Let me tell you something people: Coordinating development of the Duke Digital Repository (DDR) is a crazy logistical affair that involves much ado about… well, everything!
My last post, What is a Repository?, discussed at a high level, what exactly a digital repository is intended to be and the purpose it plays in the Libraries’ digital ecosystem. If we take a step down from that, we can categorize the DDR as two distinct efforts, 1) a massive software development project and 2) a complex service suite. Both require significant project management and leadership, and necessitate tools to help in coordinating the effort.
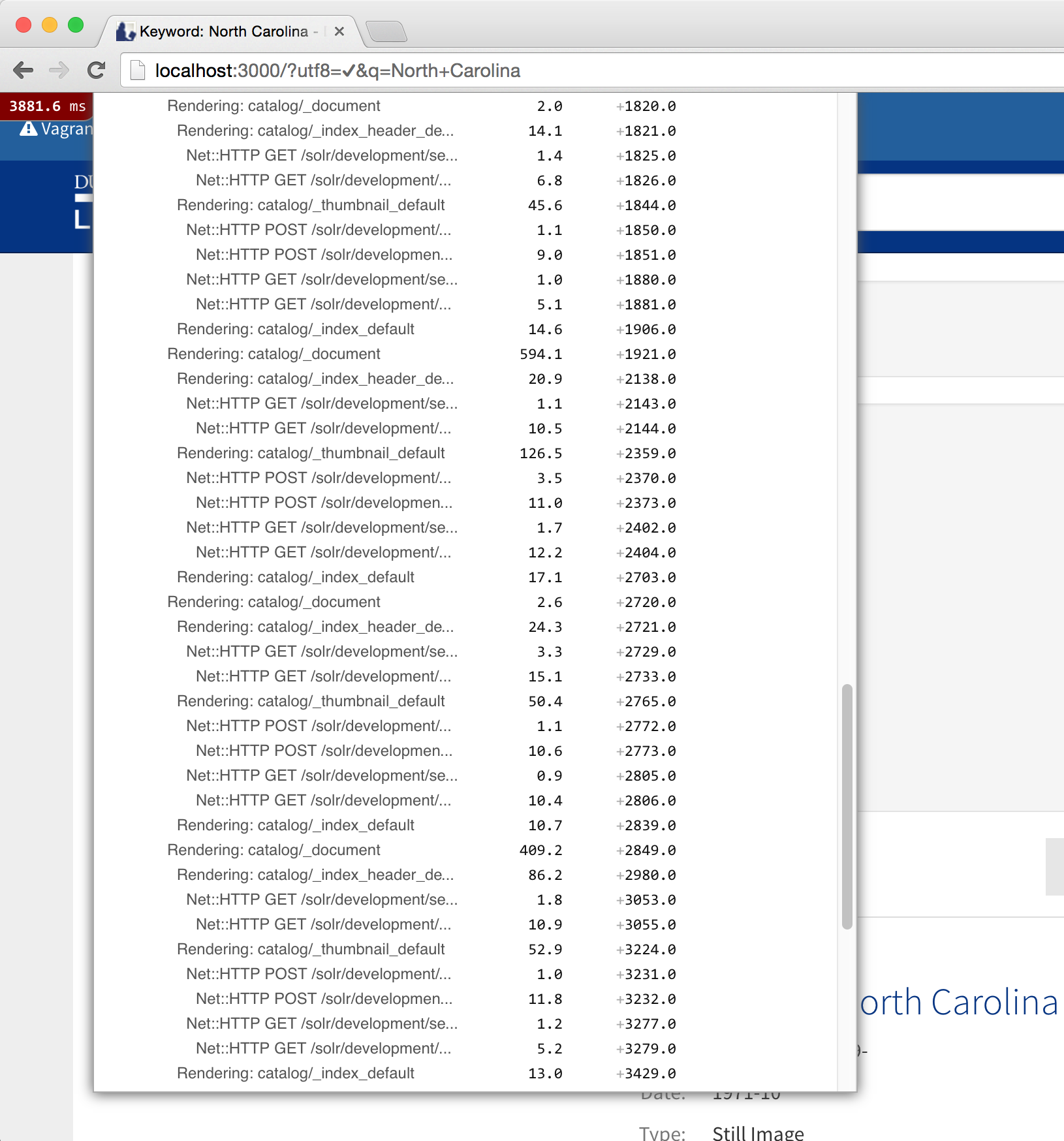
There are many, many details that require documenting and tracking through the life cycle of a software development project. Initially we start with requirements- meaning what the tools need to do to meet the end-users needs. Requirements must be properly documented and must essentially detail a project management plan that can result in a successful product (the software) and the project (the process, and everything that supports success of the product itself). From this we manage a ‘backlog’ of requirements, and pull from the backlog to structure our work. Requirements evolve into tasks that are handed off to developers. Tasks themselves become conversations as the development team determines the best possible approach to getting the work done. In addition to this, there are bugs to track, changes to document, and new requirements evolving all of the time… you can imagine that managing all of this in a simple ‘To Do’ list could get a bit unwieldy.

We realized that our ability to keep all of these many plates spinning necessitated a really solid project management tool. So we embarked on a mission to find just the right one! I’ll share our approach here, in case you and your team have a similar need and could benefit from our experiences.
STEP 1: Establish your business case: Finding the right tool will take effort, and getting buy-in from your team and organization will take even more! Get started early with justifying to your team and your org why a PM tool is necessary to support the work.
STEP 2: Perform a needs assessment: You and your team should get around a table and brainstorm. Ask yourselves what you need this tool to do, what features are critical, what your budget is, etc. Create a matrix where you fully define all of these characteristics to drive your investigation.
STEP 3: Do an environmental scan: What is out there on the market? Do your research and whittle down a list of tools that have potential. Also build on the skills of your team- if you have existing competencies in a given tool, then fully flesh out its features to see if it fits the bill.
STEP 4: Put them through the paces: Choose a select list of tools and see how they match up to you needs assessment. Task a group of people to test-drive the tools, and report out on the experience.
STEP 5: Share your findings: Discuss the findings with your team. Capture the highs and the lows and present the material in a digestible fashion. If it’s possible to get consensus, make a recommendation.
STEP 6: Get buy-in: This is the MOST critical part! Get buy-in from your team to implement the tool. A PM tool can only benefit the team if it is used thoroughly, consistently, and in a team fashion. You don’t want to deal with adverse reactions to the tool after the fact…

No matter what tool you choose, you’ll need to follow some simple guidelines to ensure successful adoption:
- Once again… Get TEAM buy-in!
- Define ownership, or an Admin, of the tool (ideally the Project Manager)
- Define basic parameters for use and team expectations
- PROVIDE TRAINING
- Consider your ecosystem of tools and simplify where appropriate
- The more robust the tool, the more support and structure will be required
Trust me when I say that this exercise will not let you down, and will likely yield a wealth of information about the tools that you use, the projects that you manage, your team’s preferences for coordinating the work, and much more!