

Tell us about your journey in Duke University Libraries.
I am so happy to have been able to work in Collection Services as a full time staff member for the past five months. I’ve worked at Duke since 2021 and served as an intern in Rubenstein Library in Technical Services. I got my start working over in Smith Warehouse, particularly in Consumer Reports. Starting as an intern in Rubenstein Smith, I got to get a lot of experience working in Special Collections. I felt grateful to be able to establish connections and work with my then supervisor, Richard Collier Jr., who I learned a ton from. I was still in school then, still navigating what I believed my library career would look like but was happy to be able to get an internship, establish a working career in Duke University Libraries. After the internship ended, I was then hired to work in the Library Service Center at Duke. I worked there for about two years. That job was essential and played an important part in my library career because I really got to network and expand within the library. I took on many roles at the LSC for the learning experience which broadened my interests within the library. Starting at the LSC, I felt a bit lost because I was nervous about sticking to my original library career plan. Leaving the LSC, I felt a lot more confident and began to reject the idea of putting so much pressure on myself. I got to learn a great deal about academic librarianship and networking through the LSC and I believe that helped prepare me for the next chapter, the next job.
How did your time in MADS help acclimate you into Collection Services?
When we agreed to begin the partnership between MADS (Metadata and Discovery Strategy) and the Library Service Center, I was excited. I was happy to go work over in Smith and excited to work more in the background of academic librarianship. In MADS, I got to work with a really knowledgeable group so I was learning new stuff all the time. Having mostly worked in the LSC and on the circulation side of DUL, I got to work and learn more about a different sector of the library. It really opened me up to another part of the library that I had been pretty unfamiliar with. It was important for me to learn about metadata and cataloging because it increased my interest in this division. It was a really great experience for me and working with Jacquie Samples and the rest of the MADS crew was an awesome learning experience. I was always excited to learn more because I wanted to become more well rounded as a librarian. I’m grateful for my experience with MADS. Through this partnership, I also got to meet a lot of people in this division so, when I started working full time here, I was already really comfortable being in Smith Warehouse.
The coolest experience about working in MADS was being able to play an active role in something really important, the Alma migration! I was able to work with different librarians and learn more about a new software that is beneficial today because I work in it everyday in my current position!
What is your current position and what do you do?
In November, I got hired back at Smith as a full time employee, working in the Electronic Resources and Serials Acquisitions (ERSA) department. In this position, I mostly work in Alma and do some work in OCLC. My job is to mostly focus on binding periodicals in serials cataloging. These periodicals come from various collections here in DUL (Lilly, Perkins, EAC, Divinity) and include binding materials, writing accurate descriptions and cleaning up these records before the items are sent to the LSC. I get to work with a really great team, including my manager, Bethany Blankemeyer, who along with the rest of the team, has been extremely helpful. Everyone is so knowledgeable and I got to learn a lot about the life cycle of a serial and other items in acquisitions.
I also work on invoice processing in Alma and recently, started learning and working more in copy-cataloging in monographic sets and series. I have other interests as well, such as learning more about the electronic side of acquisitions given that I work with print materials. A cool part of this job is getting to learn more about other parts of this department. Everyone really encourages this and supports learning and professional development so I feel really grateful to be a part of this team and coming back to Smith Warehouse felt right. I feel really comfortable here because I got to get to know lots of people during my time in DUL, being at Smith.
What’s next? What do you hope to achieve?
I’ve realized that it’s not always necessary to put so much pressure on building your career and sticking to an original plan. Life is full of shifts and changes. I wasn’t entirely sure where I was going to end up but working in this division has been such a great experience. I’m happy to go to work everyday and not only be surrounded by a good team but also by so many opportunities to grow within Duke, to continue networking and really continue learning about academic librarianship. I hope to keep working here, in this division, and hope to continue to accept any learning opportunity. I also hope to continue to work with such good people, both in my department and division.
I’ve gotten to take on some challenges in DUL and it’s helped shape me as a librarian so I also hope to continue that!





 Some of the most fun and challenging materials I work with are the accompanying materials included with A-V box sets; the packaging can be spectacular, but publishers definitely do not have libraries in mind when they include that stuff! The accompanying booklets are easy enough to deal with, but what do you do with the ice pick-shaped ball point pen that accompanied
Some of the most fun and challenging materials I work with are the accompanying materials included with A-V box sets; the packaging can be spectacular, but publishers definitely do not have libraries in mind when they include that stuff! The accompanying booklets are easy enough to deal with, but what do you do with the ice pick-shaped ball point pen that accompanied 



 Assessment of diversity in library collections has a history dating to around the mid 1990’s when diversity was thought of as multiculturalism and coalesced around race, ethnicity, and gender. Definitions of diversity in the library collection continued to expand to include other markers like sexuality, socioeconomic status, and ability status. (Ciszek & Young, 2010) Diversity in the library collection is a complicated moving target to quantify across the broad range of library types, subjects, and formats.
Assessment of diversity in library collections has a history dating to around the mid 1990’s when diversity was thought of as multiculturalism and coalesced around race, ethnicity, and gender. Definitions of diversity in the library collection continued to expand to include other markers like sexuality, socioeconomic status, and ability status. (Ciszek & Young, 2010) Diversity in the library collection is a complicated moving target to quantify across the broad range of library types, subjects, and formats. We want to measure what matters, and this project explores ways to measure diversity in the library catalog given the above limitations and other complications like time, budget, publishing context, and metadata. A large-scale diversity audit of the whole collection is challenging because each subject area will have different metrics, context, and metadata. This project seeks to conduct smaller, deeper audits of tightly scoped parts of the collection.
We want to measure what matters, and this project explores ways to measure diversity in the library catalog given the above limitations and other complications like time, budget, publishing context, and metadata. A large-scale diversity audit of the whole collection is challenging because each subject area will have different metrics, context, and metadata. This project seeks to conduct smaller, deeper audits of tightly scoped parts of the collection.

 Nancy Drew Newcomers/New Skills Award
Nancy Drew Newcomers/New Skills Award  Dr. Watson Collaboration & Outreach Award
Dr. Watson Collaboration & Outreach Award  Miss Marple Creativity & Innovation Award
Miss Marple Creativity & Innovation Award  Benoit Blanc Leadership & Coaching Award
Benoit Blanc Leadership & Coaching Award  Jessica Fletcher Slow Librarianship Award
Jessica Fletcher Slow Librarianship Award







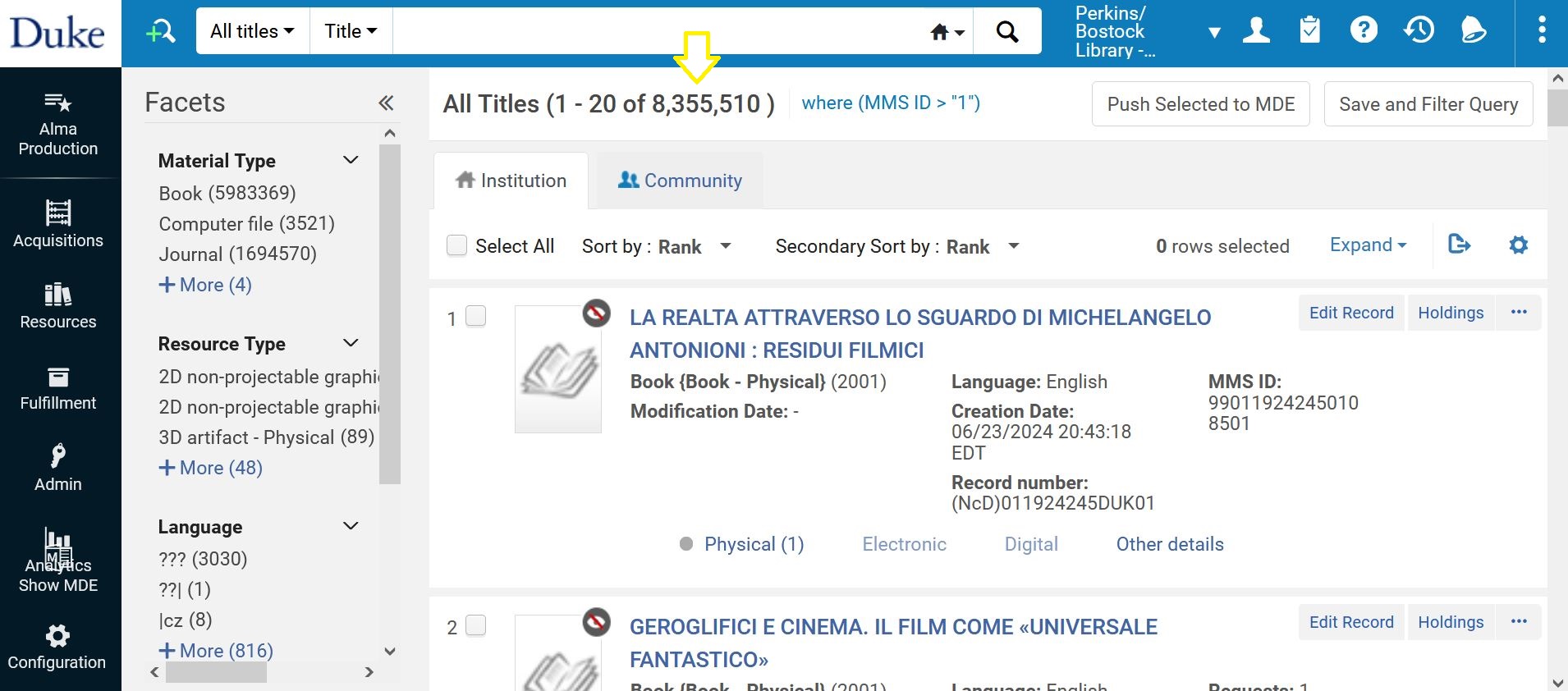
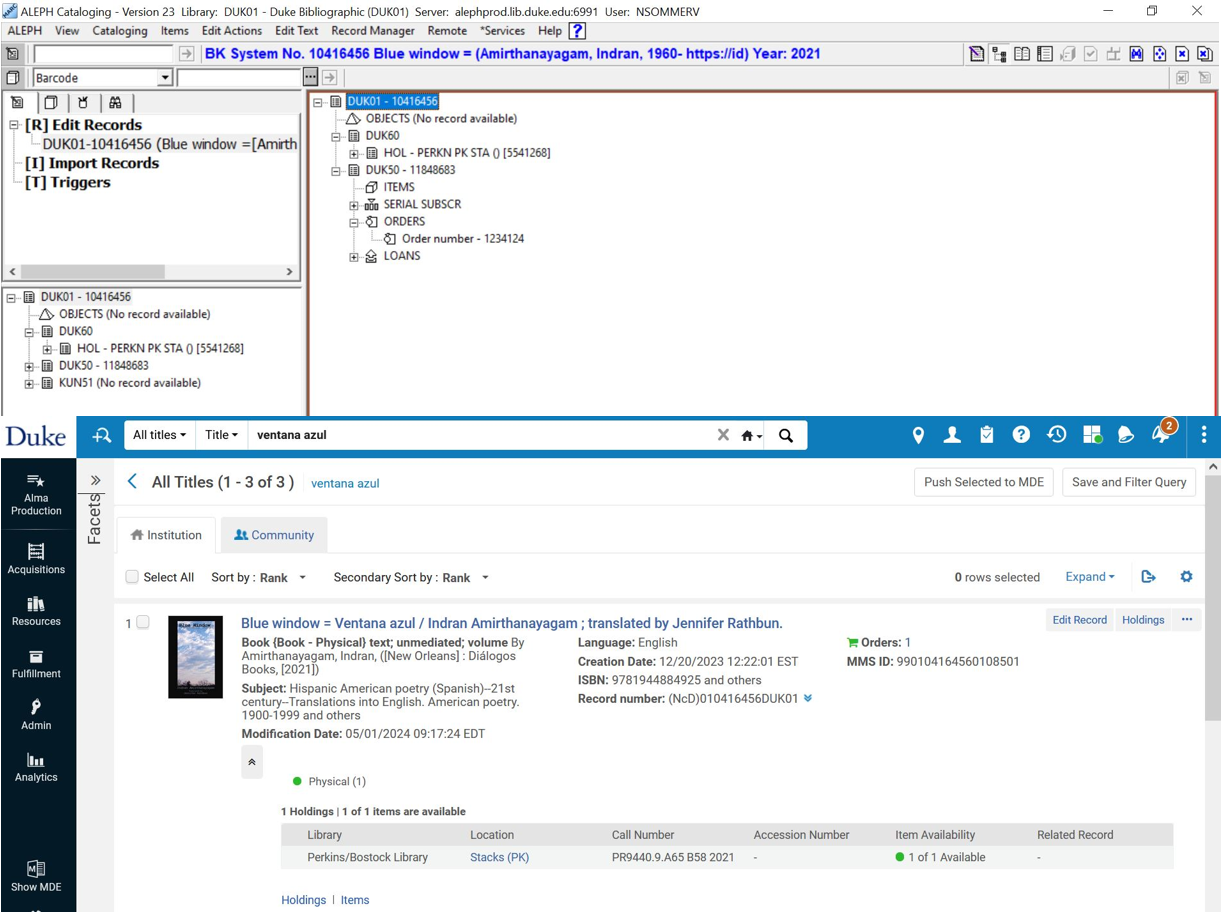 For twenty years, the libraries at Duke University have used Ex Libris’s Aleph integrated library system to manage library resources in a variety of formats and languages across the acquisitions, description, inventory, and delivery lifecycles. This requires the system to store, interpret, correlate, ingest, and output a variety of data types. Aleph has helped the libraries at Duke successfully steward existing resources and acquire upwards of 1 million new resources since 2004, including a proliferation of eBooks, eJournals, databases and streaming media. On July 10th, we will be sunsetting Aleph and implementing Ex Libris’s Alma system. Alma builds on the functionality and data models of an integrated library system and incorporates these into a library services platform that streamlines and aligns processes for selecting, acquiring, describing and delivering print and electronic resources. Much planning, careful data mapping and cleanup, and lots of collaboration among subject matter experts from across the libraries at Duke has brought us to the cusp of going live with Alma. Stay tuned for a follow-up post in the later part of July in which members of the Duke University Libraries Collections Services division will reflect on the work that led up to go-live and talk about the early days of working in Alma.
For twenty years, the libraries at Duke University have used Ex Libris’s Aleph integrated library system to manage library resources in a variety of formats and languages across the acquisitions, description, inventory, and delivery lifecycles. This requires the system to store, interpret, correlate, ingest, and output a variety of data types. Aleph has helped the libraries at Duke successfully steward existing resources and acquire upwards of 1 million new resources since 2004, including a proliferation of eBooks, eJournals, databases and streaming media. On July 10th, we will be sunsetting Aleph and implementing Ex Libris’s Alma system. Alma builds on the functionality and data models of an integrated library system and incorporates these into a library services platform that streamlines and aligns processes for selecting, acquiring, describing and delivering print and electronic resources. Much planning, careful data mapping and cleanup, and lots of collaboration among subject matter experts from across the libraries at Duke has brought us to the cusp of going live with Alma. Stay tuned for a follow-up post in the later part of July in which members of the Duke University Libraries Collections Services division will reflect on the work that led up to go-live and talk about the early days of working in Alma. 1. How long has DUL been sending materials out to the Commercial Bindery (CB)? Since everyone who knew the history of binding at Duke University Libraries (DUL) has retired, we had to do a little research to find this answer. (Thanks to
1. How long has DUL been sending materials out to the Commercial Bindery (CB)? Since everyone who knew the history of binding at Duke University Libraries (DUL) has retired, we had to do a little research to find this answer. (Thanks to 
