

Duke University Libraries has been sharing its rich resources by creating and publishing digital collections for more than 20 years (remember the Scriptorium?), and to date the digital projects team stewards more than 100 collections consisting of 191,000+ items. Over the years the technologies and practices employed to deliver this content have changed often and drastically. Two weeks ago, we announced the latest iteration of our digital collections interface with the release of the Tripod3. Currently Tripod3 only features one collection – W. Duke, Sons & Co. Advertising Materials, 1880-1910 – but in early 2016 all of the digital collections currently being delivered using Tripod2 (the predecessor to Tripod3) will be migrated to the new system.
And that’s where I come in… Hello! I’m Maggie – DUL’s newly hired Metadata Architect, and I’ve been here for about a month and a half. Now that I’ve got my sea legs, I’m embarking on a project to remediate all of the Tripod2 metadata in advance of its migration to Tripod3. I’m not going it alone, though – we’ve formed a task group to guide this process as well as make recommendations for the ongoing creation and management of metadata associated with all materials in the Duke Digital Repository (and beyond).
Back in the day – metadata in the time of the Scriptorium:

Back in 1995, when the first digital collections were being created, the focus was on providing access to those collections in a standalone way, and little thought was given to cross-collection and federated searching and browsing, because the capabilities just hadn’t evolved yet. We were still pretty excited about hypertext. Metadata standards and practices for digital collections were in their nascent stages, as well, and so their application was spotty and inconsistent. This resulted in the ‘silo-ization’ of our digital collections. Now, we have a robust, consolidated preservation and access system and the capability to share our collections much more broadly through aggregators such as the Digital Public Library of America. And LINKED DATA, y’all! But the discovery and access of our resources, even in the most sophisticated of systems, is only as good as the metadata used to describe them.
Just about yesterday – a Tripod2 metadata record:

And now, Tripod 3:

Remediating all of the legacy metadata is a big job – turns out you can create a LOT of metadata over the course of 20 years. Expressed as RDF, we have more than two million statements. And inevitably, as it’s been created over many years, by many people of varying backgrounds and experience, and according to many different practices and standards, it’s a mess. So, in the coming weeks and months, we’ll be tackling each and every one of the 85 (!) fields used in the creation of DUL’s digital collections, assessing usage and mappings and doing a whole heck of a lot of data munging (thank goodness for OpenRefine). And we’ll be diving into the world of linked data and reconciling our metadata against linked open data sets wherever possible.
A visualization of the current state of Tripod2 metadata fields and Dublin Core mappings:
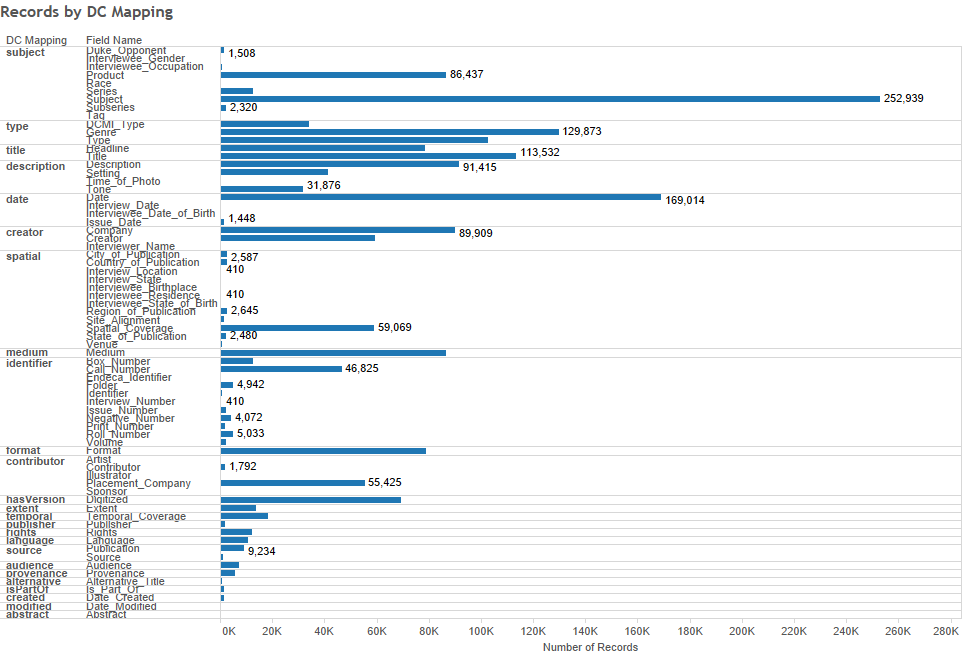
Once we’re finished with this project, our metadata will not only be beautiful, it will lend itself to a much more comprehensible experience for our users, as well as the ability to effectively and efficiently share our materials broadly. We’ve only just begun this work and will report on our progress periodically. Please stay tuned!