Making Maps with Tableau
 One of the attractive features of Tableau for visualization is that it can produce maps in addition to standard charts and graphs. While Tableau is far from being a full-fledged GIS application, it continues to expand its mapping capabilities, making it a useful option to show where something is located or to show how indicators are spatially distributed.
One of the attractive features of Tableau for visualization is that it can produce maps in addition to standard charts and graphs. While Tableau is far from being a full-fledged GIS application, it continues to expand its mapping capabilities, making it a useful option to show where something is located or to show how indicators are spatially distributed.
Here, we’re going to go over a few of the Tableau’s mapping capabilities. We’ve recorded a workshop with examples relating to this blog post’s discussion:
-
- Mapping in Tableau CDVS Workshop (examples relate to this blog post)
For a more general introduction to Tableau (including some mapping examples), you should check out one of these other past CDVS workshops:
Concepts to Keep in Mind
Tableau is a visualization tool: Tableau can quickly and effectively visualize your data, but it will not do specialized statistical or spatial analysis.
Tableau makes it easy to import data: A big advantage of Tableau is the simplicity of tasks such as changing variable definitions between numeric, string, and date, or filtering out unneeded columns. You can easily do this at the time you connect to the data (“connect” is Tableau’s term for importing data into the program).
Tableau is quite limited for displaying multiple data layers: Tableau wants to display one layer, so you need to use join techniques to connect multiple tables or layers together. You can join data tables based on common attribute values, but to overlay two geographic layers (stack them), you must spatially join one layer to one other layer based on their common location.
Tableau uses a concept that it calls a “dual-axis” map to allow two indicators to display on the same map or to overlay two spatial layers. If, however, you do need to overlay a lot of data on the same map, consider using proper GIS software.
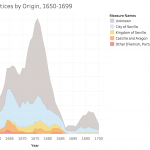
Displaying paths on a map requires a special data structure: In order for tabular data with coordinate values (latitude/longitude) to display as lines on a map, you need to include a field that indicates drawing order. Tableau constructs the lines like connect-the-dots, each row of data being a dot, and the drawing order indicating how the dots are connected.

You might use this, for instance, with hurricane tracking data, each row representing measurements and location collected sequentially at different times. The illustration above shows Paris metro lines with the station symbol diameter indicating passenger volume. See how to do this in Tableau’s tutorial.
You can take advantage of Tableau’s built-in geographies: Tableau has many built-in geographies (e.g., counties, states, countries), making it easy to plot tabular data that has an attribute with values for these geographic locations, even if you don’t have latitude/longitude coordinates or geographic files — Tableau will look up the places for you! (It won’t, however, look up addresses.)
Tableau also has several built-in base maps available for your background.
Tableau uses the “Web Mercator” projection: This is the same as Google Earth/Maps. Small-scale maps (i.e., large area of coverage) may look stretched out in an unattractive way since it greatly exaggerates the size of areas near the poles.
Useful Mapping Capabilities
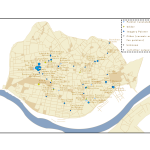
Plot points: Tableau works really well for plotting coordinate data (Longitude (X) and Latitude (Y) values) as points. The coordinates must have values in decimal degrees with negative longitudes being east of Greenwich and negative latitudes being south of the equator.
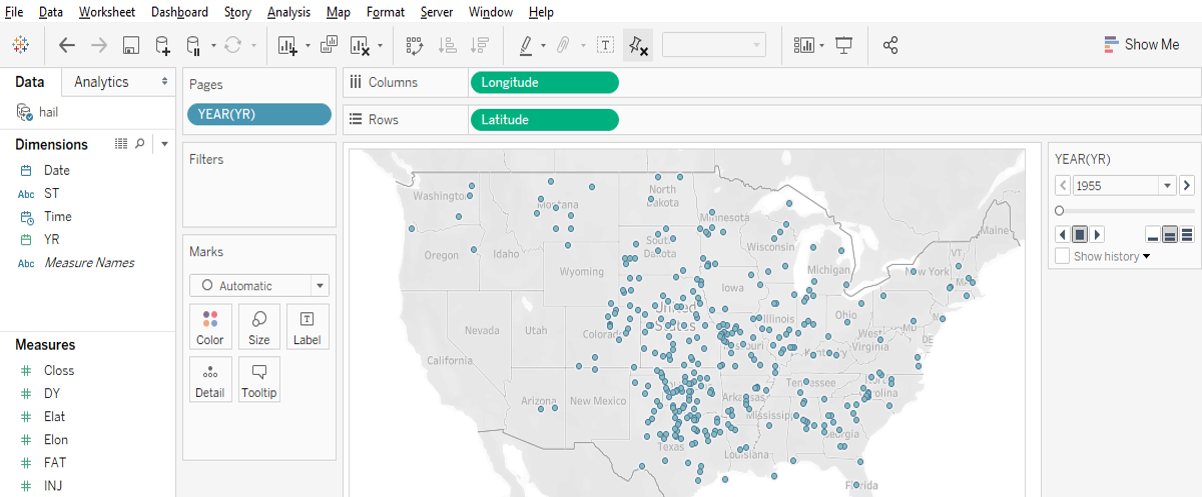
Time slider: If you move a categorical “Dimension” variable onto Tableau’s Pages Card, you can get a value-based slider to filter your data by that variable’s values (date, for instance, as in Google Earth). This is shown in the image above.
Heatmap of point distribution: You can choose Tableau’s “Density” option on its Marks card to create a heatmap, which may display the concentration of your data locations in a smoother manner.
Filter a map’s features: Tableau’s Filter card is akin to ArcGIS’s Definition Query, to allow you to look at just a subset of the features in a data table.
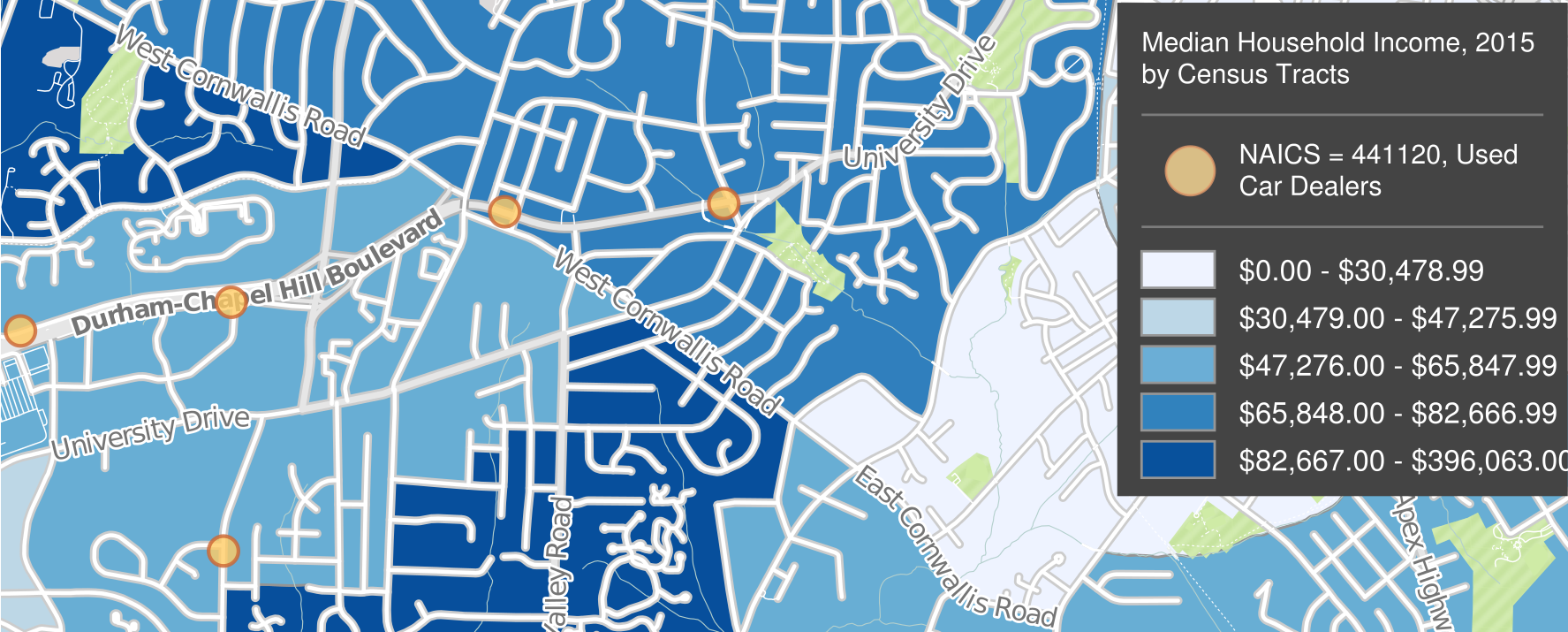
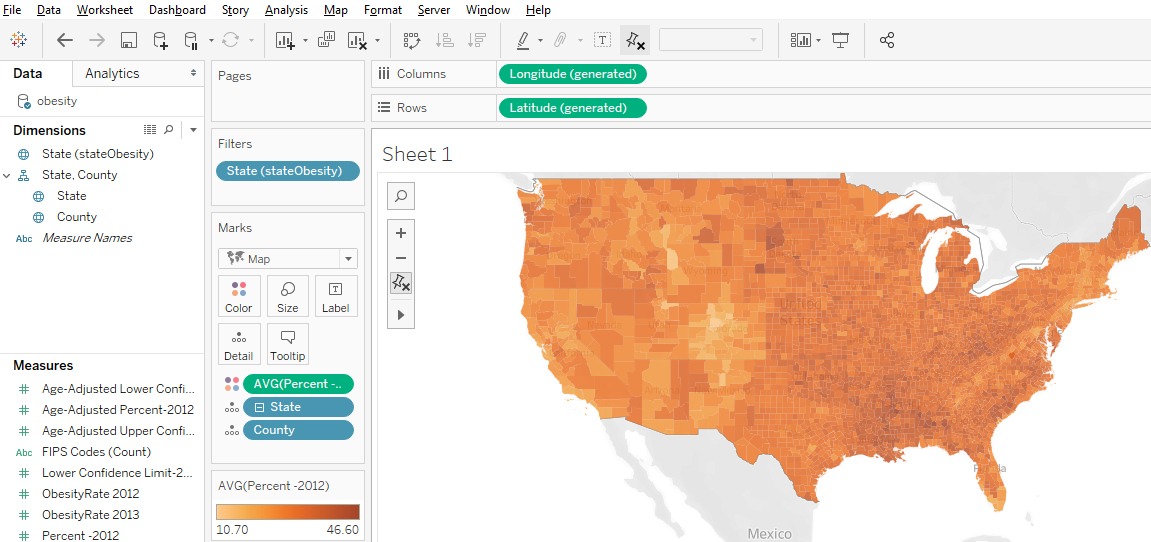
Shade polygons to reflect attribute values: Choropleth maps (polygons shaded to represent values of a variable) are easy to make in Tableau. Generally, you’ll have a field with values that match a built-in geography, like countries of the world or US counties. But you can also connect to spatial files (e.g., Esri shapefiles or GeoJSON files), which is especially helpful if the geography isn’t built into Tableau (US Census Tracts are an example).
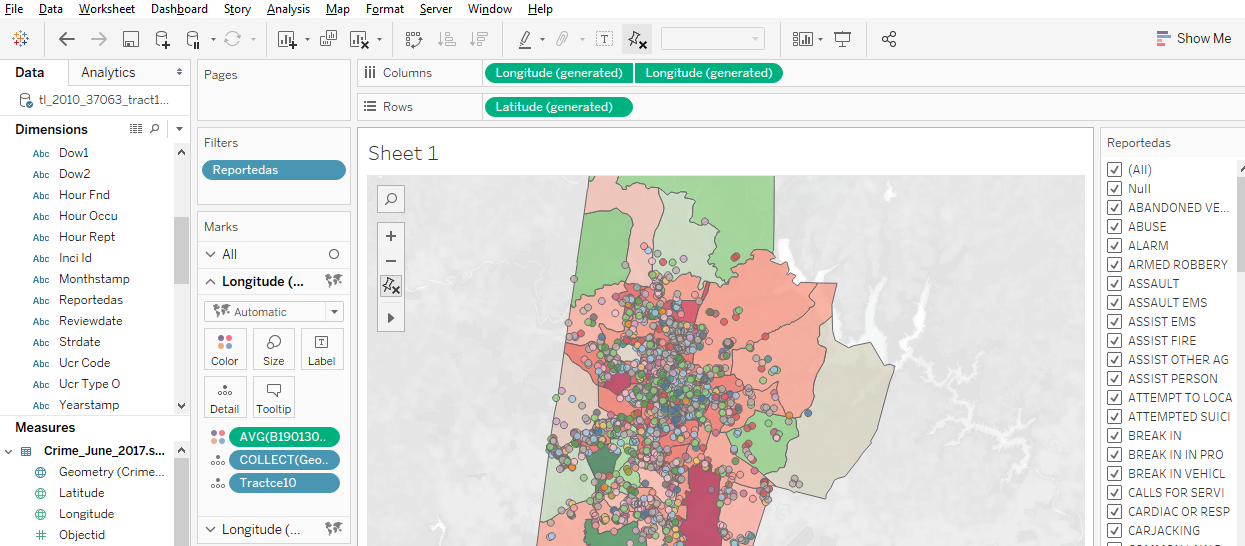
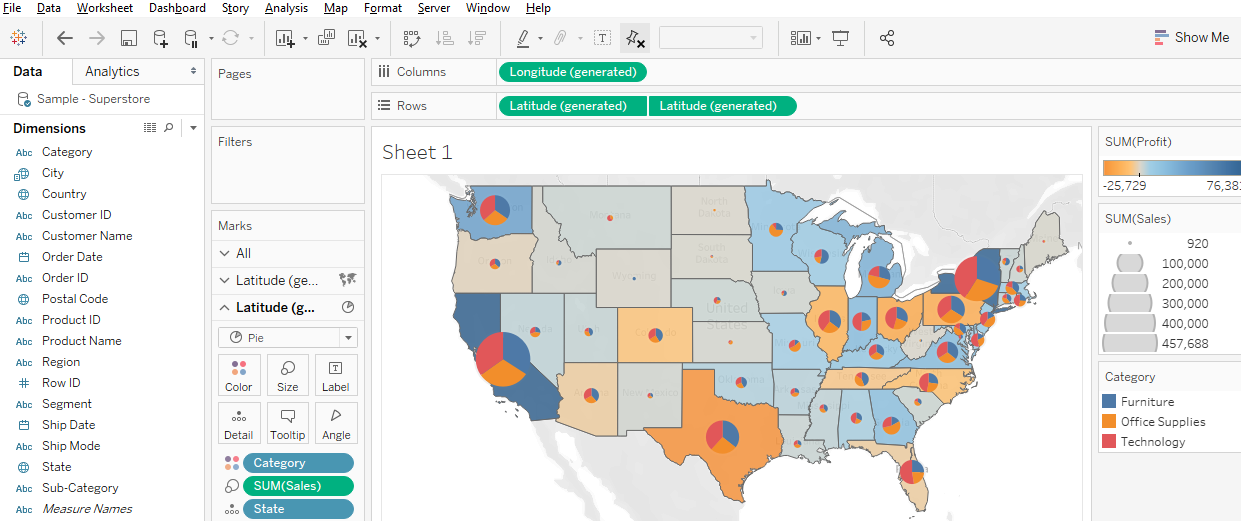
Display multiple indicators: Visualizing two variables on the same map is always problematic because the data patterns often get hidden in the confusion, but it is possible in Tableau. Use the “dual-axis” map concept mentioned above. An example might be pies for one categorical variable (with slices representing the categories) on top of choropleth polygons that visualize a continuous numeric variable.
Draw lines from tabular data: Tableau can display lines if your data is structured right, as discussed and illustrated previously, with a field for drawing order. You could also connect to a spatial line file, such as a shapefile or a GeoJSON file.
Help Resources
We’ve just given an overview of some of Tableau’s capabilities regarding spatial data. The developers are adding features in this area all the time, so stay tuned!
-
- Tableau Desktop for free for academic users: https://www.tableau.com/academic
- Tableau Public: free, but data and visualizations are stored open in the cloud: https://public.tableau.com/en-us/s/
- Videos from Tableau (may require registration): https://www.tableau.com/learn/tutorials/on-demand/getting-started-mapping?product=all&version=tableau_desktop_2019_3&topic=mapping
- Online help tutorial from Tableau: https://help.tableau.com/current/pro/desktop/en-us/maps.htm
- Mapping in Tableau CDVS Workshop
- Data to use with CDVS Workshop: https://duke.box.com/v/TableauMapping