
This post was written by Miriam Shams-Rainey, a third-year undergraduate at Duke studying Computer Science and Linguistics with a minor in Arabic. As a student employee in the Rubenstein’s Technical Services Department in the Summer of 2021, Miriam helped build a tool to audit archival description in the Rubenstein for potentially harmful language. In this post, she summarizes her work on that project.
The Rubenstein Library has collections ranging across centuries. Its collections are massive and often contain rare manuscripts or one of a kind data. However, with this wide-ranging history often comes language that is dated, harmful, often racist, sexist, homophobic, and/or colonialist. As important as it is to find and remediate these instances of potentially harmful language, there is lot of data that must be searched.
With over 4,000 collection guides (finding aids) and roughly 12,000 catalog records describing archival collections, archivists would need to spend months of time combing their metadata to find harmful or problematic language before even starting to find ways to handle this language. That is, unless there was a way to optimize this workflow.
Working under Noah Huffman’s direction and the imperatives of the Duke Libraries’ Anti-Racist Roadmap, I developed a Python program capable of finding occurrences of potentially harmful language in library metadata and recording them for manual analysis and remediation. What would have taken months of work can now be done in a few button clicks and ten minutes of processing time. Moreover, the tools I have developed are accessible to any interested parties via a GitHub repository to modify or expand upon.
Although these gains in speed push metadata language remediation efforts at the Rubenstein forward significantly, a computer can only take this process so far; once uses of this language have been identified, the responsibility of determining the impact of the term in context falls onto archivists and the communities their work represents. To this end, I have also outlined categories of harmful language occurrences to act as a starting point for archivists to better understand the harmful narratives their data uphold and developed best practices to dismantle them.
Building an automated audit tool
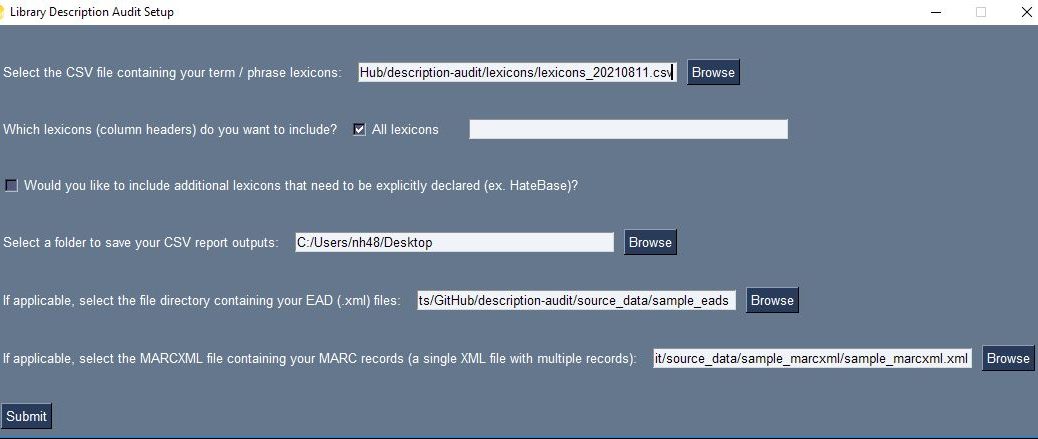
I created an executable that allows users to interact with the program regardless of their familiarity with Python or with using their computer’s command line. With an executable, all that a user must do is simply click on the program (titled “description_audit.exe”) and the script will load with all of its dependencies in a self-contained environment. There’s nothing that a user needs to install, not even Python.
Within this executable, I also created a user interface to allow users to set up the program with their specific audit parameters. To use this program, users should first create a CSV file (spreadsheet) containing each list of words they want to look for in their metadata.
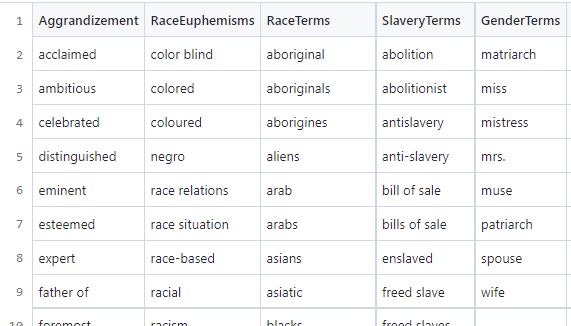
In this CSV file of “lexicons”, each category of terms should have its own column, for example RaceTerms could be the first row in a column of terms such as “colored” or “negro,” and GenderTerms could be the first row in a column of gendered terms such as “homemaker” or “wife.” See these lexicon CSV file examples.
Once this CSV has been created, users can select this CSV of lexicons in the program’s user interface and then select which columns of terms they want the program to use when searching across the source metadata. Users can either use all lexicon categories (all columns) by default or specify a subset by typing out those column headers. For the Rubenstein’s purposes, there is also a rather long lexicon called HateBase (from a regional, multilingual database of potential hate speech terms often used in online moderating) that is only enabled when a checkbox is checked; users from other institutions can download the HateBase lexicon for themselves and use it or they can simply ignore it.
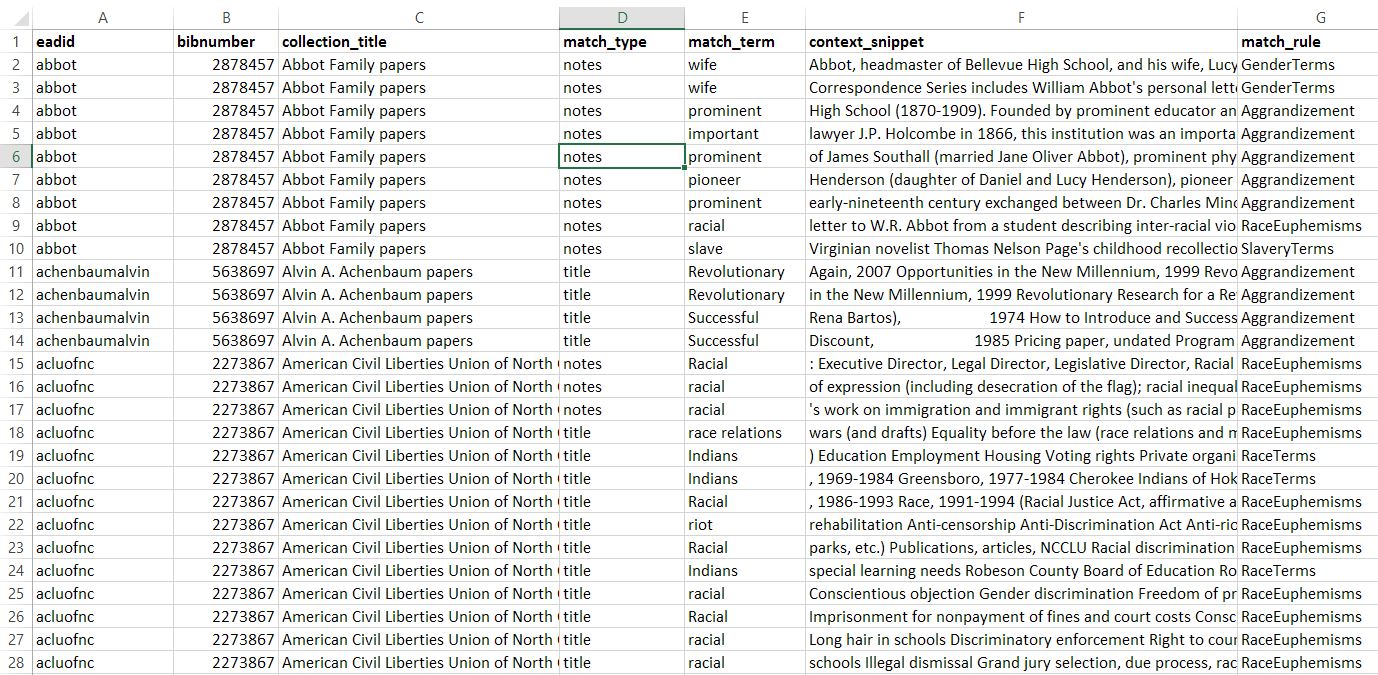
In the CSV reports that are output by the program, matches for harmful terms and phrases will be tagged with the specific lexicon category the match came from, allowing users to filter results to certain categories of potentially harmful terms.
Users also need to designate a folder on their desktop where report outputs should be stored, along with the folder containing their source EAD records in .xml format and their source MARCXML file containing all of the MARC records they wish to process as a single XML file. Results from MARC and EAD records are reported separately, so only one type of record is required to use the program, however both can be provided in the same session.
