This post was authored by Behind the Veil/Digital Collections intern Kristina Zapfe.
From the outside, viewing digitized items or requesting one yourself is a straightforward activity. Browsing images in the Duke Digital Repository produces instantaneous access to images from the David M. Rubenstein Rare Book and Manuscript Library’s collections, and requesting an item for digitization means that they appear in your email in as little as a few weeks. But what happens between placing that request and receiving your digital copies is a well-mechanized feat, a testament to the hard work and dedication put forth by the many staff members who have a hand in digitizing special collections.
I began at Duke Libraries in July 2022 as the Digital Collections Intern, learning about the workflows and pivots that were made in order to prioritize public access to Rubenstein’s collections during pandemic-era uncertainty. While learning to apply metadata and scan special collection materials, I sketched out an understanding of how digital library systems function together, crafted by the knowledge and skills of library staff who maintain and improve them. This established an appreciation of the collaborative and adaptive nature of the many departments and systems that account for every detail of digitizing items, providing patrons access to Rubenstein’s special collections from afar.
I have filmed short videos before, but none that required the amount of coordination and planning that this one did. Once the concept was formed, I began researching Duke University Libraries’ digital platforms and how they work together in order to overlay where the patron request process dipped into these platforms and when. After some email coordination, virtual meetings, and hundreds of questions, a storyboard was born and filming could begin. I tried out some camera equipment and determined that shooting on my iPhone 13 Pro with a gimbal attachment was a sufficient balance of quality and dexterity. Multiple trips to Rubenstein, Bostock, and Perkins libraries and Smith Warehouse resulted in about 500 video clips, about 35 of which appear in the final video.
Throughout this process, I learned that not everything goes as the storyboard plans, and I enjoyed leaving space for my own creativity as well as input from staff members whose insights about their daily work made for compelling shots and storytelling opportunities. The intent of this video is to tell the story of this process to everyone who uses and appreciates Duke Libraries’ resources and say “thank you” to the library staff who work together to make digital collections available.
Special thanks to all staff who appeared in this video and enthusiastically volunteered their time and Maggie Dickson, who supervised and helped coordinate this project.
simplify the patron request process in the Rubenstein Library;
preserve and make accessible files from patron requests in the Duke Digital Repository (DDR).
Note that in this context, our patrons are generally folks that want to access Rubenstein Library materials without making the trip to Durham. Anyone, regardless of their researcher or academic status, can request digital copies of Rubenstein collections.
Moving digitization requests through this workflow continues to be the major focus for the digital collections team and the Digital Production Center (DPC). Given the folder level nature of the process (whole folders of manuscript material at preservation quality), more requests are digitized by the DPC than under our previous workflow. Additionally, the new request process became an essential tool to serving remote researchers during the pandemic. It continues to be a valuable service, and we have not seen demand lessen significantly since the peak of the pandemic. Below is a chart showing the number of patron requests managed by the DPC since before the pandemic (note that we track our statistics by fiscal year or FY, which in Duke’s case is July – June).
FY18
FY19
FY20
FY21
FY22
FY23
# of requests
81
77
39
394
438
469
Files produced
1,323
676
1092
79,519
74,517
73,705
Patron requests received and files produced from said requests by the DPC.
As a result of the new patron request workflow, the digital collections team has made portions of hundreds of collections accessible in the digital repository. We also see new materials from the existing collections requested periodically, so individual digital collections grow over time. Our statistics for new digital collections are in the chart below.
FY21
FY22
FY23
New digital collections from patron requests
36
154
119
Additions to existing collections from patron requests
4
12
6
Print items digitized for patron requests
16
21
30
Non-patron based new digital collections
131
15
80
Additions to digital collections (not patron request oriented)
4
4
5
Numbers of collections launched in the Duke Digital Repository since 2020.
The patron request workflow, like all other digital collections projects, is carried out by the cross-departmental Duke Libraries Digital Collections Implementation Team (DCIT). DCIT members include representatives from Conservation Services, Digital Curation Services, the Digital Production Center, a Digital Projects Developer (from the Assessment and User Experience Strategy department), Rubenstein Library Research Services, and Rubenstein Library Technical Services. The group’s membership shows how varied the needs are to develop and sustain digital collections.
We have also been making slow progress on the “Section A” mass digitization project. This project is named for an old Rubenstein Library shelving location, and contains over 3000 small manuscript collections. Many of the collections document life in the South in the 19th Century. Since 2020, we have been able to make 210 Section A collections accessible online. Many of these were scanned before the pandemic began, however the DPC continues to scan Section A when time permits. We have also seen at least 25 Section A collections come all the way through the patron request workflow, and there are more in progress. I’ve included embedded links to 3 Section A collections below.
Here are a few other project highlights from the past 2.5 years.
Deed of Manumission from the American Slavery Digital collectionImage from the Darrin Zammit Lupi digital collection
Metadata created during a Rubenstein Library re-cataloging project has been transformed and applied to the American Slavery Documents digital collection, thus making this collection and the identities of the enslaved persons documented therein more discoverable.
The Memory Project grew to include more oral histories in September 2021.
New films have also been added to the Men’s Basketball Game Film Collection to get you ready for the upcoming season (note: these films are silent – June 2023).
