Part of my job as Digital Collections Program Manager is to manage our various projects from idea to proposal to implementation and finally to publication. It can be a long and complicated process with many different people taking part along the way. When we (we being the Digital Collections Implementation Team or DCIT) launch a project online, there are special blog posts, announcements and media attention. Everyone feels great about a successful project implementation, however as the excitement of the launch subsides the project team is not quite done. The last step in a digital collections project at Duke is the post project review.

Post project reviews are part of project management best practices for effectively closing and assessing the outcomes of projects. There are a lot of resources for project management available online, but as usual Wikipedia provides a good summary of project post-mortems as well as the different types and phases of project management in general. Also if you Google “project post-mortem,” you will get more links then you know what to do with.
Process
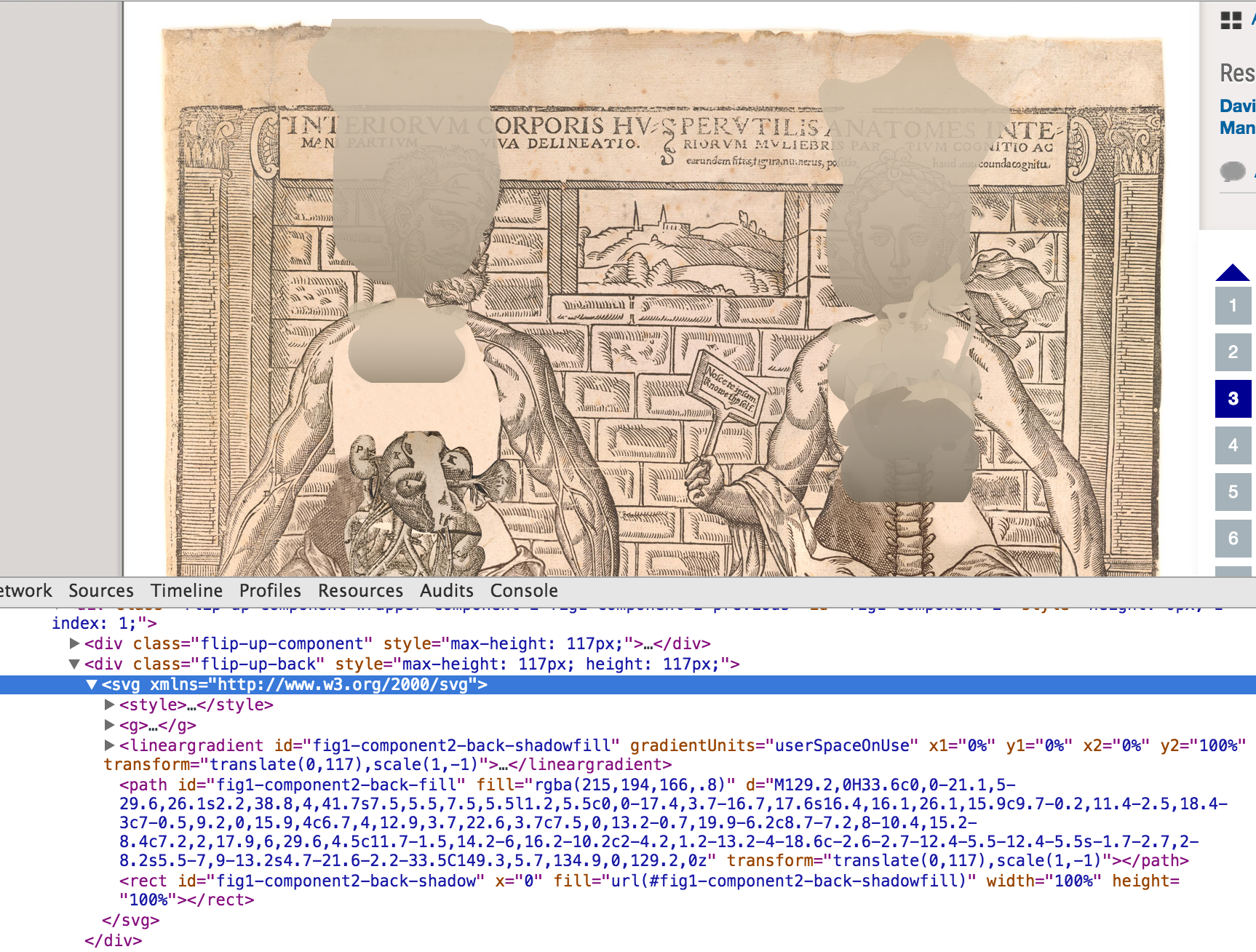
As we finish up projects we conduct what we call a “post-mortem,” and it is essentially a post project review. The name evokes autopsies, and what we do is not dissimilar but thankfully there are no bodies involved (except when we closed up the recent Anatomical Fugitive Sheets digital collection – eh? see what I did there? wink wink). The goals of our post mortem process are for the project team to do the following:
- Reflect on the project’s outcomes both positive and negative
- Document any unique decisions or methods employed during the project
- Document resources put into the project.
In practice, this means that I ask the project team to send me comments about what they thought went well and what was challenging about the project in question. Sometimes we meet in person to do this, but often we send comments through email or our project management tool. I also meet in person with each project champion as a project wraps up. Project champions are the people that propose and conceive a project. I ask everyone the same general questions: what worked about the project and what was challenging. With champions, this conversation is also an opportunity to discuss any future plans for promotion as well as think of any related projects that may come up in the future.

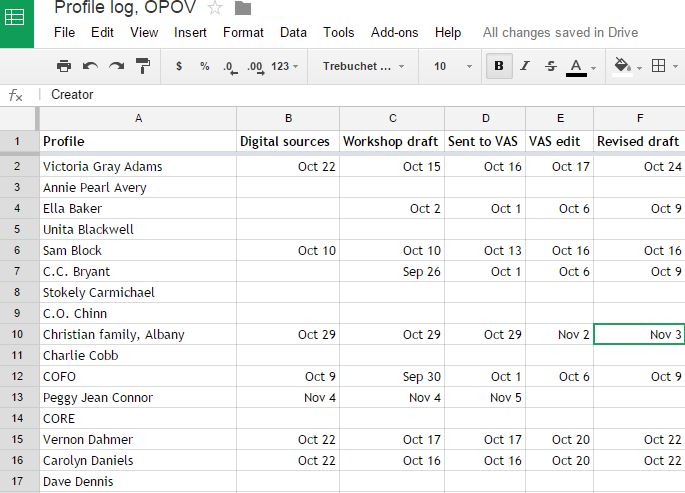
Once I have all the comments from the team and champion I put these into my post-mortem template (see right – click to expand). I also pull together project stats such as the number of items published, and the hours spent on the project. Everyone in the core project team is asked to track and submit the hours they spend on projects, which makes pulling stats an easy process. I designed the template I use as a word document. Its structured enough to be organized but unstructured enough for me to add new categories on the fly as needed (for example, we worked with a design contractor on a recent project so I added a “working with contractor” section).
Seems like a simple enough process right? It is, assuming you can have two ingredients. First, you need to have a high degree of trust in your core team and good relationships with project stakeholders. The ability to speak honestly (really really honestly) about a project is a necessity for the information you gather to be useful. Secondly, you do actually have to conduct the review. My team gets pulled so quickly from project to project, its really easy to NOT make time for this process. What helps my team, is that post mortems are a formal part of our project checklists. Also, I worked with my team to set up our information gathering process, so we all own it and its relevant and easy for them.

Impacts
The impacts these documents have on our work are very positive. First there is short term benefit just by having the core team communicate what they thought worked and didn’t work. Since we instituted this in the last year, we have used these lessons learns to make small but important changes to our process.
This process also gives the project team direct feedback from our project champions. This is something I get a lot through my informal interactions with various stakeholders in my role as project manager, however the core team doesn’t always get exposed to direct feedback both positive and negative.
The long term benefit is using the data in these reports to make predictions about resources needed for future projects, track project outcomes at a program level, and for other uses we haven’t considered yet.
Further Resources
All in all, I cannot recommend a post project review process to anyone and everyone who is managing projects enough. If you are not convinced by my template (which is very simple), there are lots of examples out there. Google “project post-mortem templates” (or similar terminology) to see a huge variety.
There are also a few library and digital collections project related resources you may find useful as well: