This post is part of the Research Data Curation Team’s ‘Researcher Highlight’ series.
Equity in Collaboration
The landscape of research and data is enterprising, expansive and diverse. This dynamic is notably visible in the work done at Duke Global Health Institute (DGHI). Collaboration with international partners inherently comes with many challenges. In a conversation with the Duke Research Data Curation team, Sabrina McCutchan of the Research Design and Analysis Core (RDAC) at DGHI shares her thoughts on why data sharing and access is critical to global health research.
Questions of equity must be addressed when discussing research data and scholarship on a global scale. For the DGHI data equity is a priority. International research partners deserve equal access to primary data to better understand what’s happening in their communities, contribute to policy initiatives that support their populations, and support their own professional advancement by publishing in research and medical journals.
“We work with so many different countries, people groups, and populations around the world that often themselves don’t have access to the same infrastructure, technologies or training in data. It can be challenging to collect quality primary data on their own, but becomes a little easier in partnership with a big research institution like Duke.”
Collaborations like the Adolescent Mental Health in Africa Network Initiative (AMANI) demonstrate the significance of data sharing. AMANI is led by Dr. Dorothy Dow of DGHI, Dr. Lukoye Atwoli of Moi University School of Medicine, and Dr. Sylvia Kaaya of Muhimbili University of Health and Allied Sciences (MUHAS) and involves participating researchers from academic and medical institutions in South Africa, Kenya, and Tanzania.
Why Share Data?
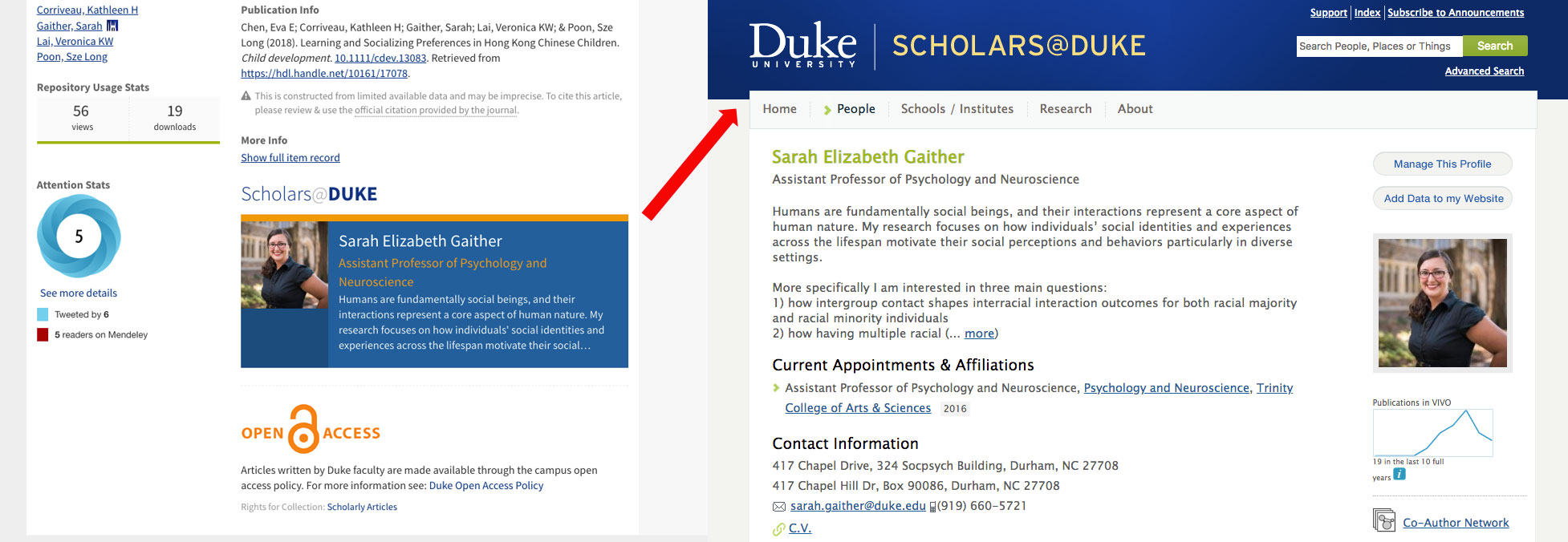
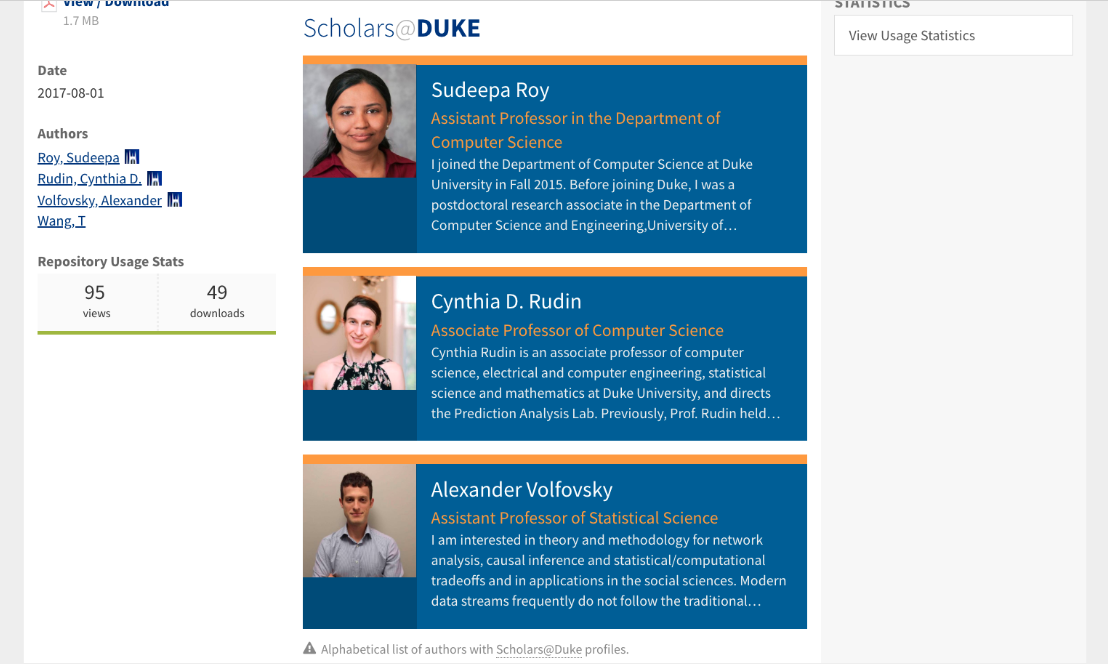
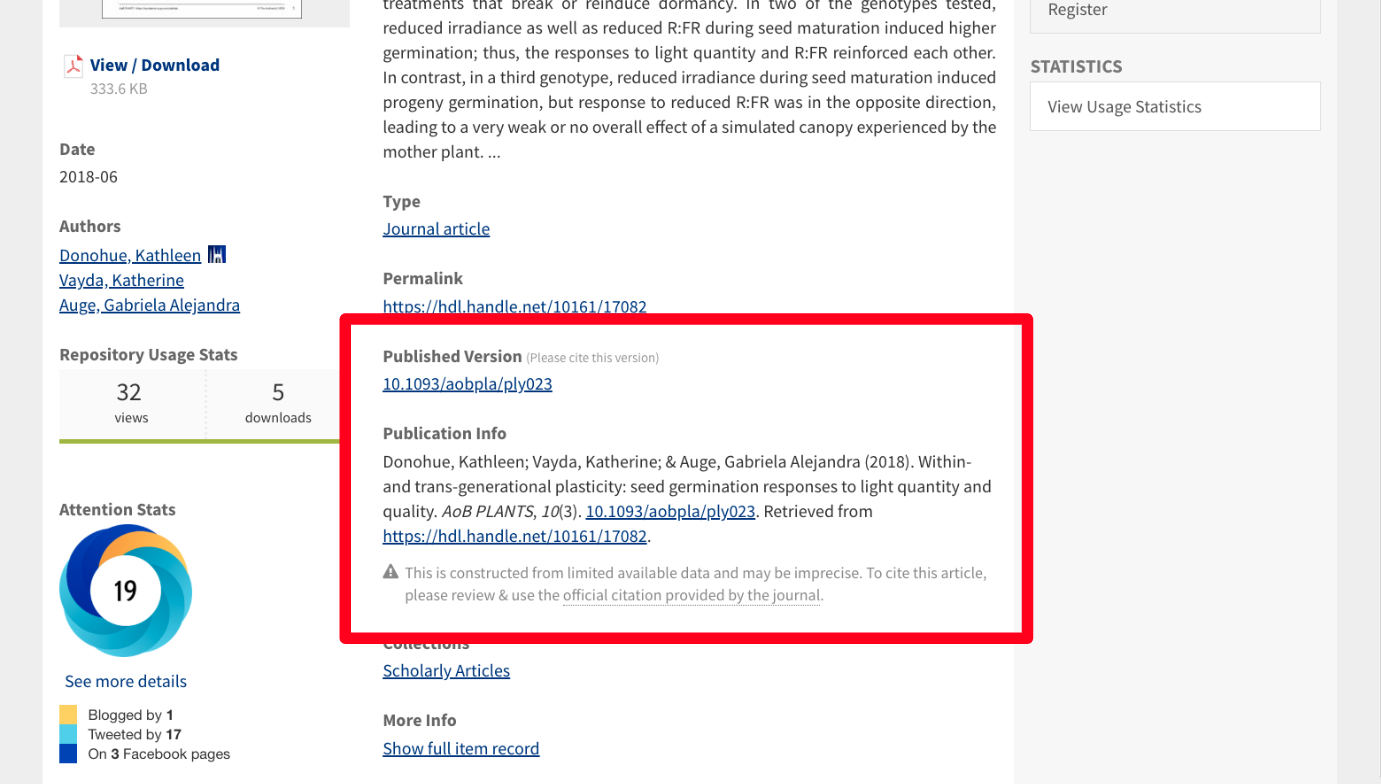
As a Data Architect, Sabrina is available to support DGHI in achieving their data sharing goals. She takes a holistic approach to identifying areas where the team needs data support. Considering at each stage of the project lifecycle how system design and data architecture will influence how data can be shared. This may entail drafting informed consent documents, developing strategies for de-identification, curating and managing data, or discovering solutions for data storage and publishing. For instance, in collaboration with CDVS Research Data Management Consultants, Sabrina has helped AMANI create a Dataverse to enable sharing restricted access health data for international junior researchers. Data from one of DGHI’s studies are also available in the Duke Research Data Repository.
“All of these components are interconnected to each other. You really need to think about what are going to be the impacts of a decision made early in the process of gathering data for this study further downstream when we’re analyzing that data and publishing findings from it.”
Reproducibility is another reason that sharing and publishing data is important to Sabrina. DGHI wants to increase data availability in accordance with FAIR principles so other researchers can independently verify, reproduce, and iterate on their work. This supports peers and contributes to the advancement of the field. Publishing data in an open repository can also increase their reach and impact. DGHI is also currently examining how to incorporate the CARE principles and other frameworks for ethical data sharing within their international collaborations.
Global collaborations in research are vital in these times. Sabrina advises that it’s important for researchers, especially Principal Investigators, to think holistically about research projects. For example, thinking about data sharing at the very beginning of the project and writing consent forms that support what they hope to do with the data. Equitable practices paired with data sharing create opportunities for greater discovery and progress in research.
![]()