

 Over the past year and a half, among our many other projects, we have been experimenting with a creative new approach to powering searches within digital collections and finding aids using Google’s index of our structured data. My colleague Will Sexton and I have presented this idea in numerous venues, most recently and thoroughly for a recorded ASERL (Association of Southeastern Research Libraries) webinar on June 6, 2013.
Over the past year and a half, among our many other projects, we have been experimenting with a creative new approach to powering searches within digital collections and finding aids using Google’s index of our structured data. My colleague Will Sexton and I have presented this idea in numerous venues, most recently and thoroughly for a recorded ASERL (Association of Southeastern Research Libraries) webinar on June 6, 2013.
We’re eager to share what we’ve learned to date and hope this new blog will make a good outlet. We’ve had some success, but have also encountered some considerable pitfalls along the way.
What We Set Out to Do
I won’t recap all the fine details of the project here, but in a nutshell, here are the problems we’ve been attempting to address:
- Maintaining our own Solr index takes a ton of time to do right. We don’t have a ton of time.
- Staff have noted poor relevance rank and poor support for search using non-Roman characters.
- Our digital collections search box is actually used sparsely (in only 12% of visits).
- External discovery (e.g., via Google) is of equal or greater importance vs. our local search for these “inside-out” resources.
Here’s our three-step strategy:
- Embed schema.org data in our HTML (using RDFa Lite)
- Get Google to index all of our embedded structured data
