
The promise of standards is to make our lives easier: TEI, XML, Unicode – all have the potential to ease interchange and reuse, which is why we use them. Ideally, we don’t even have to think about them in order to get our work done. Vast numbers of people reap the benefits of standardized Unicode encoding without even knowing it. Gone (or should be) are the days of looking for a specific proprietary “font” to display an idiosyncratically encoded Greek text.
However, when designing software that works with these standards, you sometimes have to dive a little deeper into them. Most people are blissfully unaware of various features of Unicode, and the one I’m going to discuss here crops up problematically in software design surprisingly often: combining characters. Unicode, in order to represent text, is at the low level still a sequence of bytes – these byte sequences are Unicode code points, which map to defined characters. While Unicode has some code points that define characters-with-accents, every possible permutation isn’t necessarily represented, so some code points map to combining characters – that is, characters which will combine onto the most recent “full” character that precedes them.
Unicode itself doesn’t prescribe that arbitrary sequences of code points are “illegal”, so you can essentially create non-sensical combining character sequences that have historically caused all sorts of problems for software that deals with text, font renderers in particular. I once accidentally stumbled across a combining character sequence that would immediately crash the Mac OS X terminal if it attempted to render it (now fixed). The sometimes-aptly-named @crashtxt on Twitter provides a good example of these sorts of sequences.
Of course, when dealing with historical texts written by humans, such as those in papyri.info, completely arbitrary accent sequences are unlikely. What we do have instead is a vast amount of accented polytonic Ancient Greek, which we want to represent in a standard way – so that if you search for a string with accented characters, you get all instances of that string. If, for example, you search for something containing a character which can only be represented with multiple combining accent characters, you shouldn’t have to care about the order the accents are encoded in (which is usually visually impossible in any case – they all combine onto the same character, so two different sequences of code points can be rendered to what looks like the exact same character).
Fortunately, Unicode also defines what are called normalization forms – standardized ways of normalizing sequences of code points so that equivalent sequences are encoded identically. The two forms I’ll talk about here are called Normalization Form C (NFC) and Normalization Form D (NFD). The “C” and “D” stand for “composed” and “decomposed” respectively. “Decomposed” here means “split any code points into canonical combining sequences when possible” and “composed” means “combine any sequences into canonical code points when possible”.
The best way to illustrate this is with an image, here taken from the normalization standard:
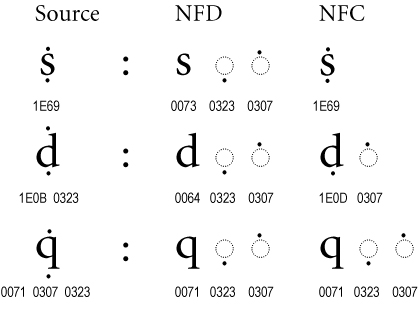
So here you can see the code point sequences for various characters under different normalization forms, where all of them would typically render to visually identical glyphs in most systems. But if you were searching for say the code point “1E69” and you didn’t find “0073 0323 0307”, that could be a bug – so it’s important for projects to decide what normalization form they’re going to use. For papyri.info we aim for NFC encoding across the corpus, and even use XSLT’s normalize-unicode function to automatically try to enforce this in the Papyrological Editor. Or so we thought…
In hunting down a bug in Leiden+ (the non-XML markup syntax we use in the editor to encode texts – which has a bidirectional mapping to TEI EpiDoc XML), I decided to finally enforce the rule that text coming into the Leiden+ processor should be converted to NFD (as some composing characters are used for syntax) while XML coming out of the processor should be NFC, so that we only store NFC-normalized XML in our canonical repository. While easy enough in theory, I wanted to check that round-trips of this conversion process wouldn’t cause parse errors or thrashing in our version history. In testing this across the entire corpus, I started to notice that certain characters were causing problems – while Leiden+ uses Java’s Unicode normalization library, the XSLT normalize-unicode process uses Saxon, and certain visually-identical characters were being flipped between the two. You can see one such character in three forms using this Unicode string analysis tool – one form is two code points, one three, and one four, but all are visually identical. Java’s idea of NFC for the decomposed form was two code points, while Saxon’s was three. Obviously, it’s not exactly normalization if two different implementations give different normalizations! This turned out to be a bug in Saxon, which was quickly resolved, but affected all characters with combining perispomeni accents which also had a combined form (some thousands of instances in our corpus).
The lesson here is that normalization can still be hard – but it’s worth doing. If you’re working with texts in Unicode and you haven’t thought about what normalization processes you want to apply, I hope this has illustrated both the potential need to apply normalization and the sorts of difficulties you might encounter along the way. After all, if you can’t see the problem in the rendered text, you might not even be aware that there’s a problem at all, which can be a dangerous sort of ignorance.