As our long-term readers of Bitstreams will attest, the Duke Digital Collections program has an established and well-earned reputation as a trailblazer when it comes to introducing new technologies, improved user interfaces, high definition imaging, and other features that deliver digital images with a beauty and verisimilitude true to the originals held by the David M. Rubenstein Rare Book & Manuscript Library. Thus, we are particularly proud to launch today our newest feature, Smell-O-Bit, which adds a whole new dimension to the digital collections experience.
Smell-O-Bit is a cutting-edge technology that utilizes the diffusers built into most recent model computers to emit predefined scents associated with select digital objects within the Duke Digital Collections site. While still in a test phase, the Digital Collections team has already tagged several images with scents that evoke the mood or content of key images. To experience the smells, simply select Ctl-Alt-W-Up- while viewing these test images:
A bold scent for a bold product, Pabst-ett cheese!
Made by the Pabst brewing company while beer was off limits due to Prohibition, Pabst-ett cheese was soft, spreadable, and comfort-food delicious. We’ve selected a bold, tangy scent to highlight these comforts. The scent may make you happy enough to slap your own cheeks!
The smell of late a night chess match.
The smell of cigarette smoke, margaritas, and salt from around glass rims and chess players’ brows will make you feel as if you have front row seating at this chess match between composer John Cage and a worthy, but anonymous opponent.
A scent strong enough to eat!
You may feel yourself overwhelmed with the wafting scent of char-broiled deliciousness, but don’t forget to take a deep inhale to detect the pickles, ketchup, and mustard which makes this a savory image all around.
Perhaps you smell garbage? If so, your Garbex isn’t working! What about flies, cats, or dogs? Or, perhaps you just smell a rat. Alright, you caught us.
Happy April Fool’s Day from Duke Digital Collections!!
Over the past year and a half, among our many other projects, we have been experimenting with a creative new approach to powering searches within digital collections and finding aids using Google’s index of our structured data. My colleague Will Sexton and I have presented this idea in numerous venues, most recently and thoroughly for a recorded ASERL (Association of Southeastern Research Libraries) webinar on June 6, 2013.
We’re eager to share what we’ve learned to date and hope this new blog will make a good outlet. We’ve had some success, but have also encountered some considerable pitfalls along the way.
What We Set Out to Do
I won’t recap all the fine details of the project here, but in a nutshell, here are the problems we’ve been attempting to address:
Maintaining our own Solr index takes a ton of time to do right. We don’t have a ton of time.
Staff have noted poor relevance rank and poor support for search using non-Roman characters.
Our digital collections search box is actually used sparsely (in only 12% of visits).
External discovery (e.g., via Google) is of equal or greater importance vs. our local search for these “inside-out” resources.
Get Google to index all of our embedded structured data
Use Google’s index of our structured data to power our local search for finding aids & digital collections
Where We Are Today
We mapped several of our metadata fields to schema.org terms, then embedded that schema.org data in all 74,000 digital object pages and all 2,100 finding aids. We’re now using Google’s index of that data to power our default search for:
Though the strategy is the same, some of the implementation details are different between our finding aids and digital collections applications. Here are the main differences:
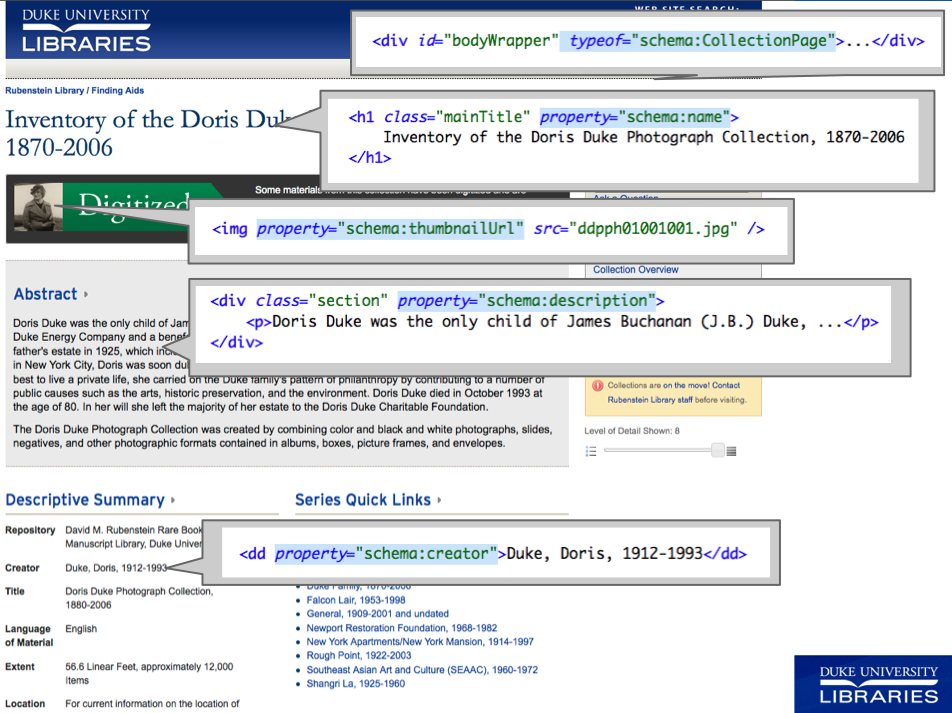
Embedding the Data. We kept it super simple here. We labeled every finding aid page a ‘CollectionPage’ and tagged only a few properties: name, description, creator, and if present, a thumbnailUrl for a collection with digitized content.
Schema.org tags using RDFa Lite in finding aid HTML
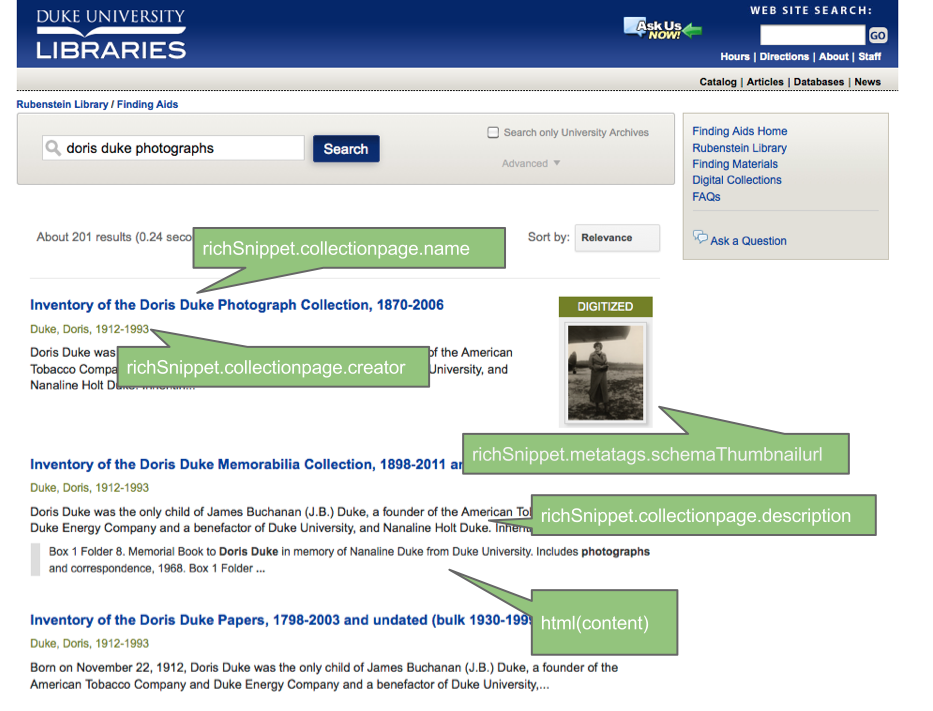
Rendering Search Results Using Google’s Index.
This worked great. We used a Google Custom Search Element (CSE) and created our own “rich snippets” using the CSE JavaScript API (v1.0) and the handy templating options Google provides. You can simply “View Source” to see the underlying code: it’s all there in the HTML. The HTML5 data- attributes set all the content and the display logic.
Google Javascript objects used in search result snippet presentation.
Digital Collections Search: Sidney D. Gamble Collection
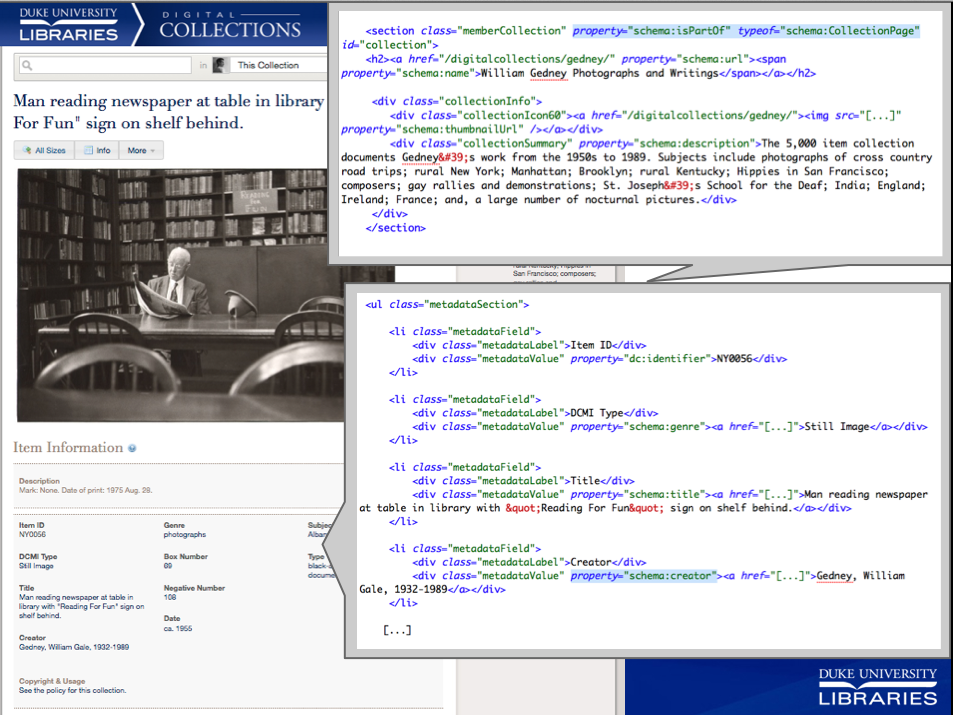
Embedding the Data.
Our digital collections introduce more complexity in the structured data than we see in our finding aids. Naturally, we have a wide range of item types with diverse metadata. We want our markup to represent the relationship of an item to its source collection. The item, the webpage that it’s on, the collection it came from, and the media files associated with it all have properties that can be expressed using schema.org terms. So, we tried it all.[1]
Example Schema.org tags used in item pages
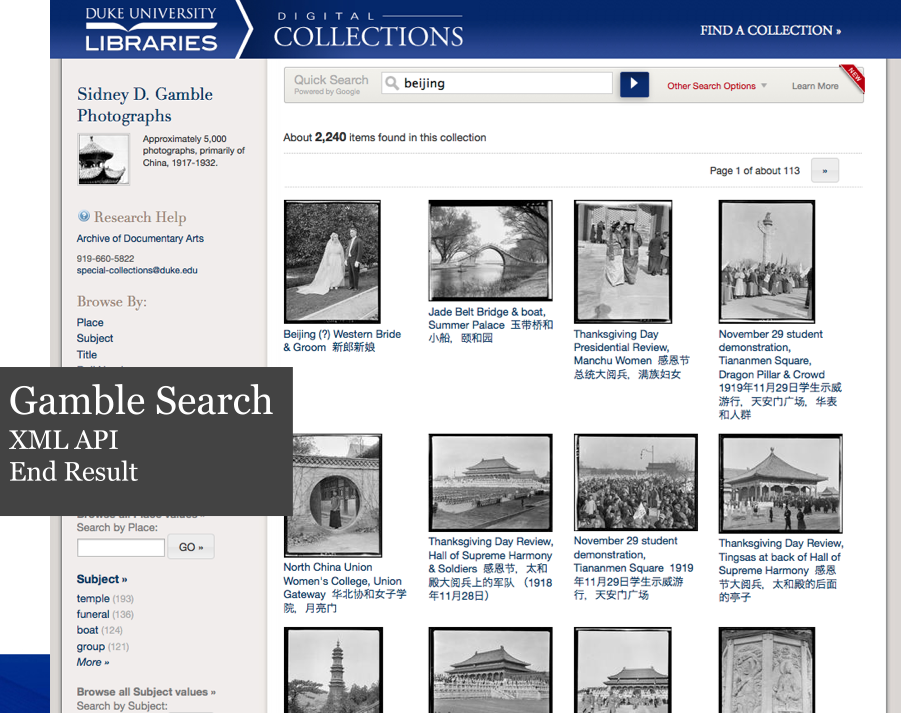
Rendering Search Results Using Google’s Index.
For the Gamble collection, we succeeded in making queries hit Google’s XML API while sustaining the look of our existing search results. Note that the facets in the left side aren’t powered via Google–we haven’t gotten far enough in our experiment to work with filtering the result set based on the structured data, but that’s possible to do.
Search result rendering using Google’s XML API
Outcomes
The Good
We’ve been pleased with the ability to make our own rich snippets and highly customize the appearance of search results without having to do a ton of development. Getting our structured data back from Google’s index to work with is an awesome service and developing around the schema.org properties that we were already providing has been a nice way to kill two birds with one stone.
For performance, Google CSE is working well in both the finding aids and the Gamble digital collection search for these purposes:
getting the most relevant content presented early on in the search result
getting results quickly
handling non-Roman characters in search terms
retrieving a needle in a haystack — an item or handful of items that contain some unique text
The Gotchas
While Google CSE shows relevant results quickly, we’re finding it’s not a good fit for exploratory searching when either of these aspects is important:
getting a stable and precise count of relevant results
browsing an exhaustive list of results that match a general query
Be careful: queries max out at 100 results with the JavaScript APIs or 1,000 results when using the XML API. Those limits aren’t obvious in the documentation, yet they might be a deal-breaker for some potential uses.
For queries with several pages of hits, you may get an estimated result count that’s close, but unfortunately things occasionally and inexplicably go sour as you navigate from from one result page to the next. E.g., the Gamble digital collection query ‘beijing‘ shows about 2,100 results (which is in the ballpark of what Solr returns), yet browse a few pages in and the result set will get truncated severely: you may only be able to actually browse about 200 of the results without issuing more specific query terms.
Other Considerations
Impact on External Discovery
Traffic to digital collections via external search engines has mostly climbed steadily every quarter for the past few years, from 26% of all visits in Jul-Sep 2011 up to 44% from Jan-Mar 2014 (to date) [2]. We entered schema.org tags in Oct 2012, however we don’t know whether adding that data has contributed at all to this trend. Does schema.org data impact relevance? It’s hard to tell.
Structured Data Syntax + Google APIs
Though RDFa Lite and microdata should be equally acceptable ways to add schema.org tags, Google’s APIs actually work better with microdata if there are nested item types.[3] And regardless of microdata or RDFa, the Google CSE JavaScript API unfortunately can’t access more than one value for any given property, so that can be problematic [4].
Rich Snippets in Big Google
We’re seeing Google render rich snippets for our videos, because we’ve marked them as schema.org VideoObjects with properties like thumbnailUrl. That’s encouraging! Perhaps someday Google will render better snippets for things like photographs (of which we have a bunch), or maybe even more library domain-specific materials like digitized oral histories, manuscripts, and newspapers. But at present, none of our other objects seem to trigger nice snippets like this.
A rich snippet triggered by using schema.org videoObject type & thumbnailUrl property.
Footnotes
[1] We represented item pages as schema.org “ItemPage” types using the “ispartOf” property to relate the item page to its corresponding “CollectionPage”. We made the ItemPage “about” a “CreativeWork”. Then we created mappings for many of our metadata fields to CreativeWork properties, e.g., creator, contentLocation, genre, dateCreated.
[2] Digital Collections External Search Traffic by Quarter
Quarter Visits via Search % Visits via Search
Jul – Sep 2011 26,621 25.97%
Oct – Dec 2011 32,191 29.59%
Jan – Mar 2012 41,048 32.16%
Apr – Jun 2012 33,872 34.49%
Jul – Sep 2012 28,250 32.40%
Oct – Dec 2012 38,472 36.52% <– entered schema.org tags Oct 19, 2012
Jan – Mar 2013 39,948 35.29%
Apr – Jun 2013 36,641 38.30%
Jul – Sep 2013 35,058 41.88%
Oct – Dec 2013 46,082 43.98%
Jan – Mar 2014 47,123 43.93%
[3] For example, if your RDFa indicates that “an ItemPage is about a CreativeWork whose creator is Sidney Gamble”– the creator of the creative work is not accessible to the API since the CreativeWork is not a top-level item. To get around that, we had to duplicate all the CreativeWork properties in the HTML <head>, which is unnatural and a bit of a hack.
[4] Google’s CSE JS APIs also don’t let us retrieve the data when there are multiple values specified for the same field. For a given CreativeWork, we might have six locations that are all important to represent: China; Beijing (China); Huabei xie he nu zi da xue (Beijing, China); 中国; 北京; 华北协和女子大学. The JSON returned by the API only contains the first value: ‘China’. This, plus the result count limit, made the XML API our only viable choice for digital collections.
I have worked in the Digital Production Center since March of 2005 and I’ve seen a lot of digital collections published in my time here. I have seen so many images that sometimes it is difficult to say which collection is my favorite but the Sidney D. Gamble Photographs have always been near the top.
The Sidney D. Gamble Photographs are an amazing collection of black and white photographs of daily life in China taken between 1908 and 1932. These documentary style images of urban and rural life, public events, architecture, religious statuary, and the countryside really resonate with me for their unopposed moment in time feel. Recently the Digital Collections Implementation Team was tasked with digitizing a subset of lantern slides from this collection. What is a lantern slide you might ask?
Herding Ducks
A lantern slide is a photographic transparency which is glass-mounted and often hand-colored for projection by a “magic lantern.” The magic lantern was the earliest form of slide projector which, in its earliest incarnation, used candles to project painted slides onto a wall or cloth screen. The projectionist was often hidden from the audience making it seem more magical. By the time the 1840s rolled around photographic processes had been developed by William and Frederick Langenheim that enabled a glass plate negative to be printed onto another glass plate by a contact method creating a positive. These positives were then painted in the same fashion that the earlier slides were painted (think Kodachrome). The magic lantern predates the school slate and the chalkboard for use in a classroom.
After working with and enjoying the digitization of the nitrate negatives from the Sidney D. Gamble Photographs it has been icing on the cake to work with the lantern slides from the same collection so many years later. While the original black and white images resonate with me the lantern slides have added a whole new dimension to the experience. On one hand the black and white images lend a sense of history and times passed and on the other, the vivid colors of the lantern slides draw me into the scene as if it were the present.
Barbers on Bund
I am in awe of the amount of work and the variety of skill sets required to create a collection such as this. Sidney D. Gamble, an amateur photographer, to trek across China over 4 trips spanning 24 years, photographing and processing nitrate negatives in the field without a traditional darkroom, all the while taking notes and labeling the negatives. Then to come home and create the glass plate positives and hand color over 500 of them. For being an “amateur photographer” Gamble’s images are striking. The type of camera he used takes skill and knowledge to create a reasonably correct exposure. Processing the film is technically challenging in a traditional darkroom and is made much more difficult in the field. Taking enough notes while shooting, processing and traveling so they make sense as a collection is a feat in itself. The transfer from negative film to positive glass plates on such a scale is a tedious and technical venture. Then to hand paint all of the slides takes additional skill and tools. All of this makes digitization of the material look like child’s play.
An inventory of the hand-colored slides was created before digitization began. Any hand-colored slides with existing black and white negatives were identified so they can be displayed together online. A color-balanced light box was used to illuminate the lantern slides and a Phase One P65 Reprographic camera was used in conjunction with a precision Kaiser copy stand to capture them. All of the equipment used in the Digital Production Center is color-calibrated and profiled so consistent results can be achieved from capture to capture. This removes the majority of the subjective decision making from the digitization process. Sidney D. Gamble had many variables to contend with to produce the lantern slides much like the Digital Collections Implementation Team deals with many variables when publishing a digital collection. From conservation of the physical material, digitization, metadata, interface design to the technology used to deliver the images online and the servers and network that connect everything to make it happen, there are plenty of variables. They are just different variables.
Nowadays we photograph and share the minutia of our lives. When Sidney Gamble took his photographs he had to be much more deliberate. I appreciate his deliberateness as much as I appreciate all the people involved in publishing collections. I look forward to publication of the Sidney D. Gamble lantern slides in the near future and hope you will enjoy this collection as much as I have over the years.
I joined the digital collections team in early December 2013, and from day 1 I have been immersed in the details of our long list of unique projects, all with their own set of schedules, stakeholders, and resource needs. My task has also been to evaluate and improve our overall workflow, create outreach and promotional opportunities (like this blog!), and really anything else that comes up that is related to digital projects. What does that all mean in terms of day-to-day work? It means I attend A LOT of meetings.
Just another day in the Digital Production Center imaging the Haitian Declaration of Independence!
Luckily most of my meetings are absolutely fascinating and revolve around very exciting projects and materials. Here are some of my favorite meetings from the last few weeks. Truth be told, I didn’t go to all of these in one day, but they are a pretty representative sample of the types of meetings I do attend everyday.
Haitian Declaration of Independence: Perhaps you have heard that the Rubenstein library has a copy of this historic document? The digital collections implementation team recently met with RL curator Will Hansen to discuss digitizing and providing access to the declaration, and of course he brought it with him. Its not that large to be honest, but very impressive. In DPPS we are using this project as catalyst to implement an image server and a new document viewing tool to provide better access to documents like the declaration.
“Girl Lost in Thought at Fast Food Counter” Image from the William Gedney Digital Collection
Workflows, Workflows, workflows: Every week I attend operational meetings with both the Duke Digital Collections Implementation teams and the Digital Production Center to discuss work in progress, scheduling, new projects, and how to perfect our ever changing workflows. I presented, along with my colleagues from Digital Projects and Production Services as part of our monthly ITS meeting, First Wednesday, on our overall process and some of the changes we have been making since I came on board. Check out all of our slides!
Gedney: Duke Digital Collections patrons are no strangers to the William Gedney Photographs and Writings digital collection. The physical collection is being re-processed and we will be digitizing more of it later in 2014. This is a large project with a long timeline, but we are so excited to provide access to more materials in one of our most popular digital collections.
Early Greek MS: the Rubenstein Library has a large collection of early Greek manuscripts. Many items have already been digitized, and Rubenstein Technical Services is in the process of cataloging them. Once cataloging is complete, we will be able to plan the publishing aspects of this project. Both DPPS and our colleagues in the Collaboratory for Classics Computing are thrilled to provide access to digital versions of these items.
Stay tuned for continuing developments in these and all the other projects we have in progress!
A scanned image from one of the Greek Manuscripts in the Rubenstein collection.
Today marks the beginning of Spring Break 2014 for Duke students! We recognize that Spring Break is normally a time of quiet reflection, but for those interested in getting away this week, we’d like to offer some travel tips courtesy of our historic advertising collections. There’s still time to plan your trip! Let’s get started.
If efficiency is more your thing, travel by air to get to your destination a little faster, because, as American Airlines reminds us, “air is everywhere.” Still not convinced? Take United Airline’s advice: “All the Important People Fly nowadays.”
Compared to buses and trains, modern air travel offers such an abundance of options and amenities. For an authentic Spring Break experience, you could reserve a seat on Resort Airline’s “Flying Houseparty” to the Caribbean or maybe grab a beverage in Continental Airline’s Coach Pub in the Sky as featured in the commercial below.
If you’re looking for something a bit more refined, be sure to book a flight on United where master chefs demonstrate their “cosmopolitan artistry in the finest meals aloft” and where your flight attendant is guaranteed to meet United’s strict qualifications for employment (gender, age, height, weight, and marital status).
What to Take
Whether you travel by air, train, or bus, you’ll want to pack only the essentials for your Spring Break getaway. Start with Dr. West’s Travel Kit, which includes toothpaste and a mini-toothbrush in a “handsome sanitary glass container,” all for just 50 cents. Be sure to include a bottle of Kreml Shampoo as well so you don’t get caught with embarrassing vacation hair.
Just because you’re traveling doesn’t mean you need to leave your entertainment at home. “Lead the Vacation Fun Parade” by packing super-tiny, ultra-compact Zenith portable radios (only 5 1/2 pounds!).
Finally, if you’re overwhelmed by too many travel options and would rather stay home, avoid the crowds, and spend your money elsewhere this Spring Break, treat yourself to something special: It’s Spring, Get a Pontiac.
Staff from the Digital Projects and Production Services Department – the proprietors of this blog – presented at the Library’s First Wednesday forum on March 6. Here are the slides from the four presenters.
Duke Digital Collections is excited to announce our newest digital collection: Duke Chapel Recordings!
This digital collection consists of a selection of audio and video recordings from the extensive collection of Duke University Chapel recordings housed in the Duke University Archives, part of the David M. Rubenstein Rare Book & Manuscript Library. The digital collection features 168 audio and video recordings from the chapel including sermons from notable African American and female preachers. This project has been a fruitful collaboration between Duke Chapel, the Divinity School, the Rubenstein Library and of course the digital projects team in Duke University Libraries. To learn more, visit the Devil’s Tale blog (the blog of the Rubenstein Library).
But wait, there’s more!
Brenda Kirton speaks in this still from one of the Duke Chapel Recordings digital collection.
Fifteen of the recordings were digitized from VHS tapes and are available as video playable from within the digital collection. These are our first digitized videos delivered via our own infrastructure. Our previous efforts have all relied on external platforms like YouTube, iTunes, and the Internet Archive to serve up the videos. While these tools are familiar to users, feature-rich, and built on a strong technological backbone, we have been intending for quite awhile to develop support for delivering digital video in-house.
When you view a video from the Duke Chapel Recordings, you’ll see a “poster frame” image of the featured speaker. Click the play button to begin (of course!) and the video will play within the page. Watching the videos is a “pseudo-streaming” or “progressive download” experience akin to YouTube. That is, you can start watching almost immediately, and you can click ahead to arbitrary points in the middle of the video at any time. And while you might occasionally have to wait for things to buffer, videos should play smoothly on desktop, tablet, and smartphone devices, and can be easily enlarged to full-screen. Finally, there’s a Download link right below the video if you’d like to take the files with you.
Behind the scenes, we are using the robust JW Player tool, for which the Pro version was recently made available by site-license to the Duke community by our friends in the Office of Information Technology. JW Player is media player software that uses a combination of HTML5 video and Javascript. It can play video from a streaming server, but as in our case, it can also pseudo-stream video over HTTP via a standard web server. Using HTML5 video, the browser requests and receives only the chunks of the video file that it needs as it plays. Almost all of the major modern browsers support HTML5 video delivering H.264/AAC MP4 content (our video encoding of choice), and a peek at our use statistics indicates that more than 80% of our users visit our site with these browsers. For the rest, JW Player renders a nearly identical media player using Adobe Flash.
We’re looking forward to hearing from our users and learning from our peers who are working with digital media to keep refining our approach. We hope to make many more videos from our collections available in the near future.
The 310 oral histories that comprise the newly published additions to the Behind the Veil digital collection were originally recorded in the 1990’s to the now (nearly) obsolete compact cassette format—what were commonly called “tapes”. The beauty of the compact cassette format was that it was small and portable (especially compared to the earlier reel-to-reel tape format), relatively durable due to its hard plastic outer shell, and most of all—could easily be recorded to at home by non-professional users. This made it perfect for oral historians who needed to be able to record interviews in the field at low cost with minimal hassle.
Unfortunately, the compact cassette format hasn’t aged particularly well. Due to cheap materials, poor storage conditions, and normal mechanical wear and tear, many of these tapes are already borderline unplayable a short 40 years after their first introduction. This introduces a number of challenges to our process of converting the audio information on the tapes into a digital file format that can easily be accessed online by patrons. I won’t exhaustively detail our digitization process here, but only touch on a few issues and how we dealt with them.
Our fearless audio digitization expert carefully inspects a tapes.
Physical degradation and damage to tapes: We visually inspected each tape prior to digitization. Any that were visibly broken or had twisted or jammed tape were rehoused in new outer shells. At least with this collection, rehousing allowed us to successfully play back all of the tapes.
Poor quality of original recordings: We also did a brief audio inspection of each tape before digitization. This allowed us to identify issues with audio quality. We found that the interviews were done in a wide variety of locations, often with background traffic, television, appliance and conversation noise bleeding into the recording. There was no easy fix for this, as these issues are inherent in the recording. Our solution was to provide the best possible playback on a high-quality cassette deck, a direct and balanced signal path, and high quality analog-to-digital conversion at the preservation standard of 24 bits, 96.1 kHz. This ensured that the digital copy faithfully reproduced the audio material on the cassette, warts and all.
Other errors in original recordings: There were some issues in the original recordings that we opted to fix via digital editing or processing in our files for patron use (while retaining the unaltered preservation files).
In cases where there was a significant gap of silence in the middle of a tape, we edited out the silence for continuity’s sake.
In cases where there were loud and abrasive clicks, pops, or microphone noise at the beginning or end of a tape side, we edited out these noises.
Several tapes were apparently recorded at the wrong speed, resulting in a “chipmunk voice” effect. I used a Speed/Pitch function in our audio capture software to electronically slow these files down so that they play back intelligibly and as intended.
Audio digitization deck
Another challenge, common to all time-based analog media, is the cassette tape’s “real-time” nature. Unlike a digital file that can be copied nearly instantaneously, a 90-minute cassette tape actually takes 90 minutes to make a digital copy. Currently we run two cassette decks simultaneously, allowing us to double our throughput.
As you can see, audio cassette digitization is more than just a matter of pressing “play”!
–post written by Zeke Graves
Still want to learn more about the Behind the Veil collection of oral histories? Check out coverage of the collection over at Rubenstein Library blog, The Devil’s Tale.
When users see the phrase “Digital Collections” how are they to know it’s where they’ll find these photos of Fidel Castro looking in his fridge for leftovers? We have a problem with “Digital Collections.” It’s a phrase that’s exclusive to libraries and librarians, mysterious to patrons and web site users, and inadequate for its purpose. It describes what it references with about the same precision that “athletic endeavor” describes a Duke-UNC basketball game.
Yet it seems a given that libraries use the phrase to refer to their online installations of digitized primary sources from unique or rare collections. I remember talking about “digital collections” when I was a graduate student in Information and Library Science in the 1990s; the phrase just seemed to stick in our field, despite having almost no meaning outside of it.
We use it at Duke, and our usability studies show time and again that it’s one of the least understood things on our web site. People tend to be excited when they find our collections and understand what they are. We just seem to have a problem providing the context they need to get there.
I don’t have the answer to the problem today, but I’ve begun to do some thinking on how libraries cue web site users on their digitized collections, how we describe the resources, and how we might better convey what we’re doing for our audience. At Duke, we’re preparing to update our design for our “Digital Collections,” and my hope is that when we’ve finished, we’re calling it something entirely different.
Your Duke Digital Collections team, as well as most of the rest of the university have been locked down at home for the past two days due to snow, ice and the dreaded “wintry mix”. If you, like us are looking for ways to entertain yourself and celebrate Valentine’s Day, you are in luck!
Among the treasures in the Emergence of Advertising digital collection, we have a cookbook specially designed to help you plan and execute meals for all holiday occasions from children’s parties to, you guessed it, Valentines Day! Check out some of the recipes below.






 Over the past year and a half, among our many other projects, we have been experimenting with a creative new approach to powering searches within digital collections and finding aids using Google’s index of our structured data. My colleague Will Sexton and I have presented this idea in numerous venues, most recently and thoroughly for a recorded ASERL (Association of Southeastern Research Libraries)
Over the past year and a half, among our many other projects, we have been experimenting with a creative new approach to powering searches within digital collections and finding aids using Google’s index of our structured data. My colleague Will Sexton and I have presented this idea in numerous venues, most recently and thoroughly for a recorded ASERL (Association of Southeastern Research Libraries)