Digital Collections has a lot to look forward to in 2023-2024. Along with the John Hope Franklin Research Center we expect to wrap up the Behind the Veil grant in 2024 (lots more news to come on that). The digital collections team also plans to continue refining the patron request workflow. We are hoping to find a new balance in our portfolio that allows us to continue serving the needs of remote researchers while also completing more project based digitization. How will we actually do that without significantly changing our staffing? When we figure it out, we will be happy to share.
In the meantime, all digital collections are available through the Duke Digital Repository.
Happy Browsing!
Behind the Veil Digitization intern Sarah Waugh and Digital Collections intern Kristina Zapfe’s efforts over the past year have focused on quality control of interviews transcribed by Rev.com. This post was authored by Sarah Waugh and Kristina Zapfe.
Introduction
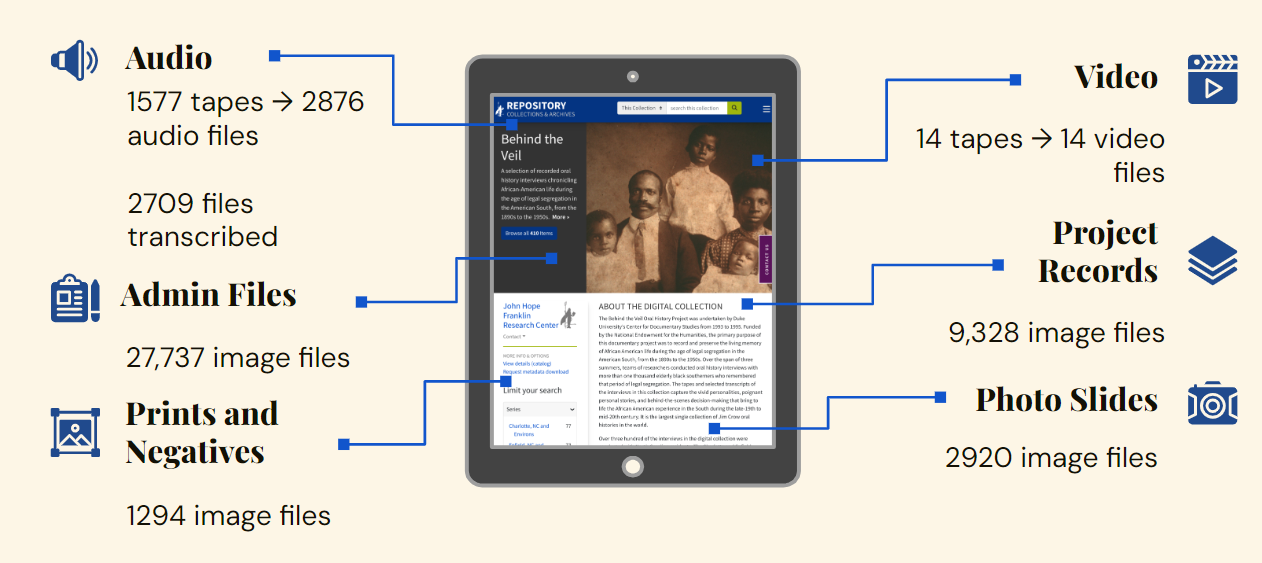
The Digital Production Center (DPC) is proud to announce that we have reached a milestone in our work on Documenting African American Life in the Jim Crow South: Digital Access to the Behind the Veil Project Archive. We have completed digitization and are over halfway through our quality control of the audio transcripts! The project, funded by the National Endowment for the Humanities, will expand the Behind the Veil (BTV) digital collection, currently 410 audio files, to include the newly digitized copies of the original master recordings, photographic materials, and supplementary project files.
The collection derives from Behind the Veil: Documenting African-American Life in the Jim Crow South. This was an oral history project headed by Duke University’s Center for Documentary Studies from 1993 to 1995 and is currently housed in the David M. Rubenstein Rare Book and Manuscript Library and curated by the John Hope Franklin Research Center for African and African American History and Culture. The BTV collectiondocumented and preserved the memory of African Americans who lived in the South from the 1890s to the 1950s, resulting in a culturally-significant and extensive multimedia collection.
As interns, our work focused on ordering transcripts from Rev.com and performing quality control on transcripts for the digitized oral histories. July 2023 marked our arrival at the halfway point of completing the oral history transcript quality control process. At the time of writing, we’ve checked 1727 of 2876 files after a year of initial planning and hard work. With over 1,666 hours worth of audio files to complete, 3 interns and 7 student workers in the DPC contributed 849 combined hours to oral history transcript quality control so far. Because of their scope, transcription and quality control are the last pieces of the digitization puzzle before the collection moves on to be ingested and published in the Duke Digital Repository.
We are approaching the home stretch with the deadline for transcript quality control coming in December 2023, and the collection scheduled to launch in 2024. With that goal approaching, here is what we’ve completed and what remains to be done.
Digitization Progress
As the graphic above indicates, the BTV digitization project consists of many different media like audio, video, prints, negatives, slides, administrative and project related documents that tell a fuller story of this endeavor.With these formats digitized, we look forward to finishing quality control and preparing the files for handoff to members of the Digital Collections and Curation Services department for ingest, metadata application, and launch for public access in 2024. We plan to send all 2876 audio files to Rev.com service by the end of August and to perform quality control on all those transcripts by December 2023.
Developing the Transcription Quality Control Process
With 2876 files to check within 19 months, the cross-departmental BTV team developed a process to perform quality control as efficiently as possible without sacrificing accuracy, accessibility, and our commitment to our stakeholders. We made our decisions based on how we thought BTV interviewers and narrators would want their speech represented as text. Our choices in creating our quality control workflow began with Columbia University’s Oral History Transcription Style Guide and from that resource, we developed a workflow that made sense for our team and the project.
Some voices were difficult to transcribe due to issues with the original recording, such as a microphone being placed too far away from a speaker, the interference of background noise, or mistakes with the tape. Since we did not have the resources to listen to entire interviews and check for every single mistake, we developed what we called the “spot-check” process of checking these interviews. Given the BTV project’s original ethos and the history of marginalized people in archives, the team decided to prioritize making sure race-related language met our standards across every single interview.
A few decisions on standards were quick and unanimous—such as not transcribing speech phonetically. With that, we avoided pitfalls from older oral histories of African Americans, like the WPA’s famous “Slave Narratives” project, that interviewed formerly-enslaved people, but often transcribed their words in non-standard phonetic spellings. Some narrators in the BTV project who may have been familiar with the WPA transcripts specifically requested the BTV project team not to use phonetic spelling.
Other choices took more discussion: we agreed on capitalizing “Black” when describing race, but we had to decide whether to capitalize other racial terms, including “White” and antiquated designations like “Colored.” Ultimately, we decided to capitalize all racial terms (with the exception of slurs). The team did not want users to make distinctions between lower and uppercase terms if we did not choose to capitalize them all. Maintaining consistency with capitalization would provide clarity and align with BTV values of equality between all races.
Using a spot-check process where we use Rev’s find-and-replace feature to standardize our top priorities saved us time to improve the transcripts in other ways. For instance, we also try to find and correct proper nouns like street names or names of important people in our narrators’ communities, allowing users to make connections in their research. We corrected mistakes with phrases used mainly in the past or that are very specific to certain regions, such as calling a dance hall a “Piccolo joint” from an early jukebox brand name. We also listened to instances where the transcriptionist could not hear or understand a phrase and marked it as “indistinct,” so we can add in the dialogue later (assuming we are able to decipher what was said).
While we developed these methods to increase the pace of our quality control process, one of the biggest improvements came from working with Rev. If we were able to attain more accurate transcripts, our quality control process would be more efficient. Luckily, Rev’s suite of services provided us this option without straying too far from our transcription budget.
Improving Accuracy with Southern Accents Specialists
When deciding on what would be the best speech-to-text option for our project’s needs, we elected to order Transcript Services from Rev, rather than their Caption Services. This decision hinged on the fact that the Transcript Services option is their only service that allows us to request Rev transcriptionists who specialize in Southern accents. Many people who were interviewed for Behind the Veil spoke with Southern accents that varied in strength and dialect. We found that the Southern accent expertise of the specialists had a significant impact on the accuracy of the transcripts we received from Rev.
This improvement in transcript quality has made a substantial difference in the time we spend on quality control for each interview: on average, it only takes us about 48 seconds of work for every 60 seconds of audio we check. We appreciated Rev’s offering of Southern accent specialists enough that we chose that service, even though it meant that we had to then convert their text file format output to the WebVTT file format for enhanced accessibility in the Duke Digital Repository.
Optimizing Accessibility with WebVTT File Format
The WebVTT file format provides visual tracking that coordinates the audio with the written transcript. This improvement in user experience and accessibility justified converting the interview transcripts to WebVTT format. Below is a visual of the WebVTT format in our existing BTV collection in the DDR. Click here to listen to the audio recording.
We have been collaborating with developer Sean Aery to convert transcript text files to WebVTT files so they will display properly in the Duke Digital Repository. He explained the conversion process that occurs after we hand off the transcripts in text file format.
“The .txt transcripts we received from the vendor are primarily formatted to be easy for people to read. However, they are structured well enough to be machine-readable as well. I created a script to batch-convert the files into standard WebVTT captions with long text cues. In WebVTT form, the caption files play nicely with our existing audiovisual features in the Duke Digital Repository, including an interactive transcript viewer, and PDF exports.” – Sean Aery, Digital Projects Developer, Duke University Libraries
Before conversion, we complete one more round of quality control using the spot-checking process. We have even referred to other components of the Behind the Veil collection (Administrative and Project Files Administrative Files) to cross-reference any alterations to metadata for accuracy.
Connecting the Local and Larger Community
Throughout the project, team members have been working on outreach. One big accomplishment by project PI John Gartrell and former BTV outreach intern Brianna McGruder was “Behind the Veil at 30: Reflections on Chronicling African American Life in the Jim Crow South.” This 2-day virtual conference convened former BTV interviewers and current scholars of the BTV collection to discuss their work and the impact that this collection had on their research.
We also recently presented at the Triangle Research Libraries Network annual meeting, where our presentation overlapped with some of what you’ve just read in this post. It was exciting to share our work publicly for the first time and answer questions from library staff across the region. We will also be presenting a poster about our BTV experience at the upcoming North Carolina Library Association conference in Winston-Salem in October.
Sarah Waugh and Kristina Zapfe presenting at the 2023 TRLN Annual Conference.
As we’ve hoped to convey, this project heavily relies on collaboration from many library departments and external vendors, and there are more contributors than we can thoroughly include in this post. Behind the Veil is a large-scale and high-profile project that has impacted many people over its 30-year history, and this newest iteration of digital accessibility seeks to expand the reach of this collection. Two years on, we’ve built on the work of the many professionals who have come before us to create and develop Behind the Veil. We are honored to be part of this rewarding process. Look for more BTV stories when we cross the finish line in 2024.
Post authored by Jen Jordan, Digital Collections Intern.
Hello, readers. This marks my third and final blog as the Digital Collections intern, a position that I began in June of last year.* Over the course of this internship I have been fortunate to gain experience in nearly every step of the digitization and digital collections processes. One of the things I’ve come to appreciate most about the different workflows I’ve learned about is how well they accommodate the variety of collection materials that pass through. This means that when unique cases arise, there is space to consider them. I’d like to describe one such case, involving a pretty remarkable collection.
Cheyne, C.E. “Booker T. Washington sitting and holding books,” 1903. 2 photographs on 1 mount : gelatin silver print ; sheets 14 x 10 cm. In Washington, D.C., Library of Congress Prints and Photographs Division.
In early October I arrived to work in the Digital Production Center (DPC) and was excited to see the Booker T. Washington correspondence, 1903-1916, 1933 and undated was next up in the queue for digitization. The collection is small, containing mostly letters exchanged between Washington, W. E. B. DuBois, and a host of other prominent leaders in the Black community during the early 1900s. A 2003 article published in Duke Magazine shortly after the Washington collection was donated to the John Hope Franklin Research Center provides a summary of the collection and the events it covers.
Arranged chronologically, the papers were stacked neatly in a small box. Having undergone undergone extensive conservation treatments to remediate water and mildew damage, each letter was sealed in a protective sleeve. As I scanned the pages, I made a note to learn more about the relationship between Washington and DuBois, as well as the events the collection is centered around—the Carnegie Hall Conference and the formation of the short-lived Committee of Twelve for the Advancement of the Interests of the Negro Race. When I did follow up, I was surprised to find that remarkably little has been written about either.
As I’ve mentioned before, there is little time to actually look at materials when we scan them, but the process can reveal broad themes and tone. Many of the names in the letters were unfamiliar to me, but I observed extensive discussion between DuBois and Washington regarding who would be invited to the conference and included in the Committee of Twelve. I later learned that this collection documents what would be the final attempt at collaboration between DuBois and Washington.
Washington to Browne, 21 July 1904, South Weymouth, Massachusetts
Once scanned, the digital surrogates pass through several stages in the DPC before they are prepared for ingest into the Duke Digital Repository (DDR); you can read a comprehensive overview of the DPC digitization workflow here. Fulfilling patron requests is top priority, so after patrons receive the requested materials, it might be some time before the files are submitted for ingest to the DDR. Because of this, I was fortunate to be on the receiving end of the BTW collection in late January. By then I was gaining experience in the actual creation of digital collections—basically everything that happens with the files once the DPC signals that they are ready to move into long term storage.
There are a few different ways that new digital collections are created. Thus far, most of my experience has been with the files produced through patron requests handled by the DPC. These tend to be smaller in size and have a simple file structure. The files are migrated into the DDR, into either a new or existing collection, after which file counts are checked, and identifiers assigned. The collection is then reviewed by one of a few different folks with RL Technical Services. Noah Huffman conducted the review in this case, after which he asked if we might consider itemizing the collection, given the letter-level descriptive metadata available in the collection guide.
I’d like to pause for a moment to discuss the tricky nature of “itemness,” and how the meaning can shift between RL and DCCS. If you reference the collection guide linked in the second paragraph, you will see that the BTW collection received item-level description during processing—with each letter constituting an item in the collection. The physical arrangement of the papers does not reflect the itemized intellectual arrangement, as the letters are grouped together in the box they are housed in. When fulfilling patron reproduction requests, itemness is generally dictated by physical arrangement, in what is called the folder-level model; materials housed together are treated as a single unit. So in this case, because the letters were grouped together inside of the box, the box was treated as the folder, or item. If, however, each letter in the box was housed within its own folder, then each folder would be considered an item. To be clear, the papers were housed according to best practices; my intent is simply to describe how the processes between the two departments sometimes diverge.
Processing archival collections is labor intensive, so it’s increasingly uncommon to see item-level description. Collections can sit unprocessed in “backlog” for many years, and though the depth of that backlog varies by institution, even well-resourced archives confront the problem of backlog. Enter: More Product, Less Process (MPLP), introduced by Mark Greene and Dennis Meissner in a 2005 article as a means to address the growing problem. They called on archivists to prioritize access over meticulous arrangement and description.
The spirit of folder-level digitization is quite similar to MPLP, as it enables the DPC to provide access to a broader selection of collection materials digitized through patron requests, and it also simplifies the process of putting the materials online for public access. Most of the time, the DPC’s approach to itemness aligns closely with the level of description given during processing of the collection, but the inevitable variance found between archival collections requires a degree of flexibility from those working to provide access to them. Numerous examples of digital collections that received item-level description can be found in the DDR, but those are generally tied to planned efforts to digitize specific collections.
Because the BTW collection was digitized as an item, the digital files were grouped together in a single folder, which translated to a single landing page in the DDR’s public user interface. Itemizing the collection would give each item/letter its own landing page, with the potential to add unique metadata. Similarly, when users navigate the RL collection guide, embedded digital surrogates appear for each item. A moment ago I described the utility of More Product Less Process. There are times, however, when it seems right to do more. Given the research value of this collection, as well as its relatively small size, the decision to proceed with itemization was unanimous.
Itemizing the collection was fairly straightforward. Noah shared a spreadsheet with metadata from the collection guide. There were 108 items, with each item’s title containing the sender and recipient of a correspondence, as well as the location and date sent. Given the collection’s chronological physical arrangement, it was fairly simple to work through the files and assign them to new folders. Once that was finished, I selected additional descriptive metadata terms to add to the spreadsheet, in accordance with the DDR Metadata Application Profile. Because there was a known sender and recipient for almost every letter, my goal was to identify any additional name authority records not included in the collection guide. This would provide an additional access point by which to navigate the collection. It would also help me to identify death dates for the creators, which determines copyright status. I think the added time and effort was well worth it.
This isn’t the space for analysis, but I do hope you’re inspired to spend some time with this fascinating collection. Primary source materials offer an important path to understanding history, and this particular collection captures the planning and aftermath of an event that hasn’t received much analysis. There is more coverage of what came after; Washington and DuBois parted ways, after which DuBois became a founding member of the Niagara Movement. Though also short lived, it is considered a precursor to the NAACP, which many members of the Niagara Movement would go on to join. A significant portion of W. E. B. DuBois’s correspondence has been digitized and made available to view through UMass Amherst. It contains many additional letters concerning the Carnegie Conference and Committee of Twelve, offering additional context and perspective, particularly in certain correspondence that were surely not intended for Washington’s eyes. What I found most fascinating, though, was the evidence of less public (and less adversarial) collaboration between the two men.
The additional review and research required by the itemization and metadata creation was such a fascinating and valuable experience. This is true on a professional level as it offered the opportunity to do something new, but I also felt moved to understand more about the cast of characters who appear in this important collection. That endeavor extended far beyond the hours of my internship, and I found myself wondering if this is what the obsessive pursuit of a historian’s work is like. In any case, I am grateful to have learned more, and also reminded that there is so much more work to do.
Click here to view the Booker T. Washington correspondence in the Duke Digital Repository.
*Indeed, this marks my final post in this role, as my internship concludes at the end of April, after which I will move on to a permanent position. Happily, I won’t be going far, as I’ve been selected to remain with DCCS as one of the next Repository Services Analysts!
Sources
Cheyne, C.E. “Booker T. Washington sitting and holding books,” 1903. 2 photographs on 1 mount : gelatin silver print ; sheets 14 x 10 cm. In Washington, D.C., Library of Congress Prints and Photographs Division. Accessed April 5, 2022. https://www.loc.gov/pictures/item/2004672766/
Post authored by Jen Jordan, Digital Collections Intern.
As another strange year nears its end, I’m going out on a limb to assume that I’m not the only one around here challenged by a lack of focus. With that in mind, I’m going to keep things relatively light (or relatively unfocused) and take you readers on a short tour of items that have passed through the Digital Production Center (DPC) this year.
Shortly before the arrival of COVID-19, the DPC implemented a folder-level model for digitization. This model was not developed in anticipation of a life-altering pandemic, but it was well-suited to meet the needs of researchers who, for a time, were unable to visit the Rubenstein Library to view materials in person. You can read about the implementation of folder-level digitization and its broader impact here. To summarize, before spring of 2020 it was standard practice to fill patron requests by imaging only the item needed (e.g., a single page within a folder). Now the default practice is to digitize the entire folder of materials. This has produced a variety of positive outcomes for stakeholders in the Duke University Libraries and broader research community, but for the purpose of this blog, I’d like to describe my experience interacting with materials in this way.
Digitization is time consuming, so the objective is to move as quickly as possible while maintaining a high level of accuracy. There isn’t much time for meaningful engagement with collection items, but context reveals itself in bits and pieces. Themes rise to the surface when working with large folders of material, and sometimes the image on the page demands to be noticed.
Even while working quickly, one would be hard-pressed to overlook this Vietnam-era anti-war message. One might imagine that was by design. From the Student Activism Reference collection: https://repository.duke.edu/dc/uastuactrc.
On more than one occasion I’ve found myself thinking about the similarities between scanning and browsing a social media app like Instagram. Stick with me here! Broadly speaking, both offer an endless stream of visual stimuli with little opportunity for meaningful engagement in the moment. Social media, when used mindfully, can be world-expanding. Work in the DPC has been similarly world-expanding, but instead of an algorithm curating my experience, the information that I encounter on any given day is curated by patron requests for digitization. Also similar to social media is the range of internal responses triggered over the course of a work day, and sometimes in the span of a single minute. Amusement, joy, shock, sorrow—it all comes up.
I started keeping notes on collection materials and topics to revisit on my own time. Sometimes I was motivated by a stray fascination with the subject matter. Other times I encountered collections relating to prominent historical figures or events that I thought I should know a bit more about.
Image from the WPSU Scrapbook.
First wave feminism was one such topic that revealed itself. It was a movement I knew little about, but the DPC has digitized numerous items relating to women’s suffrage and other feminist issues at the turn of the 20th century. I was particularly intrigued by the radical leanings of the UK’s Women’s Social and Political Union (WSPU), organized by Emmeline Pankhurst to fight for the right to vote. When I started looking at newspaper clippings pasted into a scrapbook documenting WSPU activities, I was initially distracted by the amusing choice of words (“Coronation chair damaged by wild women’s bomb”). Curious to learn more, I went home and read about the WSPU. The following excerpt is from a speech by Pankhurst in which she provides justification for the militant tactics employed by the WSPU:
I want to say here and now that the only justification for violence, the only justification for damage to property, the only justification for risk to the comfort of other human beings is the fact that you have tried all other available means and have failed to secure justice. I tell you that in Great Britain there is no other way…
Pankhurst argued that men had to take the right to vote through war, so why shouldn’t women also resort to violence and destruction? And so they did.
As Rubenstein Library is home to the Sallie Bingham Center, it’s unsurprising that the DPC digitizes a fair amount of material on women’s issues. I appreciate the juxtaposition of the following two images, both of which I find funny, and yet sad.
This advertisement for window shades is pasted inside a young woman’s scrapbook dated 1900—1905. It contains information on topics such as etiquette, how to manage a household, and how to be a good wife. Are we to gather that proper shade cloth is necessary to keep a man happy?
Source collection: Young woman’s scrapbook, 1900-1905 and n.d.
In contrast, the below image from the bookL’amour libre by French feminist, Madeleine Vernet, describes prostitution and marriage as the same kind of prison, with “free love” as the only answer. Perhaps this is a hyperbolic comparison, but after perusing the young woman’s scrapbook, I’m not so sure. I’m just thankful to have been born a woman near the end of the 20th century and not the start of it.
From the book L’amour libre by Madeline Vernet
This may be difficult to believe, but I didn’t set out to write a blog so focused on struggle. The reality, however, is that our special collections are full of struggle. That’s not all there is, of course, but I’m glad this material is preserved. It holds many lessons, some of which we still have yet to learn.
I think we can all agree that 2021 was, well, a challenging year. I’d be remiss not to close with a common foe we might all rally around. As we move into 2022 and beyond, venturing ever deeper into space, we may encounter this enemy sooner than we imagined…
Image from an illustrated 1906 French translation of H.G. Wells’s ‘War of the Worlds’.
Sources:
Pankhurst, Emmeline. Why We Are Militant: A Speech Delivered by Mrs. Pankhurst in New York, October 21, 1913. London: Women’s Press, 1914. Print.
“‘Prayers for Prisoners’ and church protests.” Historic England, n.d., https://historicengland.org.uk/research/inclusive-heritage/womens-history/suffrage/church-protests/
This post was written by Jen Jordan, a graduate student at Simmons University studying Library Science with a concentration in Archives Management. She is the Digital Collections intern with the Digital Collections and Curation Services Department. Jen will complete her masters degree in December 2021.
The Digital Production Center (DPC) is thrilled to announce that work is underway on a 3-year long National Endowment for the Humanities (NEH) grant-funded project to digitize the entirety of Behind the Veil: Documenting African-American Life in the Jim Crow South, an oral history project that produced 1,260 interviews spanning more than 1,800 audio cassette tapes. Accompanying the 2,000 plus hours of audio is a sizable collection of visual materials (e.g.- photographic prints and slides) that form a connection with the recorded voices.
We are here to summarize the logistical details relating to the digitization of this incredible collection. To learn more about its historical significance and the grant that is funding this project, titled “Documenting African American Life in the Jim Crow South: Digital Access to the Behind the Veil Project Archive,” please take some time to read the July announcementwritten by John Gartrell, Director of the John Hope Franklin Research Center and Principal Investigator for this project. Co-Principal Investigator of this grant is Giao Luong Baker, Digital Production Services Manager.
Digitizing Behind the Veil (BTV) will require, in part, the services of outside vendors to handle the audio digitization and subsequent captioning of the recordings. While the DPC regularly digitizes audio recordings, we are not equipped to do so at this scale (while balancing other existing priorities). The folks at Rubenstein Library have already been hard at work double checking the inventory to ensure that each cassette tape and case are labeled with identifiers. The DPC then received the tapes, filling 48 archival boxes, along with a digitization guide (i.e. – an Excel spreadsheet) containing detailed metadata for each tape in the collection. Upon receiving the tapes, DPC staff set to boxing them for shipment to the vendor. As of this writing, the boxes are snugly wrapped on a pallet in Perkins Shipping & Receiving, where they will soon begin their journey to a digital format.
The wait has begun! In eight to twelve weeks we anticipate receiving the digital files, at which point we will perform quality control (QC) on each one before sending them off for captioning. As the captions are returned, we will run through a second round of QC. From there, the files will be ingested into the Duke Digital Repository, at which point our job is complete. Of course, we still have the visual materials to contend with, but we’ll save that for another blog!
As we creep closer to the two-year mark of the COVID-19 pandemic and the varying degrees of restrictions that have come with it, the DPC will continue to focus on fulfilling patron reproduction requests, which have comprised the bulk of our work for some time now. We are proud to support researchers by facilitating digital access to materials, and we are equally excited to have begun work on a project of the scale and cultural impact that is Behind the Veil. When finished, this collection will be accessible for all to learn from and meditate on—and that’s what it’s all about.
One of the greatest challenges to digitizing analog moving-image sources such as videotape and film reels isn’t the actual digitization. It’s the enormous file sizes that result, and the high costs associated with storing and maintaining those files for long-term preservation. For many years, Duke Libraries has generated 10-bit uncompressed preservation master files when digitizing our vast inventory of analog videotapes.
Unfortunately, one hour of uncompressed video can produce a 100 gigabyte file. That’s at least 50 times larger than an audio preservation file of the same duration, and about 1000 times larger than most still image preservation files. That’s a lot of data, and as we digitize more and more moving-image material over time, the long-term storage costs for these files can grow exponentially.
To help offset this challenge, Duke Libraries has recently implemented the FFV1 video codec as its primary format for moving image preservation. FFV1 was first created as part of the open-source FFmpeg software project, and has been developed, updated and improved by various contributors in the Association of Moving Image Archivists (AMIA) community.
FFV1 enables lossless compression of moving-image content. Just like uncompressed video, FFV1 delivers the highest possible image resolution, color quality and sharpness, while avoiding the motion compensation and compression artifacts that can occur with “lossy” compression. Yet, FFV1 produces a file that is, on average, 1/3 the size of its uncompressed counterpart.
FFV1 produces a file that is, on average, 1/3 the size of its uncompressed counterpart. Yet, the audio & video content is identical, thanks to lossless compression.
The algorithms used in lossless compression are complex, but if you’ve ever prepared for a fall backpacking trip, and tightly rolled your fluffy goose-down sleeping bag into one of those nifty little stuff-sacks, essentially squeezing all the air out of it, you just employed (a simplified version of) lossless compression. After you set up your tent, and unpack your sleeping bag, it decompresses, and the sleeping bag is now physically identical to the way it was before you packed.
Yet, during the trek to the campsite, it took up a lot less room in your backpack, just like FFV1 files take up a lot less room in our digital repository. Like that sleeping bag, FFV1 lossless compression ensures that the compressed video file is mathematically identical to it’s pre-compressed state. No data is “lost” or irreversibly altered in the process.
Duke Libraries’ Digital Production Center utilizes a pair of 6-foot-tall video racks, which house a current total of eight videotape decks, comprised of a variety of obsolete formats such as U-matic (NTSC), U-matic (PAL), Betacam, DigiBeta, VHS (NTSC) and VHS (PAL, Secam). Each deck is converted from analog to digital (SDI) using Blackmagic Design Mini Converters.
The SDI signals are sent to a Blackmagic Design Smart Videohub, which is the central routing center for the entire system. Audio mixers and video transcoders allow the Digitization Specialist to tweak the analog signals so the waveform, vectorscope and decibel levels meet broadcast standards and the digitized video is faithful to its analog source. The output is then routed to one of two Retina 5K iMacs via Blackmagic UltraStudio devices, which convert the SDI signal to Thunderbolt 3.
FFV1 video digitization in progress in the Digital Production Center.
Because no major company (Apple, Microsoft, Adobe, Blackmagic, etc.) has yet adopted the FFV1 codec, multiple foundational layers of mostly open-source systems software had to be installed, tested and tweaked on our iMacs to make FFV1 work: Apple’s Xcode, Homebrew, AMIA’s vrecord, FFmpeg, Hex Fiend, AMIA’s ffmprovisr, GitHub Desktop, MediaInfo, and QCTools.
FFV1 operates via terminal command line prompts, so some understanding of programming language is helpful to enter the correct prompts, and be able to decipher the terminal logs.
The FFV1 files are “wrapped” in the open source Matroska (.mkv) media container. Our FFV1 scripts employ several degrees of quality-control checks, input logs and checksums, which ensure file integrity. The files can then be viewed using VLC media player, for Mac and Windows. Finally, we make an H.264 (.mp4) access derivative from the FFV1 preservation master, which can be sent to patrons, or published via Duke’s Digital Collections Repository.
An added bonus is that, not only can Duke Libraries digitize analog videotapes and film reels in FFV1, we can also utilize the codec (via scripting) to target a large batch of uncompressed video files (that were digitized from analog sources years ago) and make much smaller FFV1 copies, that are mathematically lossless. The script runs checksums on both the original uncompressed video file, and its new FFV1 counterpart, and verifies the content inside each container is identical.
Now, a digital collection of uncompressed masters that took up 9 terabytes can be deleted, and the newly-generated batch of FFV1 files, which only takes up 3 terabytes, are the new preservation masters for that collection. But no data has been lost, and the content is identical. Just like that goose-down sleeping bag, this helps the Duke University budget managers sleep better at night.
The Digital Production Center (DPC) is looking to hire a Digitization Specialist to join our team! The DPC team is on the forefront of enabling students, teachers, and researchers to continue their research by digitizing materials from our library collections. We get to work with a variety of unique and rare materials (in a multitude of formats), and we use professional equipment to get the work done. Imagine working on digitizing papyri and comic books – the spectrum is far and wide! Get a glimpse of the collections that have been digitized by DPC staff by checking out our Duke Digital Collections.
Also, the people are really nice (and right now, we’re working in a socially distanced manner)!
More information about the job description can be found here. The successful candidate should be detailed-oriented, possess excellent organizational, project management skills, have scanning experience, and be able to work independently and effectively in a team environment. This position is part of the Digital Collections and Curation Services department and will report to the Digital Production Services manager.
More information about Duke’s benefit package can be found at https://hr.duke.edu/benefits. For more information and to apply, please submit an electronic resume, cover letter, and a list of 3 references to https://library.duke.edu/about/jobs/digitizationspecialist. Review of applications will begin immediately and will continue until the position is filled.
Earlier this year and prior to the pandemic, Digital Production Center (DPC) staff piloted an alternative approach to digitize patron requests with the Rubenstein Library’s Research Services (RLRS) team. The previous approach was focused on digitizing specific items that instruction librarians and patrons requested, and these items were delivered directly to that person. The alternative strategy, the Folder Level digitization approach, involves digitizing the contents of the entire folder that the item is contained in, ingesting these materials to the Duke Digital Repository (to enable Duke Library staff to retrieve these items), and when possible, publishing these materials so that they are available to anyone with internet access. This soft launch prepared us for what is now an all-hands-on-deck-but-in-a-socially-distant-manner digitization workflow.
Giao Luong Baker assessing folders in the DPC.
Since returning to campus for onsite digitization in late June, the DPC’s primary focus has been to perfect and ramp up this new workflow. It is important to note that the term “folder” in this case is more of a concept and that its contents and their conditions vary widely. Some folders may have 2 pages, other folders have over 300 pages. Some folders consists of pamphlets, notebooks, maps, papyri, and bound items. All this to say that a “folder” is a relatively loose term.
Like many initiatives at Duke Libraries, Folder Level Digitization is not just a DPC operation, it is a collaborative effort. This effort includes RLRS working with instructors and patrons to identify and retrieve the materials. RLRS also works with Rubenstein Library Technical Services (RLTS) to create starter digitization guides, which are the building blocks for our digitization guide. Lastly, RLRS vets the materials and determines their level of access. When necessary, Duke Library’s Conservation team steps in to prepare materials for digitization. After the materials are digitized, ingest and metadata work by the Digital Collections and Curation Services as well as the RLTS teams ensure that the materials are preserved and available in our systems.
Kristin Phelps captures a color target.
Doing this work in the midst of a pandemic requires that DPC work closely with the Rubenstein Library Access Services Reproduction Team (a section of RLRS) to track our workflow using a Google Doc. We track the point where the materials are identified by RLRS, through multiple quarantine periods, scanning, post processing, file delivery, to ingest. Also, DPC staff are digitizing in a manner that is consistent with COVID-19 guidelines. Materials are quarantined before and after they arrive at the DPC, machines and workspaces are cleaned before and after use, capture is done in separate rooms, and quality control is done off site with specialized calibrated monitors.
Since we started Folder Level digitization, the DPC has received close to 200 unique Instruction and Patron requests from RLRS. As of the publication of this post, 207 individual folders (an individual request may contain several folders) have been digitized. In total, we’ve scanned and quality controlled over 26,000 images since we returned to campus!
By digitizing entire folders, we hope this will allow for increased access to the materials without risking damage through their physical handling. So far we anticipate that 80 new digital collections will be ingested to the Duke Digital Repository. This number will only grow as we receive more requests. Folder Level Digitization is an exciting approach towards digital collection development, as it is directly responsive to instruction and researcher needs. With this approach, it is access for one, access for all!
This began as a quest for images of people engaging in recreational activities. Facing copious time indoors with limited places to go, many are looking for respite. I thought it would be uplifting to find pictures of people having fun. While combing through Duke University Libraries’ numerous digital collections in search of such images, several photos caught my eye. I clicked through hundreds of images reading their captions and summaries. Driven to delve deeper into collections for the story behind those smiling faces. As I sought these stories, I recalled the words of James Baldwin:
“You think your pain and your heartbreak are unprecedented in the history of the world, but then you read.”
Here were the lived experiences of people striving, aspiring, and persevering.
What started as a search for people pursuing pastimes quickly pivoted. It transformed into a search for people – smiling, laughing and hoping despite their circumstances. Presented below is a small harvest of photographs that inspired this post, including embedded links to their collections. As they did for me, I hope these photos may serve as a gateway to explore these inspired collections.
This image is from a series of photographs taken by James Karales between 1953 and 1957 in Rendville, Ohio, a small mining town which was one of the first racially integrated towns in the U.S.
African would-be immigrants play soccer in an enclosed compound at the Safi detention centre outside Valletta July 15, 2008. Around 1,500 illegal immigrants are currently held in detention in Malta for periods of up to 18 months. Though their intention was to reach Italy, most found themselves in Malta when they were rescued by the Maltese Armed Forces when they found themselves in difficulties while on their way to reach European soil from Africa.
Men eating at cooperative farm, central Cuba
Notes from the Duke University Libraries Digital Projects Team