
How We Got Here: A terribly simplistic history of library metadata
Managing the description of library collections (especially “special” collections) is an increasingly complex task. In the days of yore, we bought books and other things, typed up or purchased catalog cards describing those things (metadata), and filed the cards away. It was tedious work, but fairly straightforward. If you wanted to know something about anything in the library’s collection, you went to the card catalog. Simple.
Some time in the 1970s or 1980s we migrated all (well, most) of that card catalog description to the ILS (Integrated Library System). If you wanted to describe something in the library, you made a MARC record in the ILS. Patrons searched those MARC records in the OPAC (the public-facing view of the ILS). Still pretty simple. Sure, we maintained other paper-based tools for managing description of manuscript and archival collections (printed finding aids, registers, etc.), but until somewhat recently, the ILS was really the only “system” in use in the library.

From the 1990s on things got complicated. We started making EAD and MARC records for archival collections. We started digitizing parts of those collections and creating Dublin Core records and sometimes TEI for the digital objects. We created and stored library metadata in relational databases (MySQL), METS, MODS, and even flat HTML. As library metadata standards proliferated, so too did the systems we used the create, manage, and store that metadata.
Now, we have an ILS for managing MARC-based catalog records, ArchivesSpace for managing more detailed descriptions of manuscript collections, a Fedora (Hydra) repository for managing digital objects, CONTENTdm for managing some other digital objects, and lots of little intermediary descriptive tools (spreadsheets, databases, etc.). Each of these systems stores library metadata in a different format and in varying levels of detail.
So what’s the problem and what are we doing about it?
The variety of metadata standards and systems isn’t the problem. What is the problem–a very painful and time-consuming problem–is having to maintain and reconcile description of the same thing (a manuscript, a folder of letters, an image, an audio file, etc.) across all these disparate metadata formats and systems. It’s a metadata synchronization problem and it’s a big one.
For the past four months or so, a group of archivists and developers here in the library have been meeting regularly to brainstorm ways to solve or at least help alleviate some of our metadata synchronization problems. We’ve been calling our group “The Synchronizers.”
What have The Synchronizers been up to? Well, so far we’ve been trying to tackle two pieces of the synchronization conundrum:
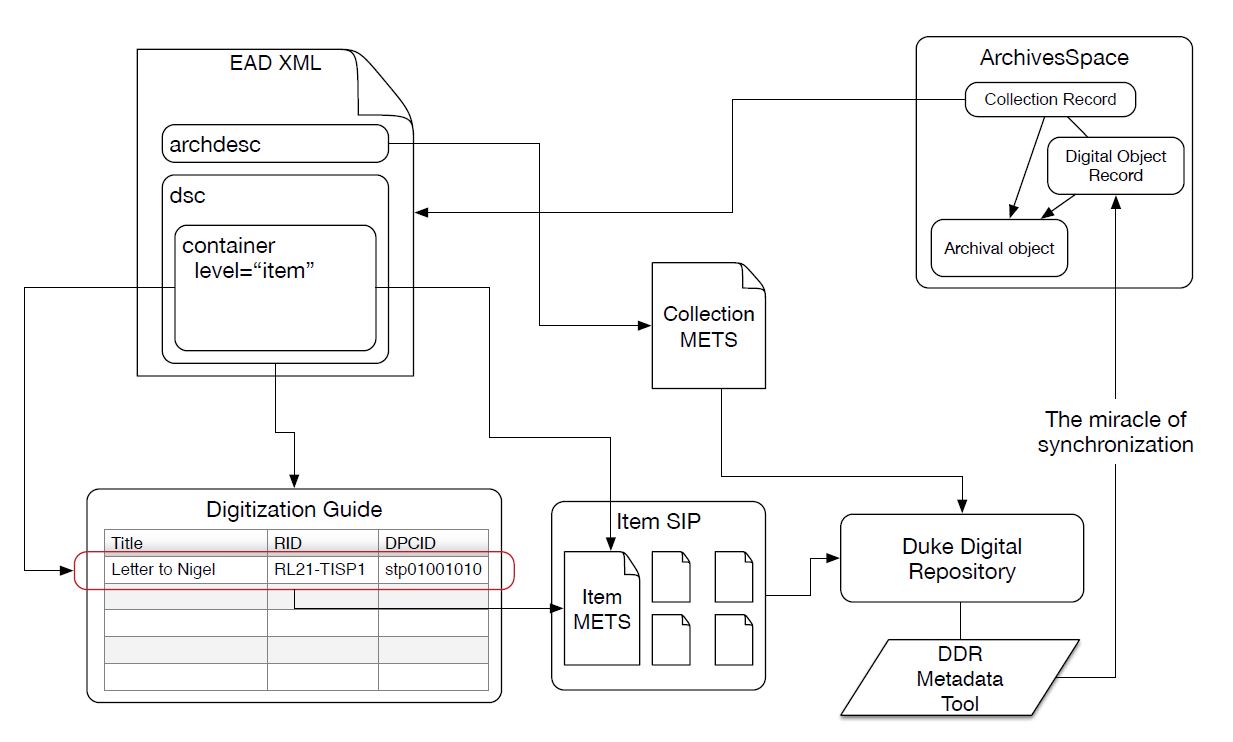
Problem 1 (the big one): Keeping metadata for special collections materials in sync across ArchivesSpace, the digitization process, and our Hydra repository.
Ideally, we’d like to re-purpose metadata from ArchivesSpace to facilitate the digitization process and also keep that metadata in sync as items are digitized, described more fully, and ingested into our Hydra repository. Fortunately, we’re not the only library trying to tackle this problem. For more on AS/Hydra integration, see the work of the Hydra Archivists Interest Group.
Below are a couple of rough sketches we drafted to start thinking about this problem at Duke.

In addition to these systems integration diagrams, I’ve been working on some basic tools (scripts) that address two small pieces of this larger problem:
- A script to auto-generate digitization guides by extracting metadata from ArchivesSpace-generated EAD files (digitization guides are simply spreadsheets we use to keep track of what we digitize and to assign identifiers to digital objects and files during the digitization process).
- A script that uses a completed digitization guide to batch-create digital object records in ArchivesSpace and at the same time link those digital objects to the descriptions of the physical items (the archival object records in ArchivesSpace-speak). Special thanks to Dallas Pillen at the University of Michigan for doing most of the heavy lifting on this script.
Problem 2 (the smaller one): Using ArchivesSpace to produce MARC records for archival collections (or, stopping all that cutting and pasting).
In the past, we’ve had two completely separate workflows in special collections for creating archival description in EAD and creating collection-level MARC records for those same collections. Archivists churned out detailed EAD finding aids and catalogers took those finding aids, and cut-and-pasted relevant sections into collection-level MARC records. It’s quite silly, really, and we need a better solution that saves time and keeps metadata consistent across platforms.
While we haven’t done much work in this area yet, we have formed a small working group of archivists/catalogers and developed the following work plan:
- Examine default ArchivesSpace MARC exports and compare those exports to current MARC cataloging practices (document differences).
- Examine differences between ArchivesSpace MARC and “native” MARC and decide which current practices are worth maintaining keeping in mind we’ll need to modify default ArchivesSpace MARC exports to meet current MARC authoring practices.
- Develop cross-walking scripts or modify the ArchivesSpace MARC exporter to generate usable MARC data from ArchivesSpace.
- Develop and document an efficient workflow for pushing or harvesting MARC data from ArchivesSpace to both OCLC and our local ILS.
- If possible, develop, test, and document tools and workflows for re-purposing container (instance) information in ArchivesSpace in order to batch-create item records in the ILS for archival containers (boxes, folders, etc).
- Develop training for staff on new ArchivesSpace to MARC workflows.
Conclusion
So far we’ve only taken baby steps towards our dream of TOTAL METADATA SYNCHRONIZATION, but we’re making progress. Please let us know if you’re working on similar projects at your institution. We’d love to hear from you.