
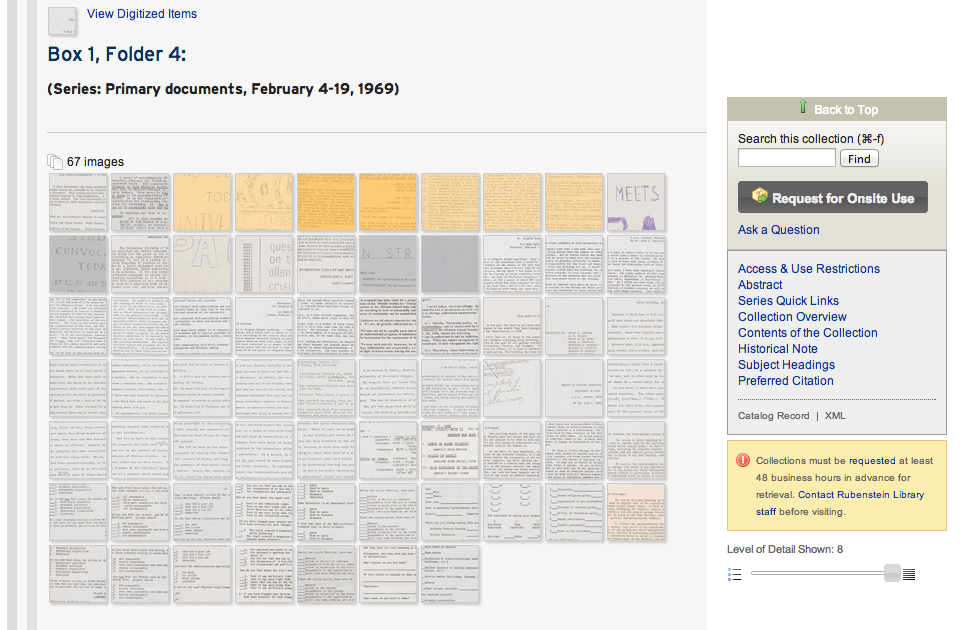
Back in February 2014, we wrapped up the CCC project, a collaborative three year IMLS-funded digitization initiative with our partners in the Triangle Research Libraries Network (TRLN). The full title of the project is a mouthful, but it captures its essence: “Content, Context, and Capacity: A Collaborative Large-Scale Digitization Project on the Long Civil Rights Movement in North Carolina.”
Together, the four university libraries (Duke, NC State, UNC-Chapel Hill, NC Central) digitized over 360,000 documents from thirty-eight collections of manuscripts relevant to the project theme. About 66,000 were from our David M. Rubenstein Rare Book & Manuscript Library collections.
Large-Scale
So how large is “large-scale”? By comparison, when the project kicked off in summer 2011, we had a grand total of 57,000 digitized objects available online (“published”), collectively accumulated through sixteen years of digitization projects. That number was 69,000 by the time we began publishing CCC manuscripts in June 2012. Putting just as many documents online in three years as we’d been able to do in the previous sixteen naturally requires a much different approach to creating digital collections.
| Traditional Digitization | Large-Scale Digitization |
|---|---|
| Individual items identified during scanning | No item-level identification: entire folders scanned |
| Descriptive metadata applied to each item | Archival description only (e.g., at the folder level) |
| Robust portals for search & browse | Finding aid / collection guide as access point |
There are some considerable tradeoffs between document availability vs. discovery and access features, but going at this scale speeds publication considerably. Large-scale digitization was new for all four partners, so we benefited by working together.

Project Evaluation
CCC staff completed qualitative and quantitative evaluations of this large-scale digitization approach during the course of the project, ranging from conducting user focus groups and surveys to analyzing the impact on materials prep time and image quality control. Researcher assessments targeted three distinct user groups: 1) Faculty & History Scholars; 2) Undergraduate Students (in research courses at UNC & NC State); 3) NC Secondary Educators.
Here are some of the more interesting findings (consult the full reports for details):
- Ease of Use. Faculty and scholars, for the most part, found it easy to use digitized content presented this way. Undergraduates were more ambivalent, and secondary educators had the most difficulty.
- To Embed or Not to Embed. In 2012, Duke was the only library presenting the image thumbnails embedded directly within finding aids and a lightbox-style image navigator. Undergrads who used Duke’s interface found it easier to use than UNC or NC Central’s, and Duke’s collections had a higher rate of images viewed per folder than the other partners. UNC & NC Central’s interfaces now use a similar convention.
- Potential for Use. Most users surveyed said they could indeed imagine themselves using digitized collections presented in this way in the course of their research. However, the approach falls short in meeting key needs for secondary educators’ use of primary sources in their classes.
- Desired Enhancements. The top two most desired features by faculty/scholars and undergrads alike were 1) the ability to search the text of the documents (OCR), and 2) the ability to explore by topic, date, document type (i.e., things enabled by item-level metadata). PDF download was also a popular pick.
Impact on Duke Digitization Projects
Since the moment we began putting our CCC manuscripts online (June 2012), we’ve completed the eight CCC collections using this large-scale strategy, and an additional eight manuscript collections outside of CCC using the same approach. We have now cumulatively put more digital objects online using the large-scale method (96,000) than we have via traditional means (75,000). But in that time, we have also completed eleven digitization projects with traditional item-level identification and description.
We see the large-scale model for digitization as complementary to our existing practices: a technique we can use to meet the publication needs of some projects.
Usage
Do people actually use the collections when presented in this way? Some interesting figures:
- Views / item in 2013-14 (traditional digital object; item-level description): 13.2
- Views / item in 2013-14 (digitized image within finding aid; folder-level description): 1.0
- Views / folder in 2013-14 (digitized folder view in finding aid): 8.5
It’s hard to attribute the usage disparity entirely to the publication method (they’re different collections, for one). But it’s reasonable to deduce (and unsurprising) that bypassing item-level description generally results in less traffic per item.
On the other hand, one of our CCC collections (The Allen Building Takeover Collection) has indeed seen heavy use–so much, in fact, that nearly 90% of TRLN’s CCC items viewed in the final six months of the project were from Duke. Its images averaged over 78 views apiece in the past year; its eighteen folders opened 363 times apiece. Why? The publication of this collection coincided with an on-campus exhibit. And it was incorporated into multiple courses at Duke for assignments to write using primary sources.
The takeaway is, sometimes having interesting, important, and timely content available for use online is more important than the features enabled or the process by which it all gets there.
Looking Ahead
We’ll keep pushing ahead with evolving our practices for putting digitized materials online. We’ve introduced many recent enhancements, like fulltext searching, a document viewer, and embedded HTML5 video. Inspired by the CCC project, we’ll continue to enhance our finding aids to provide access to digitized objects inline for context (e.g., The Jazz Loft Project Records). Our TRLN partners have also made excellent upgrades to the interfaces to their CCC collections (e.g., at UNC, at NC State) and we plan, as usual, to learn from them as we go.