
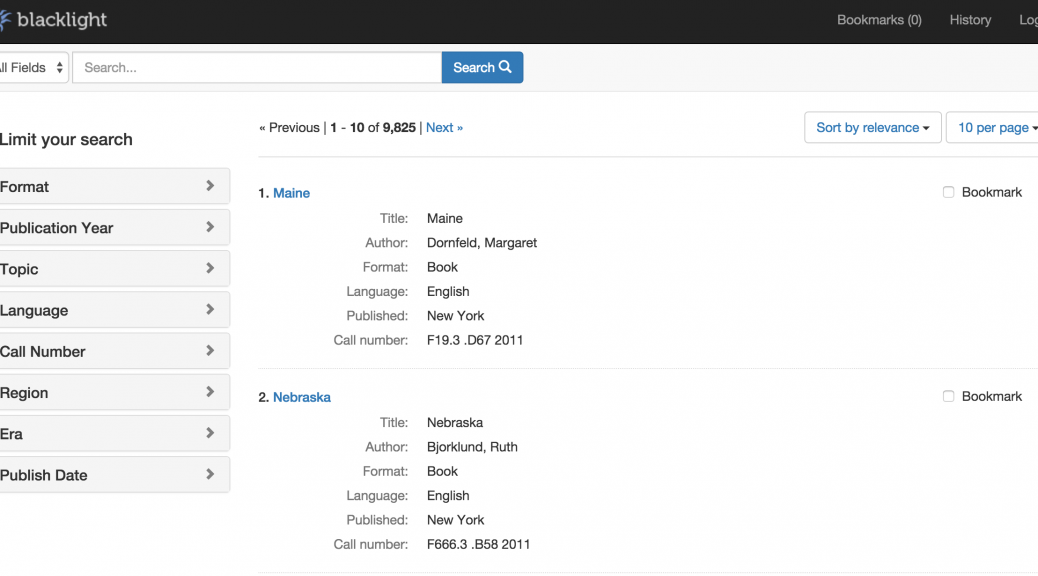
The Library’s Digital Projects Services department has been working with Digital Repository Services on a software project that will eventually replace our existing Digital Collections platform. There will be future posts announcing the new way of discovering and accessing Duke’s Digital Collections, but I want to use this post to reflect on the tools and practices we’ve been using to build this new application.
There are a few important differences between this not yet released new application and our current system. One is that Digital Collections will be part of the library’s Digital Repository, which includes a much broader range of digital items and collections. The second is that since the repository is being developed using Project Hydra, we’re using a component of the Hydra stack, Project Blacklight, as the discovery and access layer for Digital Collections.
![]()
The Blacklight Wiki explains that:
Blacklight is an open source, Ruby on Rails Engine that provides a basic discovery interface for searching an Apache Solr index, and provides search box, facet constraints, stable document urls, etc., all of which is customizable via Rails (templating) mechanisms.
The Blacklight Development Google Group has posts going back to 2009, and the GitHub repository has commits back to 2009 as well. So, the project’s been actively developed and used for a while. The Project Blacklight website maintains a list of different implementations of the software, where you can see the range of interfaces it has been used to develop.
One of the benefits of using a widely adopted open source platform is access to a community of developers who use the same software. I was able to solve many problems just by searching the Blacklight Development Google Group for answers. Blacklight made it easy to get a basic interface up and running quickly and provided a platform to add local customizations. Because the basics were already in place we were able to spend our time on more specialized features and local requirements. For example, specifying which search filters should appear for a collection and what metadata fields should be included in search were as easy as adding a few lines of configuration code to the application.

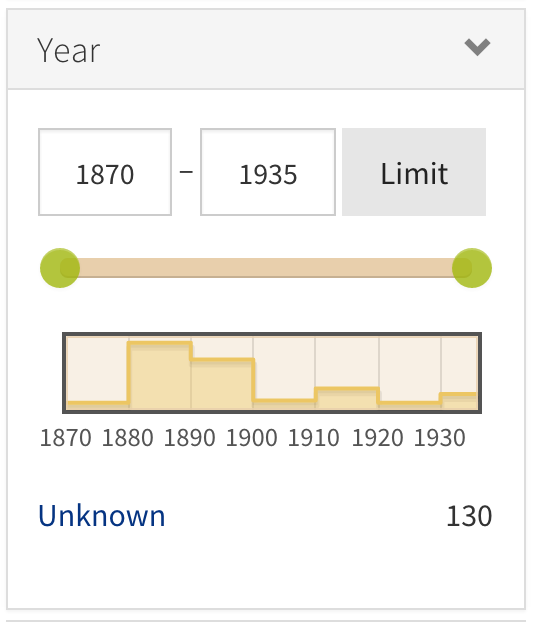
Even for some of the more specialized features, we’ve relied as much as possible on available add-ons and tools to add features to Blacklight. Because of this we’ve been able to add advanced features to the new application that did not require a large amount of development time. For example, we’re using the Blacklight Range Limit Ruby Gem to add a visual date picker with a histogram for searching the collections by year.
We also used the Blacklight Gallery Ruby Gem to add an option to view search results as a gallery with larger thumbnails.