- Use Google’s index of our structured data to power our local search for finding aids & digital collections
Where We Are Today
We mapped several of our metadata fields to schema.org terms, then embedded that schema.org data in all 74,000 digital object pages and all 2,100 finding aids. We’re now using Google’s index of that data to power our default search for:
- All of our finding aids (a.k.a. collection guides). [Example search for “photo”]
- One digital collection: Sidney Gamble Photographs. [Example search for “beijing”]
Though the strategy is the same, some of the implementation details are different between our finding aids and digital collections applications. Here are the main differences:
| Site | Service | Google CSE API | Max Results per Query |
|---|---|---|---|
| Finding Aids | Google Custom Search (free) | JS v1.0 | 100 |
| Digital Collection | Google Site Search (premium version of Custom Search) |
XML API | 1,000 |
Finding Aids Search
Embedding the Data. We kept it super simple here. We labeled every finding aid page a ‘CollectionPage’ and tagged only a few properties: name, description, creator, and if present, a thumbnailUrl for a collection with digitized content.
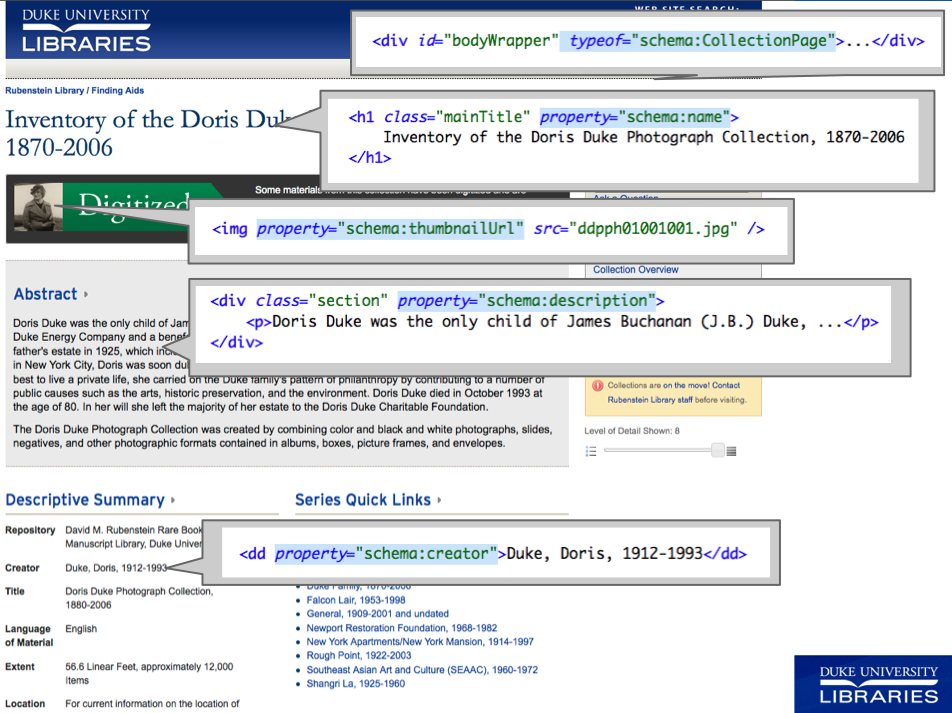
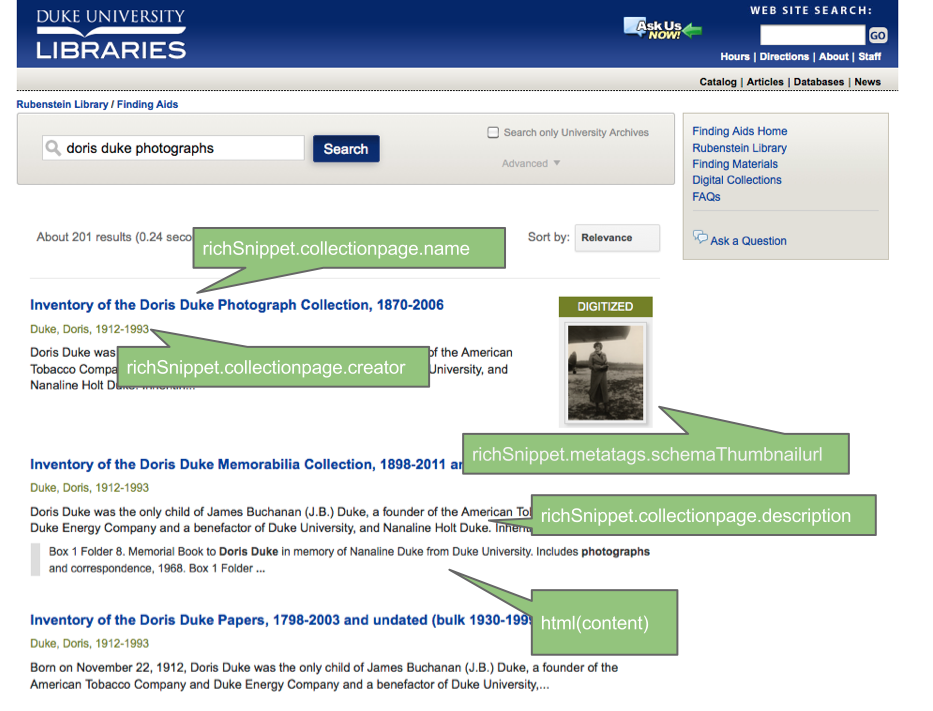
Rendering Search Results Using Google’s Index.
This worked great. We used a Google Custom Search Element (CSE) and created our own “rich snippets” using the CSE JavaScript API (v1.0) and the handy templating options Google provides. You can simply “View Source” to see the underlying code: it’s all there in the HTML. The HTML5 data- attributes set all the content and the display logic.
Digital Collections Search: Sidney D. Gamble Collection
Embedding the Data.
Our digital collections introduce more complexity in the structured data than we see in our finding aids. Naturally, we have a wide range of item types with diverse metadata. We want our markup to represent the relationship of an item to its source collection. The item, the webpage that it’s on, the collection it came from, and the media files associated with it all have properties that can be expressed using schema.org terms. So, we tried it all.[1]
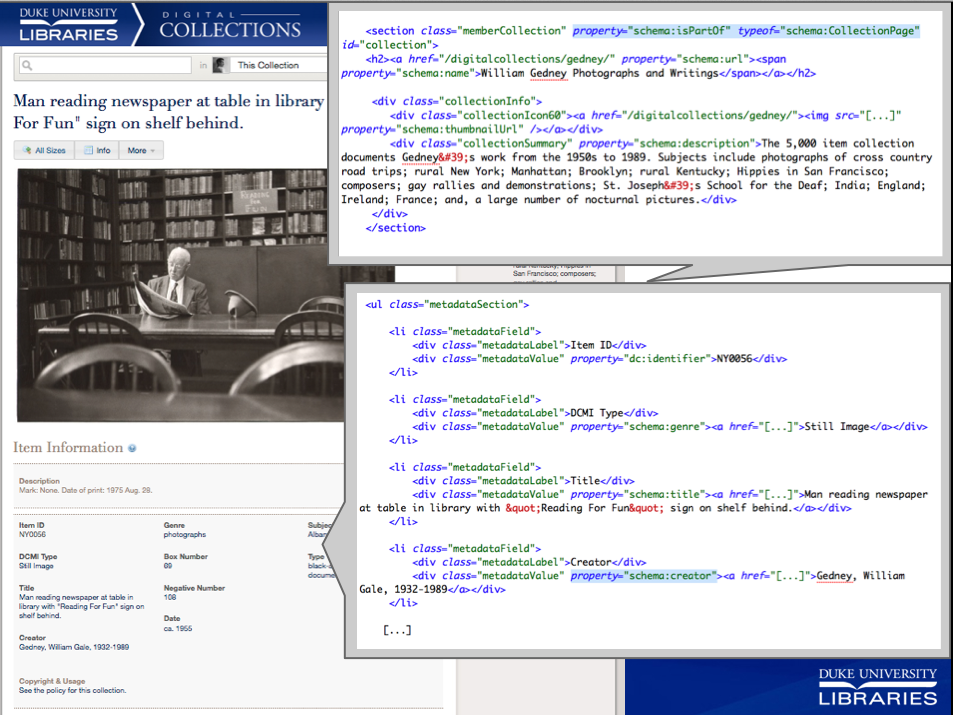
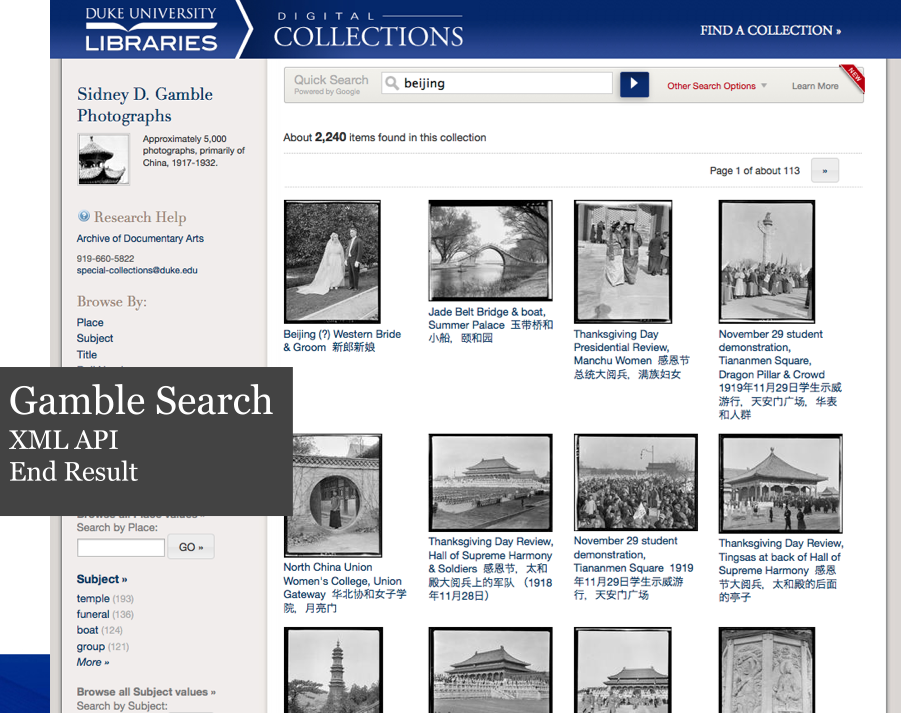
Rendering Search Results Using Google’s Index.
For the Gamble collection, we succeeded in making queries hit Google’s XML API while sustaining the look of our existing search results. Note that the facets in the left side aren’t powered via Google–we haven’t gotten far enough in our experiment to work with filtering the result set based on the structured data, but that’s possible to do.
Outcomes
The Good
We’ve been pleased with the ability to make our own rich snippets and highly customize the appearance of search results without having to do a ton of development. Getting our structured data back from Google’s index to work with is an awesome service and developing around the schema.org properties that we were already providing has been a nice way to kill two birds with one stone.
For performance, Google CSE is working well in both the finding aids and the Gamble digital collection search for these purposes:
- getting the most relevant content presented early on in the search result
- getting results quickly
- handling non-Roman characters in search terms
- retrieving a needle in a haystack — an item or handful of items that contain some unique text
The Gotchas
While Google CSE shows relevant results quickly, we’re finding it’s not a good fit for exploratory searching when either of these aspects is important:
- getting a stable and precise count of relevant results
- browsing an exhaustive list of results that match a general query
Be careful: queries max out at 100 results with the JavaScript APIs or 1,000 results when using the XML API. Those limits aren’t obvious in the documentation, yet they might be a deal-breaker for some potential uses.
For queries with several pages of hits, you may get an estimated result count that’s close, but unfortunately things occasionally and inexplicably go sour as you navigate from from one result page to the next. E.g., the Gamble digital collection query ‘beijing‘ shows about 2,100 results (which is in the ballpark of what Solr returns), yet browse a few pages in and the result set will get truncated severely: you may only be able to actually browse about 200 of the results without issuing more specific query terms.
Other Considerations
Impact on External Discovery
Traffic to digital collections via external search engines has mostly climbed steadily every quarter for the past few years, from 26% of all visits in Jul-Sep 2011 up to 44% from Jan-Mar 2014 (to date) [2]. We entered schema.org tags in Oct 2012, however we don’t know whether adding that data has contributed at all to this trend. Does schema.org data impact relevance? It’s hard to tell.
Structured Data Syntax + Google APIs
Though RDFa Lite and microdata should be equally acceptable ways to add schema.org tags, Google’s APIs actually work better with microdata if there are nested item types.[3] And regardless of microdata or RDFa, the Google CSE JavaScript API unfortunately can’t access more than one value for any given property, so that can be problematic [4].
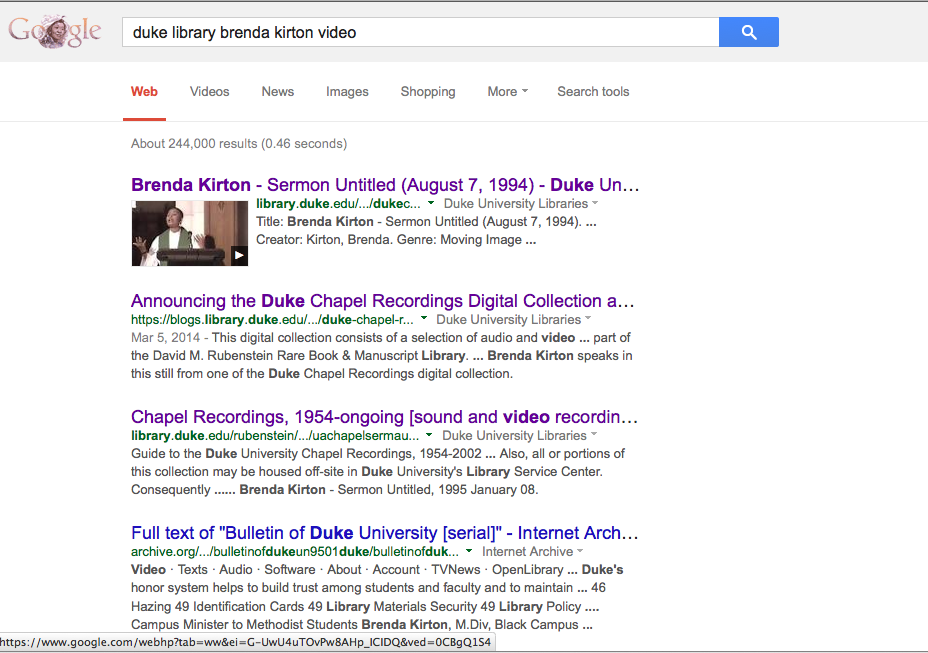
Rich Snippets in Big Google
We’re seeing Google render rich snippets for our videos, because we’ve marked them as schema.org VideoObjects with properties like thumbnailUrl. That’s encouraging! Perhaps someday Google will render better snippets for things like photographs (of which we have a bunch), or maybe even more library domain-specific materials like digitized oral histories, manuscripts, and newspapers. But at present, none of our other objects seem to trigger nice snippets like this.
Footnotes
[1] We represented item pages as schema.org “ItemPage” types using the “ispartOf” property to relate the item page to its corresponding “CollectionPage”. We made the ItemPage “about” a “CreativeWork”. Then we created mappings for many of our metadata fields to CreativeWork properties, e.g., creator, contentLocation, genre, dateCreated.
[2] Digital Collections External Search Traffic by Quarter
Quarter Visits via Search % Visits via Search
Jul – Sep 2011 26,621 25.97%
Oct – Dec 2011 32,191 29.59%
Jan – Mar 2012 41,048 32.16%
Apr – Jun 2012 33,872 34.49%
Jul – Sep 2012 28,250 32.40%
Oct – Dec 2012 38,472 36.52% <– entered schema.org tags Oct 19, 2012
Jan – Mar 2013 39,948 35.29%
Apr – Jun 2013 36,641 38.30%
Jul – Sep 2013 35,058 41.88%
Oct – Dec 2013 46,082 43.98%
Jan – Mar 2014 47,123 43.93%
[3] For example, if your RDFa indicates that “an ItemPage is about a CreativeWork whose creator is Sidney Gamble”– the creator of the creative work is not accessible to the API since the CreativeWork is not a top-level item. To get around that, we had to duplicate all the CreativeWork properties in the HTML <head>, which is unnatural and a bit of a hack.
[4] Google’s CSE JS APIs also don’t let us retrieve the data when there are multiple values specified for the same field. For a given CreativeWork, we might have six locations that are all important to represent: China; Beijing (China); Huabei xie he nu zi da xue (Beijing, China); 中国; 北京; 华北协和女子大学. The JSON returned by the API only contains the first value: ‘China’. This, plus the result count limit, made the XML API our only viable choice for digital collections.
But if you are not able to implement schema.org recommendation properly in your website then let me assure you, you are going to hit it much more than anything else as it will generate a lots of error in google webmaster central and thus you will receive a very less traffic. So instead of using schema.org i would love to add some other coding standard. What do you think about this? Waiting for your kind attention in this case.
@rakesh The RDFa Lite syntax has the benefit of being pretty simple, so it’s not hard to add code “properly.” There’s seemingly a lot of wiggle room for how one chooses to markup content. The Schema.org vocabulary can easily be used alongside other vocabularies (e.g., OpenGraph, Dublin Core)–even in the same HTML elements. The top search engines have declared schema.org to be the best vocabulary for optimizing the semantic data in your webpages for their indexes.
Fantastic blog post. My head was nodding the whole time.