
On January 20, 2020, we kicked off our first development sprint for implementing ArcLight at Duke as our new finding aids / collection guides platform. We thought our project charter was solid: thorough, well-vetted, with a reasonable set of goals. In the plan was a roadmap identifying a July 1, 2020 launch date and a list of nineteen high-level requirements. There was nary a hint of an impending global pandemic that could upend absolutely everything.
The work wasn’t supposed to look like this, carried out by zooming virtually into each other’s living rooms every day. Code sessions and meetings now require navigating around child supervision shifts and schooling-from-home responsibilities. Our new young office-mates occasionally dance into view or within earshot during our calls. Still, we acknowledge and are grateful for the privilege afforded by this profession to continue to do our work remotely from safe distance.
So, a major shoutout is due to my colleagues in the trenches of this work overcoming the new unforeseen constraints around it, especially Noah Huffman, David Chandek-Stark, and Michael Daul. Our progress to date has only been possible through resilience, collaboration, and willingness to keep pushing ahead together.
Three months after we started the project, we remain on track for a summer 2020 launch.
As a reminder, we began with the core open-source ArcLight platform (demo available) and have been building extensions and modifications in our local application in order to accommodate Duke needs and preferences. With the caveat that there’ll be more changes coming over the next couple months before launch, I want to provide a summary of what we have been able to accomplish so far and some issues we have encountered along the way. Duke staff may access our demo app (IP-restricted) for an up-to-date look at our work in progress.
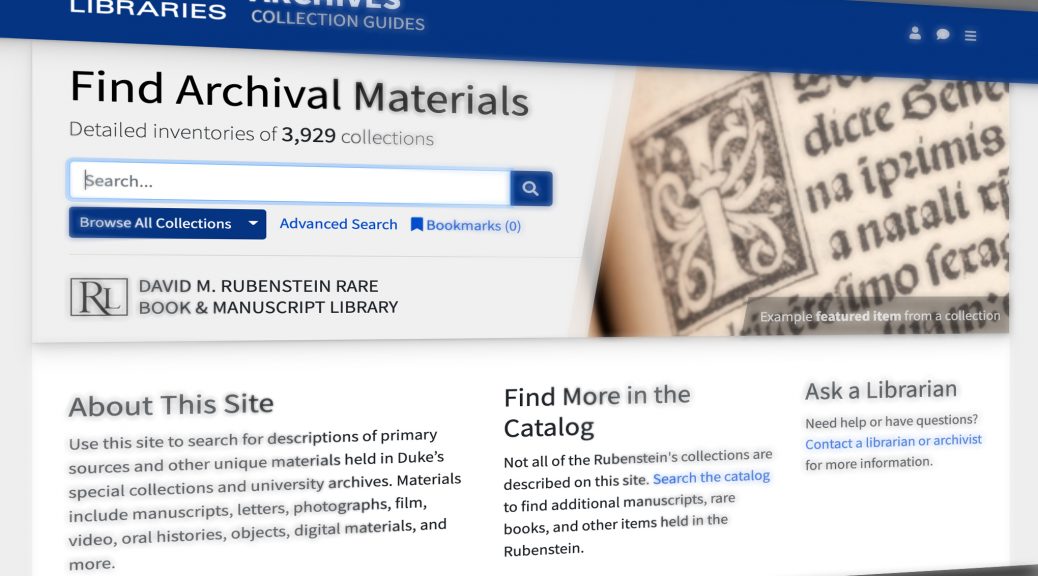
Homepage

- Duke Branding. Aimed to make an inviting front door to the finding aids consistent with other modern Duke interfaces, similar to–yet distinguished enough from–other resources like the catalog, digital collections, or Rubenstein Library website.
- Featured Items. Built a configurable set of featured items from the collections (with captions), to be displayed randomly (actual selections still in progress).
- Dynamic Content. Provided a live count of collections; we might add more indicators for types/counts of materials represented.
Layout
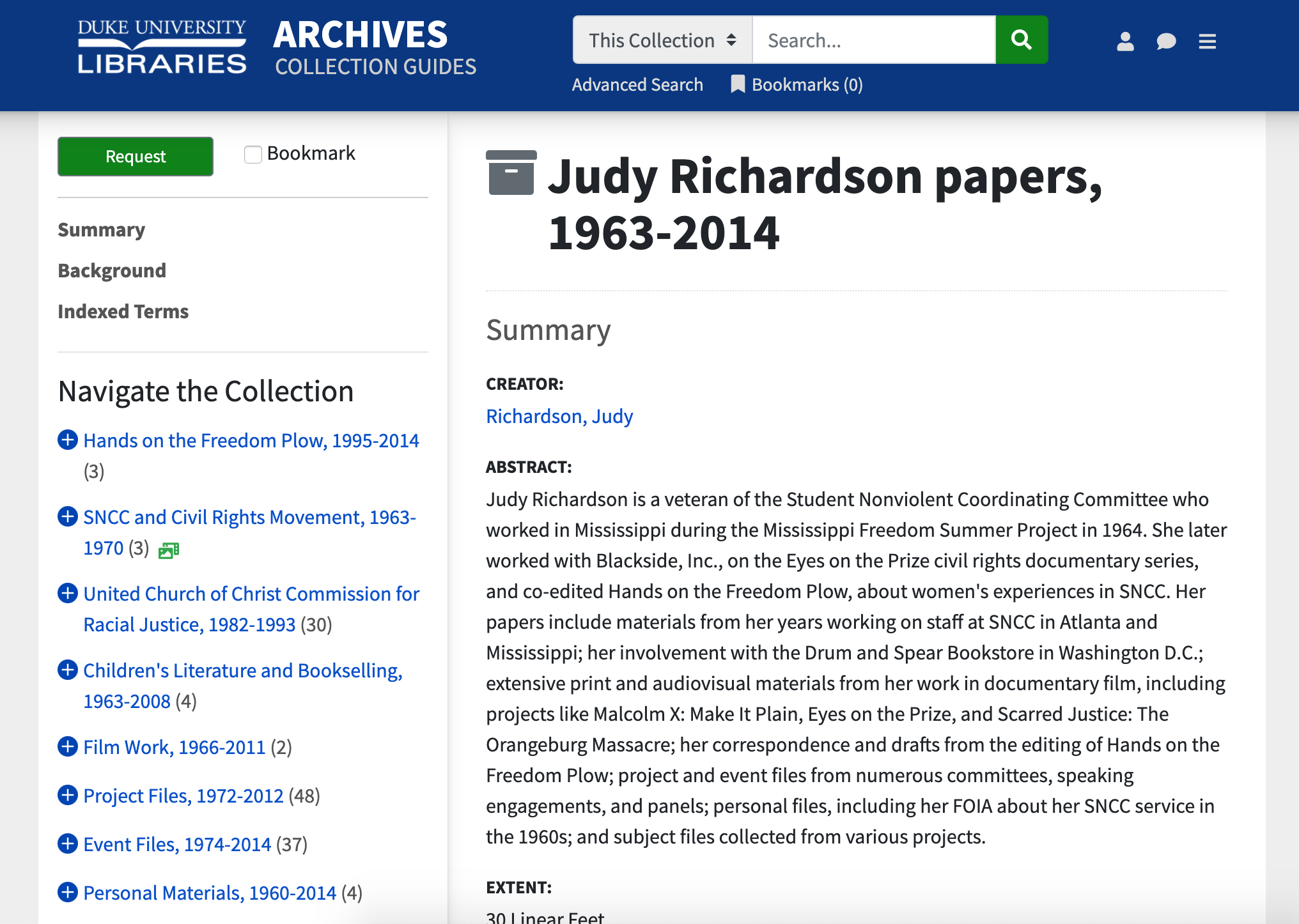
- Sidebar. Replaced the single-column tabbed layout with a sidebar + main content area.
- Persistent Collection Info. Made collection & component views more consistent; kept collection links (Summary, Background, etc.) visible/available from component pages.
- Width. Widened the largest breakpoint. We wanted to make full use of the screen real estate, especially to make room for potentially lengthy sidebar text.
