


Everyone knows that Twitter limits each post to 140 characters. Early criticism has since cooled and most people agree it’s a helpful constraint, circumvented through clever (some might say better) writing, hyperlinks, and URL-shorteners. But as a reader of tweets, how do you know what lies at the other end of a shortened link? What entices you to click? The tweet author can rarely spare the characters to attribute the source site or provide a snippet of content, and can’t be expected to attach a representative image or screenshot.
Our webpages are much more than just mystery destinations for shortened URLs. Twitter agrees: its developers want help understanding what the share-worthy content from a webpage actually is in order to present it in a compelling way alongside the 140 characters or less. Enter two library hallmarks: vocabularies and metadata.
This week, we added Twitter Card metadata in the <head> of all of our digital collections pages and in our library blogs. This data instantly made all tweets and retweets linking to our pages far more interesting. Check it out!
For the blogs, tweets now display the featured image, post title, opening snippet, site attribution, and a link to the original post. Links to items from digital collections now show the image itself (along with some item info), while links to collections, categories, or search results now display a grid of four images with a description underneath. See these examples:
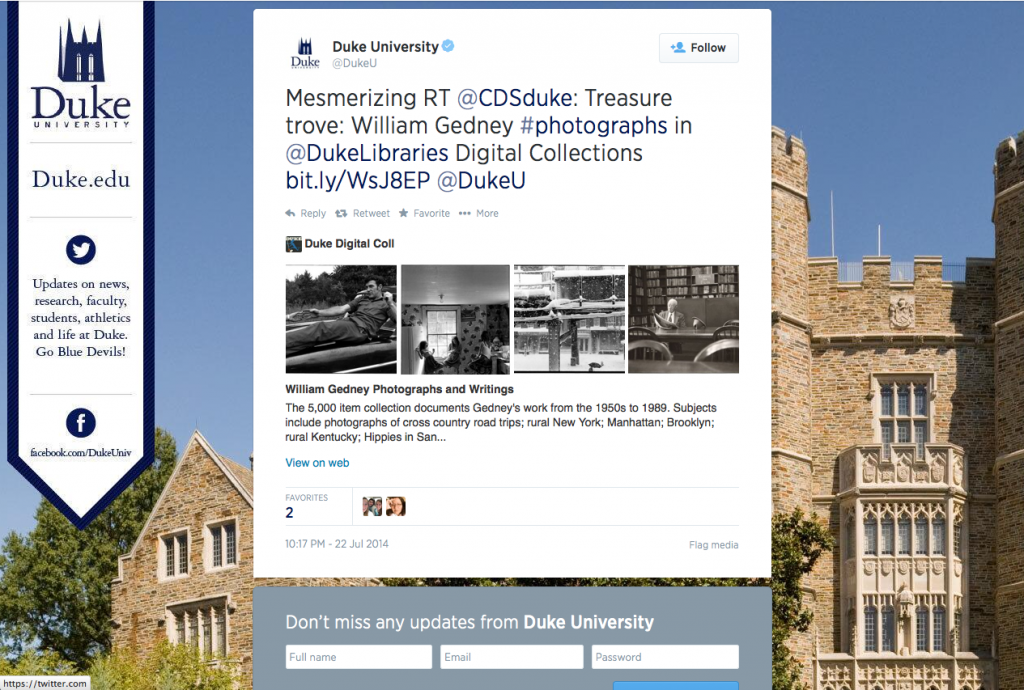
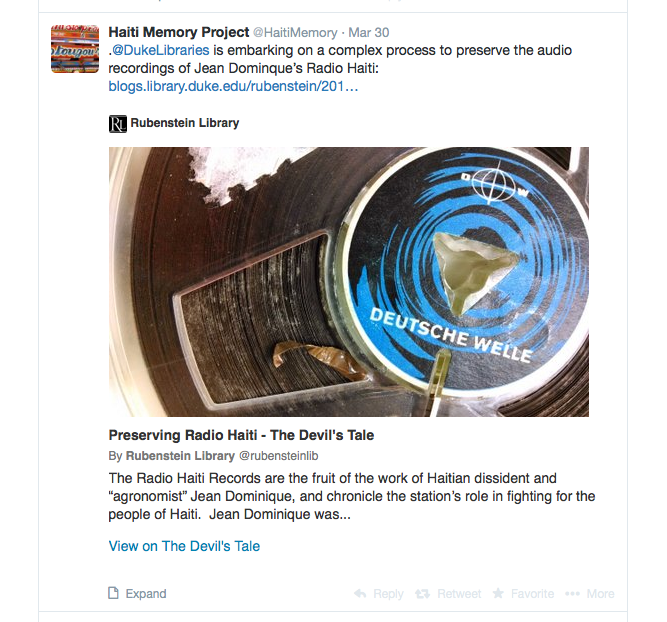

