

Noise is an inescapable part of our sonic environment. As I sit at my quiet library desk writing this, I can hear the undercurrent of the building’s pipes and HVAC systems, the click-clack of the Scribe overhead book scanner, footsteps from the floor above, doors opening and closing in the hallway, and the various rustlings of my own fidgeting. In our daily lives, our brains tune out much of this extraneous noise to help us focus on the task at hand and be alert to sounds conveying immediately useful information: a colleagues’s voice, a cell-phone buzz, a fire alarm.
When sound is recorded electronically, however, this tuned-out noise is often pushed to the foreground. This may be due to the recording conditions (e.g. a field recording done on budget equipment in someone’s home or outdoors) or inherent in the recording technology itself (electrical interference, mechanical surface noise). Noise is always present in the audio materials we digitize and archive, many of which are interviews, oral histories, and events recorded to cassette or open reel tape by amateurs in the field. Our first goal is to make the cleanest and most direct analog-to-digital transfer possible, and then save this as our archival master .wav file with no alterations. Once this is accomplished, we have some leeway to work with the digital audio and try to create a more easily listenable and intelligible access copy.

I recently started experimenting with Steinberg WaveLab software to clean up digitized recordings from the Larry Rubin Papers. This collection contains some amazing documentation of Rubin’s work as a civil rights organizer in the 1960s, but the ever-present hum & hiss often threaten to obscure the content. I worked with two plug-ins in WaveLab to try to mitigate the noise while leaving the bulk of the audio information intact.
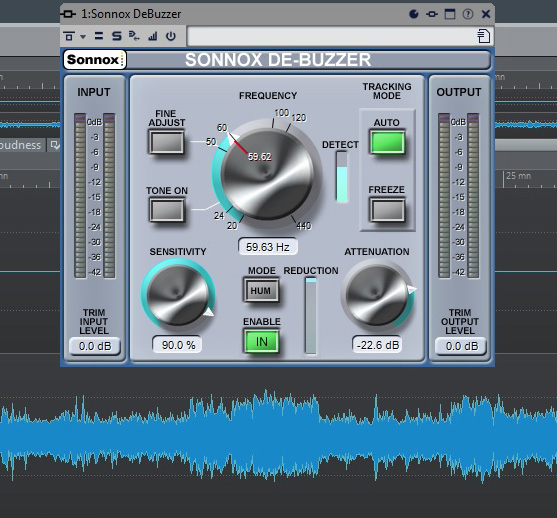
Even if you don’t know it by name, anyone who has used electronic audio equipment has probably heard the dreaded 60 Cycle Hum. This is a fixed low-frequency tone that is related to our main electric power grid operating at 120 volts AC in the United States. Due to improper grounding and electromagnetic interference from nearby wires and appliances, this current can leak into our audio signals and appear as the ubiquitous 60 Hz hum (disclaimer–you may not be able to hear this as well on tiny laptop speakers or earbuds). Wavelab’s De-Buzzer plug-in allowed me to isolate this troublesome frequency and reduce its volume level drastically in relation to the interview material. Starting from a recommended preset, I adjusted the sensitivity of the noise reduction by ear to cut unwanted hum without introducing any obvious digital artifacts in the sound.
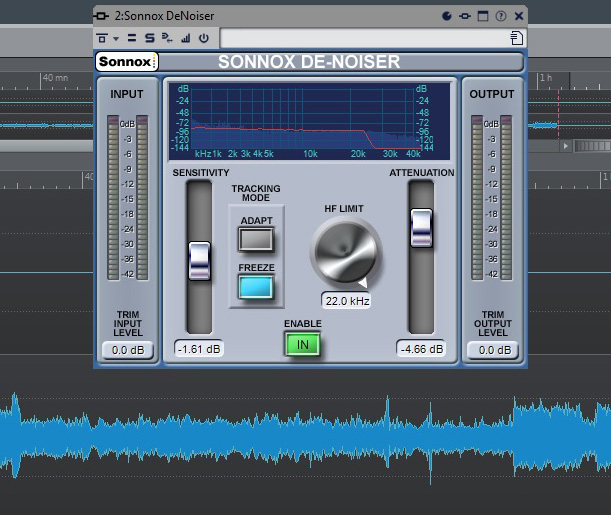
Similarly omnipresent in analog audio is High-Frequency Hiss. This wash of noise is native to any electrical system (see Noise Floor) and is especially problematic in tape-based media where the contact of the recording and playback heads against the tape introduces another level of “surface noise.” I used the De-Noiser plug-in to reduce hiss while being careful not to cut into the high-frequency content too much. Applying this effect too heavily could make the voices in the recording sound dull and muddy, which would be counterproductive to improving overall intelligibility.
Listen to the before & after audio snippets below. While the audio is still far from perfect due to the original recording conditions, conservative application of the noise reduction tools has significantly cleaned up the sound. It’s possible to cut the noise even further with more aggressive use of the effects, but I felt that would do more harm than good to the overall sound quality.
BEFORE:
AFTER:
I was fairly pleased with these results and plan to keep working with these and other software tools in the future to create digital audio files that meet the needs of archivists and researchers. We can’t eliminate all of the noise from our media-saturated lives, but we can always keep striving to keep the signal-to-noise ratio at manageable and healthy levels.































){kind=link}
{kind=link}