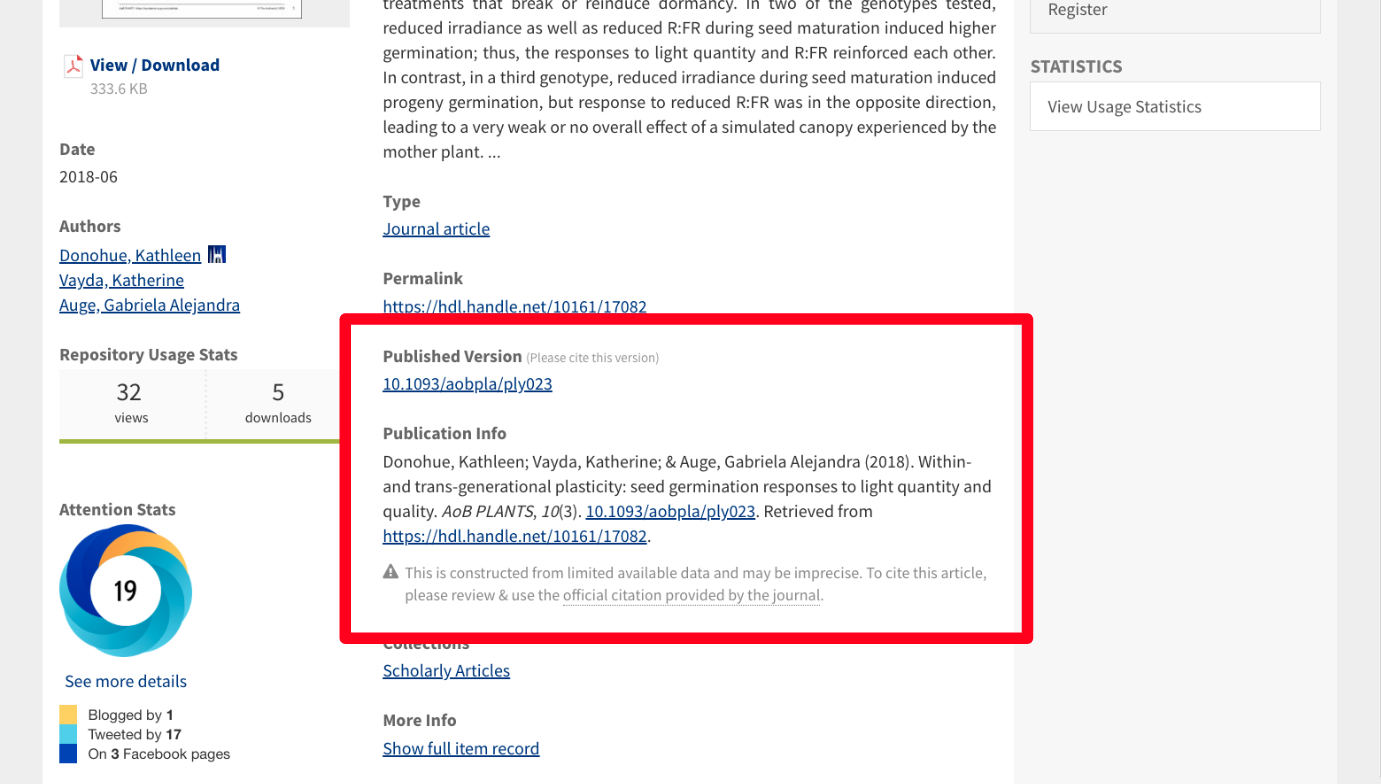
In cases when there’s a published version of an article available, we direct users to review and use that citation instead.
DukeSpace article with a DOI for a published version.
Item pages also now display a “Citation Stats” badge in the sidebar, powered by Digital Science’s Dimensions tool. Click it to explore other scholarly work that has cited the current item.
Homepage
Finally, we topped off this project phase by redesigning DukeSpace’s homepage. Notable among the changes: a clearer indication of the number of items (broken down by type), a dynamic list of trending items, and streamlined menu navigation in the sidebar.
Final Thoughts
Duke Libraries’ current strategic plan emphasizes the mission-critical importance of our open-access publishing and repository efforts, and also demands that we “highlight and promote the scholarly activities of our faculty, students, and staff.” This two-month DukeSpace enhancements project was a great opportunity for us to think outside the box about our technology platforms, and consider how those goals relate.
Many thanks to several people whose work enabled these features to come to life, especially Maggie Dickson, Hugh Cayless, Paolo Mangiafico, and the Scholars@Duke team.
Near the tail end of 2017, the Duke Libraries committed to a major multi-version upgrade for DukeSpace (powered by the open-source repository platform DSpace), and assembled an Avengers-like team to combine its members’ complementary powers to conquer it together. The team persisted through several setbacks and ultimately prevailed in its mission. The new site launched successfully in March 2018.
That same team is now back for a sequel, collaborating to tackle additional issues around system integrations, statistics/reporting, citations, and platform maintenance. Phase II of the project will wrap up this summer.
I’d like to share a bit more about the DSpace upgrade project, beginning with some background on why it’s important and where the platform fits into the larger picture at Duke. Then I’ll share more about the areas to which we have devoted the most developer time and attention over the past several months. Some of the development efforts were required to make DSpace 6 viable at all for Duke’s ongoing needs. Other efforts have been to strengthen connections between DukeSpace and other platforms. We have also been enhancing several parts of the user interface to optimize its usability and visual appeal.
DSpace at Duke: What’s in It?
Duke began using DSpace around 2006 as a solution for Duke University Archives to collect and preserve electronic theses and dissertations (ETDs). In 2010, the university adopted an Open Access policy for articles authored by Duke faculty, and DukeSpace became the host platform to make these articles accessible under the policy. These two groups of materials represent the vast majority of the 15,000+ items currently in the platform. Ensuring long-term preservation, discovery, and access to these items is central to the library’s mission.
Integrations With Other Systems
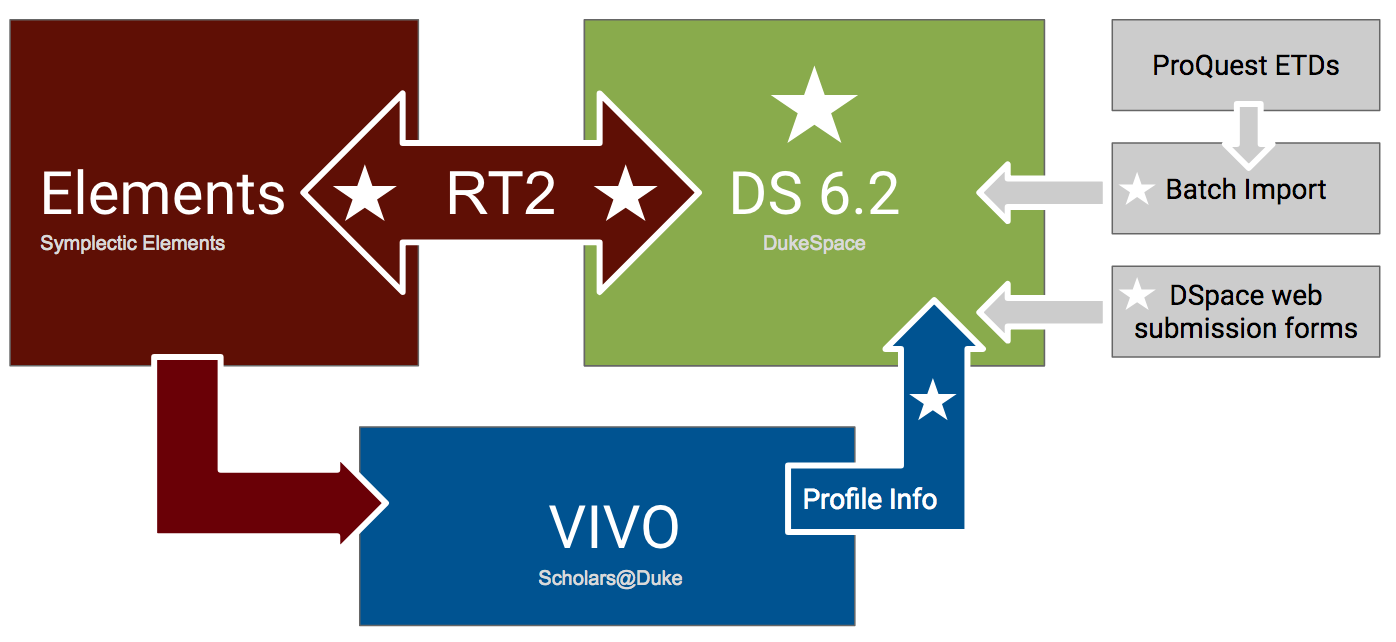
DukeSpace is one of three key technology platforms working in concert to support scholarly communications at Duke. The other two are the proprietary Research Information Management System Symplectic Elements, and the open-source research networking tool VIVO (branded as Scholars@Duke). Here’s a diagram illustrating how the platforms work together, created by my colleague Paolo Mangiafico:
Credit: Paolo Mangiafico
In a nutshell, DSpace plays a critical role in Duke University scholars’ ability to have their research easily discovered, accessed, and used.
Faculty use Elements to manage information about their scholarly publications. That information is pulled neatly into Scholars@Duke which presents for each scholar an authoritative profile that also includes contact info, courses taught, news stories in which they’re mentioned, and more.
The Scholars@Duke profile has an SEO-friendly URL, and the data from it is portable: it can be dynamically displayed anywhere else on the web (e.g., departmental websites).
Elements is also the place where faculty submit the open access copies of their articles; Elements in turn deposits those files and their metadata to DSpace. Faculty don’t encounter DSpace at all in the process of submitting their work.
Publications listed in a Scholars@Duke profile automatically include a link to the published version (which is often behind a paywall), and a link to the open access copy in DSpace (which is globally accessible).
Upgrading DSpace: Ripple Effects
The following diagram expands upon the previous one. It adds boxes to the right to account for ETDs and other materials deposited to DSpace either by batch import mechanisms or directly via the application’s web input forms. In a vacuum, a DSpace upgrade–complex as that is in its own right–would be just the green box. But as part of an array of systems working together, the upgrade meant ripping out and replacing so much more. Each white star on the diagram represents a component that had to be thoroughly investigated and completely re-done for this upgrade to succeed.
One of the most complicated factors in the upgrade effort was the bidirectional arrow marked “RT2”: Symplectic’s new Repository Tools 2 connector. Like its predecessor RT1, it facilitates the deposit of files and metadata from Elements into DSpace (but now via different mechanisms). Unlike RT1, RT2 also permits harvesting files and metadata from DSpace back into Elements, even for items that weren’t originally deposited via Elements. The biggest challenges there:
Divergent metadata architecture. DukeSpace and Elements employ over 60 metadata fields apiece (and they are not the same).
Crosswalks. The syntax for munging/mapping data elements from Elements to DSpace (and vice versa) is esoteric, new, and a moving target.
Legacy/inconsistent data. DukeSpace metadata had not previously been analyzed or curated in the 12 years it had been collected.
Newness. Duke is likely the first institution to integrate DSpace 6.x & Elements via RT2, so a lot had to be figured out through trial & error.
Kudos to superhero metadata architect Maggie Dickson for tackling all of these challenges head-on.
