
Post contributed by Matthew Farrell, Digital Records Archivist.
I can claim without controversy that the web is among the more popular avenues for communicating, publishing, and otherwise interacting with information. Although professionals involved in the creation of websites often have titles (engineer, web designer, information architect) that borrow the language of corollaries in the physical world, information on the web and how one experiences it is inherently ephemeral. Relics of the early web still extant online often owe their continued life to chance, such as the website for the 1996 film Space Jam or the long-thought-lost-until-a-copy-was-discovered-on-a-floppy-disk first website.
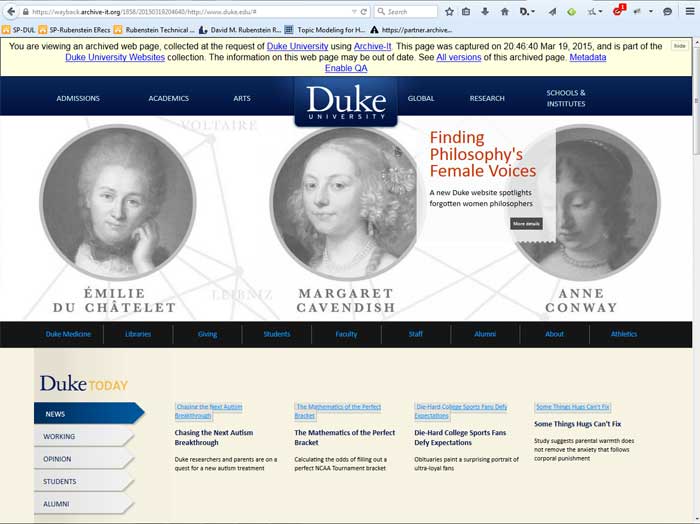
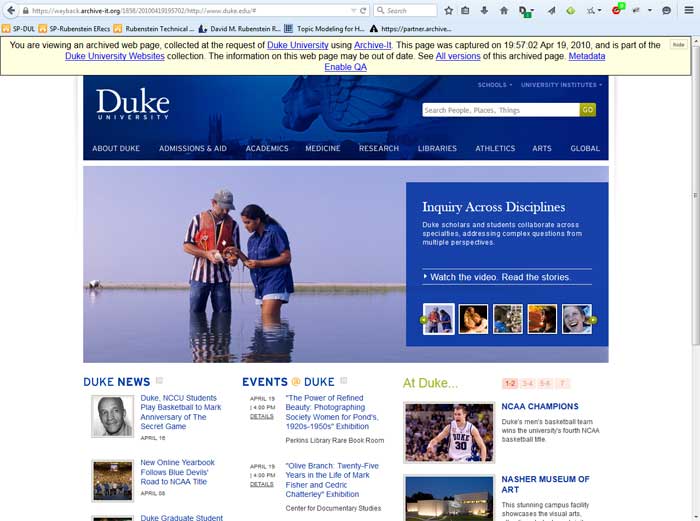
In order to preserve Duke’s web presence, in 2010 the University Archives partnered with Archive-It, a service of the Internet Archive, to take snapshots of various websites. In the five years since we have captured close to 500 Duke-related websites. Comparing a site’s evolution over time can be striking. This portal allows one to compare Duke homepages at different times. For example:

The following screencaps are for the Duke Chapel’s website.
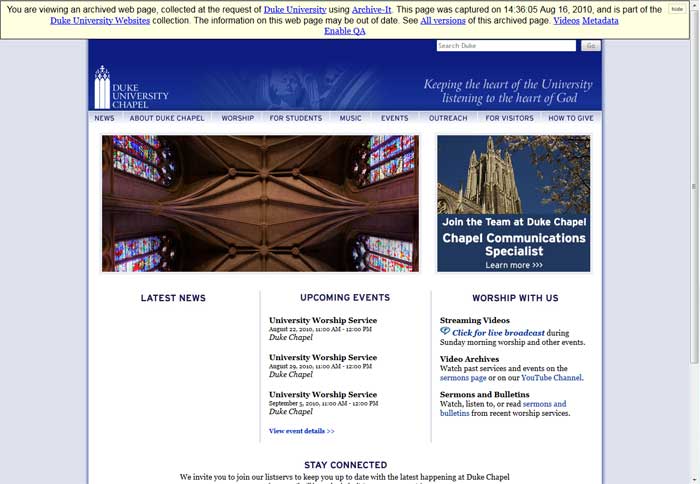
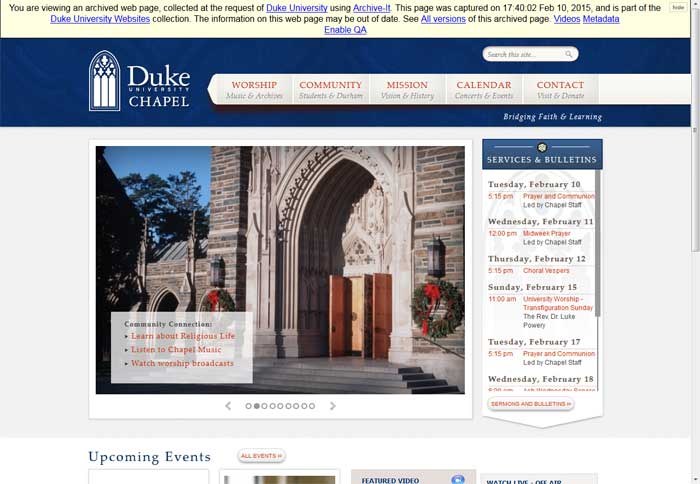
While the above examples are changes that are, at least in part, cosmetic changes to information, capturing web content allows us to preserve and provide access to the social and intellectual conversations on campus. We have had success capturing Develle Dish in both DukeGroups and their more recent Sites.Duke iteration.
Because the Duke Fact Checker was not officially associated with the university, his blog went down after his passing in early 2014. Though its no longer available at its original URL, we were able to get annual captures of his commentary between 2012 and 2014.
All of this is great but was previously difficult to access without knowing how to use the system. As of February 2015, there are two easy ways to browse and search through the Duke Web Archives. First, the University Archives created a collection guide to the Duke-related websites. The 500 or so URLs are arranged loosely by organizational type and can be browsed here.
Because of the way the web is crawled, some sites may have been crawled that don’t appear in the collection guide. To help address this problem as well as provide another avenue into the collection, there is a search function provided by Archive-It and their Wayback Machine here. Using the Wayback search, one can search for any URL. If the site appears in our collection, even if only partially, the search will return it.
We are currently at work to address Social Media, so look for future posts around that subject.
Post contributed by Matthew Farrell, Digital Records Archivist.