

Archival collection guides—also known as finding aids—are a critical part of the researcher experience when finding and accessing materials from the David M. Rubenstein Rare Book & Manuscript Library and the Duke University Archives. At present, we have guides for nearly 4,000 collections with upwards of one million components that have some level of description. Our collection guides site is visited by researchers about 400 times per day.
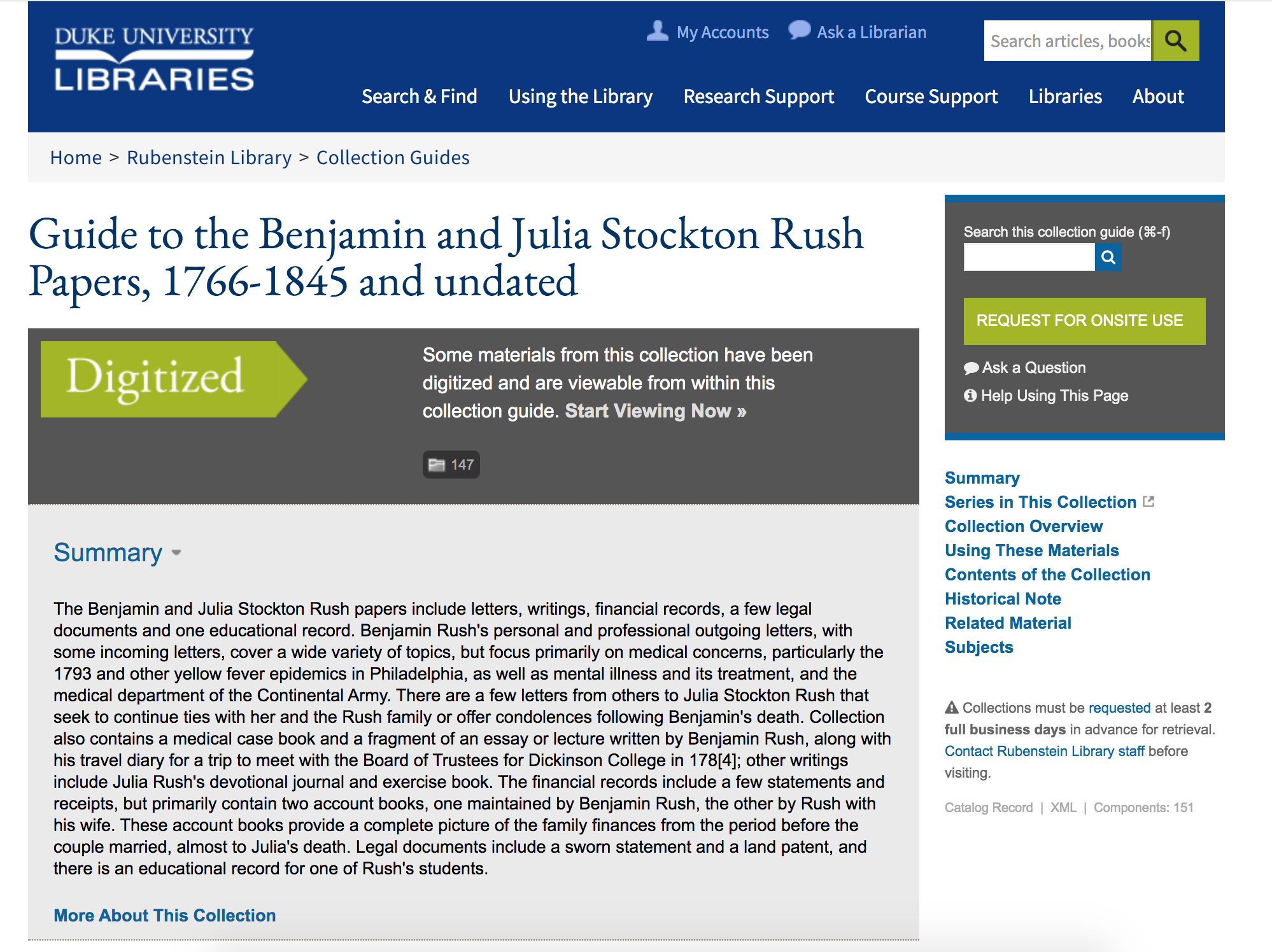
In 2020, we’ll be making significant changes to our systems supporting archival discovery and access. The main impetus for this shift is that our current platform has grown outdated and is no longer sustainable going forward. We intend to replace our platform with ArcLight, open source software backed by a community of peer institutions.
Finding Aids at Duke: Innovations Past
At Duke, we’re no strangers to pushing the boundaries of archival discovery through advances in technology. Way back in the mid 1990s, Duke was among pioneers rendering SGML-encoded finding aids into HTML. For most of the 90s and aughts we used a commercial platform, but we decided to develop our own homegrown finding aids front-end in 2007 (using the Apache Cocoon framework). We then replaced it in 2012 with another in-house platform built on the Django web framework.
Since going home-grown in 2007, we have been able to find some key opportunities to innovate within our platforms. Here are a few examples:
-
2013. Added inline digital object viewing, as part of a consortium-wide collaborative foray into large-scale manuscript digitization.
-
2014. Crosswalked metadata using Schema.org markup and used different Google APIs to power rich snippet search results (since deprecated).
-
2015. Expanded the use of <dao> tags for various types of inline digital object delivery; integrated embedded display of objects from Duke Digital Repository.
-
2016. Enhanced contextual navigation with sticky headers and series outline menus; provided component-level linkage from digital objects to their location in a finding aid. Pulled in collection abstracts from EAD to the digital collections UI.
So, Why Migrate Now?
Our current platform was pretty good for its time, but a lot has changed in eight years. The way we build web applications today is much different than it used to be. And beyond desiring a modern toolset, there are major concerns going forward around size, search/indexing, and support.
Size
We have some enormous finding aids. And we have added more big ones over the years. This causes problems of scale, particularly with an interface like ours that renders each collection as a single web page with all of the text of its contents written in the markup. One of our finding aids contains over 21,000 components; all told it is 9MB of raw EAD transformed into 15MB of HTML.
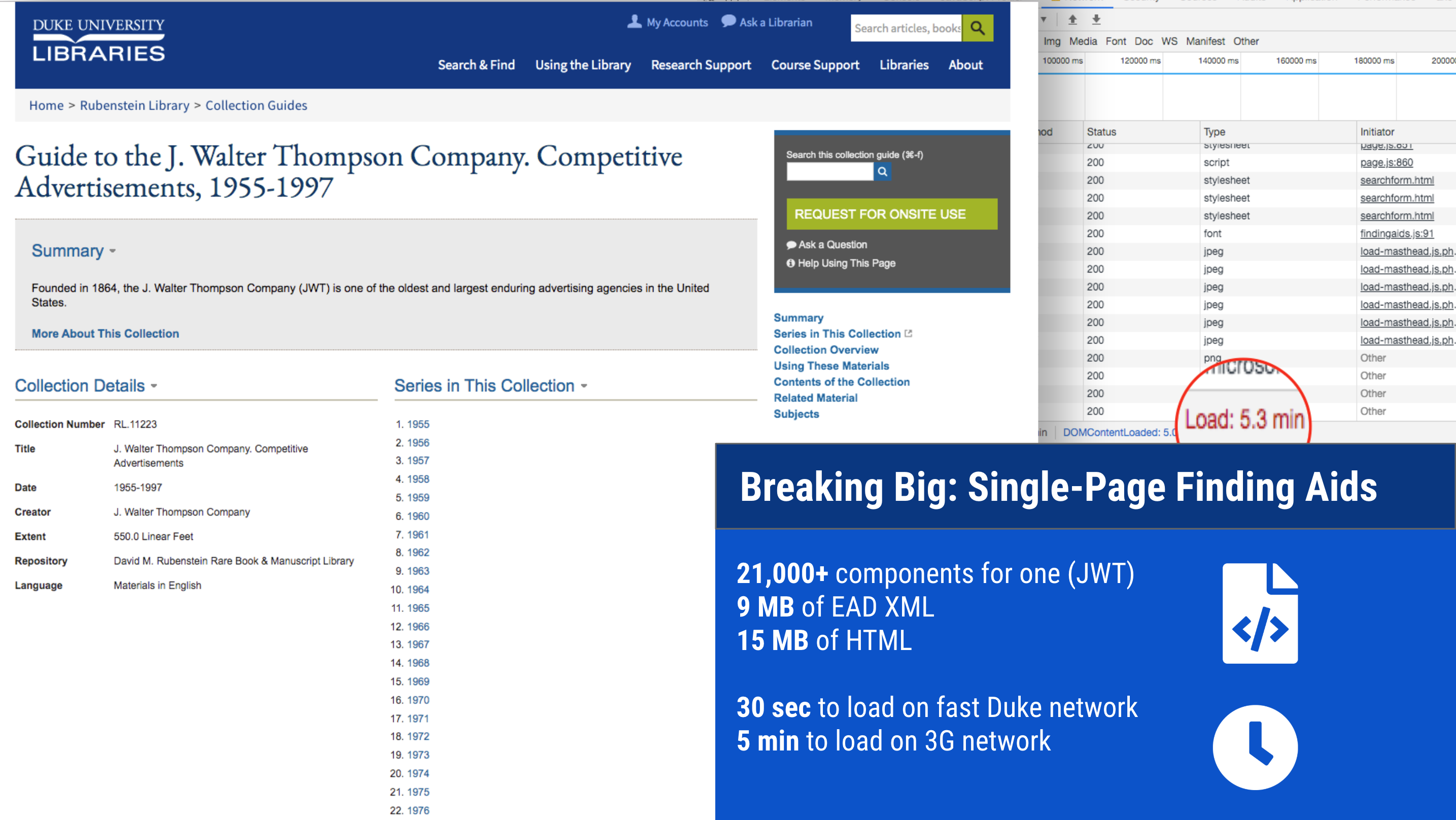
No amount of caching or server wizardry can change the fact that this is simply too much data to be delivered and rendered in a single webpage, especially for researchers in lower-bandwidth conditions. We need a solution that divides the data for any given finding aid into smaller payloads.