User Interface Enhancements in Action
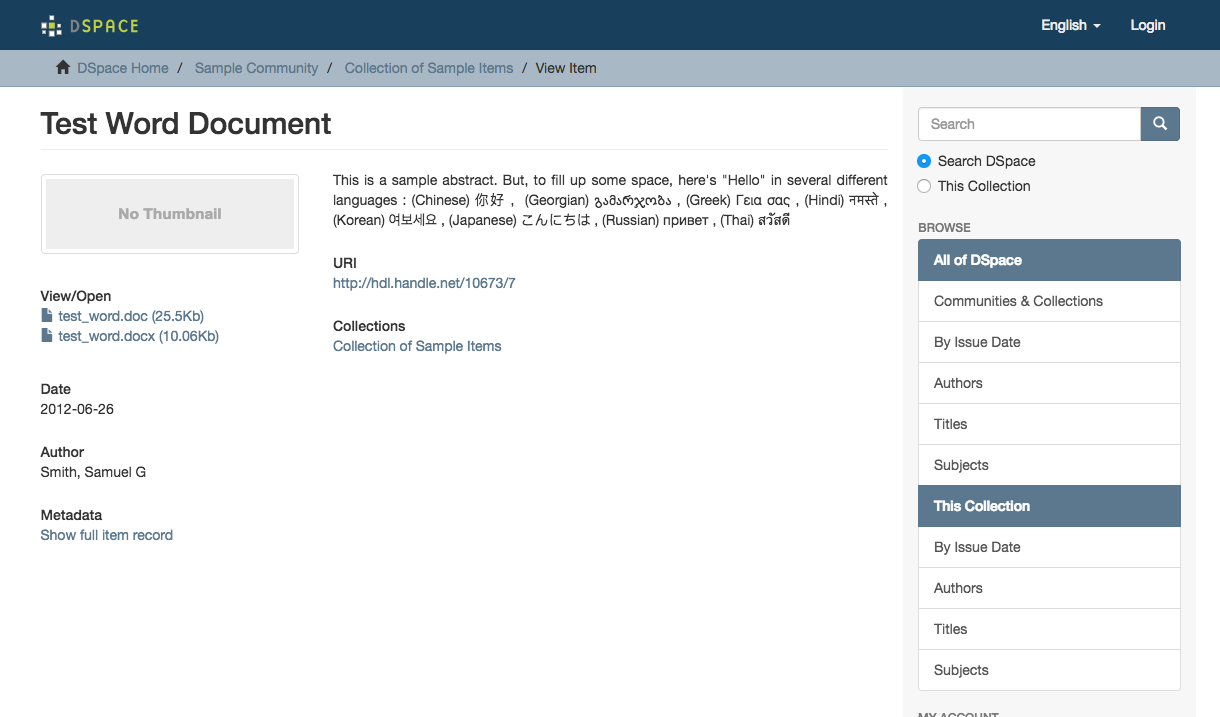
There are over 2,000 DSpace instances in the world. Most implementors haven’t done much to customize the out-of-the-box templates, which look something like this for an item page:
DSpace interface out of the box. From http://demo.dspace.org/xmlui/
The UI framework itself is outdated (driven via XSLT 1.0 through Cocoon XML pipelines), which makes it hard for anyone to revise substantially. It’s a bit like trying to whittle a block of wood into something ornate using a really blunt instrument. The DSpace community is indeed working on addressing that for DSpace 7.0, but we didn’t have the luxury to wait. So we started with the vanilla template and chipped away at it, one piece at a time. These screenshots highlight the main areas we have been able to address so far.
We configured DSpace to generate and display thumbnail images for all items. Then we added icons corresponding to MIME types to help distinguish different kinds of files. We added really prominent indicators for when an item was embargoed (and when it would become available), and also revised the filesize display to be more clear and concise.
Usage & Attention Stats
Out of the box, DSpace item statistics are only available by clicking a link on the item page to go to a separate stats page. We figured out how to tap into the Solr statistics core and transform that data to display item views and file downloads directly in the item sidebar for easier access. We were also successful showing an Altmetric donut badge for any article with a DOI. These features together help provide a clear indication on the item page how much of an impact a work has made.
Rights
We added a lookup from the item page to retrieve the parent collection’s rights statement, which may contain a statement about Open Access, a Creative Commons license, or other explanatory text. This will hopefully assert rights information in a more natural spot for a user to see it, while at the same time draw more attention to Duke’s Open Access policy.
Scholars@Duke Profiles & ORCID Links
For any DukeSpace item author with a Scholars@Duke profile, we now display a clickable icon next to their name. This leads to their Scholars@Duke profile, where a visitor can learn much more about the scholar’s background, affiliations, and other research. Making this connection relies on some complicated parts: 1) enable getting Duke IDs automatically from Elements or manually via direct entry; 2) storing the ID in a DSpace field; 3) using the ID to query a VIVO API to retrieve the Scholars@Duke profile URL. We are able to treat a scholar’s ORCID in a similar fashion.
Other Development Areas
Beyond the public-facing UI, these areas in DSpace 6.2 also needed significant development for the upgrade project to succeed:
Fixed several bugs related to batch metadata import/export
Developed a mechanism to create user accounts via batch operations
Modified features related to authority control for metadata values
Coming Soon
By summer 2018, we aim to have the following in place:
Streamlined Sidebar
Add collapsable / expandable facet and browse options to reduce the number of menu links visible at any given time.
Citations
Present a copyable citation on the item page.
…And More!
Upgrade the XSLT processor from Xalan to Saxon, using XLST 3.0; this will enable us to accomplish more with less code going forward
Revise the Scholars@Duke profile lookup by using a different VIVO API
Create additional browse/facet options
Display aggregated stats in more places
We’re excited to get all of these changes in place soon. And we look forward to learning more from our users, our collaborators, and our peers in the DSpace community about what we can do next to improve upon the solid foundation we established during the project’s initial phases.
We kicked off the spring 2018 semester by rolling out a brand-new design for the David M. Rubenstein Library website. The new site features updated imagery from the collections, better navigation, and more prominent presence for the exhibits currently on display.
Much credit goes to Katie Henningsen and Kate Collins who championed the project.
Objectives for the Redesign
Make wayfinding from the homepage clearer (by reorganizing links into a primary dropdown navigation)
Dynamically feature Rubenstein Library exhibits that are currently on display
Improve navigation to key Rubenstein site pages from within research center / collection pages
Display larger images illustrative of the library’s distinctive and diverse collections
Retain aspects of the homepage that have been effective, e.g., hours and resource search boxes
Improve the site aesthetic
Internal Navigation
With a new primary navigation in hand on the Rubenstein homepage that links to key pages in the site, we began to explore ways to get visitors to those links in an unobtrusive way when they aren’t on the homepage. Each research center within the library, e.g., the John W. Hartman Center for Sales, Advertising & Marketing History, has its own sub-site with its own secondary menus, which already contend a bit with the blue Duke Libraries menu in the masthead. To avoid burying visitors in a Russian nesting doll of navigation, we decided to try dropping the RL menu down from the breadcrumb trail link so it’s tucked away, but still accessible when needed. We’re eager to learn whether or not this is effective.
Rubenstein primary navigation menu available from breadcrumb trail.
A Look Back
Depending on how you count, this is now the seventh or eighth homepage design for the Rubenstein Library (formerly the Rare Book, Manuscript, and Special Collections Library; formerly the Special Collections Library). I thought I’d take a quick stroll down memory lane, courtesy of the Internet Archive’s Wayback Machine, to reflect on how far we have come over the years.
used a flat aesthetic removing gradients, shadows, rounded corners
2018
January 2018
Features
lightened the overall aesthetic
featured image cycling from selections at random (diagonally sliced using css clip-path polygons)
prominent current exhibits feed with images
a primary nav with dropdown menus
How long will this latest edition of the Rubenstein Library homepage stick around? Only time will tell, but we’ll surely continue to iterate, learn from the past, and improve with each attempt. For now, we’re pleased with the new site, and hope you will be as well.