How archival metadata is parsed and analyzed
Once users submit their input parameters in the GUI, the program begins by accessing the specified lexicons from the given CSV file. For each lexicon, a “rule” is created for a SpaCy rule-based matcher, using the column name (e.g. RaceTerms or GenderTerms) as the name of the specific rule. The same SpaCy matcher object identifies matches to each of the several lexicons or “rules”. Once the matcher has been configured, the program assesses whether valid MARC or EAD records were given and starts reading in their data.
To access important pieces of data from each of these records, I used a Python library called BeautifulSoup to parse the XML files. For each individual record, the program parses the call numbers and collection or entry name so that information can be included in the CSV reports. For EAD records, the collection title and component titles are also parsed to be analyzed for matches to the lexicons, along with any data that is in a paragraph (<p>) tag. For MARC records, the program also parses the author or creator of the item, the extent of the collection, and the timestamp of when the description of the item was last updated. In each MARC record, the 520 field (summary) and 545 field (biography/history note) are all concatenated together and analyzed as a single entity.
Data from each record is stored in a Python dictionary with the names of fields (as strings) as keys mapping to the collection title, call number, etc. Each of these dictionaries is stored in a list, with a separate structure for EAD and MARC records.
Once data has been parsed and stored, each record is checked for matches to the given lexicons using the SpaCy rule-based matcher. For each record, any matches that are found are then stored in the dictionary with the matching term, the context of the term (the entire field or surrounding few sentences, depending on length), and the rule the term matches (such as RaceTerms). These matches are found using simple tokenization from SpaCy that allow matches to be identified quickly and without regard for punctuation, capitalization, etc.
Although this process doesn’t necessarily use the cutting-edge of natural language processing that the SpaCy library makes accessible, this process is adaptable in ways that matching procedures like using regular expressions often isn’t. Moreover, identifying and remedying harmful language is a fundamentally human process which, at the end of the day, needs a significant level of input both from historically marginalized communities and from archivists.
Matches to any of the lexicons, along with all other associated data (the record’s call number, title, etc.) are then written into CSV files for further analysis and further categorization by users. You can see sample CSV audit reports here. The second phase of manual categorization is still a lengthy process, yielding roughly 14600 matches from the Rubenstein Library’s EAD data and 4600 from its MARC data which must still be read through and analyzed by hand, but the process of identifying these matches has been computerized to take a mere ten minutes, where it could otherwise be a months-long process.
Categorizing matches: an archivist and community effort
To better understand these matches and create a strategy to remediate the harmful language they represent, it is important to consider each match in several different facets.
Looking at the context provided with each match allows archivists to understand the way in which the term was used. The remediation strategy for the use of a potentially harmful term in a proper noun used as a positive, self-identifying term, such as the National Association for the Advancement of Colored People, for example, is vastly different from that of a white person using the word “colored” as a racist insult.
The three ways in which I proposed we evaluate context are as follows:
- Match speaker: who was using the term? Was the sensitive term being used as a form of self-identification or reclaiming by members of a marginalized group, was it being used by an archivist, or was it used by someone with privilege over the marginalized group the term targets (e.g. a white person using an anti-Black term or a cisgender straight person using an anti-LGBTQ+ term)? Within this category, I proposed three potential categories for uses of a term: in-group, out-group, and archivist. If a term is used by a member (or members) of the identity group it references, its use is considered an in-group use. If the term is used by someone who is not a member of the identity group the term references, that usage of the term is considered out-group. Paraphrasing or dated term use by archivists is designated simply as archivist use.
- Match context: how was the term in question being used? Modifying the text used in a direct quote or a proper noun constitutes a far greater liberty by the archivist than removing a paraphrased section or completely archivist-written section of text that involved harmful language. Although this category is likely to evolve as more matches are categorized, my initial proposed categories are: proper noun, direct quote, paraphrasing, and archivist narrative.
- Match impact: what was the impact of the term? Was this instance a false positive, wherein the use of the term was in a completely unrelated and innocuous context (e.g. the use of the word “colored” to describe the colors used in visual media), or was the use of the term in fact harmful? Was the use of the term derogatory, or was it merely a mention of politicized identities? In many ways, determining the impact of a particular term or use of potentially harmful language is a community effort; if a community member with a marginalized identity says that the use of a term in that particular context is harmful to people with that identity, archivists are in no position to disagree or invalidate those feelings and experiences. The categories that I’ve laid out initially–dated original term, dated Rubenstein term, mention of marginalized issues, mention of marginalized identity, downplaying bias (e.g. calling racism and discrimination an issue with “race relations”), dehumanization of marginalized people, false positive–only hope to serve as an entry point and rudimentary categorization of these nuances to begin this process.
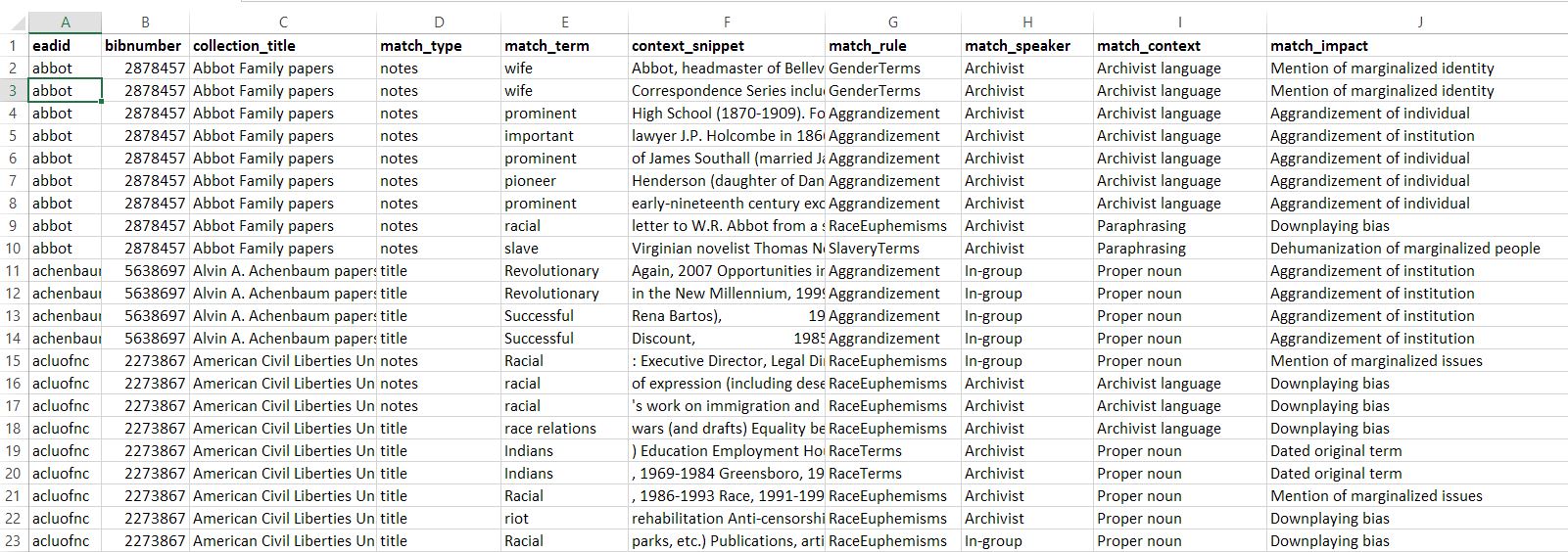
Here you can find more documentation on the manual categorization strategy.
Categorizing each of these instances of potentially harmful language remains a time-consuming, meticulous process. Although much of this work can be computerized, decolonization is a fundamentally human and fundamentally community-centered practice. No computer can dismantle the colonial, white supremacist narratives that archival work often upholds. This work requires our full attention and, for better or for worse, a lot of time, even with the productivity boost technology gives us.
Once categories have been established, at least on a preliminary level, I found that about 100-200 instances of potentially harmful language could be manually parsed and categorized in an hour.
Conclusion
Decolonization and anti-racist efforts in archival work are an ongoing process. It is bound to take active learning, reflection, and lots of remediation. However, using technology to start this process creates a much less daunting entry point. Anti-racism work is essential in archival spaces.
The ways we talk about history can either work to uphold traditional white supremacist, racist, ableist, etc. narratives, or they can work to dismantle them. In many ways, archival work has often upheld these narratives in the past, however this audit represents the sincere beginnings of work to further equitable narratives in the future.
One thought on “Auditing Archival Description for Harmful Language: A Computer and Community Effort”
Comments are closed.