Search
Google Custom Search does a pretty nice job of relevance ranking and highlighting where in a finding aid a term matches (after all, that’s Google’s bread-and-butter). However, when used to power search in an application like this, it has some serious limitations. It only returns a maximum of one hundred results per query. Google doesn’t index 100% of the text, especially for our larger finding aids. And some finding aids are just mysteriously omitted despite our best efforts optimizing our markup for SEO and providing a sitemap.

We need search functionality where we have complete control of what gets indexed, when, and how. And we need assurance that the entirety of the materials described will be discoverable.
Support
This is a familiar story. Homegrown applications used for several years by organizations with a small number of developers and a large number of projects to support become difficult to sustain over time. We have only one developer remaining who can fix our finding aids platform when it breaks, or prevent it from breaking when the systems around it change. Many of the software components powering the system are at or nearing end-of-life and they can’t be easily upgraded.
Where to Go From Here?
It has been clear for awhile that we would soon need a new platform for finding aids, but not as clear what platform we should pursue. We had been eyeing the progress of two promising open source community-built solutions emerging from our peer institutions: the ArchivesSpace Public UI (PUI), and ArcLight.
Over 2018-19, my colleague Noah Huffman and I co-led a project to install pilot instances of the ASpace PUI and ArcLight, index all of our finding aids in them, and then evaluate the platforms for their suitability to meet Duke’s needs going forward. The project involved gathering feedback from Duke archivists, curators, research services staff, and our digital collections implementation team. We looked at six criteria: 1) features; 2) ease of migration/customization; 3) integration with other systems; 4) data cleanup considerations; 5) impact on existing workflows; 6) sustainability/maintenance.