* Revised Feb 9, 2018 to reflect that the first version using a content management system was in 2005 rather than 2007.
Over the course of 2017, we improved our capacity to support digital audiovisual materials in the Duke Digital Repository (DDR) by leaps and bounds. A little more than a year ago, I had written a Bitstreams blog post highlighting the new features we had just developed in the DDR to provide basic functionality for AV, especially in support of the Duke Chapel Recordings collection. What a difference a year makes.
This past year brought renewed focus on AV development, as we worked to bring the NEH grant-funded Radio Haiti Archive online (launched in June). At the same time, our digital collections legacy platform migration efforts shifted toward moving our existing high-profile digital AV material into the repository.
Closed Captions
At Duke University Libraries, we take accessibility seriously. We aim to include captions or transcripts for the audiovisual objects made available via the Duke Digital Repository, especially to ensure that the materials can be perceived and navigated by people with disabilities. For instance, work is well underway to create closed captions for all 1,400 items in the Duke Chapel Recordings project.
Captioned video displays a CC button and shows captions as an overlay in the video player. Example from the AdViews collection, coming soon to the DDR.
The DDR now accommodates modeling and ingest for caption files, and our AV player interface (powered by JW Player) presents a CC button whenever a caption file is available. Caption files are encoded using WebVTT, the modern W3C standard for associating timed text with HTML audio and video. WebVTT is structured so as to be machine-processable, while remaining lightweight enough to be reasonably read, created, or edited by a person. It’s a format that transcription vendors can provide. And given its endorsement by W3C, it should be a viable captioning format for a wide range of applications and devices for the foreseeable future.
Text cues from a WebVTT caption file for an audio item in the Duke Chapel Recordings collection.
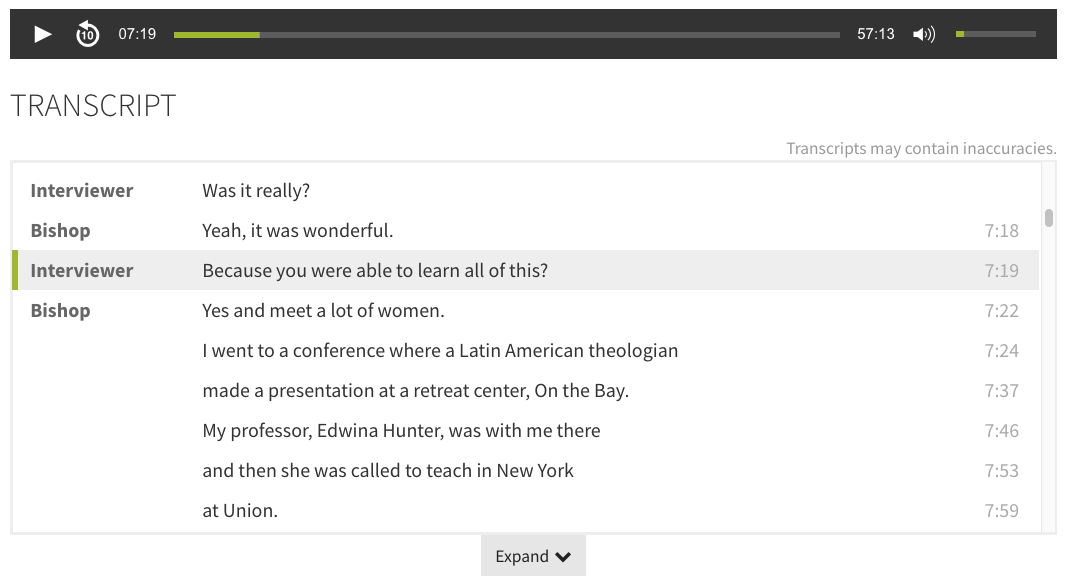
Interactive Transcripts
Displaying captions within the player UI is helpful, but it only gets us so far. For one, that doesn’t give a user a way to just read the caption text without requiring them to play the media. We also need to support captions for audio files, but unlike with video, the audio player doesn’t include enough real estate within itself to render the captions. There’s no room for them to appear.
So for both audio and video, our solution is to convert the WebVTT caption files on-the-fly into an interactive in-page transcript. Using the webvtt-ruby gem (developed by Coconut) , we parse the WebVTT text cues into Ruby objects, then render them back on the page as HTML. We then use the JWPlayer Javascript API to keep the media player and the HTML transcript in sync. Clicking on a transcript cue advances the player to the corresponding moment in the media, and the currently-playing cue gets highlighted as the media plays.
Example interactive synchronized transcript for an audio item (rendered from a WebVTT caption file). From a collection coming soon to the DDR.
We also do some extra formatting when the WebVTT cues include voice tags (<v> tags), which can optionally indicate the name of the speaker (e.g., <v Jane Smith>). The in-page transcript is indexed by Google for search retrieval.
Transcript Documents
In many cases, especially for audio items, we may have only a PDF or other type of document with a transcript of a recording that isn’t structured or time-coded. Like captions, these documents are important for accessibility. We have developed support for displaying links to these documents near the media player. Look for some new collections using this feature to become available in early 2018.
Transcript documents presented above the media player. Coming soon to AV collections in the DDR.
A/V Embedding
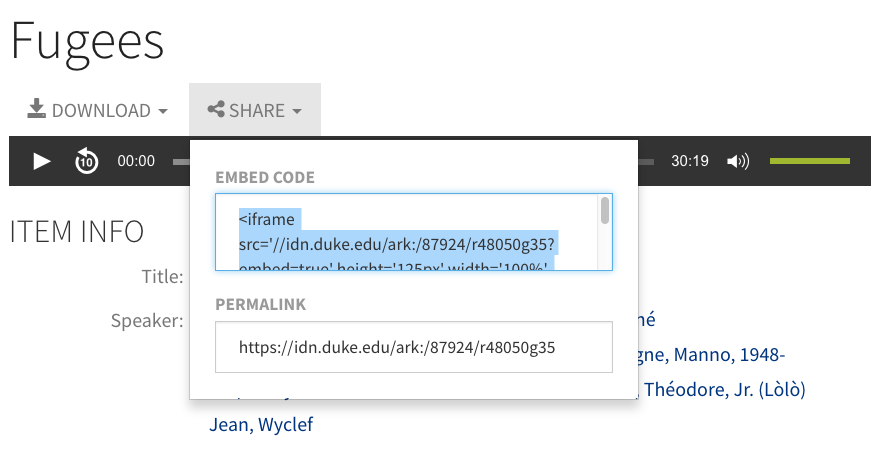
The DDR web interface provides an optimal viewing or listening experience for AV, but we also want to make it easy to present objects from the DDR on other websites, too. When used on other sites, we’d like the objects to include some metadata, a link to the DDR page, and proper attribution. To that end, we now have copyable <iframe> embed code available from the Share menu for AV items.