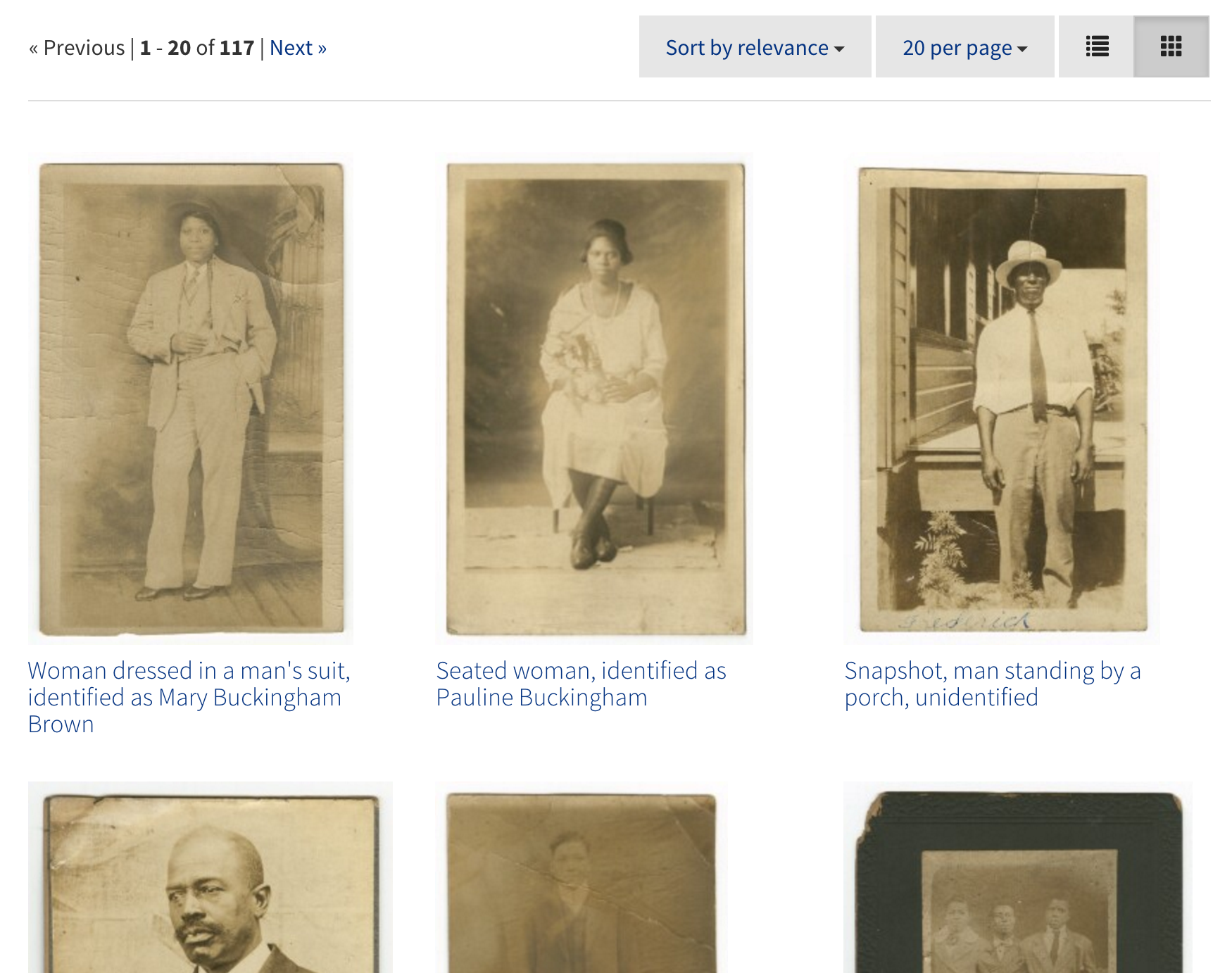
Both of these features were relatively easy to implement because we were able to make use of plugins shared with the Blacklight community.
Another new (to us) tool we’re using is the IIPImage server for serving images to the application. Because the image server automatically creates and then returns the right size image based on parameters sent in a request, we don’t have to pre-generate thumbnails of various sizes to support different displays in the application. The image server can even crop images. Because the image server stores the images as Pyramid TIFFs, we’re able to provide very smooth and fast in-browser pan and zoom of images, which works similarly to Google maps. To get a better idea of what this means for exploring high resolution images in your browser, you can explore some of the examples on the IIPImage site.
To manage this project we’ve been following Agile project management techniques, which for us meant taking an iterative approach to designing and building features of the application in two week sprints. At the beginning of each sprint we decide what we’re going to work on from a backlog of user stories, and our goal by the end of the two weeks is to have a version of the code that is working and deployed with these features implemented. Each day we have a 15-minute stand-up meeting during which each person reviews what they worked on yesterday, explains what they’re going to work on today, and then notes anything that’s blocking their progress. These quick, daily meetings have helped keep the project moving by increasing communication and helping to focus our work.
We’re still putting some pieces in place, so our new platform for publishing Digital Collections isn’t available yet, but look for it soon along with more information about the project and its first published collection.