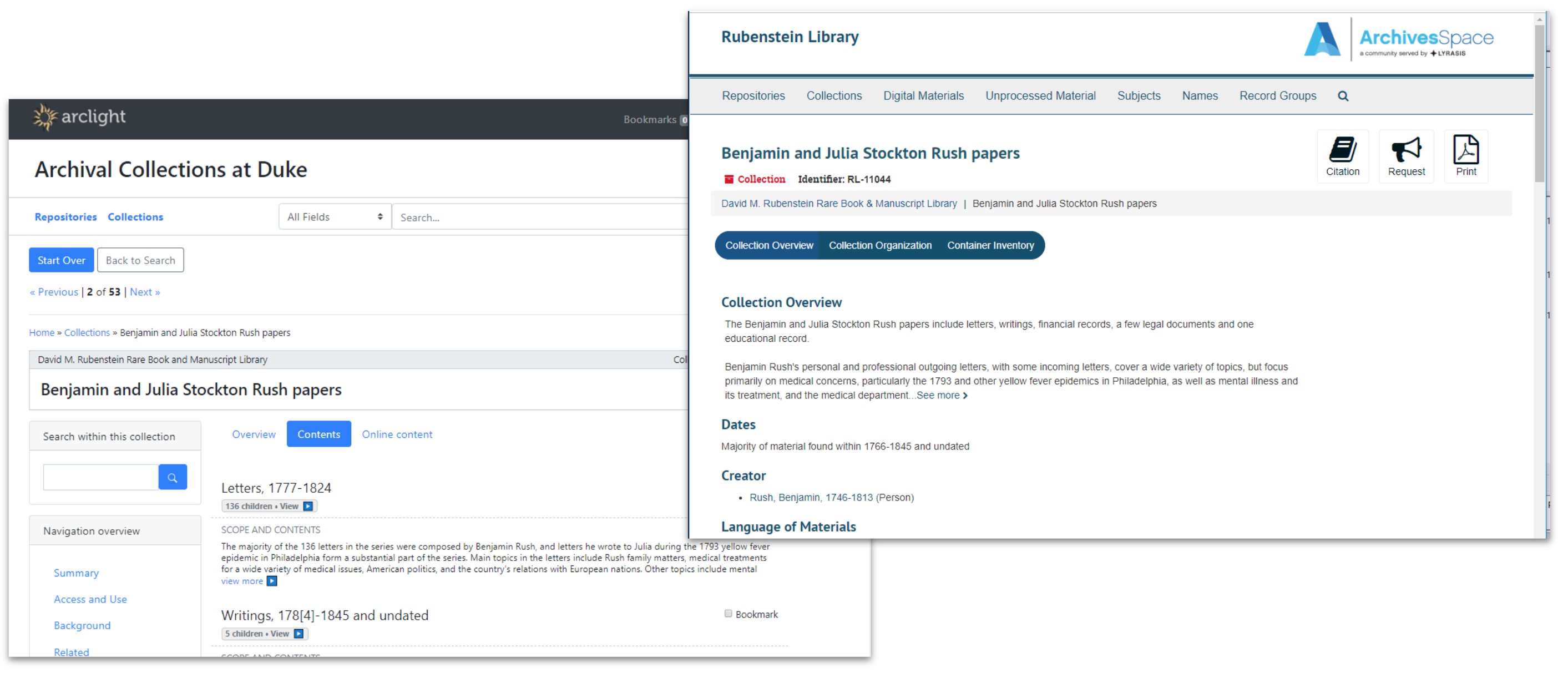
There’s a lot to like about both the ASpace PUI and ArcLight. Feature-wise, they’re fairly comparable. Both are backed by a community of talented, respected peers, and either would be a suitable foundation for a usable, accessible interface to archives. In the end, we recommended that Duke pursue ArcLight, in large part due to its similarity to so much of the other software in our IT portfolio.
ArcLight is an extension to Blacklight, which is the key software component powering our library catalog, our Digital Collections / Digital Repository, and our Hyrax-based Research Data Repository. Our developers and operations staff have accumulated considerable experience working together to build, customize, and maintain Blacklight applications.
ArcLight Community Work Cycle: Fall 2019
Duke is certainly not alone in our desire to replace an outdated, unsustainable homegrown finding aids platform, and intention to use ArcLight as a replacement.
This fall, with tremendous leadership from Stanford University Libraries, five universities collaborated on developing the ArcLight software further to address shared needs. Over a nine week work cycle from August to October, we had the good fortune of working alongside Stanford, Princeton, Michigan, and Indiana. The team addressed needs on several fronts, especially: usability, accessibility, indexing, context/navigation, and integrations.

Three Duke staff members participated: I was a member of the Development Team, Noah Huffman a member of the Product Owners Team, and Will Sexton on the Steering Group.
The work cycle is complete and you can try out the current state of the core ArcLight demo application. It includes several finding aids from each of the participating partner institutions. Here are just a few highlights that have us excited about bringing ArcLight to Duke:
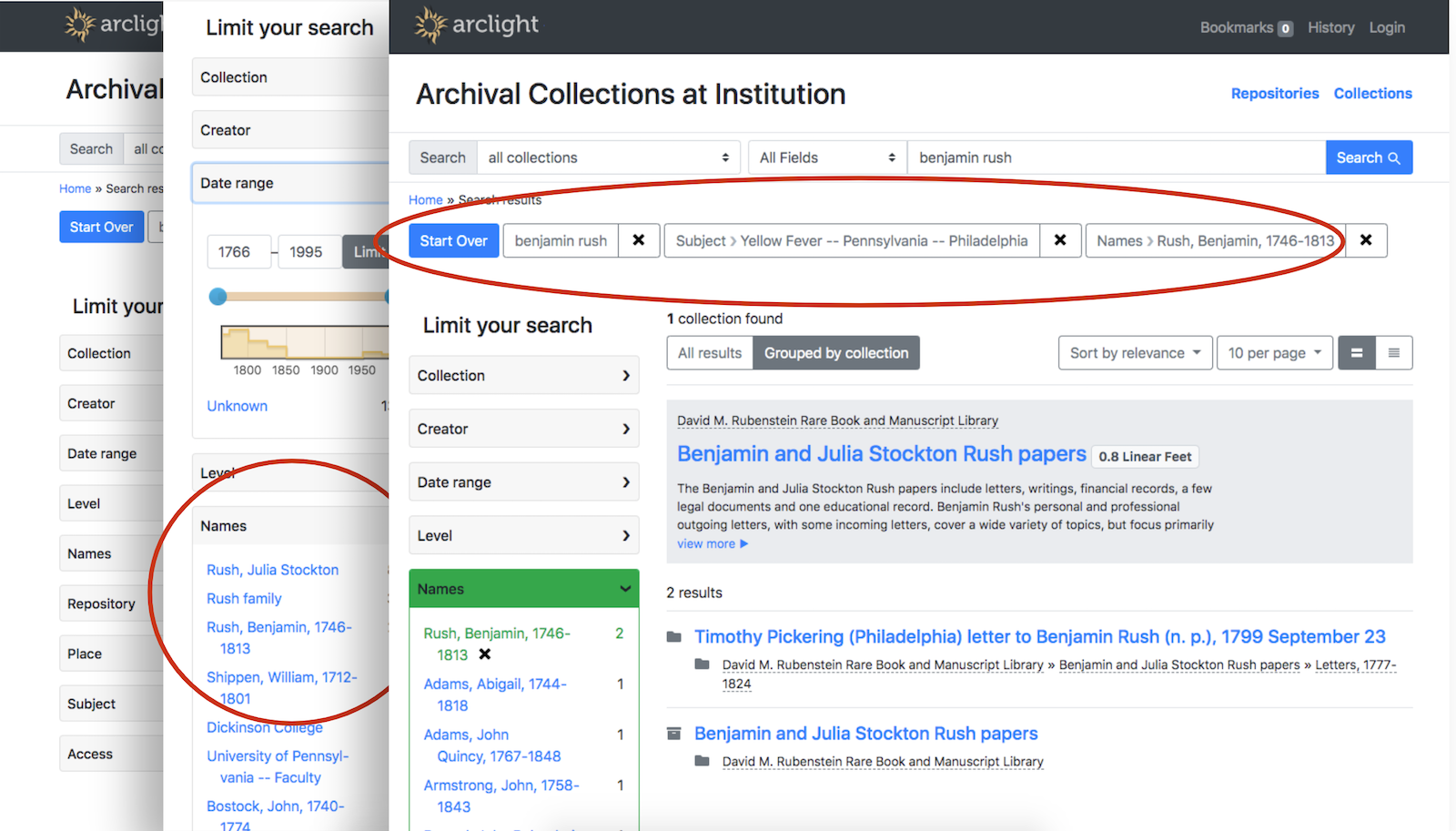
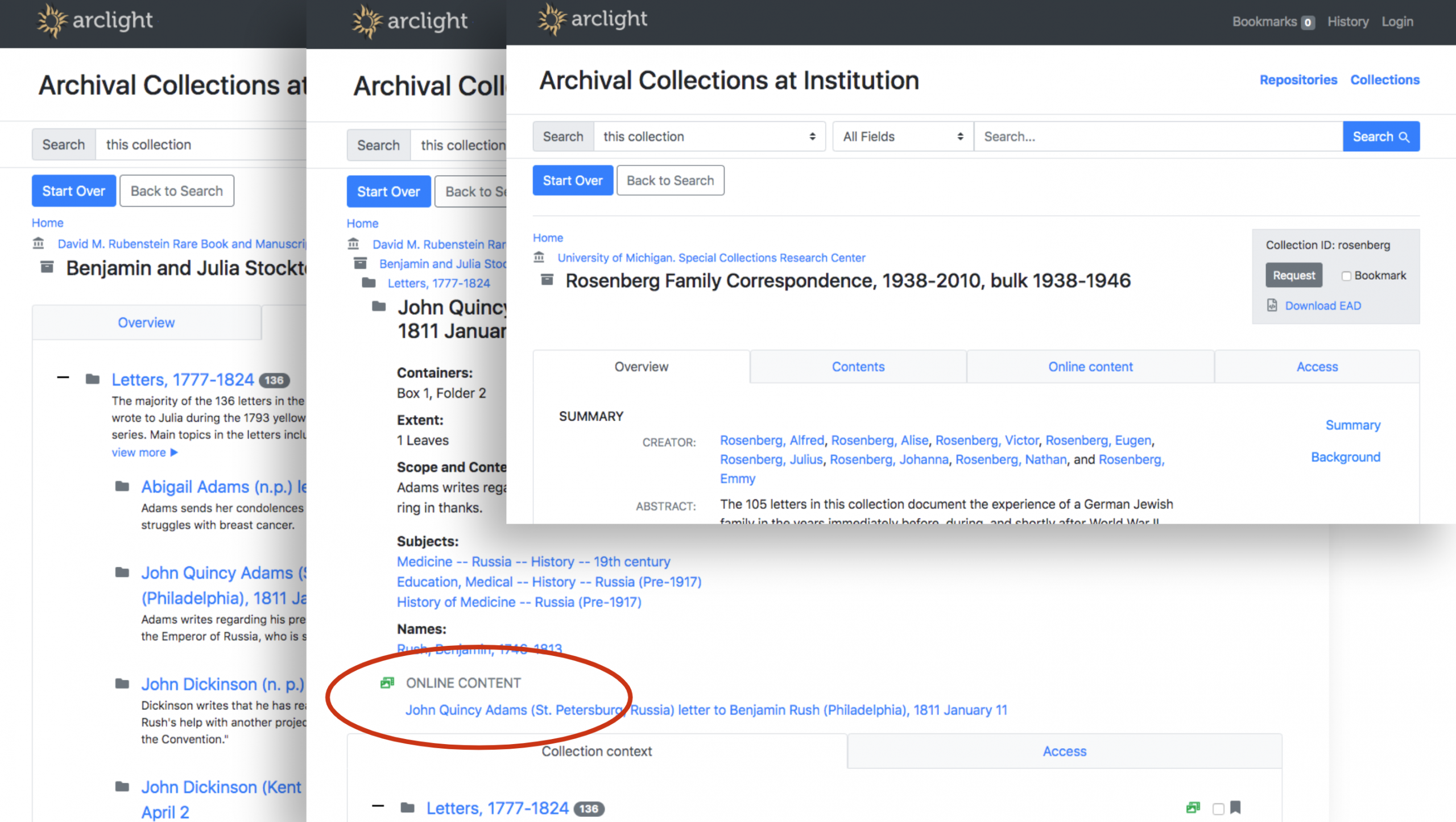
Here’s a final demo video (37 min) that nicely summarizes the work completed in the fall 2019 work cycle.
Lighting the Way
 With some serious momentum from the fall ArcLight work cycle and plans taking shape to implement the software in 2020, the Duke Libraries intend to participate in the Stanford-led, IMLS grant-funded Lighting the Way project, a platform-agnostic National Forum on Archival Discovery and Delivery. Per the project website:
With some serious momentum from the fall ArcLight work cycle and plans taking shape to implement the software in 2020, the Duke Libraries intend to participate in the Stanford-led, IMLS grant-funded Lighting the Way project, a platform-agnostic National Forum on Archival Discovery and Delivery. Per the project website:
Lighting the Way is a year-long project led by Stanford University Libraries running from September 2019-August 2020 focused on convening a series of meetings focused on improving discovery and delivery for archives and special collections.
Coming in 2020: ArcLight Implementation at Duke
There’ll be much more share about this in the new year, but we are gearing up now for a 2020 ArcLight launch at Duke. As good as the platform is now out-of-the-box, we’ll have to do additional development to address some local needs, including:
- Duke branding
- An efficient preview/publication workflow
- Digital object viewing / repository integration
- Sitemap generation
- Some data cleanup
Building these local customizations will be time well-spent. We’ll also look for more opportunities to collaborate with peers and contribute code back to the community. The future looks bright for Duke with ArcLight lighting the way.