Near the tail end of 2017, the Duke Libraries committed to a major multi-version upgrade for DukeSpace (powered by the open-source repository platform DSpace), and assembled an Avengers-like team to combine its members’ complementary powers to conquer it together. The team persisted through several setbacks and ultimately prevailed in its mission. The new site launched successfully in March 2018.
That same team is now back for a sequel, collaborating to tackle additional issues around system integrations, statistics/reporting, citations, and platform maintenance. Phase II of the project will wrap up this summer.
I’d like to share a bit more about the DSpace upgrade project, beginning with some background on why it’s important and where the platform fits into the larger picture at Duke. Then I’ll share more about the areas to which we have devoted the most developer time and attention over the past several months. Some of the development efforts were required to make DSpace 6 viable at all for Duke’s ongoing needs. Other efforts have been to strengthen connections between DukeSpace and other platforms. We have also been enhancing several parts of the user interface to optimize its usability and visual appeal.
DSpace at Duke: What’s in It?
Duke began using DSpace around 2006 as a solution for Duke University Archives to collect and preserve electronic theses and dissertations (ETDs). In 2010, the university adopted an Open Access policy for articles authored by Duke faculty, and DukeSpace became the host platform to make these articles accessible under the policy. These two groups of materials represent the vast majority of the 15,000+ items currently in the platform. Ensuring long-term preservation, discovery, and access to these items is central to the library’s mission.

Integrations With Other Systems
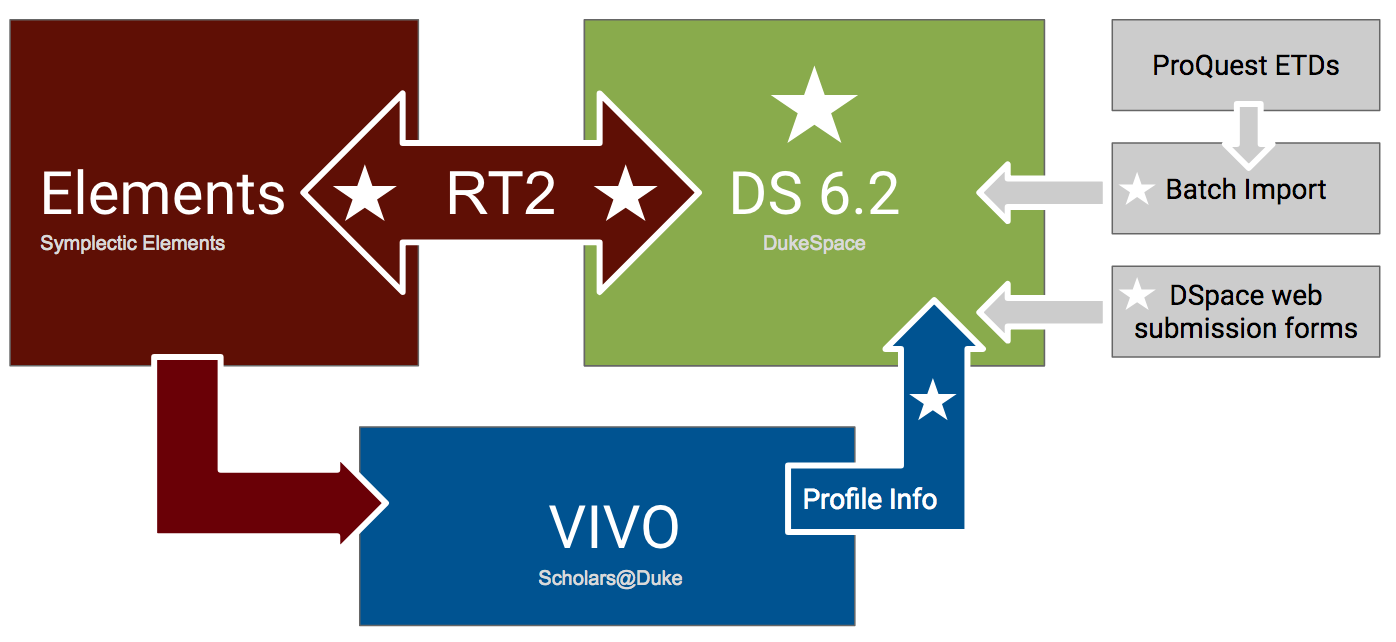
DukeSpace is one of three key technology platforms working in concert to support scholarly communications at Duke. The other two are the proprietary Research Information Management System Symplectic Elements, and the open-source research networking tool VIVO (branded as Scholars@Duke). Here’s a diagram illustrating how the platforms work together, created by my colleague Paolo Mangiafico:

In a nutshell, DSpace plays a critical role in Duke University scholars’ ability to have their research easily discovered, accessed, and used.
- Faculty use Elements to manage information about their scholarly publications. That information is pulled neatly into Scholars@Duke which presents for each scholar an authoritative profile that also includes contact info, courses taught, news stories in which they’re mentioned, and more.
- The Scholars@Duke profile has an SEO-friendly URL, and the data from it is portable: it can be dynamically displayed anywhere else on the web (e.g., departmental websites).
- Elements is also the place where faculty submit the open access copies of their articles; Elements in turn deposits those files and their metadata to DSpace. Faculty don’t encounter DSpace at all in the process of submitting their work.
- Publications listed in a Scholars@Duke profile automatically include a link to the published version (which is often behind a paywall), and a link to the open access copy in DSpace (which is globally accessible).
Upgrading DSpace: Ripple Effects
The following diagram expands upon the previous one. It adds boxes to the right to account for ETDs and other materials deposited to DSpace either by batch import mechanisms or directly via the application’s web input forms. In a vacuum, a DSpace upgrade–complex as that is in its own right–would be just the green box. But as part of an array of systems working together, the upgrade meant ripping out and replacing so much more. Each white star on the diagram represents a component that had to be thoroughly investigated and completely re-done for this upgrade to succeed.
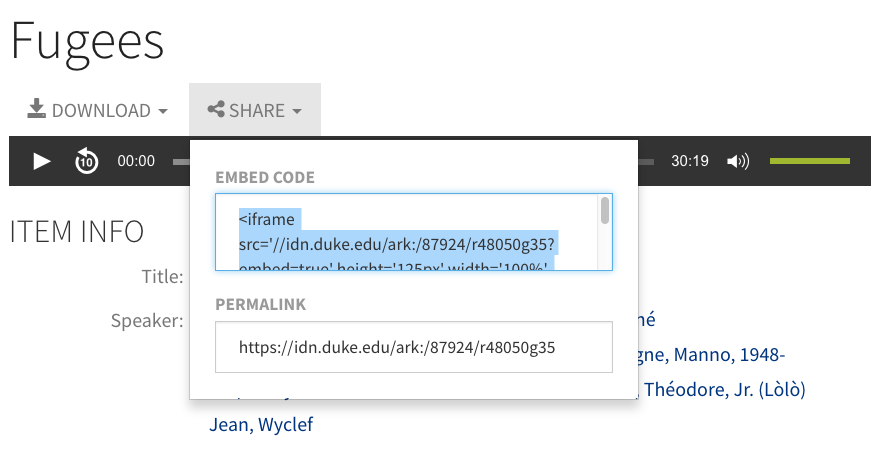
One of the most complicated factors in the upgrade effort was the bidirectional arrow marked “RT2”: Symplectic’s new Repository Tools 2 connector. Like its predecessor RT1, it facilitates the deposit of files and metadata from Elements into DSpace (but now via different mechanisms). Unlike RT1, RT2 also permits harvesting files and metadata from DSpace back into Elements, even for items that weren’t originally deposited via Elements. The biggest challenges there:
- Divergent metadata architecture. DukeSpace and Elements employ over 60 metadata fields apiece (and they are not the same).
- Crosswalks. The syntax for munging/mapping data elements from Elements to DSpace (and vice versa) is esoteric, new, and a moving target.
- Legacy/inconsistent data. DukeSpace metadata had not previously been analyzed or curated in the 12 years it had been collected.
- Newness. Duke is likely the first institution to integrate DSpace 6.x & Elements via RT2, so a lot had to be figured out through trial & error.
Kudos to superhero metadata architect Maggie Dickson for tackling all of these challenges head-on.
User Interface Enhancements in Action
There are over 2,000 DSpace instances in the world. Most implementors haven’t done much to customize the out-of-the-box templates, which look something like this for an item page:
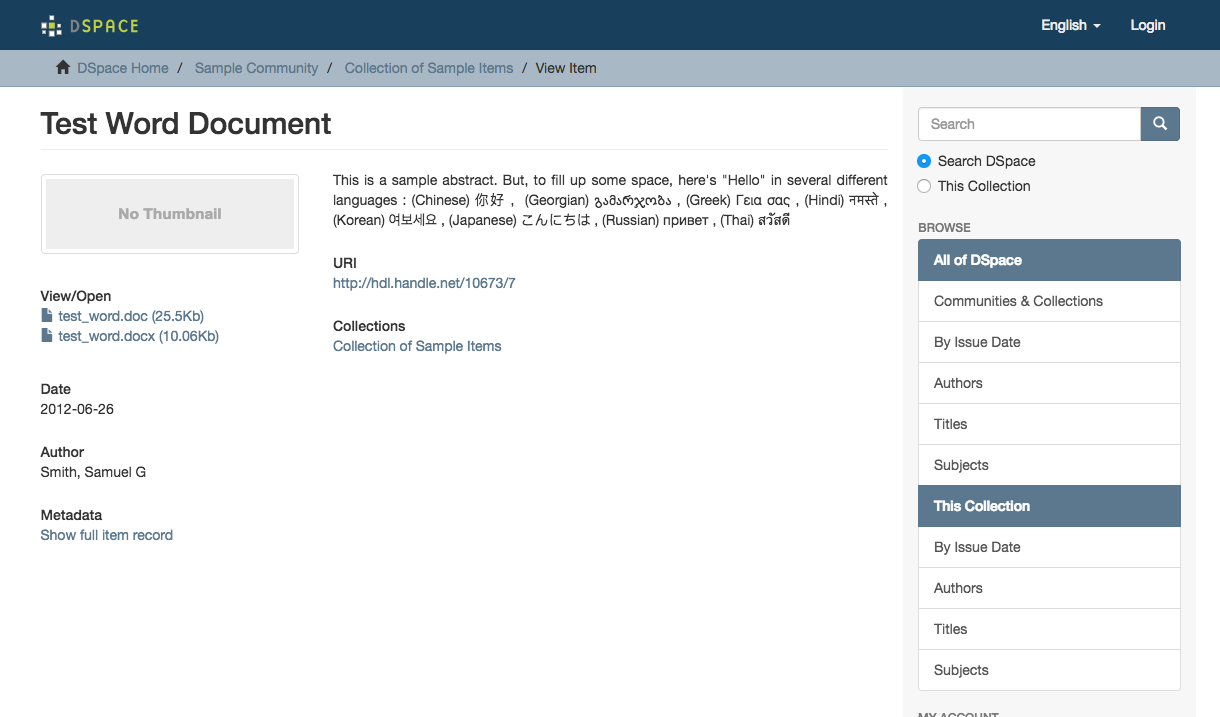
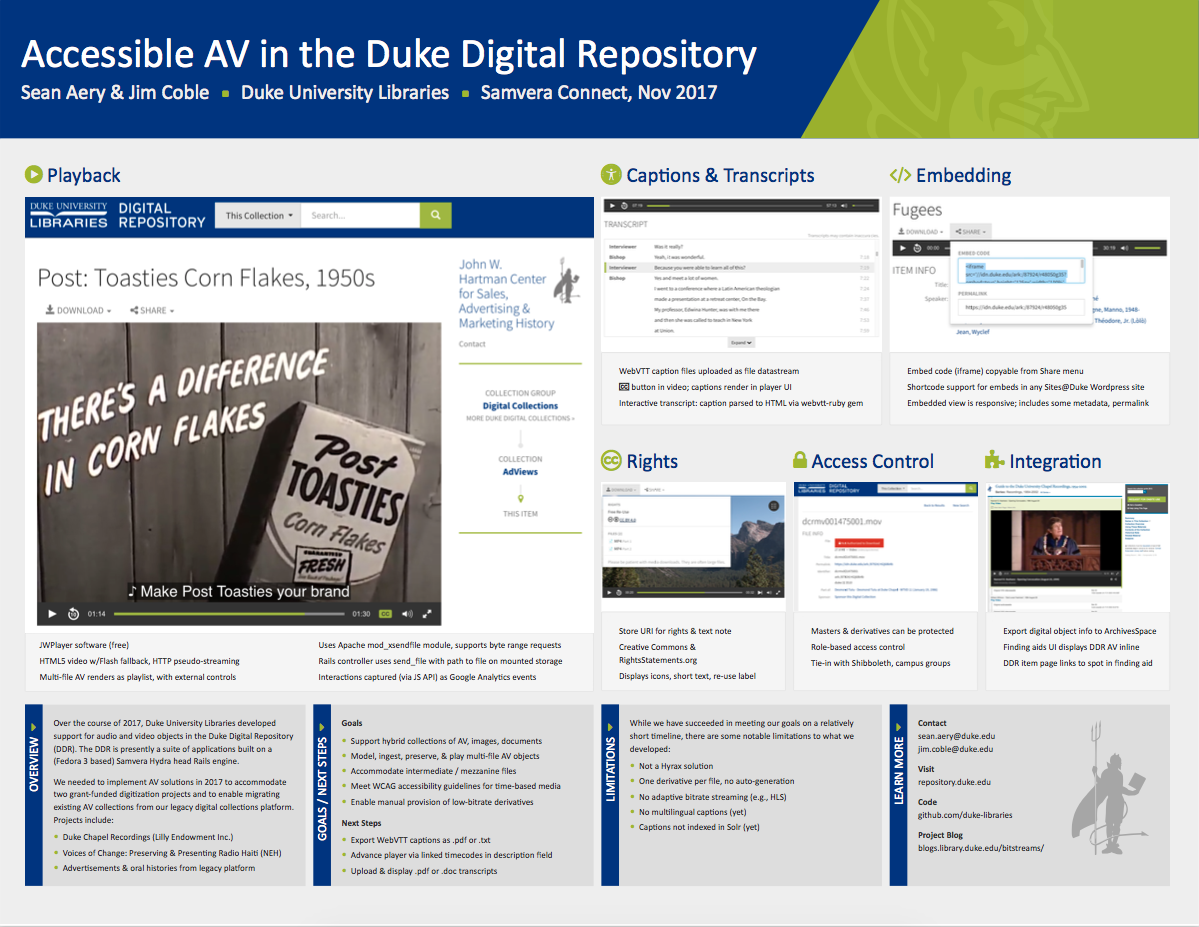
The UI framework itself is outdated (driven via XSLT 1.0 through Cocoon XML pipelines), which makes it hard for anyone to revise substantially. It’s a bit like trying to whittle a block of wood into something ornate using a really blunt instrument. The DSpace community is indeed working on addressing that for DSpace 7.0, but we didn’t have the luxury to wait. So we started with the vanilla template and chipped away at it, one piece at a time. These screenshots highlight the main areas we have been able to address so far.
Bootstrap / Bootswatch Theme
We layered on the same adapted Bootswatch theme in use by the Duke Libraries’ Drupal website and Duke Digital Repository, then applied the shared library masthead. This gives DukeSpace a fairly common look and feel with the rest of the library’s web presence.

Images, Icons, and Filesizes
We configured DSpace to generate and display thumbnail images for all items. Then we added icons corresponding to MIME types to help distinguish different kinds of files. We added really prominent indicators for when an item was embargoed (and when it would become available), and also revised the filesize display to be more clear and concise.

Usage & Attention Stats
Out of the box, DSpace item statistics are only available by clicking a link on the item page to go to a separate stats page. We figured out how to tap into the Solr statistics core and transform that data to display item views and file downloads directly in the item sidebar for easier access. We were also successful showing an Altmetric donut badge for any article with a DOI. These features together help provide a clear indication on the item page how much of an impact a work has made.

Rights
We added a lookup from the item page to retrieve the parent collection’s rights statement, which may contain a statement about Open Access, a Creative Commons license, or other explanatory text. This will hopefully assert rights information in a more natural spot for a user to see it, while at the same time draw more attention to Duke’s Open Access policy.

Scholars@Duke Profiles & ORCID Links
For any DukeSpace item author with a Scholars@Duke profile, we now display a clickable icon next to their name. This leads to their Scholars@Duke profile, where a visitor can learn much more about the scholar’s background, affiliations, and other research. Making this connection relies on some complicated parts: 1) enable getting Duke IDs automatically from Elements or manually via direct entry; 2) storing the ID in a DSpace field; 3) using the ID to query a VIVO API to retrieve the Scholars@Duke profile URL. We are able to treat a scholar’s ORCID in a similar fashion.

Other Development Areas
Beyond the public-facing UI, these areas in DSpace 6.2 also needed significant development for the upgrade project to succeed:
- Fixed several bugs related to batch metadata import/export
- Developed a mechanism to create user accounts via batch operations
- Modified features related to authority control for metadata values
Coming Soon
By summer 2018, we aim to have the following in place:
Streamlined Sidebar
Add collapsable / expandable facet and browse options to reduce the number of menu links visible at any given time.

Citations
Present a copyable citation on the item page.

…And More!
- Upgrade the XSLT processor from Xalan to Saxon, using XLST 3.0; this will enable us to accomplish more with less code going forward
- Revise the Scholars@Duke profile lookup by using a different VIVO API
- Create additional browse/facet options
- Display aggregated stats in more places
We’re excited to get all of these changes in place soon. And we look forward to learning more from our users, our collaborators, and our peers in the DSpace community about what we can do next to improve upon the solid foundation we established during the project’s initial phases.