Folks, developing digital repositories is hard. There are so many different layers of complexity built into the stack, compounded by the unique variety of end-users, or stakeholders, that we serve.
Consider the breadth of this work:
Starting at the bottom of the stack, you have our Preservation layer. This is where we capture your bits, and ensure the long-term preservation of your digital assets. But it goes well beyond just logging a single record in a database. It involves capturing the data stream, writing that file and all associated files (metadata) to storage, replicating the data to various geographically dispersed servers, validating the ingest, logging the validation, ensuring successful recovery of replicated assets, and more.
All of that comes post-ingest. I’ll not even belabor the complexities of data modeling and ingest here, but you get the idea… it’s hairy stuff. Receiving and massaging a highly diverse body of data into a package appropriate for homogeneous ingest is a monumental effort in normalization.
Move up the stack into our Curation layer. Currently we have a single administrative application that facilitates management and curatorial activities of our digital objects following ingest. Roles or access controls can be managed here, in addition to various types of metadata (description about the item), etc. There are a variety of other applications that are managed at this layer, which interact with, and store, various values that fuel display and functionality within the user interface. This layer is quickly evolving in a way that necessitates diversification. We have found that a single monolithic application is not a one-size-fits-all solution for our stakeholders who are in the business of data production/curation; it is at this layer where we are getting increasingly more pressure to integrate and inter-operate with a myriad of other tools and platforms for resource/data management. This is tricky business as each of these tools handle data in different ways.
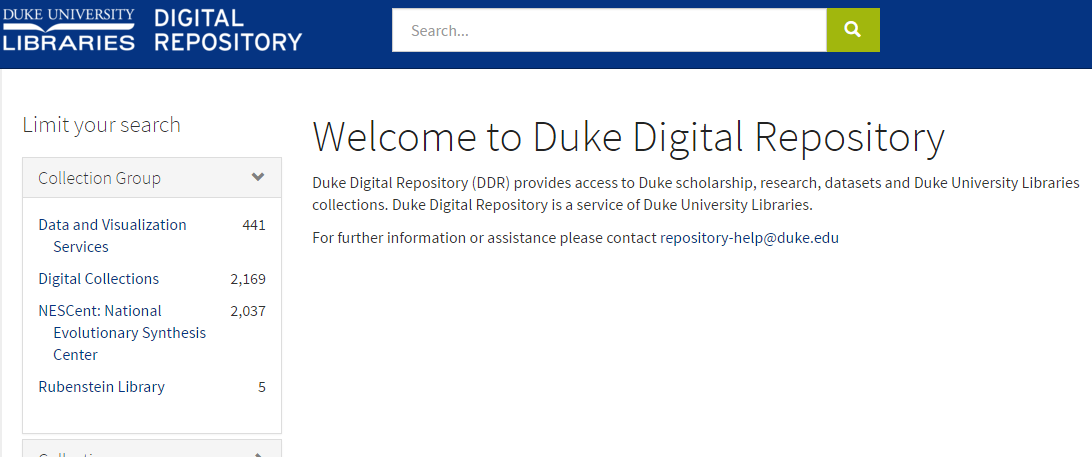
Finally, we have the Discovery layer. The user interface. This is what the public sees and consumes. It’s where access to ingested materials occurs. It is itself an application requiring significant custom development to meet the needs of various programs and collections of materials. It is tightly coupled with the Curation layer, and therefore highly complex and customized to meet the needs of different focal areas. Search functionality is yet another piece of complexity that requires maintenance and customization of a central index. Nothing is OOTB (out of the box). Everything requires configuration and customization.
And ALL of this- all of it- is inter-related. Highly coupled and complex. Few things reap easy wins, and often our work challenges foundational assumptions that have come well before. It’s an exercise in balancing technical debt and moving forward without re-inventing the wheel every six months.
What I have presented here is a simplistic view of our software eco-system. It’s just a snapshot of the various puzzle pieces that support the operation of a production repository. In general, digital repositories are still fairly new on the scene. No one has them figured out entirely and everyone does them a little bit differently. There’s a strength to that which manifests in diverse platforms and a breadth of development possibilities. There’s a weakness to it because there is no cookie-cutter approach that defines an easy path forward.
So it’s an exercise in evolution. In iteration. In patience. In requirements definition. We’re not going to always get it right, and our efforts will largely take a bit of time and experimentation, but we’re constantly working to improve, to enhance, and to mature our repository platform to meet the growing and evolving needs of our University.
So, here’s to many years of hard work ahead! And many successful collaborations with our Duke community to realize our repository’s future. We’re ready if you are!