

OpenRefine, formerly Google Refine, bills itself as “a free, open source, powerful tool for working with messy data.” As someone who works with messy data almost every day, I can’t recommend it enough. While Open Refine is a great tool for cleaning up “grid-shaped data” (spreadsheets), it’s a bit more challenging to use when your source data is in some other format, particularly XML.

As part of a recent project to migrate data from EAD (Encoded Archival Description) to ArchivesSpace, I needed to clean up about 27,000 name and subject headings spread across over 2,000 EAD records in XML. Because the majority of these EAD XML files were encoded by hand using a basic text editor (don’t ask why), I knew there were likely to be variants of the same subject and name terms throughout the corpus–terms with extra white space, different punctuation and capitalization, etc. I needed a quick way to analyze all these terms, dedup them, normalize them, and update the XML before importing it into ArchivesSpace. I knew Open Refine was the tool for the job, but the process of getting the terms 1) out of the EAD, 2) into OpenRefine for munging, and 3) back into EAD wasn’t something I’d tackled before.
Below is a basic outline of the workflow I devised, combining XSLT, OpenRefine, and, yes, Excel. I’ve provided links to some source files when available. As with any major data cleanup project, I’m sure there are 100 better ways to do this, but hopefully somebody will find something useful here.
1. Use XSLT to extract names and subjects from EAD files into a spreadsheet
I’ve said it before, but sooner or later all metadata is a spreadsheet. Here is some XSLT that will extract all the subjects, names, places and genre terms from the <controlaccess> section in a directory full of EAD files and then dump those terms along with some other information into a tab-separated spreadsheet with four columns: original_term, cleaned_term (empty), term_type, and eadid_term_source.
2. Import the spreadsheet into OpenRefine and clean the messy data!
Once you open the resulting tab delimited file in OpenRefine, you’ll see the four columns of data above, with “cleaned_term” column empty. Copy the values from the first column (original_term) to the second column (cleaned_term). You’ll want to preserve the original terms in the first column and only edit the terms in the second column so you can have a way to match the old values in your EAD with any edited values later on.
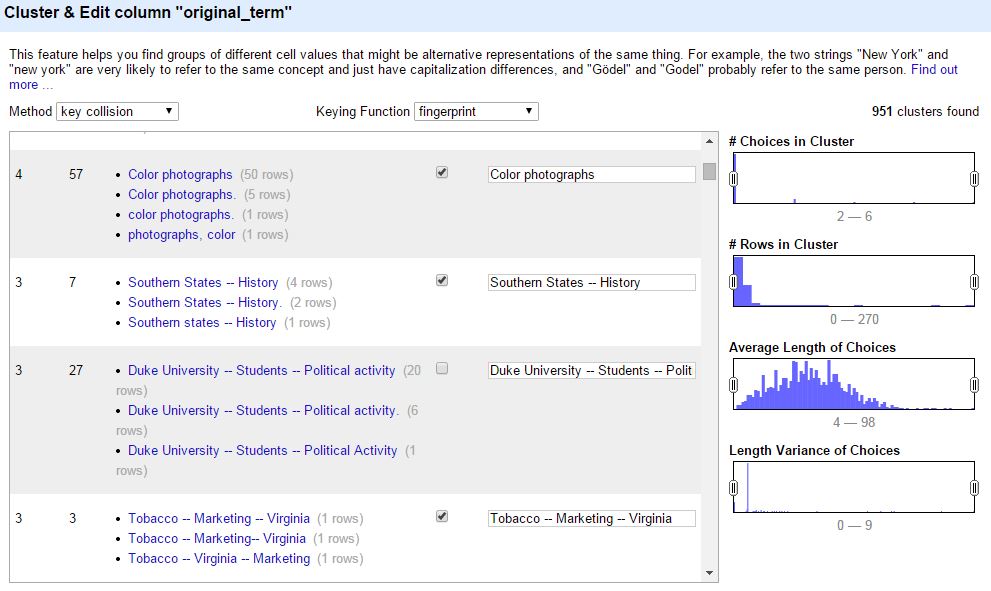
OpenRefine offers several amazing tools for viewing and cleaning data. For my project, I mostly used the “cluster and edit” feature, which applies several different matching algorithms to identify, cluster, and facilitate clean up of term variants. You can read more about clustering in Open Refine here: Clustering in Depth.
In my list of about 27,000 terms, I identified around 1200 term variants in about 2 hours using the “cluster and edit” feature, reducing the total number of unique values from about 18,000 to 16,800 (about 7%). Finding and replacing all 1200 of these variants manually in EAD or even in Excel would have taken days and lots of coffee.
In addition to “cluster and edit,” OpenRefine provides a really powerful way to reconcile your data against known vocabularies. So, for example, you can configure OpenRefine to query the Library of Congress Subject Heading database and attempt to find LCSH values that match or come close to matching the subject terms in your spreadsheet. I experimented with this feature a bit, but found the matching a bit unreliable for my needs. I’d love to explore this feature again with a different data set. To learn more about vocabulary reconciliation in OpenRefine, check out freeyourmetadata.org
3. Export the cleaned spreadsheet from OpenRefine as an Excel file
Simple enough.
4. Open the Excel file and use Excel’s “XML Map” feature to export the spreadsheet as XML.
I admit that this is quite a hack, but one I’ve used several times to convert Excel spreadsheets to XML that I can then process with XSLT. To get Excel to export your spreadsheet as XML, you’ll first need to create a new template XML file that follows the schema you want to output. Excel refers to this as an “XML Map.” For my project, I used this one: controlaccess_cleaner_xmlmap.xml
From the Developer tab, choose Source, and then add the sample XML file as the XML Map in the right hand window. You can read more about using XML Maps in Excel here.
After loading your XML Map, drag the XML elements from the tree view in the right hand window to the top of the matching columns in the spreadsheet. This will instruct Excel to map data in your columns to the proper XML elements when exporting the spreadsheet as XML.
Once you’ve mapped all your columns, select Export from the developer tab to export all of the spreadsheet data as XML.
Your XML file should look something like this: controlaccess_cleaner_dataset.xml

5. Use XSLT to batch process your source EAD files and find and replace the original terms with the cleaned terms.
For my project, I bundled the term cleanup as part of a larger XSLT “scrubber” script that fixed several other known issues with our EAD data all at once. I typically use the Oxygen XML Editor to batch process XML with XSLT, but there are free tools available for this.
Below is a link to the entire XSLT scrubber file, with the templates controlling the <controlaccess> term cleanup on lines 412 to 493. In order to access the XML file you saved in step 4 that contains the mappings between old values and cleaned values, you’ll need to call that XML from within your XSLT script (see lines 17-19).
What this script does, essentially, is process all of your source EAD files at once, finding and replacing all of the old name and subject terms with the ones you normalized and deduped in OpenRefine. To be more specific, for each term in EAD, the XSLT script will find the matching term in the <original_term>field of the XML file you produced in step 4 above. If it finds a match, it will then replace that original term with the value of the <cleaned_term>. Below is a sample XSLT template that controls the find and replace of <persname> terms.

Final Thoughts
Admittedly, cobbling together all these steps was quite an undertaking, but once you have the architecture in place, this workflow can be incredibly useful for normalizing, reconciling, and deduping metadata values in any flavor of XML with just a few tweaks to the files provided. Give it a try and let me know how it goes, or better yet, tell me a better way…please.
More resources for working with OpenRefine:
Great write up. You may have looked at this and already dismissed it, but you might be able to use the OpenRefine ‘templating’ export option to export directly from OpenRefine to the XML you want.
As an example see the OpenRefine template to export to MODS XML by Sara Allain at http://www.utsc.utoronto.ca/digitalscholarship/content/blogs/converting-spreadsheets-modsxml-using-open-refine#tldr
Owen, thanks for the feedback and the suggestion. Sara’s MODS template looks incredibly useful. I knew there was probably a way to avoid Excel altogether, I just hadn’t bothered to explore. I’ll definitely check out the templating export option next time I need to export XML from OpenRefine.