
![]() My work involves a lot of problem-solving and problem solving often requires learning new skills. It’s one of the things I like most about my job. Over the past year, I’ve spent most of my time helping Duke’s Rubenstein Library implement ArchivesSpace, an open source web application for managing information about archival collections.
My work involves a lot of problem-solving and problem solving often requires learning new skills. It’s one of the things I like most about my job. Over the past year, I’ve spent most of my time helping Duke’s Rubenstein Library implement ArchivesSpace, an open source web application for managing information about archival collections.
As an archivist and metadata librarian by training (translation: not a programmer), I’ve been working mostly on data mapping and migration tasks, but part of my deep-dive into ArchivesSpace has been learning about the ArchivesSpace API, or, really, learning about APIs in general–how they work, and how to take advantage of them. In particular, I’ve been trying to find ways we can use the ArchivesSpace API to work smarter and not harder as the saying goes.
Why use the ArchivesSpace API?
Quite simply, the ArchivesSpace API lets you do things you can’t do in the staff interface of the application, especially batch operations.
So what is the ArchivesSpace API? In very simple terms, it is a way to interact with the ArchivesSpace backend without using the application interface. To learn more, you should check out this excellent post from the University of Michigan’s Bentley Historical Library: The ArchivesSpace API.

Working with the ArchivesSpace API: Other stuff you might need to know
As with any new technology, it’s hard to learn about APIs in isolation. Figuring out how to work with the ArchivesSpace API has introduced me to a suite of other technologies–the Python programming language, data structure standards like JSON, something called cURL, and even GitHub. These are all technologies I’ve wanted to learn at some point in time, but I’ve always found it difficult to block out time to explore them without having a concrete problem to solve.
Fortunately (I guess?), ArchivesSpace gave me some concrete problems–lots of them. These problems usually surface when a colleague asks me to perform some kind of batch operation in ArchivesSpace (e.g. export a batch of EAD, update a bunch of URLs, or add a note to a batch of records).
Below are examples of some of the requests I’ve received and some links to scripts and other tools (on Github) that I developed for solving these problems using the ArchivesSpace API.
ArchivesSpace API examples:
“Can you re-publish these 12 finding aids again because I fixed some typos?”
Problem:
I get this request all the time. To publish finding aids at Duke, we export EAD from ArchivesSpace and post it to a webserver where various stylesheets and scripts help render the XML in our public finding aid interface. Exporting EAD from the ArchivesSpace staff interface is fairly labor intensive. It involves logging into the application, finding the collection record (resource record in ASpace-speak) you want to export, opening the record, making sure the resource record and all of its components are marked “published,” clicking the export button, and then specifying the export options, filename, and file path where you want to save the XML.
In addition to this long list of steps, the ArchivesSpace EAD export service is really slow, with large finding aids often taking 5-10 minutes to export completely. If you need to post several EADs at once, this entire process could take hours–exporting the record, waiting for the export to finish, and then following the steps again. A few weeks after we went into production with ArchivesSpace I found that I was spending WAY TOO MUCH TIME exporting and re-exporting EAD from ArchivesSpace. There had to be a better way…
Solution:
asEADpublish_and_export_eadid_input.py – A Python script that batch exports EAD from the ArchivesSpace API based on EADID input. Run from the command line, the script prompts for a list of EADID values separated with commas and checks to see if a resource record’s finding aid status is set to ‘published’. If so, it exports the EAD to a specified location using the EADID as the filename. If it’s not set to ‘published,’ the script updates the finding aid status to ‘published’ and then publishes the resource record and all its components. Then, it exports the modified EAD. See comments in the script for more details.
Below is a screenshot of the script in action. It even prints out some useful information to the terminal (filename | collection number | ASpace record URI | last person to modify | last modified date | export confirmation)

[Note that there are some other nice solutions for batch exporting EAD from ArchivesSpace, namely the ArchivesSpace-Export-Service plugin.]
“Can you update the URLs for all the digital objects in this collection?”
Problem:
We’re migrating most of our digitized content to the new Duke Digital Repository (DDR) and in the process our digital objects are getting new (and hopefully more persistent) URIs. To avoid broken links in our finding aids to digital objects stored in the DDR, we need to update several thousand digital object URLs in ArchivesSpace that point to old locations. Changing the URLs one at a time in the ArchivesSpace staff interface would take, you guessed it, WAY TOO MUCH TIME. While there are probably other ways to change the URLs in batch (SQL updates?), I decided the safest way was to, of course, use the ArchivesSpace API.
Solution:
asUpdateDAOs.py – A Python script that will batch update Digital Object identifiers and file version URIs in ArchivesSpace based on an input CSV file that contains refIDs for the the linked Archival Object records. The input is a five column CSV file (without column headers) that includes: [old file version use statement], [old file version URI], [new file version URI], [ASpace ref_id], [ark identifier in DDR (e.g. ark:/87924/r34j0b091)].
[WARNING: The script above only works for ArchivesSpace version 1.5.0 and later because it uses the new “find_by_id” endpoint. The script is also highly customized for our environment, but could easily be modified to make other batch changes to digital object records based on CSV input. I’d recommend testing this in a development environment before using in production].
“Can you add a note to these 300 records?”
Problem:
We often need to add a note or some other bit of metadata to a set of resource records or component records in ArchivesSpace. As you’ve probably learned, making these kinds of batch updates isn’t really possible through the ArchivesSpace staff interface, but you can do it using the ArchivesSpace API!
Solution:
duke_archival_object_metadata_adder.py – A Python script that reads a CSV input file and batch adds ‘repository processing notes’ to archival object records in ArchivesSpace. The input is a simple two-column CSV file (without column headers) where the first column contains the archival object’s ref_ID and the second column contains the text of the note you want to add. You could easily modify this script to batch add metadata to other fields.
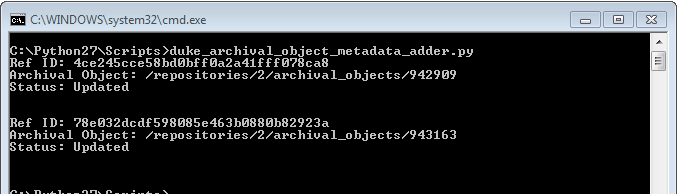
[WARNING: Script only works in ArchivesSpace version 1.5.0 and higher].
Conclusion
The ArchivesSpace API is a really powerful tool for getting stuff done in ArchivesSpace. Having an open API is one of the real benefits of an open-source tool like ArchivesSpace. The API enables the community of ArchivesSpace users to develop their own solutions to local problems without having to rely on a central developer or development team.
There is already a healthy ecosystem of ArchivesSpace users who have shared their API tips and tricks with the community. I’d like to thank all of them for sharing their expertise, and more importantly, their example scripts and documentation.
Here are more resources for exploring the ArchivesSpace API: