Last Fall, this blog featured brief profiles of all your favorite Duke Library Information Technology Services staff, including our digitization specialists. This week on the blog we thought we would shine the spotlight even closer on our still image digitization expert, Mike and learn more about his unique contribution to Duke University Libraries.
Mike Adamo, Still Image Digitization Specialist
Favorite thing about your job:
While there are a number of things I enjoy about my job I would have to say that working on the Digital Collections Implementation Team consistently rises to the top. We are a small agile group that is tasked with publishing a wide variety of digital content created within the library and without for publication on the Library’s Digital Collections website. Each member of the team has a different vantage point when working with digital collections but we have the same goal in mind. We all strive to publish high quality digital collections in an efficient, consistent and innovative way. Everyone on the team is constantly trying to expand our capabilities whether it be an enhancement to the interface, normalization of metadata, adding new digitization equipment, streamlining the proposal process or the overarching goal to fold all of our workflows and systems together. It is rewarding to be on such an innovative, hard–working team.
What is the most noteworthy/most exciting/biggest change in your 10 years at Duke:
I would say that the Digital Production Center is always changing. The DPC has been in 4 different locations. I think we have had over 10 department heads all with different priorities, communication styles and approaches to the work. Our department has been under Conservation and IT (twice). We have a steady flow of students to keep us on our toes.
Favorite collection/project you have worked on:
I’ve had a few favorite collections over the years but the one that rise to the top is the Jane Goodall Archive. The Goodall Research papers was an interesting project to work on because it is such a large collection and it spanned many years. The logistics of pulling this off were pretty complex with a lot of moving parts. The highlight was that I (along with other members of the team) got to meet Jane Goodall. She has an open, quiet strength and was very friendly. Who knows if I’ll ever meet another legend in my lifetime?
Most challenging aspect of your work:
Just like many of us in the Library, the demands on my time are spread across many areas. Our main focus in the DPC is to “create(s) digital captures of unique, valuable, or compelling primary resources for the purpose of preservation, access, and publication.” This involves analyzing collections for digitization, developing project plans, consulting Conservation, providing supporting documentation for each project, training and monitoring students, color calibrating and profiling the environment, digitization of collections, quality control of collections, moving and posting of thousands upon thousands of images. To make it more fun, we always have multiple projects going at one time.
But just like most of us in the Library, in addition to my main job I have where many hats. Some of them are: Normalization and ingest of legacy collections into the repository; test and make recommendations for new technology for use in the DPC and elsewhere in the Library; maintain existing technology; troubleshoot our own equipment and work with our vendors to resolve mechanical, software and enterprise issues; consult with faculty and staff in the Library and across campus on their digitization projects; train Library staff on digital imaging standards and equipment; monitor and maintain 7 servers used for production and storage of archival digital images; and field all manner of random questions related to still image capture. So, balancing all of these things is probably the most challenging thing about my job. I think many, if not all of us, in the Library deal with this and do a pretty good job of keeping up with everything.
Favorite image:
This is not on Duke Digital Collections, but we digitized it and it was displayed at the Nasher Museum. For me, this picture personifies the severity of the struggle and sacrifice that is the Civil Rights Movement.
James Karales, Passive resistance training, Student Nonviolent Coordinating Committee (SNCC), 1960. Atlanta, Georgia. Gelatin silver print, 8.5 x 13 inches. The Duke University Special Collections Library. Screenshot from Nasher Museum of Art webpage.
One of my favorite movies as a youngster was Steven Spielberg’s “Raiders of the Lost Ark.” It’s non-stop action as the adventurous Indiana Jones criss-crosses the globe in an exciting yet dangerous race against the Nazis for possession of the Ark of the Covenant. According to the Book of Exodus, the Ark is a golden chest which contains the original stone tablets on which the Ten Commandments are inscribed, the moral foundation for both Judiasm and Christianity. The Ark is so powerful that it single-handedly destroys the Nazis and then turns Steven Spielberg and Harrison Ford into billionaires. Countless sequels, TV shows, theme-park rides and merchandise follow.
Greek manuscript 94, binding consists of heavily decorated repoussé silver over leather.
Fast-forward several decades, and I am asked to digitize Duke Libraries’ Kenneth Willis Clark Collection of Greek Manuscripts. Although not quite as old as the Ten Commandments, this is an amazing collection of biblical texts dating all the way back to the 9th century. These are weighty volumes, hand-written using ancient inks, often on animal-skin parchment. The bindings are characterized as Byzantine, and often covered in leathers like goatskin, sometimes with additional metal ornamentation. Although I have not had to run from giant boulders, or navigate a pit of snakes, I do feel a bit like Indiana Jones when holding one of these rare, ancient texts in my hands. I’m sure one of these books must house a secret code that can bestow fame and fortune, in addition to the obvious eternal salvation.
Before digitization, Senior Conservator Erin Hammeke evaluates the condition of each Greek manuscript, and rules out any that are deemed too fragile to digitize. Some are considered sturdy enough, but still need repairs, so Erin makes the necessary fixes. Once a manuscript is given the green light for digitization, I carefully place it in our book cradle so that it cannot be opened beyond a 90-degree angle. This helps protect our fragile bound materials from unnecessary stress on the binding. Next, the aperture, exposure, and focus are carefully adjusted on our Phase One P65+ digital camera so that the numerical values of our X-rite color calibration target, placed on top of the manuscript, match the numerical readings shown on our calibrated monitors.
Greek manuscript 101, with X-Rite color calibration target, secured in book cradle.
As the photography begins, each page of the manuscript is carefully turned by hand, so that a new image can be made of the following page. This is a tedious process, but requires careful concentration so the pages are consistently captured throughout each volume. Right-hand (recto) pages are captured first, in succession. Then the volume is turned over, so that the left-hand (verso) pages can be captured. I can’t read Greek, but it’s fascinating to see the beauty of the calligraphy, and view the occasional illustrations that appear on some pages. Sometimes, I discover that moths, beetles or termites have bored through the pages over time. It’s interesting to speculate as to which century this invasive destruction may have occurred. Perhaps the Nazis from the Indiana Jones movies traveled back in time, and placed the insects there?
Greek manuscript 101, showing insect damage.
Once the photography is complete, the recto and verso images are processed and then interleaved to recreate the left-right page order of the original manuscript. Next, the images go through a quality-control process in which any extraneous background area is cropped out, and each page is checked for clarity and consistent color and illumination. After that, another round of quality control insures that no pages are missing, or out of order. Finally, the images are converted to Pyramid TIFF files, which allow our web site users to zoom out and see all the pages at once, or zoom in to see maximum detail of any selected page. 38 Greek manuscripts are ready for online viewing now, and many more are coming soon. Stay tuned for the exciting sequel: “Indiana Jones and Even More Greek Manuscripts.”
The Digital Production Center engages with various departments within the Libraries and across campus to preserve endangered media and create unique digital collections. We work especially closely with The Rubenstein Rare Book, Manuscript, & Special Collections Library, as they hold many of the materials that we digitize and archive on a daily basis. This collaboration requires a shared understanding of numerous media types and their special characteristics; awareness of potential conservation and preservation issues; and a working knowledge of digitization processes, logistics, and limitations.
In order to facilitate this ongoing collaboration, we recently did a semester-long cross-training course with The Rubenstein’s Reproductions Manager, Megan O’Connell. Megan is one of our main points of contact for weekly patron requests, and we felt that this training would strengthen our ability to navigate tricky and time-sensitive digitization jobs heading into the future. The plan was for Megan to work with all three of our digitization specialists (audio, video, & still image) to get a combination of hands-on and observational learning opportunities.
Still image comprises the bulk of our workload, so we decided to spend most of the training on these materials. “Still image” includes anything that we digitize via photographic or scanning technology, e.g. manuscripts, maps, bound periodicals, posters, photographs, slides, etc. We identified a group of uniquely challenging materials of this type and digitized one of each for hands-on training, including:
Bound manuscript – Most of these items cannot be opened more than 90 degrees. We stabilize them in a custom-built book cradle, capture the recto sides of the pages, then flip the book and capture the verso sides. The resulting files then have to be interleaved into the correct sequence.
Map, or other oversize item – These types of materials are often too large to capture in one single camera shot. Our setup allows us to take multiple shots (with the help of the camera being mounted on a sliding track) which we then stitch together into a seamless whole.
Item with texture or different item depths, e.g. a folded map, tipped into a book – It is often challenging to properly support these items and level the map so that it is all in focus within the camera’s depth of field.
ANR volume – These are large, heavy volumes that typically contain older newspapers and periodicals. The paper can be very fragile and they have to be handled and supported carefully so as not to damage or tear the material.
Item with a tight binding w/ text that goes into the gutter – We do our best to capture all of the text, but it will sometimes appear to curve or disappear into the gutter in the resulting digital image.
Working through this list with Megan, I was struck by the diversity of materials that we collect and digitize. The training process also highlighted the variety of tricks, techniques, and hacks that we employ to get the best possible digital transfers, given the limitations of the available technology and the materials’ condition. I came out of the experience with a renewed appreciation of the complexity of the digitization work we do in the DPC, the significance of the rare materials in the collection, and the excellent service that we are able to provide to researchers through the Rubenstein Library.
In late October of this year, the Digital Production Center (along with many others in the Library) were busy developing budgets for FY 2015. We were asked to think about the needs of the department, where the bottlenecks were and possible new growth areas. We were asked to think big. The idea was to develop a grand list and work backwards to identify what we could reasonably ask for. While the DPC is able to digitize many types of materials and formats, such as audio and video, my focus is specifically still image digitization. So that’s what I focused on.
We serve many different parts of the Library and in order to accommodate a wide variety of requests, we use many different types of capture devices in the DPC: high-speed scanners, film scanners, overhead scanners and high-end cameras. The most heavily used capture device is the Phase One camera system. This camera system uses P65 60 MP digital back with a 72mm Schneider flat field lens. This enables us to capture high quality images at archival standards. The majority of material we digitize using this camera are bound volumes (most of them rare books from the David M. Rubenstein Library), but we also use this camera to digitize patron requests, which have increased significantly over the years (everything is expected to be digital it seems), oversized items, glass plate negatives, high-end photography collections and much more. It is no surprise that this camera is a bottleneck for still image production. In researching cameras to include in the budget, I was hard pressed to find another camera system that can compete with the Phase One camera. For over 5 years we have used Digital Transitions, a New York-based provider of high-end digital solutions, for our Phase One purchases and support. We have been very happy with the service, support and equipment we have purchased from them over the years, so I contacted them to inquire about new equipment on the horizon and pricing for upgrading our current system.
New equipment they turned me onto is the BC100 book scanner. This scanner uses a 100° glass platen and two reprographic cameras to capture two facing pages at the same time. While there are other camera systems that use a similar two camera setup (most notably the Scribe, Kirtas and Atiz), the cameras and digital backs used with the BC100, as well as the CaptureOne software that drives the cameras, are more well suited for cultural heritage reproduction. Along with the new BC100, CaptureOne is now offering a new software package specifically geared toward the cultural heritage community for use with this new camera system. While inquiring about the new system, I was invited to attend a Cultural Heritage Round Table event that Digital Transitions was hosting.
This roundtable was focused on the new CaptureOne software for use with the BC100 and the specific needs of the cultural heritage community. I have always found the folks at Digital Transitions to be very professional, knowledgeable and helpful. The event they put together included Jacob Frost, Application Software R&D Manager for PhaseOne; Doug Peterson, Technical Support, Training, R&D at Digital Transitions; and Don Williams of Image Science Associates, Imaging Scientist. Don is also on the Still Image Digitization Advisory Board with the Federal Agencies Digitization Guidelines Initiative (FADGI), a collaborative effort by federal agencies to define common guidelines, methods, and practices for digitizing historical content. They talked about the new features of the software, the science behind the software, the science behind the color technology and new information about the FADGI Still Image standard that we currently follow at the Library. I was impressed by the information provided and the knowledge shared, but what impressed me the most was the fact that the main reason Digital Transitions pulled this particular group of users and developers together was to ask us what the cultural heritage community needed from the new software. WHAT!? What we need from the software? I’ve been doing this work for about 15 years now and I think that’s the first time any software developer from any digital imaging company has asked our community specifically what we need. Don’t get me wrong, there is a lot of good software out there but usually the software comes “as is.” While it is fully functional, there are usually some work-arounds to get the software to do what I need it to do. We, as a community, spent about an hour drumming up ideas for software improvements and features.
While we still need to see follow-through on what we talked about, I am hopeful that some of the features we talked about will show up in the software. The software still needs some work to be truly beneficial (especially in post-production), but Phase One and Digital Transitions are definitely on to something.
A few weeks ago, archivists, engineers, students and vendors from across the globe arrived in the historic city of Savannah, GA for AMIA 2014. The annual conference for The Association of Moving Image Archivists is a gathering of professionals who deal with the challenge of preserving motion picture film and videotape content for future generations. Since today is Halloween, I must also point out that Savannah is a really funky city that is haunted! The downtown area is filled with weeping willow trees, well-preserved 19th century architecture and creepy cemeteries dating back to the U.S. Civil and Revolutionary wars. Savannah is almost as scary as a library budget meeting.
The bad moon rises over Savannah City Hall.
Since many different cultural heritage institutions are digitizing their collections for preservation and online access, it’s beneficial to develop universal file standards and best practices. For example, organizations like NARA and FADGI have contributed to the universal adoption of the 8-bit uncompressed TIFF file format for (non-transmissive) still image preservation. Likewise, for audio digitization, 24-bit uncompressed WAV has been universally adopted as the preservation standard. In other words, when it comes to still image and audio digitization, everyone is driving down the same highway. However, at AMIA 2014, it was apparent there are still many different roads being taken in regards to moving image preservation, with some potential traffic jams ahead. Are you frightened yet? You should be!
The smallest known film gauge: 3mm. Was it built by ancient druids?
Up until now, two file formats have been competing for dominance for moving image preservation: 10-bit uncompressed (.mov or .avi wrapper) vs. Motion JPEG2000 (MXF wrapper). The disadvantage of uncompressed has always been its enormous file size. Motion JPEG2000 incorporates lossless compression, which can reduce file sizes by 50%, but it’s expensive to implement, and has limited interoperability with most video software and players. At AMIA 2014, some were championing the use of a newer format, FFV1, a lossless codec that has compression ratios similar to JPEG2000, but is open source, and thus more widely adoptable. It is part of the FFmpeg software project. Adoption of FFV1 is growing, but many institutions are still heavily invested in 10-bit uncompressed or Motion JPEG2000. Which format will become the preservation standard, and which will become ghosts that haunt us forever?!?
Another emerging need is for content management systems that can store and provide public access to digitized video. The Hydra repository solution is being adopted by many institutions for managing preservation video files. In conjunction with Hydra, many are also adopting Avalon to provide public access for online viewing of video content. Like FFmpeg, both Hydra and Avalon are open source, which is part of their appeal. Others are building their own systems, catered specifically to their own needs, like The Museum of Modern Art. There are also competing metadata standards. For example, PBCore has been adopted by many public television stations, but is generally disliked by libraries. In fact, they find it really creepy!
A new print of Peter Pan was shown at AMIA 2014. That movie gave me nightmares as a child.
Finally, there is the thorny issue of copyright. Once file formats are chosen and delivery systems are in place, methods must be implemented to control access by only those intended, to protect copyright and hinder piracy. The Avalon Media System enables rights and access control to video content via guest passwords. The Library of Congress works around some of these these issues another way, by setting up remote viewing rooms in Washington, DC, which are connected via fiber-optic cable to their Audio-Visual Conservation Center in Culpeper, Va. Others, with more limited budgets, like Dino Everett at USC Cinematic Arts, watermark their video, upload it to sites like Vimeo, and implement temporary password protection, canceling the passwords manually after a few weeks. I mean, is there anything more frightening than a copyright lawsuit? Happy Halloween!
My recent posts have touched on endangered analog audio formats (open reel tape and compact cassette) and the challenges involved in digitizing and preserving them. For this installment, we’ll enter the dawn of the digital and Internet age and take a look at the first widely available consumer digital audio format: the DAT (Digital Audio Tape).
The DAT was developed by consumer electronics juggernaut Sony and introduced to the public in 1987. While similar in appearance to the familiar cassette and also utilizing magnetic tape, the DAT was slightly smaller and only recorded on one “side.” It boasted lossless digital encoding at 16 bits and variable sampling rates maxing out at 48 kHz–better than the 44.1 kHz offered by Compact Discs. During the window of time before affordable hard disk recording (roughly, the 1990s), the DAT ruled the world of digital audio.
The format was quickly adopted by the music recording industry, allowing for a fully digital signal path through the recording, mixing, and mastering stages of CD production. Due to its portability and sound quality, DAT was also enthusiastically embraced by field recordists, oral historians & interviewers, and live music recordists (AKA “tapers”):
[Conway, Michael A., “Deadheads in the Taper’s section at an outside venue,” Grateful Dead Archive Online, accessed October 10, 2014, http://www.gdao.org/items/show/834556.]
However, the format never caught on with the public at large, partially due to the cost of the players and the fact that few albums of commercial music were issued on DAT [bonus trivia question: what was the first popular music recording to be released on DAT? see below for answer]. In fact, the recording industry actively sought to suppress public availability of the format, believing that the ability to make perfect digital copies of CDs would lead to widespread piracy and bootlegging of their product. The Recording Industry Association of America (RIAA) lobbied against the DAT format and attempted to impose restrictions and copyright detection technology on the players. Once again (much like the earlier brouhaha over cassette tapes and subsequent battle over mp3’s and file sharing) “home taping” was supposedly killing music.
By the turn of the millennium, CD burning technology had become fairly ubiquitous and hard disk recording was becoming more affordable and portable. The DAT format slowly faded into obscurity, and in 2005, Sony discontinued production of DAT players.
In 2014, we are left with a decade’s worth of primary source audio tape (oral histories, interviews, concert and event recordings) that is quickly degrading and may soon be unsalvageable. The playback decks (and parts for them) are no longer produced and there are few technicians with the knowledge or will to repair and maintain them. The short-term answer to these problems is to begin stockpiling working DAT machines and doing the slow work of digitizing and archiving the tapes one by one. For example, the Libraries’ Jazz Loft Project Records collection consisted mainly of DAT tapes, and now exists as digital files accessible through the online finding aid: http://library.duke.edu/rubenstein/findingaids/jazzloftproject/. A long-term approach calls for a survey of library collections to identify the number and condition of DAT tapes, and then for prioritization of these items as it may be logistically impossible to digitize them all.
And now, the answer to our trivia question: in May 1988, post-punk icons Wire released The Ideal Copy on DAT, making it the first popular music recording to be issued on the new format.
Back in February 2014, we wrapped up the CCC project, a collaborative three year IMLS-funded digitization initiative with our partners in the Triangle Research Libraries Network (TRLN). The full title of the project is a mouthful, but it captures its essence: “Content, Context, and Capacity: A Collaborative Large-Scale Digitization Project on the Long Civil Rights Movement in North Carolina.”
So how large is “large-scale”? By comparison, when the project kicked off in summer 2011, we had a grand total of 57,000 digitized objects available online (“published”), collectively accumulated through sixteen years of digitization projects. That number was 69,000 by the time we began publishing CCC manuscripts in June 2012. Putting just as many documents online in three years as we’d been able to do in the previous sixteen naturally requires a much different approach to creating digital collections.
Traditional Digitization
Large-Scale Digitization
Individual items identified during scanning
No item-level identification: entire folders scanned
Descriptive metadata applied to each item
Archival description only (e.g., at the folder level)
Digitized documents accessed through an archival finding aid / collection guide with folder-level description.
Project Evaluation
CCC staff completed qualitative and quantitative evaluations of this large-scale digitization approach during the course of the project, ranging from conducting user focus groups and surveys to analyzing the impact on materials prep time and image quality control. Researcher assessments targeted three distinct user groups: 1) Faculty & History Scholars; 2) Undergraduate Students (in research courses at UNC & NC State); 3) NC Secondary Educators.
Ease of Use. Faculty and scholars, for the most part, found it easy to use digitized content presented this way. Undergraduates were more ambivalent, and secondary educators had the most difficulty.
To Embed or Not to Embed. In 2012, Duke was the only library presenting the image thumbnails embedded directly within finding aids and a lightbox-style image navigator. Undergrads who used Duke’s interface found it easier to use than UNC or NC Central’s, and Duke’s collections had a higher rate of images viewed per folder than the other partners. UNC & NC Central’s interfaces now use a similar convention.
Potential for Use. Most users surveyed said they could indeed imagine themselves using digitized collections presented in this way in the course of their research. However, the approach falls short in meeting key needs for secondary educators’ use of primary sources in their classes.
Desired Enhancements. The top two most desired features by faculty/scholars and undergrads alike were 1) the ability to search the text of the documents (OCR), and 2) the ability to explore by topic, date, document type (i.e., things enabled by item-level metadata). PDF download was also a popular pick.
