Last fall, I wrote about how we were embarking on a large-scale remediation of our digital collections metadata in preparation for migrating those collections to the Duke Digital Repository. I started remediation at the beginning of this calendar year, and it’s been at times a slow-going but ultimately pretty satisfying experience. I’m always interested in hearing about how other people working with metadata actually do their work, so I thought I would share some of the tools and techniques I have been using to conduct this project.
First things first: documentation
The metadata task group charged with this work undertook a broad review and analysis of our data, and created a giant google spreadsheet containing all of the fields currently in use in our collections to document the following:
- What collections used the field?
- Was usage consistent within/across collections?
- What kinds of values were used? Controlled vocabularies or free text?
- How many unique values?
Based on this analysis, the group made recommendations for remediation of fields and values, which were documented in the spreadsheet as well.
OpenRefine
I often compose little love notes in my head to OpenRefine, because my life would be much harder without it in that I would have to harass my lovely developer colleagues for a lot more help. OpenRefine is a powerful tool for analyzing and remediating messy data, and allows me to get a whole lot done without having to do much scripting. It was really useful for doing the initial review and analysis: here’s a screen shot of how I could use the facets to, for example, limit by the Dublin Core contributor property, see which fields are mapped to contributor, which collections use contributor fields, and what the array of values looks like.
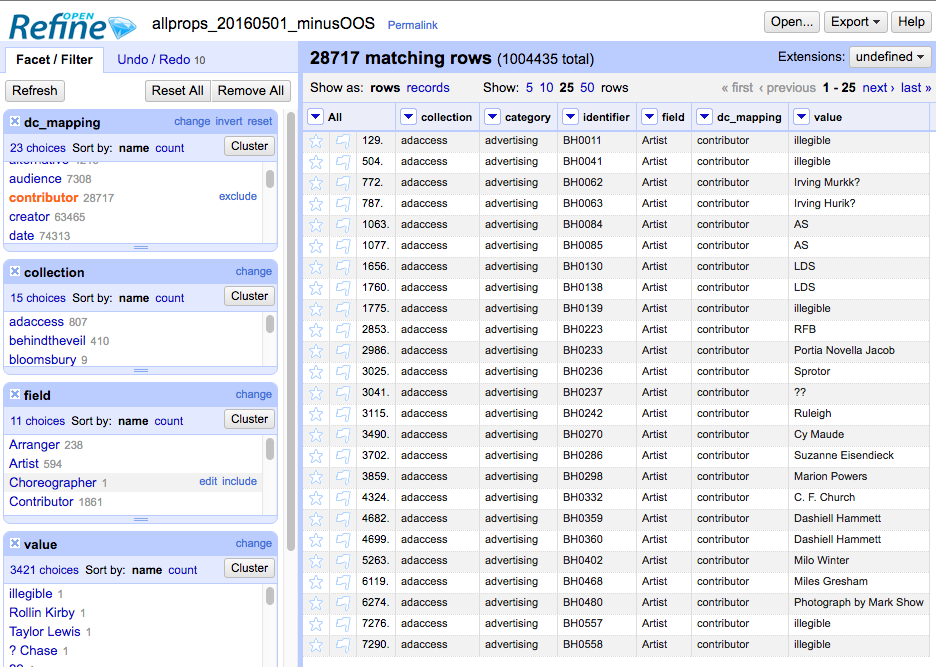
The facet feature is also great for performing batch level operations like changing field names and editing values. The cluster and edit feature has been really useful for normalizing values so that they will function well as facetable fields in the user interface. OpenRefine also allows for bulk transformations using regular expressions, so I can make changes based on patterns, rather than specific strings. Eventually I want to take advantage of it’s ability to reconcile data against external sources, too, but it will be more effective if we get through the cleaning process first.
TextWrangler
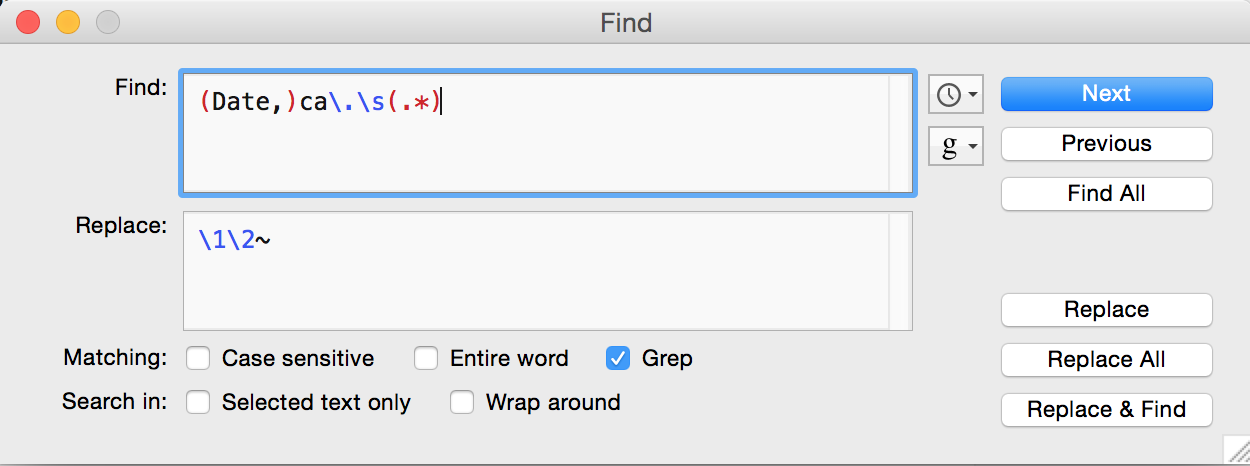
For some of the more complex transformations I’ve found it is easier and faster to use regular expressions in a text editor – I’ve been using Text Wrangler, which is free and very handy. Here’s an example of one of the regular expressions I used when converting date values to the Extended Date Time Format, which we’ve covered on this blog here and here, and, um, here (what can I say? We love EDTF):
Ruby Scripting
And in a few cases, like where I’ve needed to swap out a lot of individual values with other ones, I’ve had to dip my toes into Ruby scripting. I’ve done some self educating on Ruby via Duke’s access to Lynda.com courses, but I mostly have benefited from the very kind and patient developer on our task group. I also want to make a shout out to RailsBridge, which is an organization dedicated to making tech more diverse by teaching free workshops on Rails and Ruby for underrepresented groups of people in tech. I attended a full day Ruby on Rails workshop organized by RailsBridge Triangle here in Raleigh N.C . and found it to be really approachable and informative, and would encourage anyone interested in building out her/his tech skills to look for local opportunities.