

Quick—when was the last time you went a full day without using a Google product or service? How many years ago was that day?
We all know Google has permeated so many facets of our personal and professional lives. A lot of times, using a Google something-or-other is your organization’s best option to get a job done, given your available resources. If you ever searched the Duke Libraries website at any point over the past seventeen years, you were using Google.
It’s really no secret that when you have a website with a lot of pages, you need to provide a search box so people can actually find things. Even the earliest version of the library website known to the Wayback Machine–from “way back” in 1997–had a search box. Those days, search was powered by the in-house supported Texis Webinator. Google was yet to exist.
July 24, 2004 was an eventful day for the library IT staff. We went live with a shiny new Integrated Library System from Ex Libris called Aleph (that we are still to this day working to replace). On that very same day, we launched a new library website, and in the top-right corner of the masthead on that site was–for the very first time–a Google search box.
Years went by. We redesigned the website several times. Interface trends came and went. But one thing remained constant: there was a search box on the site, and if you used it, somewhere on the next page you were going to get search results from a Google index.
That all changed in summer 2021, when we implemented Nutch…
![]()
Why Not Google?
Google Programmable Search Engine (recently rebranded from “Google Custom Search Engine”), is easy to use. It’s “free.” It’s fast, familiar, and being a Google thing, it’s unbeatable at search relevancy. So why ditch it now? Well…
- Protecting patron privacy has always been a core library value. Recent initiatives at Duke Libraries and beyond have helped us to refocus our efforts around ensuring that we meet our obligations in this area.
- Google’s service changed recently, and creating a new engine now involves some major hoop-jumping to be able to use it ad-free.
- It doesn’t work in China, where we actually have a Duke campus, and a library.
- The results are capped at 100 per query. Google prioritizes speed and page 1 relevancy, but it won’t give you a precise hit count nor an exhaustive list of results.
- It’s a black box. You don’t really get to see why pages get ranked higher or lower than others.
- There’s a search API you could potentially build around, but if you exceed 100 searches/day, you have to start paying to use it.
What’s Nutch?
Apache Nutch is open source web crawler software written in Java. It’s been around for nearly 20 years–almost as long as Google. It supports out-of-the-box integration with Apache Solr for indexing.

What’s So Good About Nutch?
- Solr. Our IT staff have grown quite accustomed to the Solr search platform over the past decade; we already support around ten different applications that use it under the hood.
- Self-Hosted. You run it yourself, so you’re in complete control of the data being crawled, collected, and indexed. User search data is not being collected by a third party like Google.
- Configurable. You have a lot of control over how it works. All our configs are in a public code repository so we have record of what we have changed and why.
What are the Drawbacks to Using Nutch?
- Maintenance. Using open source software requires a commitment of IT staff resources to build and maintain over time. It’s free, but it’s not really free.
- Interface. Nutch doesn’t come with a user interface to actually use the indexed data from the crawls; you have to build a web application. Here’s ours.
- Relevancy. Though Google considers such factors as page popularity and in-link counts to deem pages as more relevant than others for a particular query, Nutch can’t. Or, at least, its optional features that attempt to do so are flawed enough that not using them gets us better results. So we rely on other factors for our relevancy algorithm, like the segment of the site that a page resides, URL slugs, page titles, subheading text, inlink text, and more.
- Documentation. Some open source platforms have really clear, easy to understand instruction manuals online to help you understand how to use them. Nutch is not one of those platforms.
How Does Nutch Work at Duke?
The main Duke University Libraries website is hosted in Drupal, where we manage around 1,500 webpages. But the full scope of what we crawl for library website searching is more than ten times that size. This includes pages from our blogs, LibGuides, exhibits, staff directory, and more. All told: 16,000 pages of content.
Searching from the website masthead or the default “All” box in the tabbed section on our homepage brings you to QuickSearch results page.
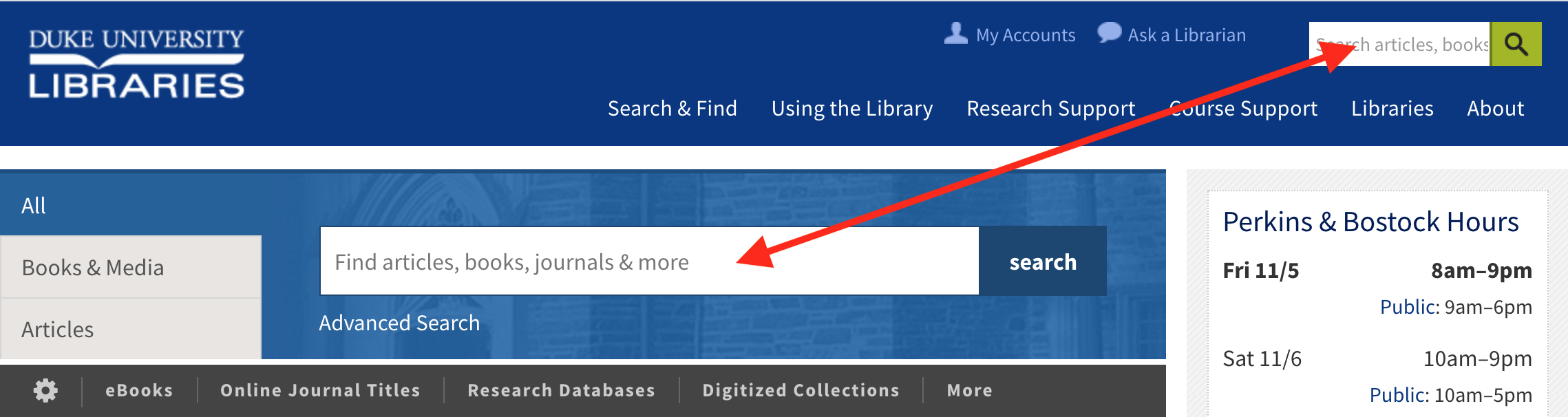
You’ll see a search results page rendered by our QuickSearch app. It includes sections of results from various places, like articles, books & media, and more. One of the sections is “Our Website” — it shows the relevant pages that we’ve crawled with Nutch.

You can just search the website specifically if you’re not interested in all those other resources.


Three pieces work in concert to enable searching the website: Nutch, Solr, and QuickSearch. Here’s what they do:
Nutch
- Crawls web pages that we want to include in the website search.
- Parses HTML content; writes it to Solr fields.
- Includes configuration for what pages to include/exclude, crawler settings, field mappings
Solr
- Index & document store for crawled website content.
QuickSearch
- Built on NC State University Libraries’ QuickSearch engine, an open source Ruby on Rails application.
- Provides the UI for searching the website content, within a Bento box or via a website-only search page.
- Hits a Solr endpoint to retrieve results.
- Includes configuration for determining relevancy; see parameters in website_searcher.rb
Crawls happen every night to pick up new pages and changes to existing ones. We use an “adaptive fetch schedule” so by default each page gets recrawled every 30 days. If a page changes frequently, it’ll get re-crawled sooner automatically.
Summary
Overall, we’re satisfied with how the switch to Nutch has been working out for us. The initial setup was challenging, but it has been running reliably without needing much in the way of developer intervention. Here’s hoping that continues!
Many thanks to Derrek Croney and Cory Lown for their help implementing Nutch at Duke, and to Kevin Beswick (NC State University Libraries) for consulting with our team.
Thank you for the information you shared. I also used Analysts and it has been very useful for SEO analysis.
Greetings! Very helpful advice on this article! It is the small changes that make the biggest difference. Thanks a lot for sharing!