Impact on Duke Digitization Projects
Since the moment we began putting our CCC manuscripts online (June 2012), we’ve completed the eight CCC collections using this large-scale strategy, and an additional eight manuscript collections outside of CCC using the same approach. We have now cumulatively put more digital objects online using the large-scale method (96,000) than we have via traditional means (75,000). But in that time, we have also completed eleven digitization projects with traditional item-level identification and description.
We see the large-scale model for digitization as complementary to our existing practices: a technique we can use to meet the publication needs of some projects.
Usage
Do people actually use the collections when presented in this way? Some interesting figures:
Views / item in 2013-14 (traditional digital object; item-level description): 13.2
Views / item in 2013-14 (digitized image within finding aid; folder-level description): 1.0
Views / folder in 2013-14 (digitized folder view in finding aid): 8.5
It’s hard to attribute the usage disparity entirely to the publication method (they’re different collections, for one). But it’s reasonable to deduce (and unsurprising) that bypassing item-level description generally results in less traffic per item.
On the other hand, one of our CCC collections (The Allen Building Takeover Collection) has indeed seen heavy use–so much, in fact, that nearly 90% of TRLN’s CCC items viewed in the final six months of the project were from Duke. Its images averaged over 78 views apiece in the past year; its eighteen folders opened 363 times apiece. Why? The publication of this collection coincided with an on-campus exhibit. And it was incorporated into multiple courses at Duke for assignments to write using primary sources.
The takeaway is, sometimes having interesting, important, and timely content available for use online is more important than the features enabled or the process by which it all gets there.
Looking Ahead
We’ll keep pushing ahead with evolving our practices for putting digitized materials online. We’ve introduced many recent enhancements, like fulltext searching, a document viewer, and embedded HTML5 video. Inspired by the CCC project, we’ll continue to enhance our finding aids to provide access to digitized objects inline for context (e.g., The Jazz Loft Project Records). Our TRLN partners have also made excellent upgrades to the interfaces to their CCC collections (e.g., at UNC, at NC State) and we plan, as usual, to learn from them as we go.
The audio tapes in the recently acquired Radio Haiti collection posed a number of digitization challenges. Some of these were discussed in this video produced by Duke’s Rubenstein Library:
In this post, I will use a short audio clip from the collection to illustrate some of the issues that we face in working with this particular type of analog media.
First, I present the raw digitized audio, taken from a tape labelled “Tambour Vaudou”:
As you can hear, there are a number of confusing and disorienting things going on there. I’ll attempt to break these down into a series of discrete issues that we can diagnose and fix if necessary.
Tape Speed
Analog tape machines typically offer more than one speed for recording, meaning that you can change the rate at which the reels turn and the tape moves across the record or playback head. The faster the speed, the higher the fidelity of the result. On the other hand, faster speeds use more tape (which is expensive). Tape speed is measured in “ips” (inches per second). The tapes we work with were usually recorded at speeds of 3.75 or 7.5 ips, and our playback deck is set up to handle either of these. We preview each tape before digitizing to determine what the proper setting is.
In the audio example above, you can hear that the tape speed was changed at around 10 seconds into the recording. This accounts for the “spawn of Satan” voice you hear at the beginning. Shifting the speed in the opposite direction would have resulted in a “chipmunk voice” effect. This issue is usually easy to detect by ear. The solution in this case would be to digitize the first 10 seconds at the faster speed (7.5 ips), and then switch back to the slower playback speed (3.75 ips) for the remainder of the tape.
The Otari MX-5050 tape machine
Volume Level and Background Noise
The tapes we work with come from many sources and locations and were recorded on a variety of equipment by people with varying levels of technical knowledge. As a result, the audio can be all over the place in terms of fidelity and volume. In the audio example above, the volume jumps dramatically when the drums come in at around 00:10. Then you hear that the person making the recording gradually brings the level down before raising it again slightly. There are similar fluctuations in volume level throughout the audio clip. Because we are digitizing for archival preservation, we don’t attempt to make any changes to smooth out the sometimes jarring volume discrepancies across the course of a tape. We simply find the loudest part of the content, and use that to set our levels for capture. The goal is to get as much signal as possible to our audio interface (which converts the analog signal to digital information that can be read by software) without overloading it. This requires previewing the tape, monitoring the input volume in our audio software, and adjusting accordingly.
This recording happens to be fairly clean in terms of background noise, which is often not the case. Many of the oral histories that we work with were recorded in noisy public spaces or in homes with appliances running, people talking in the background, or the subject not in close enough proximity to the microphone. As a result, the content can be obscured by noise. Unfortunately there is little that can be done about this since the problem is in the recording itself, not the playback. There are a number of hum, hiss, and noise removal tools for digital audio on the market, but we typically don’t use these on our archival files. As mentioned above, we try to capture the source material as faithfully as possible, warts and all. After each transfer, we clean the tape heads and all other surfaces that the tape touches with a Q-tip and denatured alcohol. This ensures that we’re not introducing additional noise or signal loss on our end.
Splices
While cleaning the Radio Haiti tapes (as detailed in the video above), we discovered that many of the tapes were comprised of multiple sections of tape spliced together. A splice is simply a place where two different pieces of audio tape are connected by a piece of sticky tape (much like the familiar Scotch tape that you find in any office). This may be done to edit together various content into a seamless whole, or to repair damaged tape. Unfortunately, the sticky tape used for splicing dries out over time, becomes brittle, and loses it’s adhesive qualities. In the course of cleaning and digitizing the Radio Haiti tapes, many of these splices came undone and had to be repaired before our transfers could be completed.
