Recently I worked on a simple kiosk for a new exhibit in the library, Yasak/Banned: Political Cartoons from Late Ottoman and Republican Turkey. The interface presents users with three videos featuring the curators of the exhibit that explain the historical context and significance of the items in the exhibit space. We also included a looping background video that highlights many of the illustrations from the exhibit and plays examples of Turkish music to help envelop visitors into the overall experience.
With some of the things I’ve built in the past, I would setup different section of an interface to view videos, but in this case I wanted to keep things as simple as possible. My plan was to open each video in an overlay using fancybox. However, I didn’t want the looping background audio to interfere with the curator videos. We also needed to include a ‘play/pause’ button to turn off the background music in case there was something going on in the exhibit space. And I wanted all these transitions to be as smooth as possible so that the experience wouldn’t be jarring. What seemed reasonably simple on the surface proved a little more difficult than I thought.
After trying a few different approaches with limited success, as usual stackoverflow revealed a promising direction to go in — the key turned out to be the .animate jQuery method.
The first step was to write functions to ‘play/pause’ – even though in this case we’d let the background video continue to play and only lower the volume to zero. The playVid function sets the volume to 0, then animates it back up to 100% over three seconds. pauseVid does the inverse, but more quickly.
function playVid() {
vid.volume = 0;
$('#myVideo').animate({
volume: 1
}, 3000); // 3 seconds
playBtn.style.display = 'none';
pauseBtn.style.display = 'block';
}
function pauseVid() {
// really just fading out music
vid.volume = 1;
$('#myVideo').animate({
volume: 0
}, 750); // .75 seconds
playBtn.style.display = 'block';
pauseBtn.style.display = 'none';
}
The play and pause buttons, which are positioned on top of each other using CSS, are set to display or hide in the functions above. The are also set to call the appropriate function using an onclick event. Their markup looks like this:
You can view a demo version and download a zip of the assets in case it’s helpful. I think the final product works really well and I’ll likely use a similar implementation in future projects.
Every Halloween at Duke Libraries, we have our annual “Screamfest.” This is when the David M. Rubenstein Rare Book & Manuscript Library shows off unique holdings related to extrasensory perception, premature burial, 16th century witches, devils (not just blue ones), creepy advertisements, eerie pulp fiction, scary zines and more. Attendees sometimes show up in costumes, and there is of course, lots of candy. I always eat too much.
When I look through the various materials on display, there is one item in particular that always seems to draw me in. In fact, you could say I am compelled to read it, almost as if I am not in control of my actions! It’s a simple one-page letter, written in 1949 by Luther M. Schulze, a Lutheran pastor in Washington, D.C., addressed to J.B Rhine, the scientist who founded parapsychology as a branch of psychology, and started the Duke Parapsychology Laboratory, which operated at Duke University from 1935 until the 1960’s. Parapsychology is the study of phenomena such as telepathy, clairvoyance, hypnosis, psychokinesis and other paranormal mysteries.
The 1949 letter from the Rev. Luther Schulze to J.B. Rhine. (click to enlarge)
The letter begins: “We have in our congregation a family who are being disturbed by poltergeist phenomena. It first appeared about January 15, 1949. The family consists of the maternal grandmother, a fourteen (year) old boy who is an only child, and his parents. The phenomena is present only in the boy’s presence. I had him in my home on the night of February 17-18 to observe for myself. Chairs moved with him and one threw him out. His bed shook whenever he was in it.” The letter also states that his family says that “words appeared on the boy’s body” and he “has visions of the devil and goes into a trance and speaks in a strange language”
This letter immediately reminded me of “The Exorcist,” one of the best horror movies of all time. I was too young to see the film when it was originally released in 1973, but got the chance to see the director’s cut on the big screen in 2000. It’s a very unsettling and frightening film, but not because of gratuitous gore like you see in today’s monotonously-sadistic slasher films. The Exorcist is one of the scariest movies ever because it expertly taps into a central fear within our Judeao-Christian collective subconscious: That evil isn’t just something we battle outside of ourselves. The most frightening evil of all is that which can take root within us.
It turns out there’s a direct link between this mysterious letter to J.B Rhine and “The Exorcist.” William Peter Blatty, who wrote the 1971 novel and adapted it for the film, based his book on a real-life 1949 exorcism performed by Jesuit priests in St. Louis. The exorcism was performed on a 14-yr-old boy under the pseudonym of “Roland Doe” and that is the same boy that Rev. Schulze is referring to in his letter to J.B. Rhine at Duke. When Rhine received the letter, Roland’s family had taken him to St. Louis for the exorcism, having given up on conventional psychiatry. Blatty changed the gender and age of the child for his novel and screenplay, but many of the occurrences described in the letter are recognizable to anyone familiar with the book or movie.
The reply from J.B. Rhine to the Rev. Luther Schulze. (click to enlarge)
Unfortunately for this blog post, poltergeists or demons or psychosomatic illnesses (depending on your point of view) often vanish as unexpectedly as they show up, and that’s what happened in this case. After an initial reply to the letter from L.E. Rhine, his wife and lab partner, J.B. Rhine responded to Rev. Schulze that he was “deeply interested in this case,” and that “the most likely normal explanation is that the boy is, himself led to create the effect of being the victim of mysterious agencies or forces and might be sincerely convinced of it. Such movements as those of the chair and bed might, from your very brief account of them, have originated within himself.” Part of the reason Rhine was successful in his field is that he was an empirical skeptic. Rhine later visited Schulze in person, but by then, the exorcism had ended, and Roland’s condition had returned to normal.
According to subsequent research, Roland married, had children and leads a quiet, ordinary life near Washington, D.C. He refuses to talk about the events of 1949, other than saying he doesn’t remember. In the mid-1960’s, Duke and J.B. Rhine parted ways, and the Duke Parapsychology Lab closed. This was likely due in part to the fact that, despite Rhine’s extensive research and empirical testing, parapsychology was, and still is, considered a dubious pseudoscience. Duke probably realized the association wasn’t helping their reputation as a stellar academic institution. The Rhines continued their research, setting up the “Foundation for Research on the Nature of Man,” independently of Duke. But the records of the Duke Parapsychology Laboratory are available for study at Duke Libraries. I wonder what other dark secrets might be discovered, brought to light and exorcized?
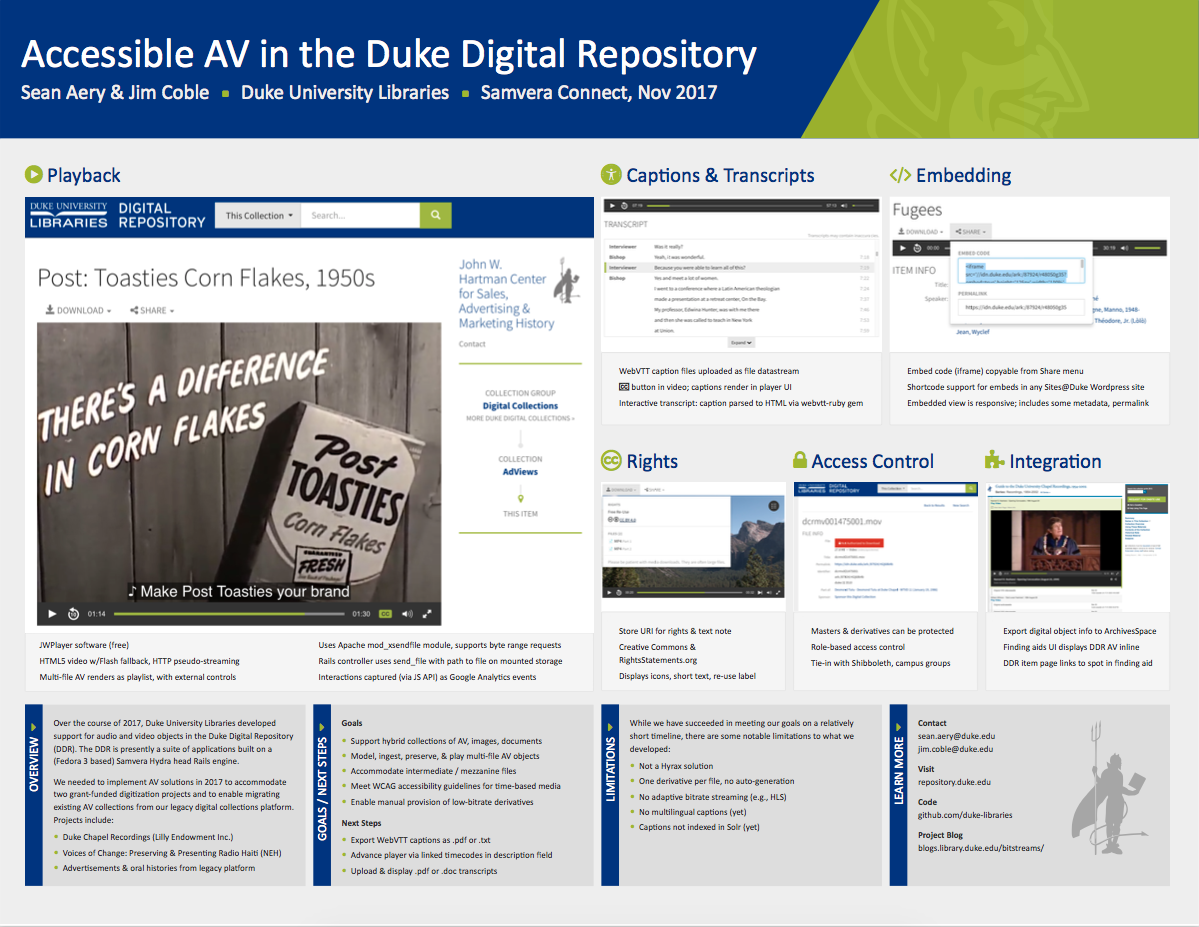
Over the course of 2017, we improved our capacity to support digital audiovisual materials in the Duke Digital Repository (DDR) by leaps and bounds. A little more than a year ago, I had written a Bitstreams blog post highlighting the new features we had just developed in the DDR to provide basic functionality for AV, especially in support of the Duke Chapel Recordings collection. What a difference a year makes.
This past year brought renewed focus on AV development, as we worked to bring the NEH grant-funded Radio Haiti Archive online (launched in June). At the same time, our digital collections legacy platform migration efforts shifted toward moving our existing high-profile digital AV material into the repository.
Closed Captions
At Duke University Libraries, we take accessibility seriously. We aim to include captions or transcripts for the audiovisual objects made available via the Duke Digital Repository, especially to ensure that the materials can be perceived and navigated by people with disabilities. For instance, work is well underway to create closed captions for all 1,400 items in the Duke Chapel Recordings project.
Captioned video displays a CC button and shows captions as an overlay in the video player. Example from the AdViews collection, coming soon to the DDR.
The DDR now accommodates modeling and ingest for caption files, and our AV player interface (powered by JW Player) presents a CC button whenever a caption file is available. Caption files are encoded using WebVTT, the modern W3C standard for associating timed text with HTML audio and video. WebVTT is structured so as to be machine-processable, while remaining lightweight enough to be reasonably read, created, or edited by a person. It’s a format that transcription vendors can provide. And given its endorsement by W3C, it should be a viable captioning format for a wide range of applications and devices for the foreseeable future.
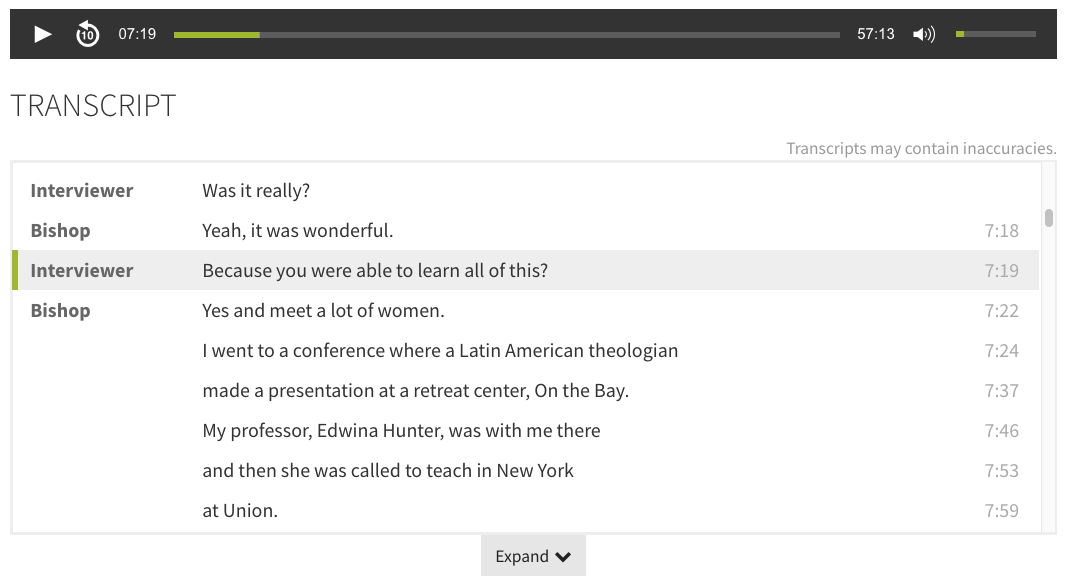
Text cues from a WebVTT caption file for an audio item in the Duke Chapel Recordings collection.
Interactive Transcripts
Displaying captions within the player UI is helpful, but it only gets us so far. For one, that doesn’t give a user a way to just read the caption text without requiring them to play the media. We also need to support captions for audio files, but unlike with video, the audio player doesn’t include enough real estate within itself to render the captions. There’s no room for them to appear.
So for both audio and video, our solution is to convert the WebVTT caption files on-the-fly into an interactive in-page transcript. Using the webvtt-ruby gem (developed by Coconut) , we parse the WebVTT text cues into Ruby objects, then render them back on the page as HTML. We then use the JWPlayer Javascript API to keep the media player and the HTML transcript in sync. Clicking on a transcript cue advances the player to the corresponding moment in the media, and the currently-playing cue gets highlighted as the media plays.
Example interactive synchronized transcript for an audio item (rendered from a WebVTT caption file). From a collection coming soon to the DDR.
We also do some extra formatting when the WebVTT cues include voice tags (<v> tags), which can optionally indicate the name of the speaker (e.g., <v Jane Smith>). The in-page transcript is indexed by Google for search retrieval.
Transcript Documents
In many cases, especially for audio items, we may have only a PDF or other type of document with a transcript of a recording that isn’t structured or time-coded. Like captions, these documents are important for accessibility. We have developed support for displaying links to these documents near the media player. Look for some new collections using this feature to become available in early 2018.
Transcript documents presented above the media player. Coming soon to AV collections in the DDR.
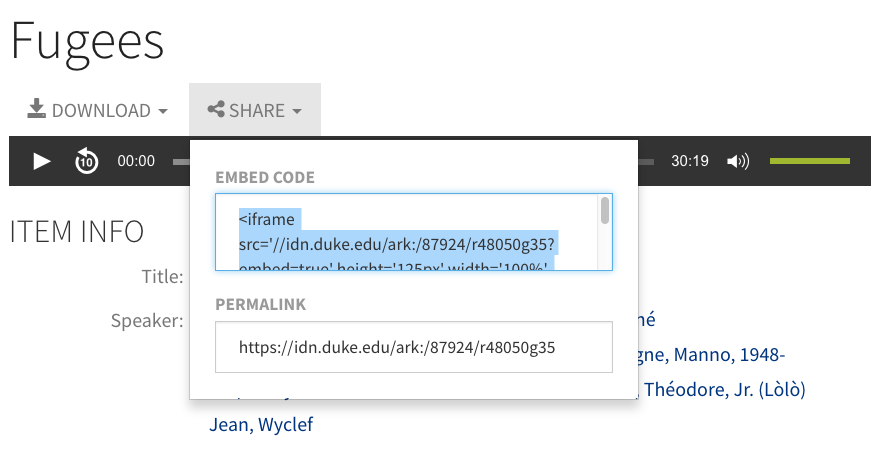
A/V Embedding
The DDR web interface provides an optimal viewing or listening experience for AV, but we also want to make it easy to present objects from the DDR on other websites, too. When used on other sites, we’d like the objects to include some metadata, a link to the DDR page, and proper attribution. To that end, we now have copyable <iframe> embed code available from the Share menu for AV items.
This embed code is also what we now use within the Rubenstein Library collection guides (finding aids) interface: it lets us present digital objects from the DDR directly from within a corresponding collection guide. So as a researcher browses the inventory of a physical archival collection, they can play the media inline without having to leave.
Embedded view of a DDR video from the Duke Chapel Recordings collection presented inline in a Rubenstein Library archival collection guide.
Sites@Duke Integration
If your website or blog is one of the thousands of WordPress sites hosted and supported by Sites@Duke — a service of Duke’s Office of Information Technology (OIT) — we have good news for you. You can now embed objects from the DDR using WordPress shortcode. Sites@Duke, like many content management systems, doesn’t allow authors to enter <iframe> tags, so shortcode is the only way to get embeddable media to render.
Sites@Duke WordPress sites can embed DDR media by using shortcode with the DDR item’s permalink.
And More!
Here are the other AV-related features we have been able to develop in 2017:
Access control: master files & derivatives alike can be protected so access is limited to only authorized users/groups
Video thumbnail images: model, manage, and display
Video poster frames: model, manage, and display
Intermediate/mezzanine files: model and manage
Rights display: display icons and info from RightsStatements.org and Creative Commons, so it’s clear what users are permitted to do with media.
What’s Next
We look forward to sharing our recent AV development with our peers at the upcoming Samvera Connect conference (Nov 6-9, 2017 in Evanston, IL). Here’s our poster summarizing the work to date:
Duke University Libraries has successfully used multispectral imaging to make ancient manuscripts more readable, but the same technology can also be employed on modern collection materials. Over the summer, our multispectral imaging working group teamed up with Rubenstein Library staff to investigate whether advanced imaging techniques could be used to make certain faded photocopies more legible. Duke’s archival collections are filled with copies of documents made using a wide range of printing techniques. Some print processes which were popular before the proliferation of “laser” printing (electrostatic prints) can become badly and irreversibly faded. The Thermo-Fax was a specific type of copying process, introduced by 3M in 1950, but has become a common proprietary eponym for this whole category of collection materials.
Robert Hill Papers, Electrolytic print under normal illumination
When confronted with a badly faded photocopy, library staff have traditionally resorted to one preservation tactic: create a more stable reproduction of the document on high quality paper. While the original print will continue to fade over time, the “preservation photocopy” should remain just as legible. In some cases, the decision may be made to retain just the preservation copy and deaccession the original. If the document is completely illegible, however, a preservation photocopy won’t be effective and the original may not be retained at all; it’s difficult to determine the value of a letter that can’t be read. If alternative imaging techniques could be used to produce a better reproduction, it might dramatically change how we assess and work with faded documents.
Meghan Lyon, Manuscript Processing Archivist at Rubenstein Library Technical Services, helped to identify several examples of early photocopies from various collections. Our first trial was with a print, probably dating from the 1970s, from the Robert A. Hill Collection of the Marcus Garvey and Universal Negro Improvement Association Papers Project Records (see image above). This collection contains many reproductions of newspaper articles from microfilm. After multispectral imaging and software processing , we achieved these results:
Robert HIll Papers, PCA with False Color
The above image is more legible than under regular illumination, but really not the unequivocal win for which we had hoped. Research about machines that would print copies from microfilm suggested that this type of print, an electrolytic print process sometimes called “Photoconductography”, may not be the best candidate. The image is generated from metallic silver, rather than a dye. Therefore, this item likely became damaged from a water event, rather than fading. We went back to our friends in Technical Services for more examples.
Radio Haiti Collection during processing
The next candidate for imaging came from the Radio Haiti Archives. This collection contains more modern prints (from the 1990s), which are completely faded. Our test document (pictured below) almost looks like a blank sheet of paper. The only visible markings are from a ballpoint pen. Based upon descriptions of paper types and qualities of this object, we identified this as a form of direct thermal printing.
Radio Haiti, Direct thermal print under normal illumination
The paper used in this type of direct thermal printing is impregnated with a colorless dye precursor and coupler system. Thermoplastic material separates the two ingredients. When exposed to heat, the separator melts and the precursor and coupler react to form the colored print. Dyes are notoriously unstable over time, so it is not uncommon for thermal prints to completely disappear. Our document exhibits other interesting properties. For example, the faded text is visible when the page is held up to a light source. We often take transmitted light photos as part of conservation treatment documentation, so I imaged the object on top of a lightbox in a camera copy stand. This technique was pretty successful in delivering a readable image.
Radio Haiti, Transmitted light imaging
It is helpful to know that a low-tech method for reading or imaging this faded documents can be employed. It is easy to imagine library staff using a simple lightbox to identify, assess, or arrange a large collection of prints like this one.
Multispectral imaging of the letter yielded much better results. Interestingly, additional visual noise was introduced from fingerprints and hand marks on the page.
Radio Haiti, PCA with false color
Looking through the image stack, it appears the text is most legible under ultraviolet light (370nm) with a neutral filter in front of the camera.
Radio Haiti, 370nm
This result is actually quite promising when we think about scaling up an imaging project for an entire collection. Creating a full 18 image stack and processing those images takes a great deal of time; however, if we know that one frequency of light and filter combination is effective, we could easily set the imaging equipment to operate more like a normal copy stand. In this way, we could bring the requisite imaging time and storage costs closer to those of our regular imaging projects.
Many modern print types have inherent vices that cause them to fade rapidly and large collections of them are common in library archives. Advanced imaging techniques, like multispectral imaging, potentially offer opportunities to identify, arrange, and preserve volatile or unreadable prints. Creating a full image stack may not be possible for every item in a large collection, but this investigation illustrates that full MSI may not be required to achieve the needed results.
A while back, I wrote a blog post about my enjoyment in digitizing the William Gedney Photograph collection and how it was inspiring me to build a darkroom in my garage. I wish I could say that the darkroom is up and running but so far all I’ve installed is the sink. However, as Molly announced in her last Bitstreams post, we have launched the Gedney collection which includes series two series that are complete (Finished Prints and Contact Sheets) and more to come.
The newly launched site brings together this amazing body of work in a seamless way. The site allows you to browse the collection, use the search box to find something specific or use the facets to filter by series, location, subject, year and format. If that isn’t enough, we have not only related prints from the same contact sheet but also related prints of the same image. For example, you can browse the collection and click on an image of Virgil Thomson, an American composer, smoothly zoom in and out of the image, then scroll to the bottom of the page to find a thumbnail of the contact sheet from which the negative comes. When you click through the thumbnial you can zoom into the contact sheet and see additional shots that Gedney took. You even can see which frames he highlighted for closer inspection. If you scroll to the bottom of this contact sheet page you will find that 2 of those highlighted frames have corresponding finished prints. Wow! I am telling you, checkout the site, it is super cool!
What you do not see [yet], because I am in the middle of digitizing this series, is all of the proof prints Gedney produced of Virgil Thomson, 36 in all. Here are a few below.
Once the proof prints are digitized and ingested into the Repository you will be able to experience Gedney’s photographs from many different angles, vantage points and perspectives.
In the past 3 months, we have launched a number of exciting digital collections! Our brand new offerings are either available now or will be very soon. They are:
International Broadsides (added to migrated Broadsides and Ephemera collection): https://repository.duke.edu/dc/broadsides
Orange County Tax List Ledger, 1875: https://repository.duke.edu/dc/orangecountytaxlist
Radio Haiti Archive, second batch of recordings: https://repository.duke.edu/dc/radiohaiti
William Gedney Finished Prints and Contact Sheets (newly re-digitized with new and improved metadata): https://repository.duke.edu/dc/gedney
A selection from the William Gedney Photographs digital collection
In addition to the brand new items, the digital collections team is constantly chipping away at the digital collections migration. Here are the latest collections to move from Tripod 2 to the Duke Digital Repository (these are either available now or will be very soon):
What we hoped would be a speedy transition is still a work in progress 2 years later. This is due to a variety of factors one of which is that the work itself is very complex. Before we can move a collection into the digital repository it has to be reviewed, all digital objects fully accounted for, and all metadata remediated and crosswalked into the DDR metadata profile. Sometimes this process requires little effort. However other times, especially with older collection, we have items with no metadata, or metadata with no items, or the numbers in our various systems simply do not match. Tracking down the answers can require some major detective work on the part of my amazing colleagues.
Despite these challenges, we eagerly press on. As each collection moves we get a little closer to having all of our digital collections under preservation control and providing access to all of them from a single platform. Onward!
The Duke Digital Repository is a pretty nice place if you’re a file in need of preservation and perhaps some access. Provided you’re well-described and your organizational relationship to other files and collections is well understood, you could hardly hope for a better home. But what if you’re not? What if you’re an important digitized file with only collection-level description? Or what if you’re digital reproduction of an 18th century encyclopedia created by a conservator to supplement traditional conservation methods? It takes time to prepare materials for the repository. We try our best to preserve the materials in the repository, but we also have to think about the other stuff.
We may apply different levels of preservation to materials depending on their source, uniqueness, cost to reproduce or reacquire, and other factors, but the baseline is knowing the objects we’re maintaining are the same objects we were given. For that, we rely on fixity and checksums. Unfortunately, it’s not easy to keep track of a couple of hundred terabytes of files from different collections, with different organizational schemes, different owners, and sometimes active intentional change. The hard part isn’t only knowing what has changed, but providing that information to the owners and curators of the data so they can determine if those changes are intentional and desirable. Seems like a lot, right?
We’re used some great tools from our colleagues, notably ACE Audit Control Environment, for scheduled fixity reporting. We really wanted, though, to provide reporting to data owners that was tailored to they way they thought of their data to help reduce noise (with hundreds of terabytes there can be a lot of it!) and make it easier for them to identify unintentional changes. So, we got work.
That work is named FileTracker. FileTracker is a Rails application for tracking files and their fixity information. It’s got a nice dashboard, too.
What we really needed, though, was a way to disentangle the work of the monitoring application from the work of stakeholder reporting. The database that FileTracker generates makes it much easier to generate reports that contain the information that stakeholders want. For instance, one stakeholder may want to know the number of files in each directory and the difference between the present number of files and the number of files at last audit. We can also determine when files have been moved or renamed and not report those as missing files.
It’s September, and Duke students aren’t the only folks on campus in back-to-school mode. On the contrary, we here at the Duke Digital Repository are gearing up to begin promoting our research data curation services in real earnest. Over the last eight months, our four new research data staff have been busy getting to know the campus and the libraries, getting to know the repository itself and the tools we’re working with, and establishing a workflow. Now we’re ready to begin actively recruiting research data depositors!
As our colleagues in Data and Visualization Services noted in a presentation just last week, we’re aiming to scale up our data services in a big way by engaging researchers at all stages of the research lifecycle, not just at the very end of a research project. We hope to make this effort a two-front one. Through a series of ongoing workshops and consultations, the Research Data Management Consultants aspire to help researchers develop better data management habits and take the longterm preservation and re-use of their data into account when designing a project or applying for grants. On the back-end of things, the Content Analysts will be able to carry out many of the manual tasks that facilitate that longterm preservation and re-use, and are beginning to think about ways in which to tweak our existing software to better accommodate the needs of capital-D Data.
This past spring, the Data Management Consultants carried out a series of workshops intending to help researchers navigate the often muddy waters of data management and data sharing; topics ranged from available and useful tools to the occasionally thorny process of obtaining consent for–and the re-use of–data from human subjects.
Looking forward to the fall, the RDM consultants are planning another series of workshops to expand on the sessions given in the spring, covering new tools and strategies for managing research output. One of the tools we’re most excited to share is the Open Science Framework (OSF) for Institutions, which Duke joined just this spring. OSF is a powerful project management tool that helps promote transparency in research and allows scholars to associate their work and projects with Duke.
On the back-end of things, much work has been done to shore up our existing workflows, and a number of policies–both internal and external–have been met with approval by the Repository Program Committee. The Content Analysts continue to become more familiar with the available repository tools, while weighing in on ways in which we can make the software work better. The better part of the summer was devoted to collecting and analyzing requirements from research data stakeholders (among others), and we hope to put those needs in the development spotlight later this fall.
All of this is to say: we’re ready for it, so bring us your data!
In the spirit of Friday fun (and to keep with my running theme of obsolete, obscure, and endangered audio equipment,) I present this gallery of anthropomorphic electronics from Rubenstein Library’s Ad*Access digital collection. Enjoy!








































{kind=link}