I attended Open Repositories 2009 Conference this past week. Overall it was a very informative conference on the open source repository platforms (Fedora, dSpace, ePrints, Zentity), current projects and developments using these platforms, and future directions of repositories. Below are some relevant notes from the conference.
Repository Workflow
There were a few presentations that discussed how institutions were managing their repositories, in particular, repositories built with Fedora. Two of these, eSciDoc and Hydra, had some very useful nuggets.
Hydra is a grant-funded collaboration between Hull University, University of Virginia and Stanford University to build a repository management toolkit to manage their three very different workflows, and be extensible to manage heterogeneous workflows around the Fedora community. There are a few practices or ideas that we might want to adopt from this project, as well as some possible points of convergence with Trident.
- The idea to treat workflow processes discretely. Hull is using BPEL (Business Process Execution Language) to define and implement the processes. They are using Active Endpoints (was open source, may not be any longer) which provides a really nice GUI for defining and connecting workflow processes. Not sure if this tool is worth investigating it, but I have seen it before, and have heard good things.
- Stanford has a good design for representing the state of multiple workflows for an item. Items have workflow datastreams, which include a number of processes, each with an indicator of state. They then represent these workflow processes as a checklist in management interface.
- UVA, like us, is thinking RESTfully. RESTful approach to workflow steps allows processes to be encapsulated nicely and reused in a variety of ways.
- Repository API – This is a possible point of eventual convergence, Hydra will be creating a RESTful API layer on top of Fedora, similar in architecture to the one that we have developed for Trident.
eSciDoc is an eResearch environment built on top of Fedora.
- They have a well established object life cycle. An item’s stage in it’s life cycle determines who is allowed to do what to the item. For instance, pending (only the creator can access and modify, collaborators may be invited, item may be deleted), submitted (QC/editorial process, creator cannot modify any longer, metadata may still be enriched),…
- They have a very tight versioning design in their Fedora repository. They use an atomistic approach to Fedora, with items and components as separate Fedora objects. With this approach, they can represent multiple versions of an item in their repository. They do this by creating a copy of the item fedora object with each version, and a copy of only the changed component with each version. Their item fedora objects contain all of the pointers to the components. A handle gets assigned to the published version.
Cloud Storage
Sandy Payette and Michele Kimpton gave an update on the emerging DuraCloud services. They are currently in development, and will be tested with a few beta sites before general release. The DuraCloud services will definitely be worth Duke looking into; however, will probably need to wait for more Akubra development before these services can be properly integrated into Fedora. For Duke’s repository, cloud storage should be evaluated for storage of preservation masters. Also on the topic of cloud storage, David Tarrant gave an update from ePrints, as well as a reminder, “Clouds do blow away.”
Smart storage underpinning repositories
- ePrints has exactly what is needed. Their storage controller allows for rule based storage configuration. This is now in their current release.
- Fedora is still developing Akubra. Some of the beginnings of this code are in version 3.2, but it is not implemented. From what I gather, if we have a use case, we need to implement it ourselves.
- dSpace will be looking at incorporating Akubra into version 2 of dSpace
- Reagan Moore (UNC) and Bing Zhu (UCSD) gave a very detailed discussion on iRods. iRods has a very detailed architecture for rule-based storage. It defines many micro-services to be performed on objects. These micro services can be chained together. iRods has a clean rule-based configuration for defining chains of micoservices and the conditions under which these workflow chains should be executed on an object. iRods allows for a good separation between remote storage layer and “metadata repository.” Bing discussed how iRods is integrated with Fedora. From what I understood, Fedora does not directly manage iRods, rather datastreams are created in Fedora as external references to iRods, and iRods must be managed separately.
JPEG2000
djatoka continues to impress me. It takes the math out of jpeg2000. Ryan Chute discussed how this can be integrated into Fedora, and the service definitions involved in doing so. He also showed some of the image viewers that have been built using djatoka. With djatoka, the primary use of jpeg2000 is as a presentation format. The integration with Fedora relies on a separate jpeg2000 “caching” server for serving up jpeg2000 services, which would live outside of Fedora. In this model, it may be that Fedora never even needs to hold a jpeg2000 file. I need a little more understanding on how the caching server gets populated, but will be investigating this in the coming months.
Islandora
UPEI has packaged an integration of Drupal and Fedora. There is a mixed bag between what Drupal content is stored in Fedora and what content gets stored in Drupal. As new types of content are stored in Drupal, new content models need to be created in Fedora to support them. Presenter indicated that work still needs to be done on updates on Fedora being reflected in Drupal and vice-versa. Without more than a presentation to base my opinions on, this seems like an extensible model, but one that also requires continued hand-tuning and management.
Complex object packaging
METS and OAI-ORE, or should it be METS vs OAI-ORE. There is a lot more discussion and work in the last year around OAI-ORE. It is a lot more flexible packaging model for complex objects than is METS. And it has been the medium by which SWORD and other similar models are based on. With flexibility though comes programmatic complexity. Our repository model is based on a METS-centric view of digital repositories. We did generalize item structure in such a way though that we could conceivably change the underlying structure from METS to something like ORE. More to come on this
Cool stuff
@mire showed off some authoring tools integrated into Microsoft Office as add-ins. I’m told these won’t be released for at least six months, but showed some real possibility and value that repositories to add to authors. The authoring tools decomposed powerpoint presentations and word documents and stored them in the repository, and then allowed for searching of the repository (from within powerpoint and word) to include slides, images, text, etc from the repository into the working document.
Peter Sefton showed off his Fascinator. It features click to create portals that could then be customized fairly easily. He also talked about work he is currently doing on a “desktop sucker upper” which extracts data from a laptop to store into a repository.
Programming notes
- eSciDoc is using the same terminology as us, in terms of items and components. This is good, although I have not heard our terminology really used in other contexts. Also dSpace seems to be moving away from this terminology.
- Enhanced content modeling – this development allows for more precise description of datastreams and more precise description of relationships. This is not incorporated into Fedora proper, although it should be because it adds a lot of value to the core.
- There are others taking a RESTful approach to repositories, at least in representing the R in CRUD
- Others confirmed my belief that web services (RESTful ones) should be programmer friendly as well as computer friendly. In other words, the responses should display in web pages and give a programmer at least a rudimentary but helpful view of the data
Fedora
FIZ Karlsruhe has done extensive performance testing and tuning of Fedora. They tested with data sets up to 40 million objects. In terms of scaling, performance was not effected by size of the repository. They were also able to increase performance by tuning the database, as well as separating the database from the repository. They found that I/O was the limiting factor in all cases.
Fedora 3.2 highlights – beginnings of Akubra, SWORD integration, will be switching to new development environment (maven, OSGi/Spring DM)
dSpace
SWORD support, Shibboleth supported out of the box, new content model in dSpace 2.0 (based on entities and relationships)



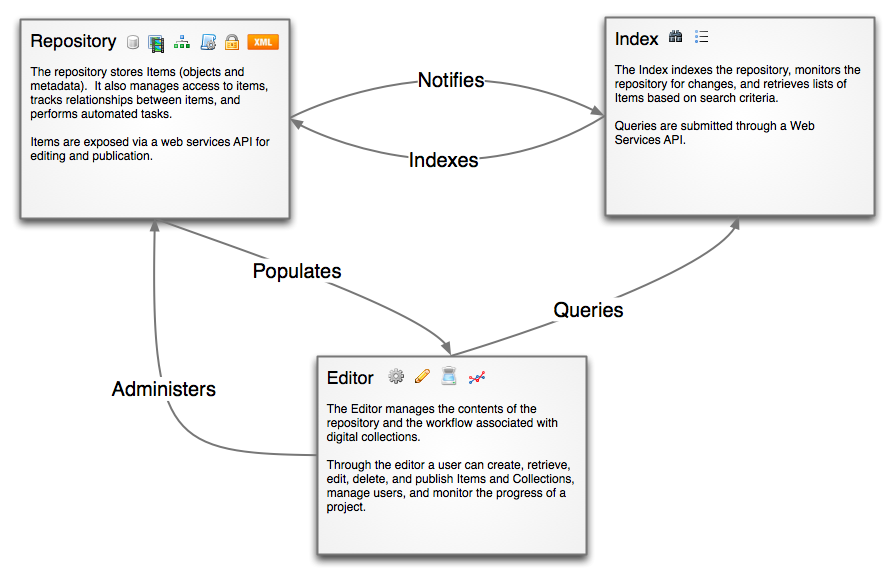
 front-end platform for digital collections Tripod, for its three-legged architecture. Use of the “Tri-” formulation evokes
front-end platform for digital collections Tripod, for its three-legged architecture. Use of the “Tri-” formulation evokes 