Why This Matters
In 2013-14, social media platforms accounted for 10.1% of traffic to our blogs (~28,000 visits in 2013-14, 11,300 via Twitter), and 4.3% of visits to our digital collections (~17,000 visits, 1,000 via Twitter). That seems low, but perhaps it’s because of the mystery link phenomenon. These new media-rich tweets have the potential to increase our traffic through these channels by being more interesting to look at and more compelling to click. We’re looking forward to finding out whether they do.
And regardless of driving clicks, there are two other benefits of Twitter Cards that we really care about in the library: context and attribution. We love it when our collections and blog posts are shared on Twitter. These tweets now automatically give some additional information and helpfully cite the source.
How to Get Your Own Twitter Cards
The Manual Way
If you’re manually adding tags like we’ve done in our Digital Collections templates, you can “View Source” on any of our pages to see what <meta> tags make the magic happen. Moz also has some useful code snippets to copy, with links to validator tools so you can make sure you’re doing it correctly.

WordPress
Since our blogs run on WordPress, we were able to use the excellent WordPress SEO plugin by Yoast. It’s helpful for a lot of things related to search engine optimization, and it makes this social media optimization easy, too.
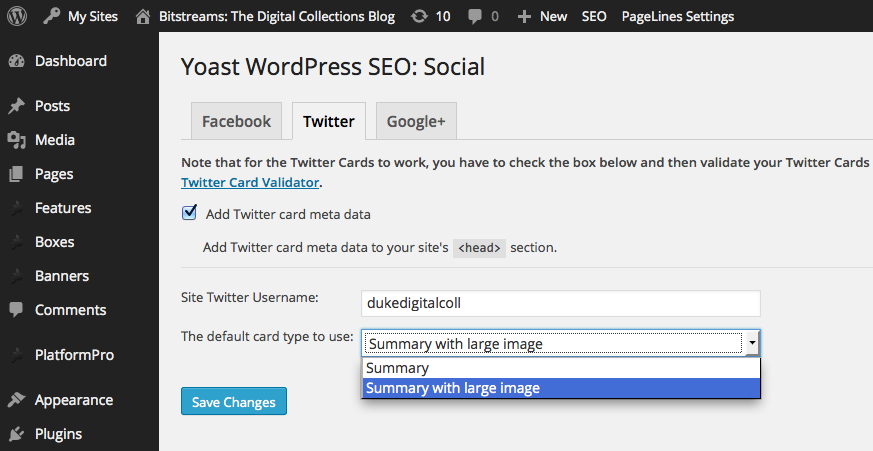
Once your tags are in place, you just need to validate an example from your domain using the Twitter Card Validator before Twitter will turn on the media-rich tweets. It doesn’t take long at all: ours began appearing within a couple hours. The cards apply retroactively to previous tweets, too.
Related Work
Our addition of Twitter Card data follows similar work we have done using semantic markup in our Digital Collections site using the Open Graph and Schema.org vocabularies. Open Graph is a standard developed by Facebook. Similar to Twitter Card metadata, OG tags inform Facebook what content to highlight from a linked webpage. Schema.org is a vocabulary for describing the contents of web pages in a way that is helpful for retrieval and representation in Google and other search engines.
All of these tools use RDFa syntax, a key cornerstone of Linked Data on the web that supports the description of resources using whichever vocabularies you choose. Google, Twitter, Facebook, and other major players in our information ecosystem are now actively using this data, providing clear incentive for web authors to provide it. We should keep striving to play along.


