
 The library’s search for software to support metadata creation served as the topic of two posts of mine from late last year, A Metadata Tool that Scales, and Grand Metadata Tool Ideas. Those posts discussed our internal process and analysis, and engaged in some “guilt-free big thinking.” This post will report on our progress since we broke for the winter holidays. While much conjecture remains in what follows, we gave real progress to report, which I plan to do in three parts over the next week or so.
The library’s search for software to support metadata creation served as the topic of two posts of mine from late last year, A Metadata Tool that Scales, and Grand Metadata Tool Ideas. Those posts discussed our internal process and analysis, and engaged in some “guilt-free big thinking.” This post will report on our progress since we broke for the winter holidays. While much conjecture remains in what follows, we gave real progress to report, which I plan to do in three parts over the next week or so.
Last fall, we completed a successful job search for two programmers to support the project. We were thrilled to bring on two talented and experienced individuals. Lead Programmer Dave Kennedy comes to us from the University of Maryland, where managed the Office of Digital Collections and Research. User Experience Developer TJ Ward made the move from the on-demand self-publishing outfit Lulu. Dave, TJ and I serve as principal developers for the project, with an extended team that includes other members of IT staff in the library.
As the team formed, we took the critical step of fixing a name to the project — Trident, which we chose for a number of reasons that sounded good at the time. First, we call our home-cooked  front-end platform for digital collections Tripod, for its three-legged architecture. Use of the “Tri-” formulation evokes Duke’s history, and the trident imagery its school mascot. Additionally, I am known to use a water metaphor to talk about metadata, which goes as follows: “Metadata flows from librarians to patrons like water to the sea. It is inevitable and inexorable. You don’t want to stop it, and you couldn’t if you did. What you do is engineer the landscape so that it meanders instead of floods, and serves as a nourishing resource, not a destructive force.” The trident, of course, is the tool with which Poseidon controls the seas. Finally, Wikipedia informs us that Bill Brasky used a trident to kill Wolfman Jack. Thanks, Wikipedia!
front-end platform for digital collections Tripod, for its three-legged architecture. Use of the “Tri-” formulation evokes Duke’s history, and the trident imagery its school mascot. Additionally, I am known to use a water metaphor to talk about metadata, which goes as follows: “Metadata flows from librarians to patrons like water to the sea. It is inevitable and inexorable. You don’t want to stop it, and you couldn’t if you did. What you do is engineer the landscape so that it meanders instead of floods, and serves as a nourishing resource, not a destructive force.” The trident, of course, is the tool with which Poseidon controls the seas. Finally, Wikipedia informs us that Bill Brasky used a trident to kill Wolfman Jack. Thanks, Wikipedia!
While metadata creation is a major part of Project Trident, the team has a broader charge related to the creation and management of digital collections. Two of our high-level objectives, then, are 1) to support the creation of metadata for digital collections at Duke University Libraries and 2) to establish a digital repository for digitized materials. We see engagement with the library community at large as an important way of approaching these objectives, to promote both the long-term health of the project, and the library’s profile. With these objectives and this approach in mind, the team has engaged in an intensive phase of analysis and design since coming together.
The documentation produced by the team now resides on a Trac wiki; while it remains private for the time being, here I’ll share some of the key design documents, exported to PDF’s (where the formatting provided by the exporter is a little flaky):
- Trident Architecture Diagram
- Trident System Entities
- Trident API Methods (Overview)
- Trident API Methods (Detailed)
- Trident Users
- Trident User Stories
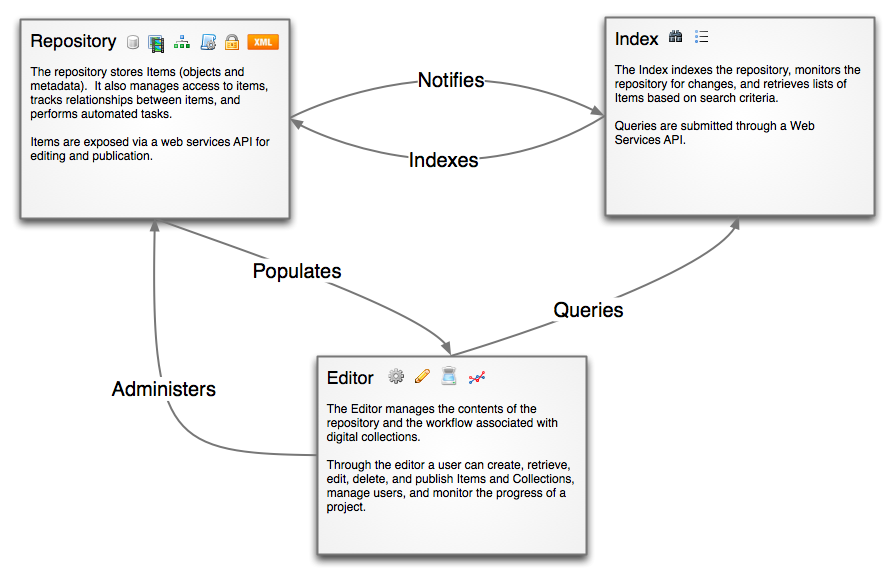
The first document is a high-level diagram of the architecture we are using. Continuing the rule of three, we formulated a triune architecture: Repository, Editor, Index. Speaking in general terms, the functions of the three modules are:
- Repository — Stores things like metadata and digitized objects. Also, maintains information about their relationships with one another.
- Editor — Changes metadata and sends it back to repository. Also, manages the organization and arrangement of digitized objects.
- Index — Produces lists of things in the repository based on arbitrary criteria.
Our specifications essentially treat the Editor as a client of the Repository, and the Repository not as an implementation, but as an API with RESTful bindings. The Index has one API method associated with it, Find, and a messaging service manages communication between the Repository and the Index.
We took this approach to promote the modularity of the Editor tool. Other organizations or institutions may choose to implement the RESTful API “on top of” their local repository implementation, and adopt the Trident Editor for their own needs. We intend to implement our Repository module using Fedora, but the Editor module should be reusable with a variety of repository platforms.
We have chosen to implement the Editor using the Django framework, in part because we already use and support it in the library, and we can take advantage of staff experience and expertise with Python. It’s also a common platform, so we believe that it will promote the reusability of the Editor.
For the Index, we will continue our use of SOLR, one of the legs in the Tripod architecture.
We also work under the assumption of Django implementations of the Repository and Index API’s, perhaps minimal but functional enough that they can bundle with the tool and enable it to stand alone. The implementation of the Repository and Index API’s in Django may be the pieces of the project for which we appeal to development partners.
Finally, we hope to be able to release our code and open up the project. We are still working out the details with the university’s administration, but we hope that more information will be forthcoming soon.
This post represents the first of three parts which I plan for the next week or so. Next: the Metadata Application Profile.
Nice work, Will. One question… is the indexing component of Trident meant to only address metadata management and administration needs (i.e., to help metadata creators find existing records and avoid duplication), or will also power front-end digital collection searching? To put it a different way, how do you expect your front-end digital collection apps will interface with Trident?
Thanks, Tito. Yes, the index should work with the front end for digital collections. I do expect the front end to use the repository API to access the contents of digital collections. In fact, I hope that implementation of the repository will open up the digital collections to a wider variety of publishing possibilities than we have now.