Navigation

- Hierarchical Navigation. Restyled & moved the hierarchical tree navigation into the sidebar. This worked well functionally in ArcLight core, but we felt it would be more effective as a navigational aid when presented beside rather than below the content.
- Tooltips & Popovers. Provided some additional context on mouseovers for some navigational elements.
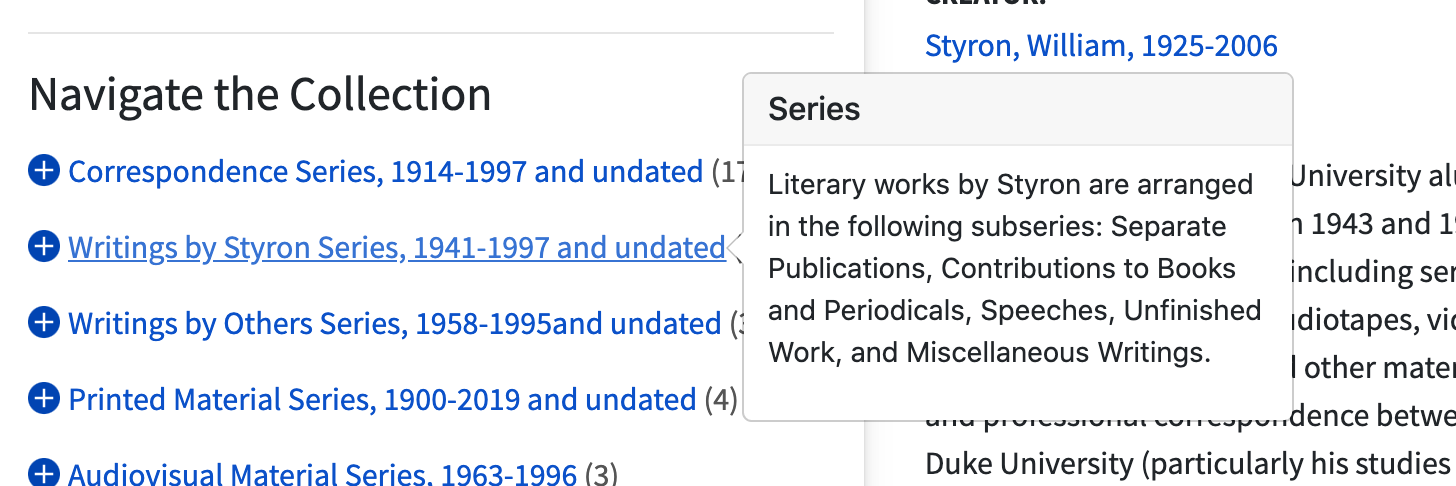
Mouseover context in navigation. - List Child Components. Added a direct-child list in the main content for any series or other component. This makes for a clear navigable table of what’s in the current series / folder / etc. Paginating it helps with performance in cases where we might have 1,000+ sibling components to load.
- Breadcrumb Refactor. Emphasized the collection title. Kept some indentation, but aimed for page alignment/legibility plus a balance of emphasis between current component title and collection title.

Breadcrumb trail to show the current component’s nesting.
Search Results

- “Group by Collection” as the default. Our stakeholders were confused by atomized components as search results outside of the context of their collections, so we tried to emphasize that context in the default search.
- Revised search result display. Added keyword highlighting within result titles in Grouped or All view. Made Grouped results display checkboxes for bookmarking & digitized content indicators.
- Advanced Search. Kept the global search box simple but added a modal Advanced search option that adds fielded search and some additional filters.
Digital Objects Integration
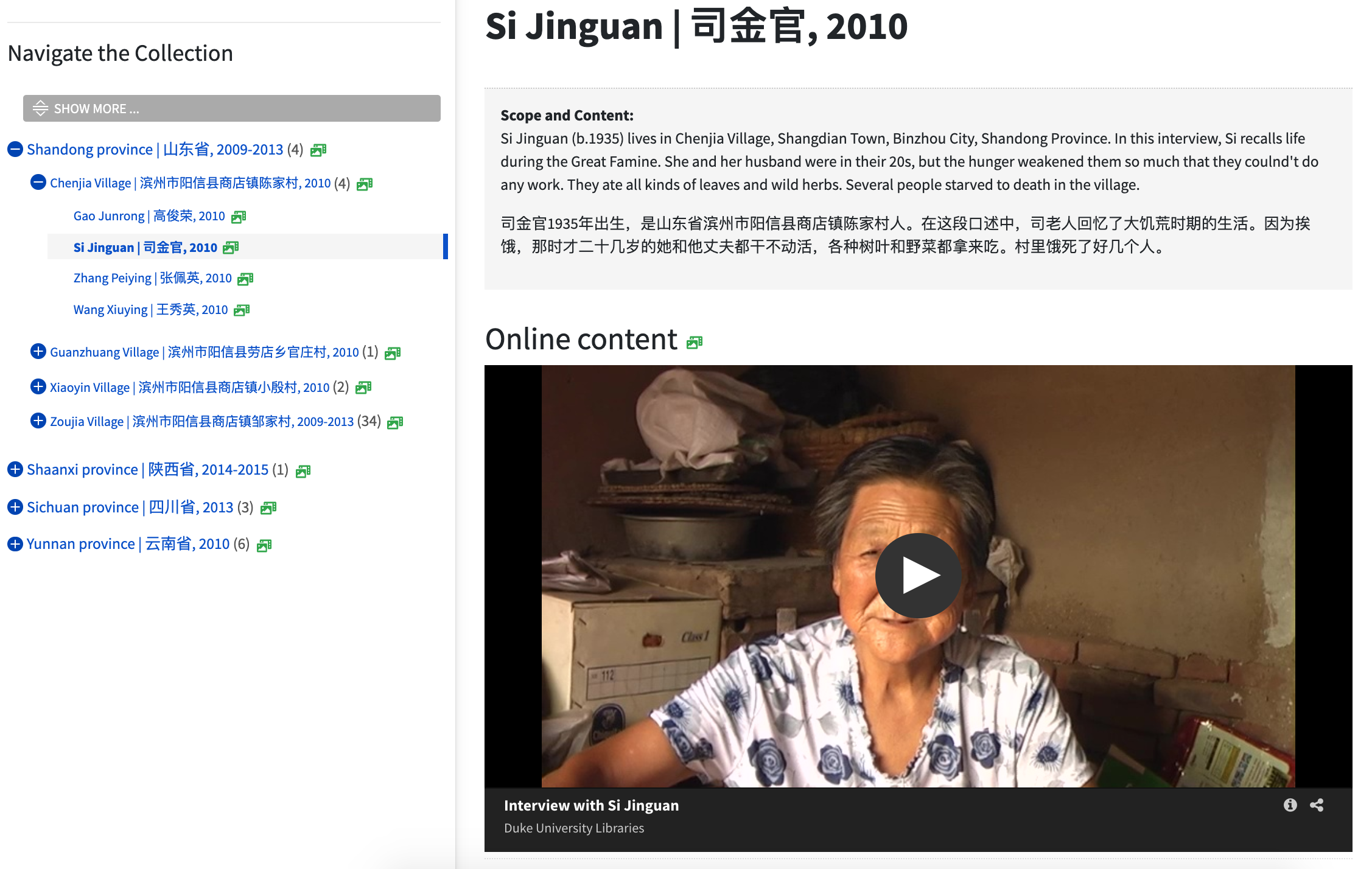
- DAO Roles. Indexed the @role attribute for
<dao>elements; we used that to call templates for different kinds of digital content - Embedded Object Viewers. Used the Duke Digital Repository’s embed feature, which renders
<iframe>s for images and AV.
Indexing
- Whitespace compression. Added a step to the pipeline to remove extra whitespace before indexing. This seems to have slightly accelerated our time-to-index rather than slow it down.
- More text, fewer strings. We encountered cases where note-like fields indexed as strings by ArcLight core (e.g.,
<scopecontent>) needed to be converted to text because we had more than 32,766 bytes of data (limit for strings) to put in them. In those cases, finding aids were failing to index. - Underscores. For the IDs that end up in a URL for a component, we added an underscore between the finding aid slug and the component ID. We felt these URLs would look cleaner and be better for SEO (our slugs often contain names).
- Dates. Changed the date normalization rules (some dates were being omitted from indexing/display)
- Bibliographic ID. We succeeded in indexing our bibliographic IDs from our EADs to power a collection-level Request button that leads a user to our homegrown requests system.
Formatting
- EAD -> HTML. We extended the EAD-to-HTML transformation rules for formatted elements to cover more cases (e.g., links like
<extptr>&<extref>or other elements like<archref>&<indexentry>)
Additional formatting and link render rules applied. - Formatting in Titles. We preserved bold or italic formatting in component titles.
ArcLight Core Contributions
- We have been able to contribute some of our code back to the ArcLight core project to help out other adopters.
Setting the Stage
The behind-the-scenes foundational work deserves mention here — it represents some of the most complex and challenging aspects of the project. It makes the application development driving the changes I’ve shared above possible.
- Built separate code repositories for our Duke ArcLight application and our EAD data
- Gathered a diverse set of 40 representative sample EADs for testing
- Dockerized our Duke ArcLight app to simplify developer environment setup
- Provisioned a development/demo server for sharing progress with stakeholders
- Automated continuous integration and deployment to servers using GitLabCI
- Performed targeted data cleanup
- Successfully got all 4,000 of our finding aids indexed in Solr on our demo server
Our team has accomplished a lot in three months, in large part due to the solid foundation the ArcLight core software provides. We’re benefiting from some amazing work done by many, many developers who have contributed their expertise and their code to the Blacklight and ArcLight codebases over the years. It has been a real pleasure to be able to build upon an open source engine– a notable contrast to our previous practice of developing everything in-house for finding aids discovery and access.
Still, much remains to be addressed before we can launch this summer.
The Road Ahead
Here’s a list of big things we still plan to tackle by July (other minor revisions/bugfixes will continue as well)…
- ASpace -> ArcLight. We need a smoother publication pipeline to regularly get data from ArchivesSpace indexed into ArcLight.
- Access & Use Statements. We need to revise the existing inheritance rules and make sure these statements are presented clearly. It’s especially important when materials are indeed restricted.
- Relevance Ranking. We know we need to improve the ranking algorithm to ensure the most relevant results for a query appear first.
- Analytics. We’ll set up some anonymized tracking to help monitor usage patterns and guide future design decisions.
- Sitemap/SEO. It remains important that Google and other crawlers index the finding aids so they are discoverable via the open web.
- Accessibility Testing / Optimization. We aim to comply with WCAG2.0 AA guidelines.
- Single-Page View. Many of our stakeholders are accustomed to a single-page view of finding aids. There’s no such functionality baked into ArcLight, as its component-by-component views prioritize performance. We might end up providing a downloadable PDF document to meet this need.
- More Data Cleanup. ArcLight’s feature set (especially around search/browse) reveals more places where we have suboptimal or inconsistent data lurking in our EADs.
- More Community Contributions. We plan to submit more of our enhancements and bugfixes for consideration to be merged into the core ArcLight software.
If you’re a member of the Duke community, we encourage you to explore our demo and provide feedback. To our fellow future ArcLight adopters, we would love to hear how your implementations or plans are shaping up, and identify any ways we might work together toward common goals.
Stay safe, everyone!
This looks really fantastic! Great work.
Thank you, Lea Ann–much appreciated!
Having read this I thought it was extremely informative. I appreciate you spending some time and effort to put this informative article together. I once again find myself personally spending way too much time both reading and posting comments. But so what, it was still worth it!
It does look REALLY great. Any chance that you will be sharing your code with the community?
Thank you, Brian! Our code is available here:
https://gitlab.oit.duke.edu/dul-its/dul-arclight
I think it remains to be seen which of our customizations would be desired and appropriate for porting upstream to the core application. In a few weeks we’ll be able to share public links to our application in production and that may help gauge interest.