Tape ready for splicing
Our playback deck includes a handy splicing block that holds the tape in the correct position for this delicate operation. First I use a razor blade to clean up any rough edges on both ends of the tape and cut it to the proper 45 degree angle. The splicing block includes a groove that helps to make a clean and accurate cut. Then I move the two pieces of tape end to end, so that they are just touching but not overlapping. Finally I apply the sticky splicing tape (the blue piece in the photo below) and gently press on it to make sure it is evenly and fully attached to the audio tape. Now the reel is once again ready for playback and digitization. In the “Tambour Vaudou” audio clip above, you may notice three separate sections of content: the voice at the beginning, the drums in the middle, and the singing at the end. These were three pieces of tape that were spliced together on the original reel and that we repaired right here in the library’s Digital Production Center.
A finished splice. Note that the splice is made on the shiny back of the tape, not on the matte side that audio is recorded on.
These are just a few of many issues that can arise in the course of digitizing a collection of analog open reel audio tapes. Fortunately, we can solve or mitigate most of these problems, get a clean transfer, and generate a high-quality archival digital file. Until next time…keep your heads clean, your splices intact, and your reels spinning!
The technology for digitizing analog videotape is continually evolving. Thanks to increases in data transfer-rates and hard drive write-speeds, as well as the availability of more powerful computer processors at cheaper price-points, the Digital Production Center recently decided to upgrade its video digitization system. Funding for the improved technology was procured by Winston Atkins, Duke Libraries Preservation Officer. Of all the materials we work with in the Digital Production Center, analog videotape has one of the shortest lifespans. Thus, it is high on the list of the Library’s priorities for long-term digital preservation. Thanks, Winston!
Thunderbolt is leaving USB in the dust.
Due to innovative design, ease of use, and dominance within the video and filmmaking communities, we decided to go with a combination of products designed by Apple Inc., and Blackmagic Design. A new computer hardware interface recently adopted by Apple and Blackmagic, called Thunderbolt, allows the the two companies’ products to work seamlessly together at an unprecedented data-transfer speed of 10 Gigabits per second, per channel. This is much faster than previously available interfaces such as Firewire and USB. Because video content incorporates an enormous amount of data, the improved data-transfer speed allows the computer to capture the video signal in real time, without interruption or dropped frames.
Blackmagic design converts the analog video signal to SDI (serial digital interface).
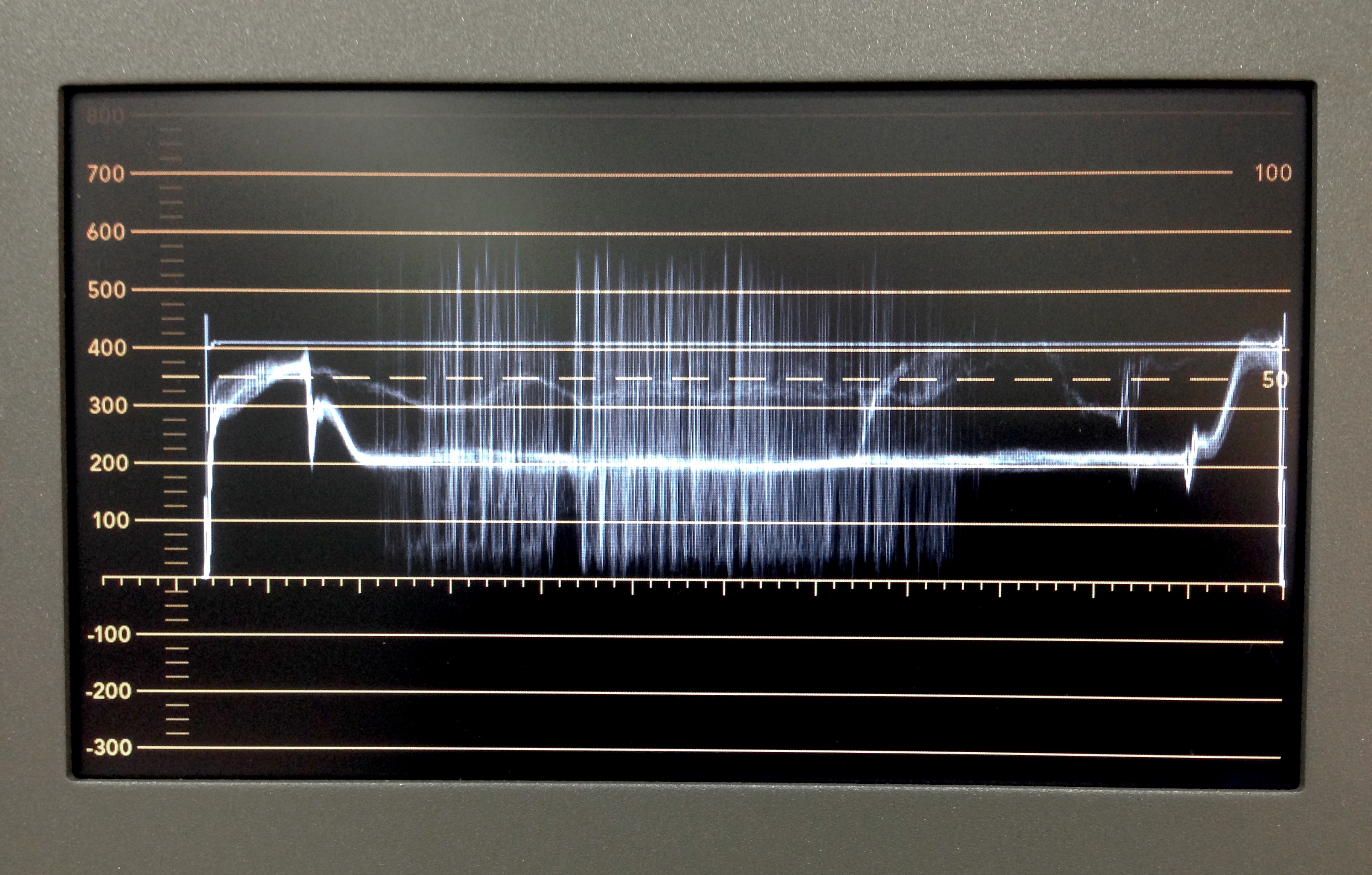
Our new data stream works as follows. Once a tape is playing on an analog videotape deck, the output signal travels through an Analog to SDI (serial digital interface) converter. This converts the content from analog to digital. Next, the digital signal travels via SDI cable through a Blackmagic SmartScope monitor, which allows for monitoring via waveform and vectorscope readouts. A veteran television engineer I know will talk to you for days regarding the physics of this, but, in layperson terms, these readouts let you verify the integrity of the color signal, and make sure your video levels are not too high (blown-out highlights) or too low (crushed shadows). If there is a problem, adjustments can be made via analog video signal processor or time-base corrector to bring the video signal within acceptable limits.
Blackmagic’s SmartScope allows for monitoring of the video’s waveform. The signal must stay between 0 and 700 (left side) or clipping will occur, which means you need to get that videotape to the emergency room, STAT!
Next, the video content travels via SDI cable to a Blackmagic Ultrastudio interface, which converts the signal from SDI to Thunderbolt, so it can now be recognized by a computer. The content then travels via Thunderbolt cable to a 27″ Apple iMac utilizing a 3.5 GHz Quad-core processor and NVIDIA GeForce graphics processor. Blackmagic’s Media Express software writes the data, via Thunderbolt cable, to a G-Drive Pro external storage system as a 10-bit, uncompressed preservation master file. After capture, editing can be done using Apple’s Final Cut Pro or QuickTime Pro. Compressed Mp4 access derivatives are then batch-processed using Apple’s Compressor software, or other utilities such as MPEG-Streamclip. Finally, the preservation master files are uploaded to Duke’s servers for long-term storage. Unless there are copyright restrictions, the access derivatives will be published online.
Video digitization happens in real time. A one-hour tape is digitized in, well, one hour, which is more than enough Bob Hope jokes for anyone.
This past week, we were excited to be able to publish a rare 1804 manuscript copy of the Haitian Declaration of Independence in our digital collections website. We used the project as a catalyst for improving our document-viewing user experience, since we knew our existing platforms just wouldn’t cut it for this particular treasure from the Rubenstein Library collection. In order to present the declaration online, we decided to implement the open-source Diva.js viewer. We’re happy with the results so far and look forward to making more strides in our ability to represent documents in our site as the year progresses.
Haitian Declaration of Independence as seen in Diva.js document viewer with full text transcription.
Challenges to Address
We have had two glaring limitations in providing access to digitized collections to date: 1) a less-than-stellar zoom & pan feature for images and 2) a suboptimal experience for navigating documents with multiple pages. For zooming and panning (see example), we use software called OpenLayers, which is primarily a mapping application. And for paginated items we’ve used two plugins designed to showcase image galleries, Galleria (example) and Colorbox (example). These tools are all pretty good at what they do, but we’ve been using them more as stopgap solutions for things they weren’t really created to do in the first place. As the old saying goes, when all you have is a hammer, everything looks like a nail.
Big (OR Zoom-Dependent) Things
A selection from our digitized Italian Cultural Posters. The “large” derivative is 11,000 x 8,000 pixels, a 28MB JPG.
Traditionally as we digitize images, whether freestanding or components of a multi-page object, at the end of the process we generate three JPG derivatives per page. We make a thumbnail (helpful in search results or other item sets), medium image (what you see on an item’s webpage), and large image (same dimensions as the preservation master, viewed via the ‘all sizes’ link). That’s a common approach, but there are several places where that doesn’t always work so well. Some things we’ve digitized are big, as in “shoot them in sections with a camera and stitch the images together” big. And we’ve got several more materials like this waiting in the wings to make available. A medium image doesn’t always do these things justice, but good luck downloading and navigating a giant 28MB JPG when all you want to do is zoom in a little bit.
Likewise, an object doesn’t have to be large to really need easy zooming to be part of the viewing experience. You might want to read the fine print on that newspaper ad, see the surgeon general’s warning on that billboard, or inspect the brushstrokes in that beautiful hand-painted glass lantern slide.
And finally, it’s not easy to anticipate the exact dimensions at which all our images will be useful to a person or program using them. Using our data to power an interactive display for a media wall? A mobile app? A slideshow on the web? You’ll probably want images that are different dimensions than what we’ve stored online. But to date, we haven’t been able to provide ways to specify different parameters (like height, width, and rotation angle) in the image URLs to help people use our images in environments beyond our website.
A page from Mary McCornack Thompson’s 1908 travel diary, limited by its presentation via an image gallery.
Paginated Things
We do love our documentary photography collections, but a lot of our digitized objects are represented by more than just a single image. Take an 11-page piece of sheet music or a 127-page diary, for example. Those aren’t just sequences or collections of images. Their paginated orientation is pretty essential to their representation online, but a lot of what characterizes those materials is unfortunately lost in translation when we use gallery tools to display them.
The Intersection of (Big OR Zoom-Dependent) AND Paginated
Here’s where things get interesting and quite a bit more complicated: when zooming, panning, page navigation, and system performance are all essential to interacting with a digital object. There are several tools out there that support these various aspects, but very few that do them all AND do them well. We knew we needed something that did.
Our Solution: Diva.js
We decided to use the open-source Diva.js (Document Image Viewer with AJAX). Developed at the Distributed Digital Music Archives and Libraries Lab (DDMAL) at McGill University, it’s “a Javascript frontend for viewing documents, designed to work with digital libraries to present multi-page documents as a single, continuous item” (see About page). We liked its combination of zooming, panning, and page navigation, as well as its extensibility. This Code4Lib article nicely summarizes how it works and why it was developed.
Setting up Diva.js required us to add a few new pieces to our infrastructure. The most significant was an image server (in our case, IIPImage) that could 1) deliver parts of a digital image upon request, and 2) deliver complete images at whatever size is requested via URL parameters.
Our Interface: How it Works
By default, we present a document in our usual item page template that provides branding, context, and metadata. You can scroll up and down to navigate pages, use Page Up or Page Down keys, or enter a page number to jump to a page directly. There’s a slider to zoom in or out, or alternatively you can double-click to zoom in / Ctrl-double-click to zoom out. You can toggle to a grid view of all pages and adjust how many pages to view at once in the grid. There’s a really handy full-screen option, too.
Fulltext transcription presented in fullscreen mode, thumbnail view.Page 4, zoom level 4, with link to download.
It’s optimized for performance via AJAX-driven “lazy loading”: only the page of the document that you’re currently viewing has to load in your browser, and likewise only the visible part of that page image in the viewer must load (via square tiles). You can also download a complete JPG for a page at the current resolution by clicking the grey arrow.
We extended Diva.js by building a synchronized fulltext pane that displays the transcript of the current page alongside the image (and beneath it in full-screen view). That doesn’t come out-of-the-box, but Diva.js provides some useful hooks into its various functions to enable developing this sort of thing. We also slightly modified the styles.
A tile delivered by IIPImage server
Behind the scenes, we have pyramid TIFF images (one for each page), served up as JPGs by IIPImage server. These files comprise arrays of 256×256 JPG tiles for each available zoom level for the image. Let’s take page 1 of the declaration for example. At zoom level 0 (all the way zoomed out), there’s only one image tile: it’s under 256×256 pixels; level 1 is 4 tiles, level 2 is 12, level 3 is 48, level 4 is 176. The page image at level 5 (all the way zoomed in) includes 682 tiles (example of one), which sounds like a lot, but then again the server only has to deliver the parts that you’re currently viewing.
Every item using Diva.js also needs to load a JSON stream including the dimensions for each page within the document, so we had to generate that data. If there’s a transcript present, we store it as a single HTML file, then use AJAX to dynamically pull in the part of that file that corresponds to the currently-viewed page in the document.
Diva.js & IIPImage Limitations
It’s a good interface, and is the best document representation we’ve been able to provide to date. Yet it’s far from perfect. There are several areas that are limiting or that we want to explore more as we look to make more documents available in the future.
Out of the box, Diva.js doesn’t support page metadata, transcriptions, or search & retrieval within a document. We do display a synchronized transcript, but there’s currently no mapping between the text and the location within each page where each word appears, nor can you perform a search and discover which pages contain a given keyword. Other folks using Diva.js are working on robust applications that handle these kinds of interactions, but the degree to which they must customize the application is high. See for example, the Salzinnes Antiphonal: a 485-page liturgical manuscript w/text and music or a prototype for the Liber Usualis: a 2,000+ page manuscript using optical music recognition to encode melodic fragments.
Diva.js also has discrete zooming, which can feel a little jarring when you jump between zoom levels. It’s not the smooth, continuous zoom experience that is becoming more commonplace in other viewers.
With the IIPImage server, we’ll likely re-evaluate using Pyramid TIFFs vs. JPEG2000s to see which file format works best for our digitization and publication workflow. In either case, there are several compression and caching variables to tinker with to find an ideal balance between image quality, storage space required, and system performance. We also discovered that the IIP server unfortunately strips out the images’ ICC color profiles when it delivers JPGs, so users may not be getting a true-to-form representation of the image colors we captured during digitization.
Next Steps
Launching our first project using Diva.js gives us a solid jumping-off point for expanding our ability to provide useful, compelling representations of our digitized documents online. We’ll assess how well this same approach would scale to other potential projects and in the meantime keep an eye on the landscape to see how things evolve. We’re better equipped now than ever to investigate alternative approaches and complementary tools for doing this work.
We’ll also engage more closely with our esteemed colleagues in the Duke Collaboratory for Classics Computing (DC3), who are at the forefront of building tools and services in support of digital scholarship. Well beyond supporting discovery and access to documents, their work enables a community of scholars to collaboratively transcribe and annotate items (an incredible–and incredibly useful–feat!). There’s a lot we’re eager to learn as we look ahead.
Notes from the Duke University Libraries Digital Projects Team






































{kind=link}
{kind=link}
{kind=link}