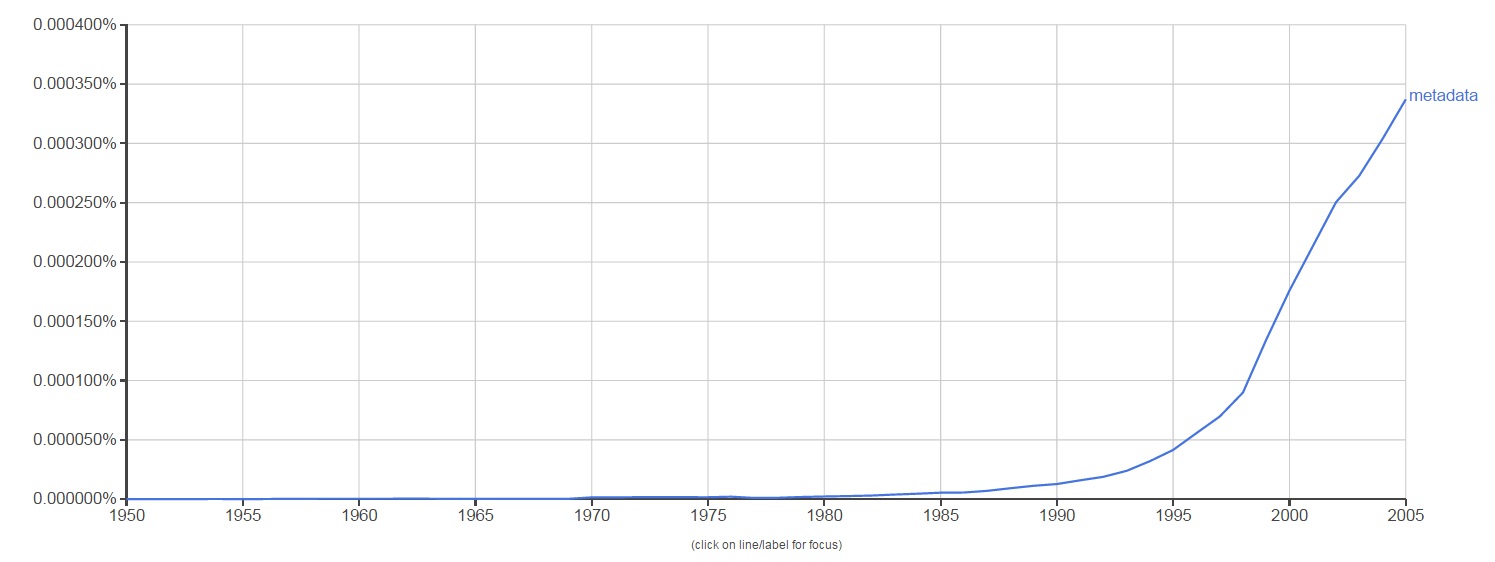The Digital Projects and Production Services is excited to announce that the 1940s and 1950s Chronicle are now digitized and accessible online at the Duke Chronicle Digital Collection. These two new decades represent the next installment in a series of releases, which now completes a string of digitized Chronicles spanning from 1940 to 1989.
Headline from December 9, 1941Army Finance Officers living at Duke, September 16, 1942
The 1940s and 1950s took Americans from WWII atrocities and scarcities to post-war affluence of sprawling suburbias, mass consumerism, and the baby boom. It marked a time of changing American lifestyles—a rebound from the Great Depression just ten years before. At Duke, these were decades filled with dances and balls and Joe College Weekends, but also wartime limitations.
Omicron Delta Kappa Fraternity Symbol, November 22, 1940
A year before the Japanese bombed Pearl Harbor, Duke lost its president of thirty years, William Preston Few. The Chronicle reported Few to be “a remarkable man” who “worked ceaselessly towards [Duke University’s] growth” during a time when it was “a small, practically unheard-of college.” While Duke may have been relatively small in 1940, it boasted a good number of schools and colleges, and a lively social scene. Sorority and fraternity events abounded in the 1940s and 1950s. So, too, did fights to overhaul the fraternity and sorority rushing systems. Social organizations and clubs regularly made the Chronicle’s front page with their numerous events and catchy names, like Hoof ‘n’ Horn, Bench ‘n’ Bar, and Shoe ‘n’ Slipper. These two decades also saw milestone celebrations, like the Chronicle’s 50th anniversary and the 25th Founders’ Day celebration.
Duke captures the wrong ram, November 13, 1942
Sports was another big headliner. In 1942, Duke hosted the Rose Bowl. Usually played in Pasadena, California, the game was moved to Durham for fear of a Japanese attack on the West Coast during World War II. The 1940s also saw the rivalry between Duke and UNC escalate into violent outbursts. Pranks became more destructive and, in 1945, concerned student leaders pleaded for a “cease-fire.” Among the pranks were cases of vandalism and theft. In 1942, Duke “ramnappers” stole what they believed to be Carolina’s ram mascot, Rameses. It was later discovered they heisted the wrong ram. In 1949, unknown assailants painted the James B. Duke statuein Carolina blue, and Duke administration warned students against retaliation. As one article from 1944 informs us, the painting of Duke property by UNC rivals was not a new occurrence, and if a Carolina painting prankster was captured, the traditional punishment was a shaved head. In an attempt to reduce the vandalism and pranks, the two schools’ student governments introduced the Victory Bell tradition in 1948 to no avail. The pranks continued into the 1950s. In 1951, Carolina stole the Victory Bell from Duke, which was returned by police to avoid a riot. It was again stolen and returned in 1952 after Duke’s victory over Carolina. That year, the Chronicle headline echoed the enthusiasm on campus: BEAT CAROLINA! I urge you to explore the articles yourself to find out more about these crazy hijinks!
The articles highlighted here are only the tip of the iceberg. The 1940s and 1950s Chronicles are filled with entertaining and informative articles on what Duke student life was like over fifty years ago. Take a look for yourself and see what these decades have to offer!
I think I speak for all of us in the Digital Collections Program when I say how excited we are to roll out this complex collection of digitized audio, video, and manuscripts that document sermons at Duke Chapel from the 1940s to early 2000s. You can now watch, listen to, and read sermons given at the Chapel by an array of preachers, including Duke Divinity faculty, and notable female and African American preachers. Many of the recordings contain full worship services complete with music by the Chapel’s 100-voice choir and four pipe organs. There are also special services, such as Martin Luther King, Jr. memorials, Good Fridays and Christmas Eves, Baccalaureates, and Convocations.
Digitization of this collection was made possible through our collaboration with Duke University’s Divinity School, Duke Chapel, University Archives, and Duke University Libraries’ Digital Collections Program. In 2015, the Divinity School received a Lilly Endowment Grant that funded the outsourcing of A/V digitization through two vendors, The Cutting Corporation and A/V Geeks, and the in-house digitization of the printed sermons. The grant will also support metadata enhancements to improve searchability and discovery, like tagging references within the recordings to biblical verses and liturgical seasons. The Divinity School will tackle this exciting portion of the project over the next two years, and their hard work will help users search deeper into the content of the collection.
Duke Chapel, September 1950
Back in 2014, digital collections program manager, Molly Bragg, announced the release of the first installation of digitized Duke Chapel Recordings. It consisted of 168 audio and video items and a newly developed video player. This collection was released in response to the high priority Duke Chapel placed on digitization, and high demand from patrons to digitize and view the materials. Fast forward two years and we have upped our game by expanding the collection to over 1,400 audio and video items, and adding more than 1,300 printed sermon manuscripts. Many of the printed sermons match up to a recording, as they are often the exact document the preacher used to deliver their sermon. The online content now represents a large percentage of the original materials held in the Duke University Archives taken from the Duke University Chapel Recordings and Duke Chapel Records collections. Many of the audio reels were not included in the scope of the project and we hope to digitize these in the near future.
Divinity student delivers practice sermon before faculty and students, undated
The Lilly Grant also provided funding to generate transcriptions of the audio-visual items, which we outsourced to Pop Up Archive, a company that specializes in creating timestamped transcripts and tags to make audio text searchable. Once the transcriptions are generated by Pop Up Archive and edited by Divinity students, they will be made available on the web interface alongside the recordings. All facets of this project support Divinity’s Duke Preaching Initiative to enhance homiletical education and pedagogy. With the release of the Duke Chapel Recordings Digital Collection, the Divinity School now has a great classroom resource to help students learn about the art of sermon writing and delivery.
The release of the Chapel Recordings marks yet another feat for the Digital Collections Program. This is the first audio-visual collection to be published in the new Tripod3 platform in conjunction with the Digital Collections migration into the Duke Digital Repository (see Will Sexton’s blog posts on the migration). Thanks to the hard work of many folks in the Digital Repository Services and Digital Projects and Production Services, this means for the user a new and squeaky clean interface to browse the collection. With the growing demand to improve online accessibility of audio-visual materials, Chapel Recordings has also been a great pilot project to explore how we can address A/V transcription needs across all our digital collections. It has presented us all with many challenges to overcome and successes to applaud along the way.
Chapel scene, 1985
If you’re not intrigued by the collection already, here are some sermon titles to lure you in!
Duke University has a long history of student activism, and the University Archives actively collects materials to document these movements. With the administration’s offices residing in the Allen Building, this is not the first time it is the center of activism activity. The Allen Building Study-In occurred November 13, 1967, the Allen Building Takeover occurred February 13, 1969, and the Allen Building Demonstration occurred in May 1970 to support the Vietnam Moratorium. In light of the current occupation of the Allen Building, we’ve compiled some digital resources you can use to find out more about the history of activism in relation to the 1969 Allen Building Takeover.
Allen Building Demonstration, 6 May 1970
The University Archives has a collection of materials from the 1969 Allen Building Takeover, which includes many digitized images available through the online finding aid. This collection also has materials from the 2002 Allen Building lock-in that commemorated 1960s activism at Duke: Guide to the Allen Building Takeover Collection, 1969-2002.
WDBS, Duke University’s campus radio station at the time of the 1969 Allen Building Takeover, also broadcasted reports on the event. Listening copies of these recordings are in the Allen Building Takeover Collection, and a list of the broadcasts can be found in the WDBS Collection: Guide to the WDBS Collection, 1949-1983.
Currently, University Archives is documenting the present Allen Building occupation, and has captured over 7,000 tweets with #DismantleDukePlantation. To ensure that Duke activism will continue to be represented in the archives, efforts will be made to collect additional materials related to the occupation.
For centuries, cultural heritage institutions—like libraries and archives—monitored the use of their collections through varying means of counting and recording. From rare manuscripts used in special collections reading rooms to the copy of Moby Dick checked out at the circulation desk, we like to keep note of who is using what. But what about those digitized special collections that patrons use more and more often? How do we monitor use of materials when they live on websites and are accessed remotely by computers, tablets, and smartphones? That’s where web analytics comes into play.
Google Analytics is by far the largest analytics aggregator today, and it is what many cultural heritage institutions turn to for data on digital collections. We can now rely on pageviews and sessions, and a plethora of other metrics, to inform us how patrons are using materials online.
Recently, I began examining the use of Duke University Archives’ digital collections to see what I could find. I quickly found that I was lost. Google Analytics is so overwhelmingly abundant with data, what I’d venture to call a statistical minefield (or ninja warrior obstacle course?), that I found myself in a fog of confusion. Don’t get me wrong, these data sets can be extremely useful if you know what you’re doing. It just took me a while to get my bearings and slowly crawl out of the fog.
With that said, if you’re interested in learning more, use every resource available to wrap your head around what Google Analytics offers and how it can help your institution. Google provides a set of tutorials at Analytics Academy. Another site, Lynda.com is a great subscription resource that may be accessible through institutional memberships. Don’t rule out YouTube either. I also learned a lot of the basics from Molly Bragg, my supervisor, who is on the Digital Library Federation Assessment Interest Group’s (DLF AIG) Analytics subcommittee. They’ve been working on a white paper to lay out digital library analytics best practices, which they hope will help steer cultural heritage institutions in the right direction.
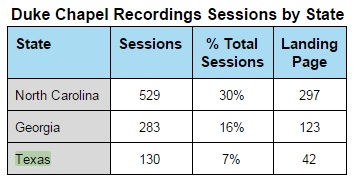
In my own experience scouring usage data from the Duke Chapel Recordings collection, I found many rather predictable results: most users come from North Carolina, Durham in particular.
But then there were strange statistics that can sometimes be hard to figure out. Like why is Texas our third highest state for traffic, with 7% of our sessions originating there?
Of Texas’ total sessions, 22% viewed webpages relating to Carlyle Marney’s sermons. For much of the 1970s, Marney was a visiting professor at Duke’s Divinity School, but this web traffic all originated in Austin, TX. Doing some internet digging, I found that in the 1940s and 1950s, Marney was a pastor and seminary professor in Austin. It is understandable why the interest in his sermons comes from a region in Texas that is likely familiar with his pastoral work.
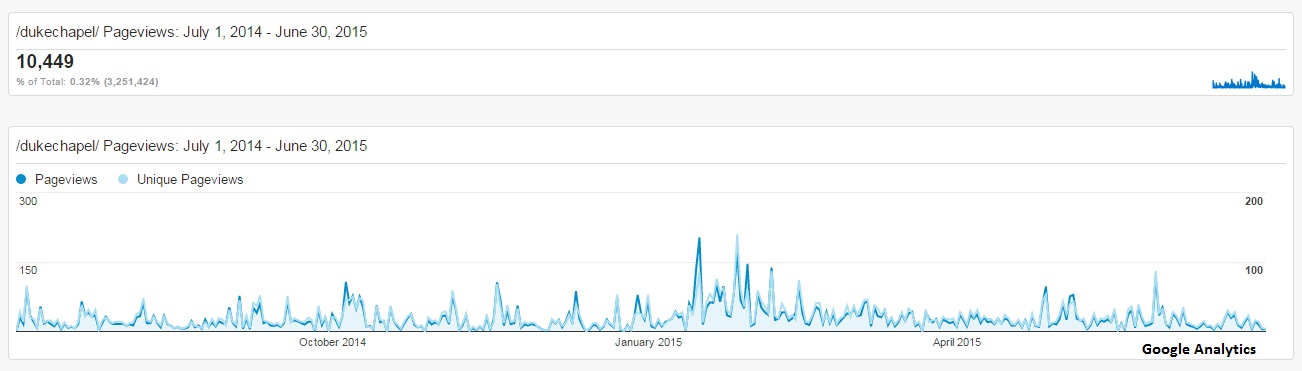
I also found that referrals from our very own Bitstreams blog make up a portion of the traffic to the collection. That explains some of our spikes in pageviews, which correspond with blog post dates. This is proof that social media does generate traffic!
Once that disorienting fog has lifted, and you have navigated the statistical minefield, you might just find that analytics can be fun. Now it doesn’t look so much like a minefield but a gold mine.
Have you found analytics useful at your cultural heritage institution? We’d love to hear from you!
Today we will take a detailed look at how the Duke Chronicle, the university’s beloved newspaper for over 100 years, is digitized. Since our scope of digitization spans nine decades (1905-1989), it is an ongoing project the Digital Production Center (DPC), part of Digital Projects and Production Services (DPPS) and Duke University Libraries’ Digital Collections Program, has been chipping away at. Scanning and digitizing may seem straightforward to many – place an item on a scanner and press scan, for goodness sake! – but we at the DPC want to shed light on our own processes to give you a sense of what we do behind the scenes. It seems like an easy-peasy process of scanning and uploading images online, but there is much more that goes into it than that. Digitizing a large collection of newspapers is not always a fun-filled endeavor, and the physical act of scanning thousands of news pages is done by many dedicated (and patient!) student workers, staff members, and me, the King Intern for Digital Collections.
Pre-Scanning Procedures
Large format 1940s Chronicles in over-sized archival box
Many steps in the digitization process do not actually occur in the DPC, but among other teams or departments within the library. Though I focus mainly on the DPC’s responsibilities, I will briefly explain the steps others perform in this digital projects tango…or maybe it’s a waltz?
Each proposed project must first be approved by the Advisory Council for Digital Collections (ACDC), a team that reviews each project for its strategic value. Then it is passed on to the Digital Collections Implementation Team (DCIT) to perform a feasibility study that examines the project’s strengths and weaknesses (see Thomas Crichlow’s post for an overview of these teams). The DCIT then helps guide the project to fruition. After clearing these hoops back in 2013, the Duke Chronicle project started its journey toward digital glory.
We pull 10 years’ worth of newspapers at a time from the University Archives in Rubenstein Library. Only one decade at a time is processed to make the 80+ years of Chronicle publications more manageable. The first stop is Conservation. To make sure the materials are stable enough to withstand digitizing, Conservation must inspect the condition of the paper prior to giving the DPC the go-ahead. Because newspapers since the mid-19th century were printed on cheap and very acidic wood pulp paper, the pages can become brittle over time and may warrant extensive repairs. Senior Conservator, Erin Hammeke, has done great work mending tears and brittle edges of many Chronicle pages since the start of this project. As we embark on digitizing the older decades, from the 1940s and earlier, Erin’s expertise will be indispensable. We rely on her not only to repair brittle pages but to guide the DPC’s strategy when deciding the best and safest way to digitize such fragile materials. Also, several volumes of the Chronicle have been bound, and to gain the best digital image scan these must be removed from their binding. Erin to the rescue!
Conservation repair on a 1940s Chronicle pageConservation repair to a torn 1940s Chronicle ad
1950s Duke Chronicle digitization guide
Now that Conservation has assessed the condition and given the DPC the green light, preliminary prep work must still be done before the scanner comes into play. A digitization guide is created in Microsoft Excel to list each Chronicle issue along with its descriptive metadata (more information about this process can be found in my metadata blog post). This spreadsheet acts as a guide in the digitization process (hence its name, digitization guide!) to keep track of each analog newspaper issue and, once scanned, its corresponding digital image. In this process, each Chronicle issue is inspected to collect the necessary metadata. At this time, a unique identifier is assigned to every issue based on the DPC’s naming conventions. This identifier stays with each item for the duration of its digital life and allows for easy identification of one among thousands of Chronicle issues. At the completion of the digitization guide, the Chronicle is now ready for the scanner.
The DPC’s Zeutschel OS 14000 A2
The Scanning Process
With all loose unbound issues, the Zeutschel is our go-to scanner because it allows for large format items to be imaged on a flat surface. This is less invasive and less damaging to the pages, and is quicker than other scanning methods. The Zeutschel can handle items up to 25 x 18 inches, which accommodates the larger sized formats of the Chronicle used in the 1940s and 1950s. If bound issues must be digitized, due to the absence of a loose copy or the inability to safely dis-bound a volume, the Phase One digital camera system is used as it can better capture large bound pages that may not necessarily lay flat.
Folders each containing multiple page images of one Chronicle issue
For every scanning session, we need the digitization guide handy as it tells what to name the image files using the previously assigned unique identifier. Each issue of the newspaper is scanned as a separate folder of images, with one image representing one page of the newspaper. This system of organization allows for each issue to become its own compound object – multiple files bound together with an XML structure – once published to the website. The Zeutschel’s scanning software helps organize these image files into properly named folders. Of course, no digitization session would be complete without the initial target scan that checks for color calibration (See Mike Adamo’s post for a color calibration crash course).
The Zeutschel’s control panel of buttonsThe Zeutschel’s optional foot pedals
The scanner’s plate glass can now be raised with the push of a button (or the tap of a foot pedal) and the Chronicle issue is placed on the flatbed. Lowering the plate glass down, the pages are flattened for a better scan result. Now comes the excitement… we can finally press SCAN. For each page, the plate glass is raised, lowered, and the scan button is pressed. Chronicle issues can have anywhere from 2 to 30 or more pages, so you can image this process can become monotonous – or even mesmerizing – at times. Luckily, with the smaller format decades, like the 1970s and 1980s, the inner pages can be scanned two at a time and the Zeutschel software separates them into two images, which cuts down on the scan time. As for the larger formats, the pages are so big you can only fit one on the flatbed. That means each page is a separate scan, but older years tended to publish less issues, so it’s a trade-off. To put the volume of this work into perspective, the 1,408 issues of the 1980s Chronicle took 28,089 scans to complete, while the 1950s Chronicle of about 482 issues took around 3,700 scans to complete.
A 1940s Chronicle page is placed on the flatbed for scanning
Scanning in progress of the 1940s Chronicle pageTarget image opened in Adobe Photoshop for color calibration
Every scanned image that pops up on the screen is also checked for alignment and cropping errors that may require a re-scan. Once all the pages in an issue are digitized and checked for errors, clicking the software’s Finalize button will compile the images in the designated folder. We now return to our digitization guide to enter in metadata pertaining to the scanning of that issue, including capture person, capture date, capture device, and what target image relates to this session (subsequent issues do not need a new target scanned, as long as the scanning takes place in the same session).
Now, with the next issue, rinse and repeat: set the software settings and name the folder, scan the issue, finalize, and fill out the digitization guide. You get the gist.
Post-Scanning Procedures
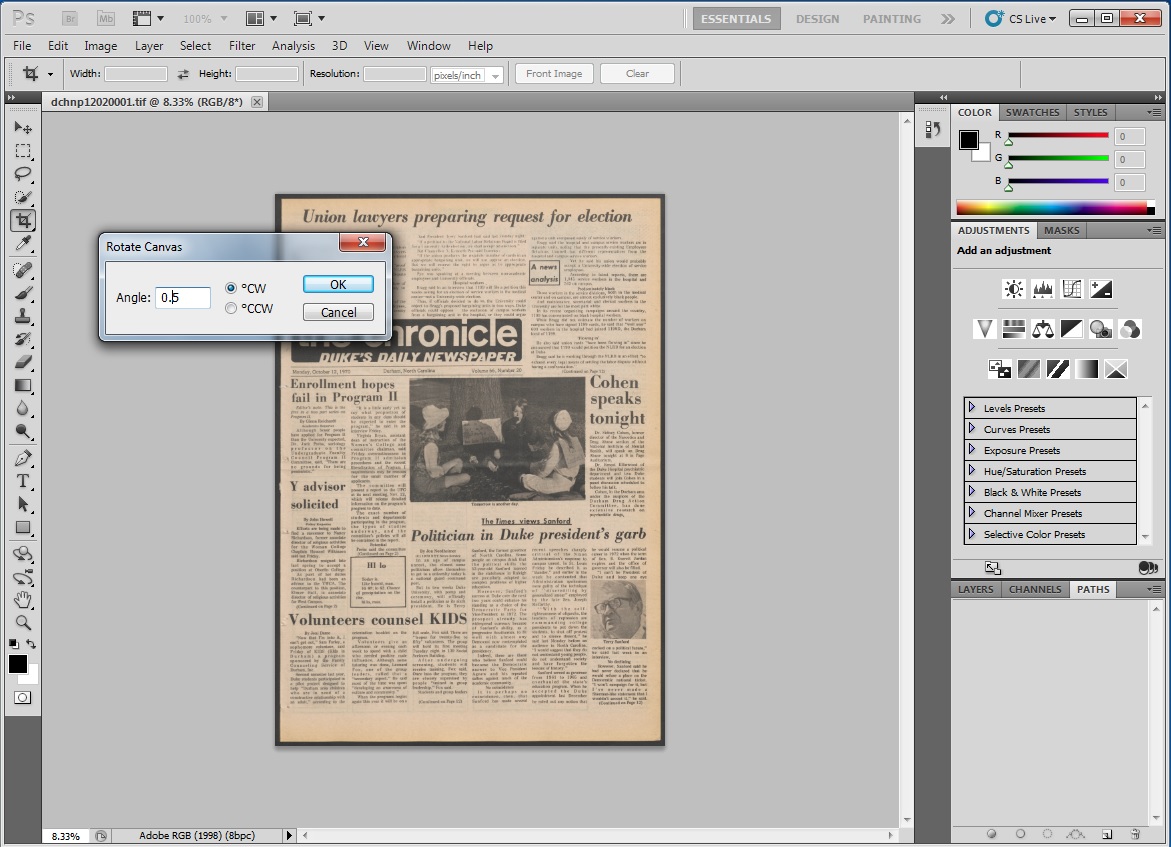
Rotating an image in Adobe Photoshop
We now find ourselves with a slue of folders filled with digitized Chronicle images. The next phase of the process is quality control (QC). Once every issue from the decade is scanned, the first round of QC checks all images for excess borders to be cropped, crooked images to be squared, and any other minute discrepancy that may have resulted from the scanning process. This could be missing images, pages out of order, or even images scanned upside down. This stage of QC is often performed by student workers who diligently inspect image after image using Adobe Photoshop. The second round of QC is performed by our Digital Production Specialist Zeke Graves who gives every item a final pass.
At this stage, derivatives of the original preservation-quality images are created. The originals are archived in dark storage, while the smaller-sized derivatives are used in the CONTENTdm ingest process. CONTENTdm is the digital collection management software we use that collates the digital images with their appropriate descriptive metadata from our digitization guide, and creates one compound object for each Chronicle issue. It also generates the layer of Optical Character Recognition (OCR) data that makes the Chronicle text searchable, and provides an online interface for users to discover the collection once published on the website. The images and metadata are ingested into CONTENTdm’s Project Client in small batches (1 to 3 years of Chronicle issues) to reduce the chance of upload errors. Once ingested into CONTENTdm, the items are then spot-checked to make sure the metadata paired up with the correct image. During this step, other metadata is added that is specific to CONTENTdm fields, including the ingest person’s initials. Then, another ingest must run to push the files and data from the Project Client to the CONTENTdm server. A third step after this ingest finishes is to approve the items in the CONTENTdm administrative interface. This gives the go-ahead to publish the material online.
Hold on, we aren’t done yet. The project is now passed along to our developers in DPPS who must add this material to our digital collections platform for online discovery and access (they are currently developing Tripod3 to replace the previous Tripod2 platform, which is more eloquently described in Will Sexton’s post back in April). Not only does this improve discoverability, but it makes all of the library’s digital collections look more uniform in their online presentation.
Then, FINALLY, the collection goes live on the web. Now, just repeat the process for every decade of the Duke Chronicle, and you can see how this can become a rather time-heavy and laborious process. A labor of love, that is.
I could have narrowly stuck with describing to you the scanning process and the wonders of the Zeutschel, but I felt that I’d be shortchanging you. Active scanning is only a part of the whole digitization process which warrants a much broader narrative than just “push scan.” Along this journey to digitize the Duke Chronicle, we’ve collectively learned many things. The quirks and trials of each decade inform our process for the next, giving us the chance to improve along the way (to learn how we reflect upon each digital project after completion, go to Molly Bragg’s blog post on post-mortem reports).
If your curiosity is piqued as to how the Duke Chronicle looks online, the Fall 1959-Spring 1970 and January 1980-February 1989 issues are already available to view in our digital collections. The 1970s Chronicle is the next decade slated for publication, followed by the 1950s. Though this isn’t a comprehensive detailed account of the digitization process, I hope it provides you with a clearer picture of how we bring a collection, like the Duke Chronicle, into digital existence.
Ah, the 1980s…a decade of perms, the Walkman, Jelly shoes, and Ziggy Stardust. It was a time of fashion statements I personally look back on in wonderment.
Personal Computer Ad, 1980
Fashionable leotards, shoulder pads, and stirrup pants were all the rage. And can we say parachute pants? Thanks, MC Hammer. If you’re craving a blast from the past, we’ve got you covered. The digitized 1980s Duke Chronicle has arrived! Now you can relive that decade of Hill Street Blues and Magnum P.I. from your own personal computer (hopefully,you’re not still using one of these models!).
As Duke University’s student-run newspaper for over 100 years, the Duke Chronicle is a window into the history of the university, North Carolina, and the world. It may even be a window into your own past if you had the privilege of living through those totally rad years. If you didn’t get the chance to live it firsthand, you may find great joy in experiencing it vicariously through the pages of the Chronicle, or at least find irony in the fact that ’80s fashion has made a comeback.
The 1980s also saw racial unrest in North Carolina, and The Duke Chronicle headlines reflected these tense feelings. Many articles illustrate a reawakened civil rights movement. From a call to increase the number of black professors at Duke, to the marching of KKK members down the streets of Greensboro, Durham, and Chapel Hill, North Carolinians found themselves in a continued struggle for equality. Students and faculty at Duke were no exception. Unfortunately, these thirty-year-old Chronicle headlines would seem right at home in today’s newspapers.
The 1980s Chronicle issues can inform us of fashion and pop culture, whether we look back at it with distaste or fondness. But it also enlightens us to the broader social atmosphere that defined the 1980s. It was a time of change and self-expression, and I invite you to explore the pages of the Duke Chronicle to learn more.
Fashion Ad, May 10, 1984
The addition of the 1980s issues to the online Duke Chronicle digital collection is part of an ongoing effort to provide digital access to all Chronicle issues from 1905 to 1989. The next decades to look forward to are the 1970s and 1950s. Also, stay tuned to Bitstreams for a more in-depth exploration of the newspaper digitization process. You can learn how we turn the pages of the Duke Chronicle into online digital gold. At least, that’s what I like to think we do here at the Digital Production Center. Until then, transport yourself back to the 1980s, Duke Chronicle style (no DeLorean or flux capacitor necessary).
Before you let your eyes glaze over at the thought of metadata, let me familiarize you with the term and its invaluable role in the creation of the library’s online Digital Collections. Yes, metadata is a rather jargony word librarians and archivists find themselves using frequently in the digital age, but it’s not as complex as you may think. In the most simplistic terms, the Society of American Archivists defines metadata as “data about data.” Okay, what does that mean? According to the good ol’ trusty Oxford English Dictionary, it is “data that describes and gives information about other data.” In other words, if you have a digitized photographic image (data), you will also have words to describe the image (metadata).
Better yet, think of it this way. If that image were of a large family gathering and grandma lovingly wrote the date and names of all the people on the backside, that is basic metadata. Without that information those people and the image would suddenly have less meaning, especially if you have no clue who those faces are in that family photo. It is the same with digital projects. Without descriptive metadata, the items we digitize would hold less meaning and prove less valuable for researchers, or at least be less searchable. The better and more thorough the metadata, the more it promotes discovery in search engines. (Check out the metadata from this Cornett family photo from the William Gedney collection.)
The term metadata was first used in the late 1960s in computer programming language. With the advent of computing technology and the overabundance of digital data, metadata became a key element to help describe and retrieve information in an automated way. The use of the word metadata in literature over the last 45 years shows a steeper increase from 1995 to 2005, which makes sense. The term became used more and more as technology grew more widespread. This is reflected in the graph below from Google’s Ngram Viewer, which scours over 5 million Google Books to track the usage of words and phrases over time.
Google Ngram Viewer for “metadata”
Because of its link with computer technology, metadata is widely used in a variety of fields that range from computer science to the music industry. Even your music playlist is full of descriptive metadata that relates to each song, like the artist, album, song title, and length of audio recording. So, libraries and archives are not alone in their reliance on metadata. Generating metadata is an invaluable step in the process of preserving and documenting the library’s unique collections. It is especially important here at the Digital Production Center (DPC) where the digitization of these collections happens. To better understand exactly how important a role metadata plays in our job, let’s walk through the metadata life cycle of one of our digital projects, the Duke Chapel Recordings.
The Chapel Recordings project consists of digitizing over 1,000 cassette and VHS tapes of sermons and over 1,300 written sermons that were given at the Duke Chapel from the 1950s to 2000s. These recordings and sermons will be added to the existing Duke Chapel Recordings collection online. Funded by a grant from the Lilly Foundation, this digital collection will be a great asset to Duke’s Divinity School and those interested in hermeneutics worldwide.
Before the scanners and audio capture devices are even warmed up at the DPC, preliminary metadata is collected from the analog archival material. Depending on the project, this metadata is created either by an outside collaborator or in-house at the DPC. For example, the Duke Chronicle metadata is created in-house by pulling data from each issue, like the date, volume, and issue number. I am currently working on compiling the pre-digitization metadata for the 1950s Chronicle, and the spreadsheet looks like this:
1950s Duke Chronicle preliminary metadata
As for the Chapel Recordings project, the DPC received an inventory from the University Archives in the form of an Excel spreadsheet. This inventory contained the preliminary metadata already generated for the collection, which is also used in Rubenstein Library‘s online collection guide.
Chapel Recordings inventory metadata
The University Archives also supplied the DPC with an inventory of the sermon transcripts containing basic metadata compiled by a student.
Duke Chapel Records sermon metadata
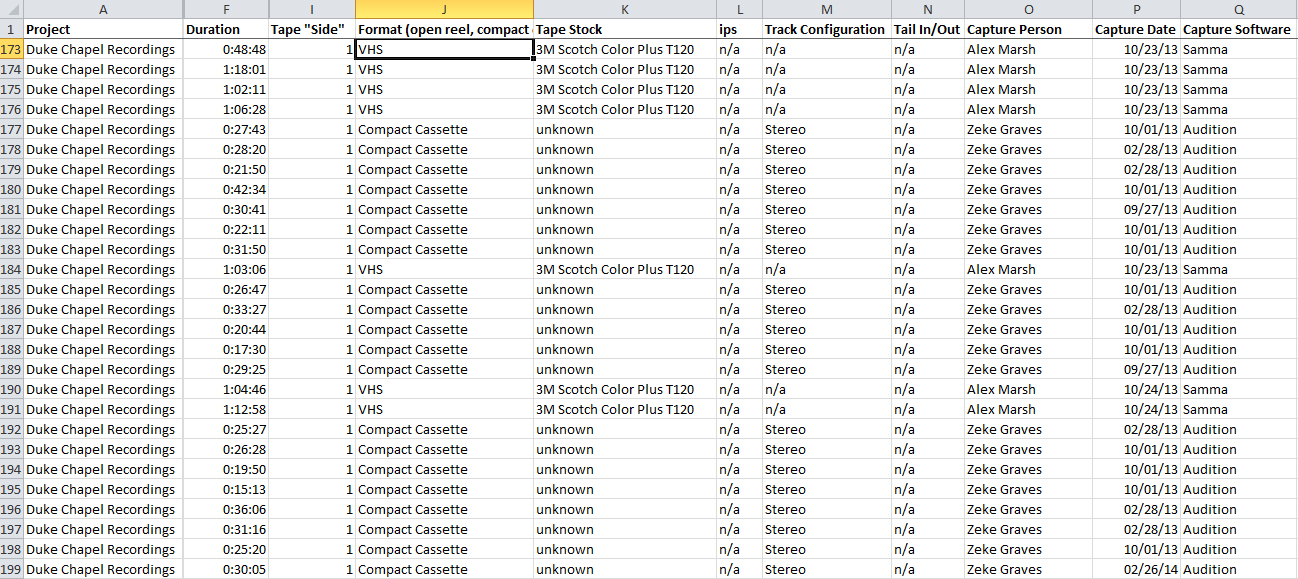
Here at the DPC, we convert this preliminary metadata into a digitization guide, which is a fancy term for yet another Excel spreadsheet. Each digital project receives its own digitization guide (we like to call them digguides) which keeps all the valuable information for each item in one place. It acts as a central location for data entry, but also as a reference guide for the digitization process. Depending on the format of the material being digitized (image, audio, video, etc.), the digitization guide will need different categories. We then add these new categories as columns in the original inventory spreadsheet and it becomes a working document where we plug in our own metadata generated in the digitization process. For the Chapel Recordings audio and video, the metadata created looks like this:
Chapel Recordings digitization metadata
Once we have digitized the items, we then run the recordings through several rounds of quality control. This generates even more metadata which is, again, added to the digitization guide. As the Chapel Recordings have not gone through quality control yet, here is a look at the quality control data for the 1980s Duke Chronicle:
1980s Duke Chronicle quality control metadata
Once the digitization and quality control is completed, the DPC then sends the digitization guide filled with metadata to the metadata archivist, Noah Huffman. Noah then makes further adds, edits, and deletes to match the spreadsheet metadata fields to fields accepted by the management software, CONTENTdm. During the process of ingesting all the content into the software, CONTENTdm links the digitized items to their corresponding metadata from the Excel spreadsheet. This is in preparation for placing the material online. For even more metadata adventures, see Noah’s most recent Bitstreams post.
In the final stage of the process, the compiled metadata and digitized items are published online at our Digital Collections website. You, the researcher, history fanatic, or Sunday browser, see the results of all this work on the page of each digital item online. This metadata is what makes your search results productive, and if we’ve done our job right, the digitized items will be easily discovered. The Chapel Recordings metadata looks like this once published online:
Chapel Recordings metadata as viewed online
Further down the road, the Duke Divinity School wishes to enhance the current metadata to provide keyword searches within the Chapel Recordings audio and video. This will allow researchers to jump to specific sections of the recordings and find the exact content they are looking for. The additional metadata will greatly improve the user experience by making it easier to search within the content of the recordings, and will add value to the digital collection.
On this journey through the metadata life cycle, I hope you have been convinced that metadata is a key element in the digitization process. From preliminary inventories, to digitization and quality control, to uploading the material online, metadata has a big job to do. At each step, it forms the link between a digitized item and how we know what that item is. The life cycle of metadata in our digital projects at the DPC is sometimes long and tiring. But, each stage of the process creates and utilizes the metadata in varied and important ways. Ultimately, all this arduous work pays off when a researcher in our digital collections hits gold.
Fifty years ago this week, Duke students faced off with computers in model car races and tic-tac-toe matches in the annual Engineers’ Show. In stark contrast to the up-and-coming computers, a Duke Chronicle article dubbed these human competitors as old-fashioned and obsolete. Five decades later, although we humans haven’t completely lost our foothold to computers, they have become a much bigger part of our daily lives than in 1965. Yes, there are those of you out there who fear the imminent robot coup is near, but we mostly have found a way to live alongside this technology we have created. Perhaps we could call it a peaceful coexistence.
Zeutschel Overhead Scanner
At least, that’s how I would describe our relationship to technology here at the Digital Production Center (DPC) where I began my internship six weeks ago. We may not have the entertaining gadgets of the Engineers’ Show, like a mechanical swimming shark or mechanical monkey climbing a pole, but we do have exciting high-tech scanners like the Zeutschel, which made such instant internet access to articles like “Man To Fight Computers” possible. The university’s student newspaper has been digitized from fall 1959 to spring 1970, and it is an ongoing project here at the DPC to digitize the rest of the collection spanning from 1905 to 1989.
My first scanning project has been the 1970s Duke Chronicle issues. While standing at the Zeutschel as it works its digitization magic, it is fascinating to read the news headlines and learn university history through pages written by and for the student population. The Duke Chronicle has been covering campus activities since 1905 when Duke was still Trinity College. Over the years it has captured the evolution of student life as well as the world beyond East and West Campus. The Chronicle is like a time capsule in its own right, each issue freezing and preserving moments in time for future generations to enjoy. This is a wonderful resource for researchers, history nerds (like me!), and Duke enthusiasts alike, and I invite you to explore the digitized collection to see what interesting articles you may find. And don’t forget to keep checking back with BitStreams to hear about the latest access to other decades of the Duke Chronicle.
DukEngineer, The College of Engineering magazine, covered this particular Engineers’ Show in their April 1965 issue.
The year 1965 doesn’t seem that distant in time, yet in terms of technological advancement it might as well be eons away from where we are now. Playing tic-tac-toe against a computer seems arcane compared to today’s game consoles and online gaming communities, but it does put things into perspective. Since that March day in 1965, it is my hope that man and computer both have put down their boxing gloves.
Notes from the Duke University Libraries Digital Projects Team