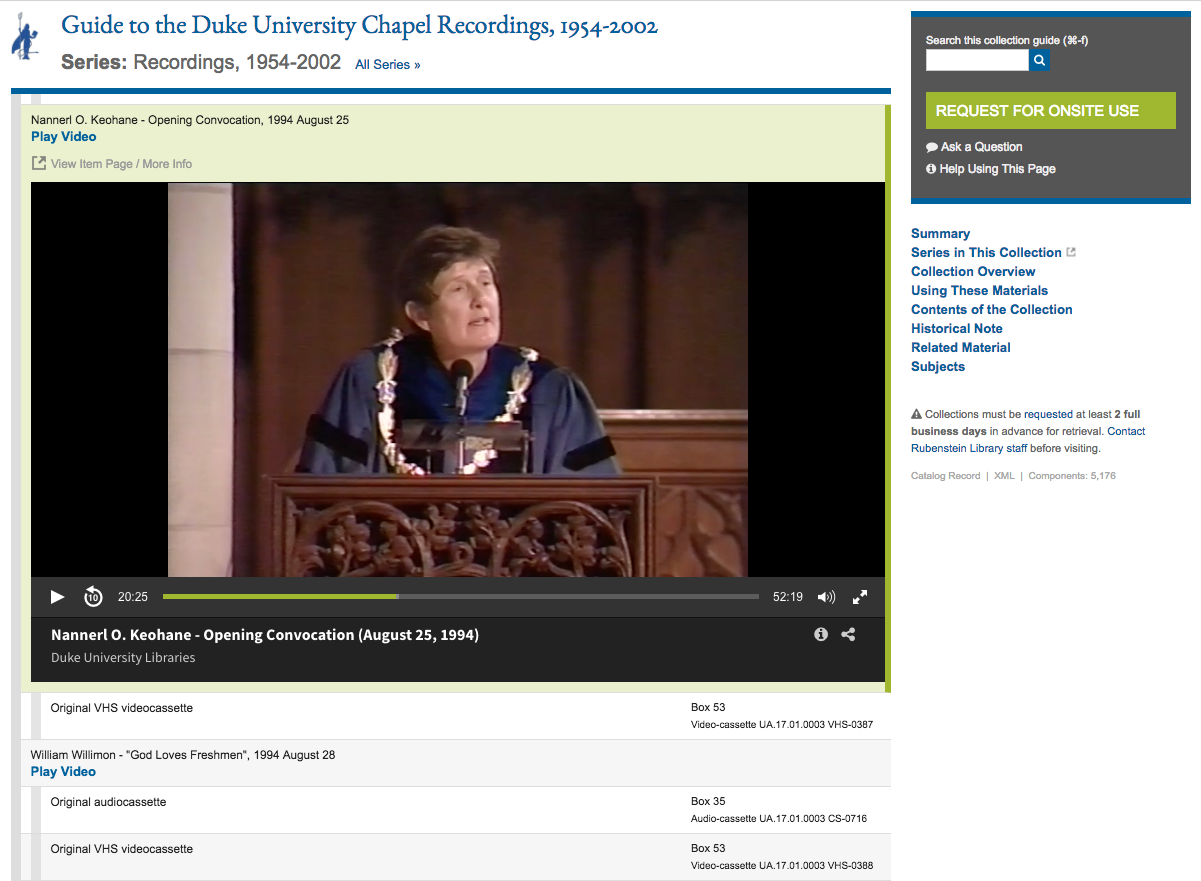
This embed code is also what we now use within the Rubenstein Library collection guides (finding aids) interface: it lets us present digital objects from the DDR directly from within a corresponding collection guide. So as a researcher browses the inventory of a physical archival collection, they can play the media inline without having to leave.
Embedded view of a DDR video from the Duke Chapel Recordings collection presented inline in a Rubenstein Library archival collection guide.
Sites@Duke Integration
If your website or blog is one of the thousands of WordPress sites hosted and supported by Sites@Duke — a service of Duke’s Office of Information Technology (OIT) — we have good news for you. You can now embed objects from the DDR using WordPress shortcode. Sites@Duke, like many content management systems, doesn’t allow authors to enter <iframe> tags, so shortcode is the only way to get embeddable media to render.
Sites@Duke WordPress sites can embed DDR media by using shortcode with the DDR item’s permalink.
And More!
Here are the other AV-related features we have been able to develop in 2017:
Access control: master files & derivatives alike can be protected so access is limited to only authorized users/groups
Video thumbnail images: model, manage, and display
Video poster frames: model, manage, and display
Intermediate/mezzanine files: model and manage
Rights display: display icons and info from RightsStatements.org and Creative Commons, so it’s clear what users are permitted to do with media.
What’s Next
We look forward to sharing our recent AV development with our peers at the upcoming Samvera Connect conference (Nov 6-9, 2017 in Evanston, IL). Here’s our poster summarizing the work to date: