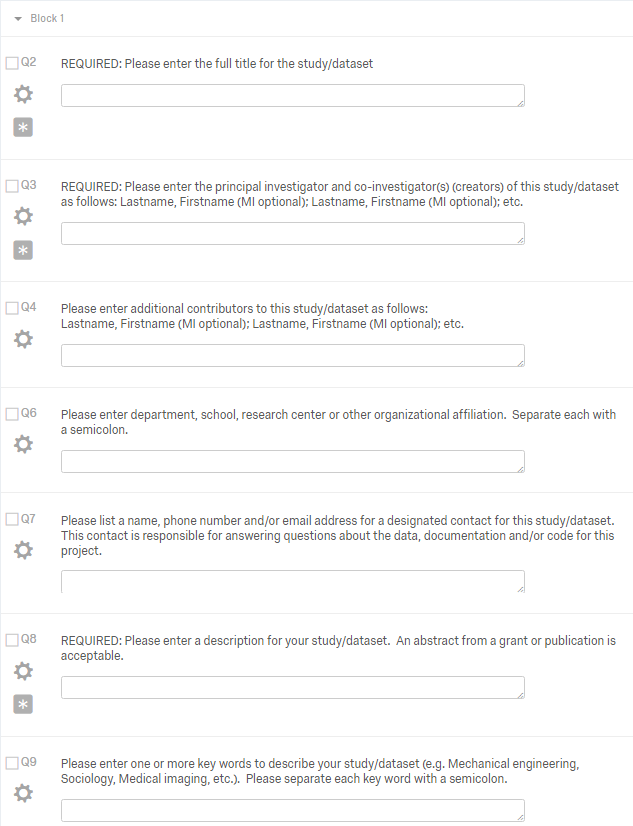
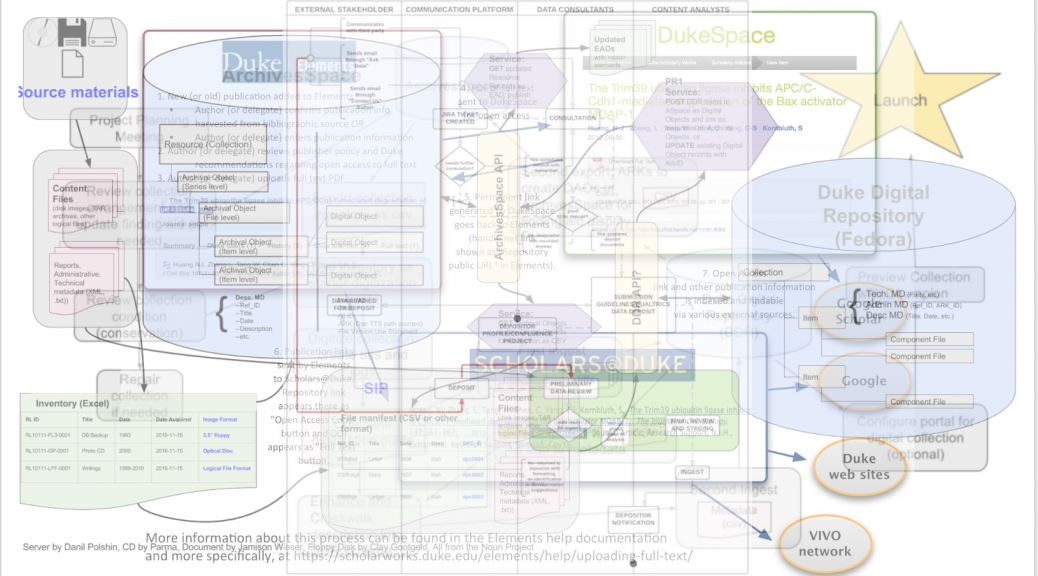
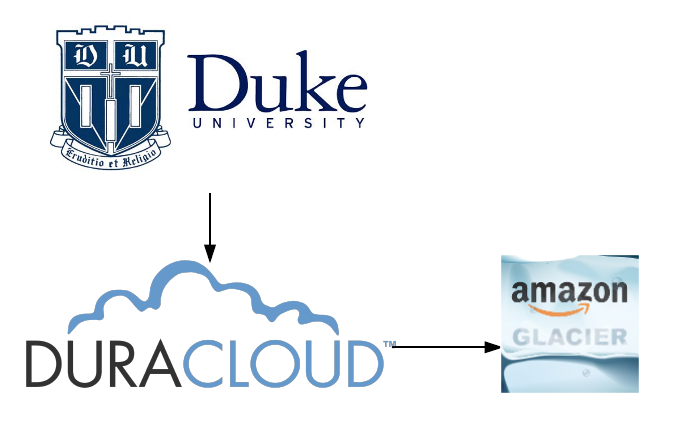
It’s September, and Duke students aren’t the only folks on campus in back-to-school mode. On the contrary, we here at the Duke Digital Repository are gearing up to begin promoting our research data curation services in real earnest. Over the last eight months, our four new research data staff have been busy getting to know the campus and the libraries, getting to know the repository itself and the tools we’re working with, and establishing a workflow. Now we’re ready to begin actively recruiting research data depositors!

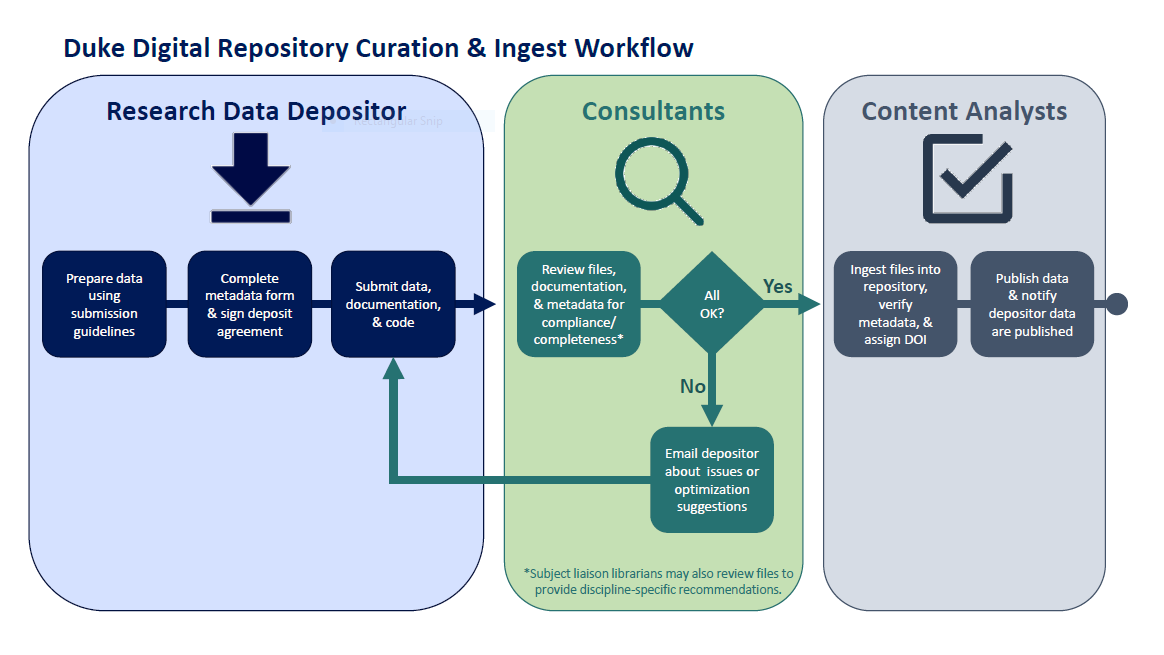
As our colleagues in Data and Visualization Services noted in a presentation just last week, we’re aiming to scale up our data services in a big way by engaging researchers at all stages of the research lifecycle, not just at the very end of a research project. We hope to make this effort a two-front one. Through a series of ongoing workshops and consultations, the Research Data Management Consultants aspire to help researchers develop better data management habits and take the longterm preservation and re-use of their data into account when designing a project or applying for grants. On the back-end of things, the Content Analysts will be able to carry out many of the manual tasks that facilitate that longterm preservation and re-use, and are beginning to think about ways in which to tweak our existing software to better accommodate the needs of capital-D Data.
This past spring, the Data Management Consultants carried out a series of workshops intending to help researchers navigate the often muddy waters of data management and data sharing; topics ranged from available and useful tools to the occasionally thorny process of obtaining consent for–and the re-use of–data from human subjects.

Looking forward to the fall, the RDM consultants are planning another series of workshops to expand on the sessions given in the spring, covering new tools and strategies for managing research output. One of the tools we’re most excited to share is the Open Science Framework (OSF) for Institutions, which Duke joined just this spring. OSF is a powerful project management tool that helps promote transparency in research and allows scholars to associate their work and projects with Duke.

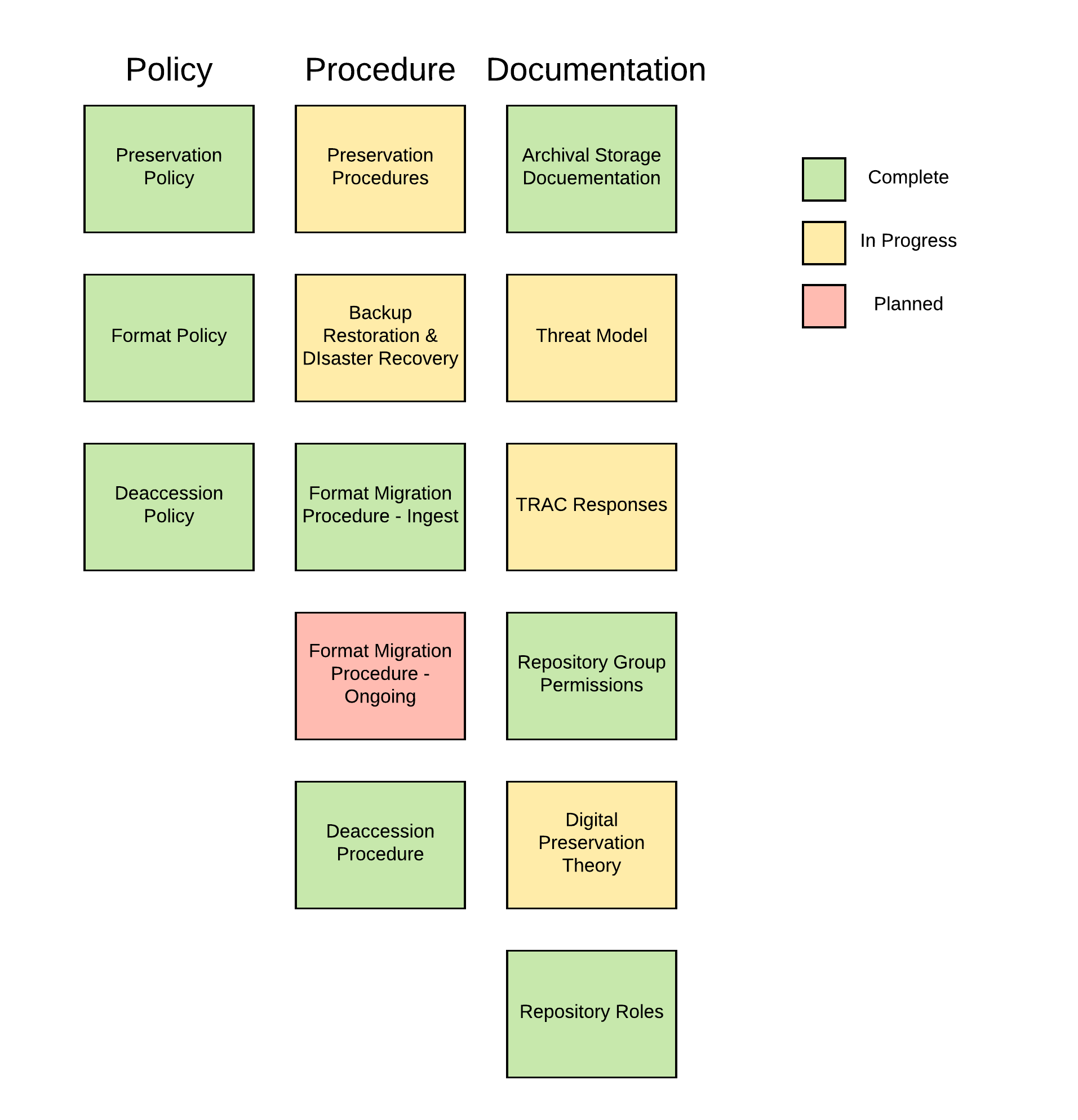
On the back-end of things, much work has been done to shore up our existing workflows, and a number of policies–both internal and external–have been met with approval by the Repository Program Committee. The Content Analysts continue to become more familiar with the available repository tools, while weighing in on ways in which we can make the software work better. The better part of the summer was devoted to collecting and analyzing requirements from research data stakeholders (among others), and we hope to put those needs in the development spotlight later this fall.
All of this is to say: we’re ready for it, so bring us your data!