In 2013, the average price for a gallon of gas was $3.80, President Obama was inaugurated for a second term, and Duke University Libraries offered DukeSpace as an institutional repository. Some things haven’t changed much, but the preservation architecture protecting the digital materials curated by the Libraries has changed a lot!
We still provide DukeSpace, but are laying the foundation to migrate collections and processes to the Duke Digital Repository (DDR). The DDR was conceived of and developed as a digital preservation repository, an environment intended to preserve and sustain the rich digital collections; university scholarship and research data; purchased collections, and history of Duke far into the future. Only through the grace of our partnership with Digital Projects and Production Services has the DDR recently also become a site that no longer hurts the eyes of our visitors.
The Duke Digital Repository endeavors to protect our assets from a large and diverse threat model. There are threats that are not addressed in the systems model presented here, such as those identified in the SPOT Model for Risk Assessment, of course. We formally consider these baseline threats to include:
Natural disasters including accidents at our local nuclear power station, fire, and hurricanes
Data degradation also known as bit rot or bit decay
External actors or threats posed by people external to the DDR team including those who manage our infrastructure
Internal actors including intentional or unintentional security risks and exploits by privileged staff in the libraries and supporting IT organizations
Phase 1 of our ingress into digital preservation established that DSpace, the software powering DukeSpace, was not sufficient for our needs, which led to an environmental scan and pilot project with Fedora and then Fedora and Hydra. This provided us with some of the infrastructure to mitigate the threats we had identified, but not all. In Phase 1 we were to perform some important preservation tasks including:
Prove authenticity by offering checksum fixity validation on ingest and periodically
Identify and report on data degradation
Capture context in the form of descriptive, administrative, and technical metadata
Phase 2 allows us to address a greater range of threats and therefore offer a higher level of security to our collections. In Phase 2 we’re doing several concurrent migrations including migrating our archival storage to infrastructure that will allow for dynamic resizing, de-duplication, and block-level integrity checking; moving to a horizontally scaled server architecture to allow the repository to grow to meet increasing demands of size (individual file size and size of collection) and traffic; and adopting a cloud replication disaster recovery process using DuraCloud to replace our local-only disk/tape infrastructure. These changes provide significant protection against our baseline threat model by providing geographic diversity to our replicas, allowing us to constantly monitor the health of our 3 cloud replicas, and providing administrative diversity to the management of our replicas ensuring no single threat may corrupt all 4 copies of our data.
More detail about the repository architecture to come.
To recap, EDTF is a machine readable date encoding standard that enables us to record dates with various levels of precision and certainty — important for cultural heritage collections.
One challenge of working with EDTF formatted dates is that it’s not necessarily obvious to humans what they mean. To the best of my knowledge, the available tools for working with EDTF dates are intended for parsing EDTF strings into objects that are understandable to programming languages. This is great for working with EDTF dates if you want to have the software do things like sort a list of items into date order or provide a searchable index of years. These tools are less helpful for outputting human readable versions of EDTF encoded dates, such as for an item’s metadata record display.
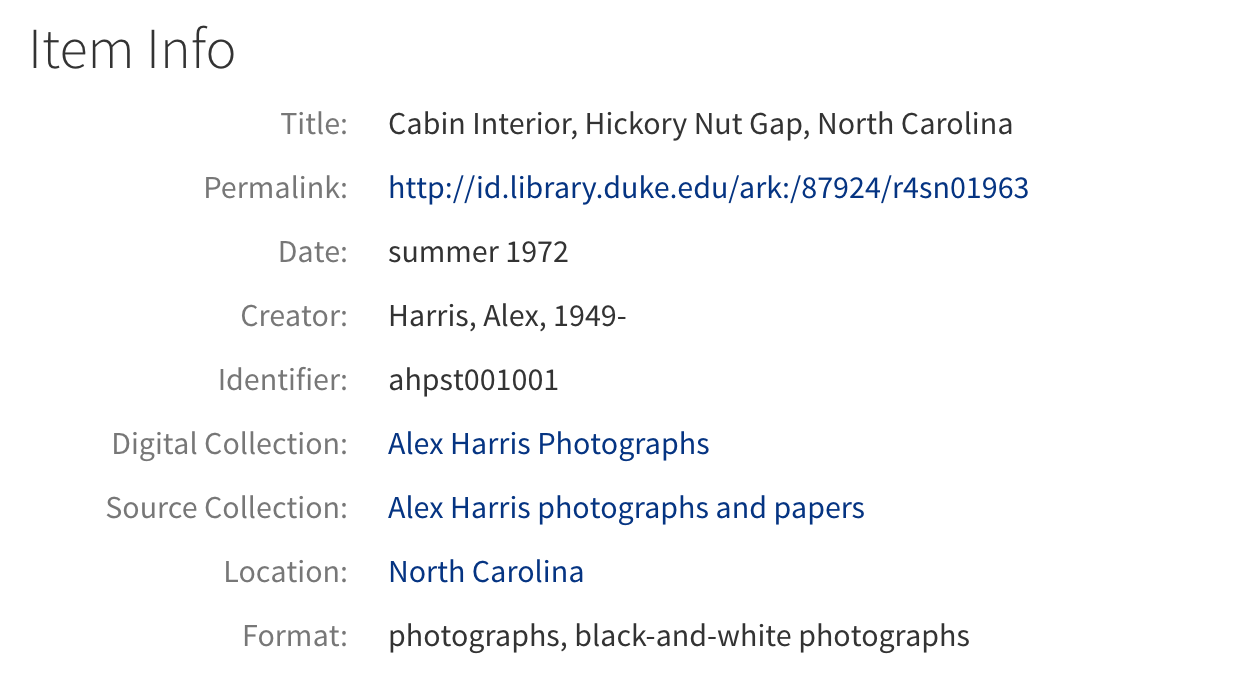
For instance, many of the photographs in the Alex Harris collection are dated with a season and year, such as “summer 1972.” EDTF specifies that “summer 1972” should be encoded as “1972-22.” This is great for our digital collections software, which knows what “1972-22” means (thanks to the EDTF gem). However, people unfamiliar with the EDTF standard will likely not understand what the date means.
But in the metadata display in the digital repository’s public interface we want to display the date in a more human friendly format:
Because EDTF is machine readable it’s possible to create a set of rules for transforming the dates for display. These rules can get complicated so I wrote a Ruby Gem that masks some of the complexity and adds a humanize method to any EDTF date object. This makes it simple to transform any EDTF encoded date to a human readable string.
> Date.edtf('1972-22').humanize
=> "summer 1972"
Although more work could be done to make it more flexible, the gem is somewhat configurable. For instance, an uncertain date with year precision is encoded in EDTF as “1972~”. The humanize method will by default output this as “circa 1972”:
> Date.edtf('1972~').humanize
=> "circa 1972"
But if for some reason I wanted a different output for an uncertain date with year precision I could modify the edtf-humanize configurations:
The humanize method that edtf-humanize adds to EDTF objects makes it much easier to display EDTF encoded date metadata in configurable human friendly formats.
The edtf-humanize gem is available on GitHub and RubyGems.org so it can be included in any Rails project’s gemfile. It should be considered an early release and could use some enhancement for use cases beyond Duke’s Digital Repository where it was originally designed to be used.
I think I speak for all of us in the Digital Collections Program when I say how excited we are to roll out this complex collection of digitized audio, video, and manuscripts that document sermons at Duke Chapel from the 1940s to early 2000s. You can now watch, listen to, and read sermons given at the Chapel by an array of preachers, including Duke Divinity faculty, and notable female and African American preachers. Many of the recordings contain full worship services complete with music by the Chapel’s 100-voice choir and four pipe organs. There are also special services, such as Martin Luther King, Jr. memorials, Good Fridays and Christmas Eves, Baccalaureates, and Convocations.
Digitization of this collection was made possible through our collaboration with Duke University’s Divinity School, Duke Chapel, University Archives, and Duke University Libraries’ Digital Collections Program. In 2015, the Divinity School received a Lilly Endowment Grant that funded the outsourcing of A/V digitization through two vendors, The Cutting Corporation and A/V Geeks, and the in-house digitization of the printed sermons. The grant will also support metadata enhancements to improve searchability and discovery, like tagging references within the recordings to biblical verses and liturgical seasons. The Divinity School will tackle this exciting portion of the project over the next two years, and their hard work will help users search deeper into the content of the collection.
Duke Chapel, September 1950
Back in 2014, digital collections program manager, Molly Bragg, announced the release of the first installation of digitized Duke Chapel Recordings. It consisted of 168 audio and video items and a newly developed video player. This collection was released in response to the high priority Duke Chapel placed on digitization, and high demand from patrons to digitize and view the materials. Fast forward two years and we have upped our game by expanding the collection to over 1,400 audio and video items, and adding more than 1,300 printed sermon manuscripts. Many of the printed sermons match up to a recording, as they are often the exact document the preacher used to deliver their sermon. The online content now represents a large percentage of the original materials held in the Duke University Archives taken from the Duke University Chapel Recordings and Duke Chapel Records collections. Many of the audio reels were not included in the scope of the project and we hope to digitize these in the near future.
Divinity student delivers practice sermon before faculty and students, undated
The Lilly Grant also provided funding to generate transcriptions of the audio-visual items, which we outsourced to Pop Up Archive, a company that specializes in creating timestamped transcripts and tags to make audio text searchable. Once the transcriptions are generated by Pop Up Archive and edited by Divinity students, they will be made available on the web interface alongside the recordings. All facets of this project support Divinity’s Duke Preaching Initiative to enhance homiletical education and pedagogy. With the release of the Duke Chapel Recordings Digital Collection, the Divinity School now has a great classroom resource to help students learn about the art of sermon writing and delivery.
The release of the Chapel Recordings marks yet another feat for the Digital Collections Program. This is the first audio-visual collection to be published in the new Tripod3 platform in conjunction with the Digital Collections migration into the Duke Digital Repository (see Will Sexton’s blog posts on the migration). Thanks to the hard work of many folks in the Digital Repository Services and Digital Projects and Production Services, this means for the user a new and squeaky clean interface to browse the collection. With the growing demand to improve online accessibility of audio-visual materials, Chapel Recordings has also been a great pilot project to explore how we can address A/V transcription needs across all our digital collections. It has presented us all with many challenges to overcome and successes to applaud along the way.
Chapel scene, 1985
If you’re not intrigued by the collection already, here are some sermon titles to lure you in!
While most of my Bitstreams posts have focused on my work preserving and archiving audio collections, my job responsibilities also include digitizing materials for display in Duke University Libraries Exhibits. The recent renovation and expansion of the Perkins Library entrance and the Rubenstein Library have opened up significantly more gallery space, meaning more exhibits being rotated through at a faster pace.
Working with such a variety of media spanning different library collections presents a number of challenges and necessitates working closely with our Exhibits and Conservation departments. First, we have to make sure that we have all of the items listed in the inventory provided by the exhibit curator. Secondly, we have to make sure we have all of the relevant information about how each item should be digitally captured (e.g. What image resolution and file specifications? Which pages from a larger volume? What section of a larger map or print?) Next we have to consider handling for items that are in fragile condition and need special attention. Finally, we use all of this information to determine which scanner, camera, or A/V deck is appropriate for each item and what the most efficient order to capture them in is.
All of this planning and preliminary work helps to ensure that the digitization process goes smoothly and that most questions and irregularities have already been addressed. Even so, there are always issues that come up forcing us to improvise creative solutions. For instance: how to level and stabilize a large, fragile folded map that is tipped into a volume with tight binding? How to assemble a seamless composite image of an extremely large poster that has to be photographed in multiple sections? How to minimize glare and reflection from glossy photos that are cupped from age? I won’t give away all of our secrets here, but I’ll provide a couple examples from the Duke Chapel exhibit that is currently on display in the Jerry and Bruce Chappell Family gallery.
This facsimile of a drawing for one of the Chapel’s carved angels was reproduced from an original architectural blueprint. It came to us as a large and tightly rolled blueprint–so large, in fact, that we had to add a piece of plywood to our usual camera work surface to accommodate it. We then strategically placed weights around the blueprint to keep it flattened while not obscuring the section with the drawing. The paper was still slightly wrinkled and buckled in places (which can lead to uneven color and lighting in the resulting digital image) but fortunately the already mottled complexion of the blueprint material made it impossible to notice these imperfections.
These projected images of the Chapel’s stained glass were reproduced from slides taken by a student in 1983 and currently housed in the University Archives. After the first run through our slide scanner, the digital images looked okay on screen, but were noticeably blurry when enlarged. Further investigation of the slides revealed an additional clear plastic protective housing which we were able to carefully remove. Without this extra refractive layer, the digital images were noticeably sharper and more vibrant.
Despite the digitization challenges, it is satisfying to see these otherwise hidden treasures being displayed and enjoyed in places that students, staff, and visitors pass through everyday–and knowing that we played a small part in contributing to the finished product!
Duke University has a long history of student activism, and the University Archives actively collects materials to document these movements. With the administration’s offices residing in the Allen Building, this is not the first time it is the center of activism activity. The Allen Building Study-In occurred November 13, 1967, the Allen Building Takeover occurred February 13, 1969, and the Allen Building Demonstration occurred in May 1970 to support the Vietnam Moratorium. In light of the current occupation of the Allen Building, we’ve compiled some digital resources you can use to find out more about the history of activism in relation to the 1969 Allen Building Takeover.
Allen Building Demonstration, 6 May 1970
The University Archives has a collection of materials from the 1969 Allen Building Takeover, which includes many digitized images available through the online finding aid. This collection also has materials from the 2002 Allen Building lock-in that commemorated 1960s activism at Duke: Guide to the Allen Building Takeover Collection, 1969-2002.
WDBS, Duke University’s campus radio station at the time of the 1969 Allen Building Takeover, also broadcasted reports on the event. Listening copies of these recordings are in the Allen Building Takeover Collection, and a list of the broadcasts can be found in the WDBS Collection: Guide to the WDBS Collection, 1949-1983.
Currently, University Archives is documenting the present Allen Building occupation, and has captured over 7,000 tweets with #DismantleDukePlantation. To ensure that Duke activism will continue to be represented in the archives, efforts will be made to collect additional materials related to the occupation.
Our modern day lives and professional endeavors are teeming with digital output. We participate in the digital ecosystem every day, contributing our activities, our scholarship, and our work in new and evolving ways. Some of that contribution gets lost in the Internet ether, and some gets saved, or preserved, in specific, often localized ways that are neither sustainable nor preservable for the long haul. We here at the Duke University Libraries, want to be able to look to the future with confidence, knowing that we have a game plan for capturing and preserving digital objects that are necessary and vital to the university community. Queue the new Duke Digital Repository.
The Duke Digital Repository is a software development initiative undertaken by the Digital Repository Services department in the Duke University Libraries. It is a preservation repository architected using the Fedora Open Source software project, which is intended to replace the current manifestation of our institutional repository, Duke Space. It is a superior product that is provisioned specifically for the preservation, storage, and access of digital objects. The Duke Digital Repository is fully operational; we are now in the process of refining user interfaces, ingesting new and varied collections, and assessing descriptive metadata needs for ingested collections.
So what’s next? Well we’ve got the Duke Digital Repository as a platform, now we need the Duke Digital Repository as a program. We need to clarify the services and support that we offer to the university community, we need to fully define its stakeholders, and we need to implement an organizational structure to support a robust service.
Here are just a few things that we’re engaged in that are seeking to define our user groups and assess their needs in a preservation platform and digital support service. Defining these expectations will allow us to take the next step in crafting a sustainable and relevant program to support the digital scholarship of the university.
ITHAKA Faculty Survey: In the Fall semester of 2015, the Libraries deployed the ITHAKA S+R Faculty Survey. Faculty are considered a primary stakeholder of the repository, as it is well provisioned to meet their data management needs. 260 faculty members responded to the survey, sharing their thoughts on a variety of topics including scholarly communications services, research practices, data preservation and management needs, and much more. There was a lot of valuable, actionable data contributed, which pertains directly to the repository as a preservation tool, and a service for data support. The digital repository team is working through this data to identify and target needs and desires in a repository program.
Graduate & Undergraduate Advisory Boards: The Digital Repository staff are also working with the Assessment & User Experience team within the library to reach out to graduate and undergraduate student constituents to capture their voice. We have collectively identified a list of questions and prompts that will engage them in a discussion about their needs pertaining to the repository as a tool and a service. From this discussion we are also gauging their understanding of ‘a repository’ and hoping to glean some information that will help us to understand how we might brand and market the repository more effectively.
Fedora Community: Fedora is an open source software product developed and stewarded by the DuraSpace community. The Duke University Libraries are active participants in the community which is essentially a consortium of academic institutions that are working toward a common goal of preserving intellectual, cultural, and scientific heritage. We are reaching out to our community constituents to ask how other institutions similar to ours are supporting their repository programs. We’re assessing various models of support and generating a discussion around repository support as a resourced program, rather than a simple software solution. We are also working with Assessment & User Experience to conduct an environmental scan and literature review to gain greater insight and understanding of best practice.
In short, we want to make the repository special, and relevant to its users. We want to feel confident that it provides a service that is valuable and necessary for our university community. We invite your feedback as we embark on this effort. For further information or to give us your feedback, please contact us.
Last Summer, Sean and I wrote about efforts we were were undertaking with colleagues to assess the research and scholarly impact of Duke Digital Collections. Sean wrote about data analysis approaches we took to detect scholarly use, and I wrote about a survey we launched in Spring 2015. The goal of the survey was to gather information about our patrons and their motivations that were not obvious from Google Analytics and other quantitative data. The survey was live for 7 months, and today I’m here to share the full results.
In a nutshell (my post last Summer included many details about setting up the survey), the survey asked users, “who are you,” “why are you here,” and “what are you going to do with what you find here?” The survey was accessible from every page of our Digital Collections website from April 30 – November 30, 2015. We set up event tracking in Google Analytics, so we know that around 43% of our 208,205 visitors during that time hovered on the survey link. A very small percentage of those clicked through (0.3% or 659 clicks), but 20% of the users that clicked through did answer the survey. This gave us a total of 132 responses, only one of which seems to be 100% spam. Traffic to the survey remained steady throughout the survey period. Now, onto the results!
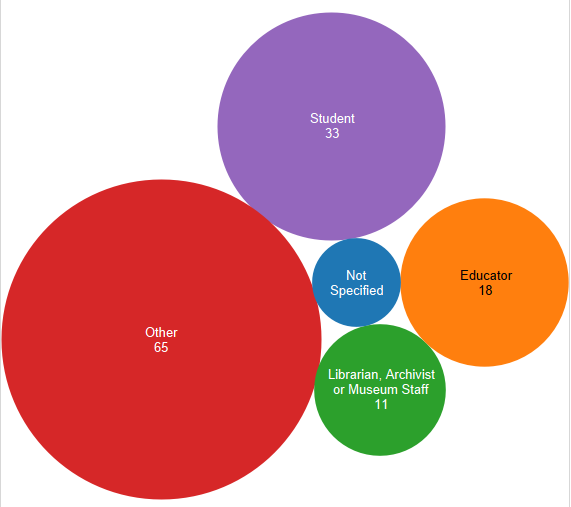
Question 1: Who are you?
Respondents were asked to identify as one of 2 academically oriented groups (students or educators), librarians, or as “other”. Results are represented in the bubble graphic below. You can see that the majority of respondents identified as “other”. Of those 65 respondents, 30 described themselves, and these labels have been grouped in the pie chart below. It is fascinating to note that other than the handful of self-identified musicians (I grouped vocalists, piano players, anything musical under musicians) and retirees, there is a large variety of self descriptors listed.
Responses to Question 1, “I am a (choose one)” (127 total – click to enlarge)Question 1 fill-in responses (39 total – click to enlarge)
The results breakdown of responses to question 1 remained steady over time when you compare the overall results to those I shared last Summer. Overall 26% of respondents identified as student (compared to 25% in July), 14% identified as educator (compared to 18% earlier), 9% identified as librarian, archivist or museum overall (exactly the same as earlier), and 51% identified as other (47% in the initial results). We thought these results might change when the Fall academic semester started, but as you can see that was not the case.
Question 2: Why are you here?
As I said above, our goal in all of our assessment work this time around was to look for signs of scholarly use so we were very interested in knowing if visitors come to Duke Digital Collections for academic research or for some other reason. Of the 125 total responses to question 2, personal research and casual browsing outweighed academic research ( see in the bar graph below). Respondents were able to check multiple categories. There were 8 instances where the same respondent selected casual browsing and personal research, 4 instances where casual browsing was paired with followed a link, 3 where academic research was tied to casual browsing, and 3 where academic research was tied to other. Several users selected more than 2 categories, but by in large respondents selected 1 category only. To me, this infers that our users are very clear about why they come to Duke Digital Collections.
Question 2 responses (125 total – click to enlarge)
Respondents were prompted to enter their research topic/purpose whether it be academic, personal or other. Every respondent that identified with other filled in a topic, 73% of personal researchers identified their topic, and 63% of academic researchers shared their topics. Many of the topics/purposes were unique, but research around music came up across all 3 categories as did topics related the history of a local region (all different regions). Advertising related topics also came up under academic and personal research. Several of the respondents who chose other entered a topic that suggested that they were in the early phases of a book project or looking for materials to use in classes. To me these seemed like more academically associated activities, and I was surprised they turned up under “other”. If I was able to ask follow up questions to these respondents, I would prompt for more information about their topic and why they defined it as academic or personal. Similarly, if we were designing this survey again, I think we would want to include a category for academic related uses apart from official research.
The results to question 2 also remained mostly consistent since our first view of the results last Summer. Academic research and casual browsing were tied at a 28% response rate each initially, and finished tied at a 30% response rate. The followed a link response rate when down from 17% to an overall 11%, personal research also went down from 44% to 36% overall, and other climbed slightly from 11% to 15% overall.
Question 3: What will you do with the images and/or resources you find on this site?
The third survey question attempts to get at the “now what” part of resource discovery. Following trends with the first two questions, it is not surprising that a majority of the 121 respondences are oriented towards “personal” use (see bar graph below). Like question 2, respondents were able to select multiple choices, however they tended to choose only one response.
Question 3 responses (121 total – click to enlarge)
Everyone who selected “other” did enter a statement, and of these a handful seemed like they could have fit under one of the defined categories. Several of the write-ins mentioned wanting to share items they found with family and friends assumably using methods other than social media. Five “others” responded with potentially academic related pursuits such as “an article”, “a book”, “update a book”, and 2 class related projects. I re-ran some numbers and combined these 5 responses with the academic publication, teaching tool, and homework respondents for a total of 55 possibly academically related answers or 45% of the total response to this question. The new 45% “academicish” grouping, as I like to think of it, is a more substantial total than each academic topic on its own. I propose this as an interesting way to slice and dice the data, and I’m sure there are others.
Observations
My colleagues and I have been very pleased with the results of this survey. First, we couldn’t be more thrilled that we were successfully able to collect necessary data (any data!). At the beginning of this assessment project, we were looking for evidence of research, scholarly and instructional use of Duke Digital Collections. We did find some, but this survey along with other data shows that the majority of our users come to Duke Digital Collections with a more personal agenda. We welcome the opportunity to make this kind of individual impact, and it is powerful. If the respondents of this survey are a representative sample of our user base, then our patrons are actively performing our collections (we have a lot of music), sharing items with family, friends, and community, as well as using the collections to pursue a wide variety of interests.
While this survey data assures us that we are making individual impacts, it also reveals that there is more we can do to cultivate our scholarly and researcher audience. This will be a long term process, but we have made some short term progress. As a result of our work in 2015, my colleagues and I put together a “teaching with digital collections” webpage to collect examples of instructional use and encourage more. In the course of developing a new platform for digital collections, we are also exploring new tools that could serve scholarly researchers more effectively. With a look towards the longer term, all of Duke University Libraries has been engaged in strategic planning for the past year, and Digital Collections is no exception. As we develop our goals around scholarly use, survey data like this is an important asset.
I’m curious to hear from others, what has your experience been with surveys? What have you learned and how have you put that knowledge to use? Feel free to comment or contact me directly! (molly.bragg at duke.edu)
The exhibit is installed in the Jerry and Bruce Chappell Family Gallery near the main entrance to the library. There are many exhibit cases filled with interesting items relating to the history of Duke Chapel. A touchscreen lenovo all-in-one computer is installed in the corner and runs a fullscreen version of Chrome containing an interface built in HTML. The interface encourages users to view six different videos and also listen to recordings of sermons given by some famous people over the years (including Desmond Tutu, Dr. Martin Luther King Sr., and Billy Graham) – these clips were pulled from our Duke Chapel Recordings digital collection. Here are some screenshots of the interface:
Home screenPlaying audio clipsPlaying a video
Carillon Video
One of the videos featured in the kiosk captures the University Carillonneur playing a short introduction, striking the bells to mark the time, and then another short piece. I was very fortunate to be able to go up into the bell tower and record J. Samuel Hammond playing this unique instrument. I had no idea as to the physicality involved and listening to the bells so close was really interesting. Here’s the final version of the video:
Chapel Windows
Another space in the physical exhibit features a projection of ten different stained glass windows from the chapel. Each window scrolls slowly up and down, then cycles to the next one. This was accomplished using CSS keyframes and my favorite image transition plugin, jquery cycle2. Here’s a general idea of how it looks, only sped up for web consumption:
Here’s a grouping of three of my favorite windows from the bunch:
The exhibit will be on display until June 19 – please swing by and check it out!
If you happen to be rummaging through your parents’ or grandparents’ attic, basement or garage, and stumble upon some old reel-to-reel audiotape, or perhaps some dust-covered videotape reels that seem absurdly large & clunky, they are most likely worthless, except for perhaps sentimental value. Even if these artifacts did, at one time, have some unique historic content, you may never know, because there’s a strong chance that decades of temperature extremes have made the media unplayable. The machines that were once used to play the media are often no longer manufactured, hard to find, and only a handful of retired engineers know how to repair them. That is, if they can find the right spare parts, which no one sells anymore.
Quarterback Bart Starr led the Green Bay Packers to a 35-10 victory over the Kansas City Chiefs in Super Bowl 1.Martin Haupt likely recorded Super Bowl 1 using an RCA Quadruplex 2″ color videotape recorder, common at television studios in the late 1960s.
However, once in a while, something that is one of a kind miraculously survives. That was the case for Troy Haupt, a resident of North Carolina’s Outer Banks, who discovered that his father, Martin Haupt, had recorded the very first Super Bowl onto 2” Quadruplex color videotape directly from the 1967 live television broadcast. After Martin passed away, the tapes ended up in Troy’s mother’s attic, yet somehow survived the elements.
What makes this so unique is that, in 1967, videotape was very expensive and archiving at television networks was not a priority. So the networks that aired the first Super Bowl, CBS and NBC, did not save any of the broadcast.
But Martin Haupt happened to work for a company that repaired professional videotape recorders, which were, in 1967, cutting edge technology. Taping television broadcasts was part of Martin’s job, a way to test the machines he was rebuilding. Fortunately, Martin went to work the day Super Bowl 1 aired live. The two Quadruplex videotapes that Martin Haupt used to record Super Bowl 1 cost $200 each in 1967. In today’s dollars, that’s almost $3000 total for the two tapes. Buying a “VCR” at your local department store was unfathomable then, and would not be possible for at least another decade. Somehow, Martin missed recording halftime, and part of the third quarter, but it turns out that Martin’s son Troy now owns the most complete known video recording of Super Bowl 1, in which the quarterback Bart Starr led the Green Bay Packers to a 35-10 victory over the Kansas City Chiefs.
Betty Cantor-Jackson recorded many of the Grateful Dead’s landmark concerts using a Nagra IV-S Reel to Reel audiotape recorder. The Dead’s magnum opus, “Dark Star” could easily fill an entire reel.
For music fans, another treasure was uncovered in a storage locker in Marin County, CA, in 1986. Betty Cantor-Jackson worked for The Grateful Dead’s road crew, and made professional multi-track recordings of many of their best concerts, between 1971-1980, on reel-to-reel audiotape. The Dead were known for marathon concerts in which some extended songs, like “Dark Star” could easily fill an entire audio reel. The band gave Betty permission to record, but she purchased her own gear and blank tape, tapping into the band’s mixing console to capture high-quality, soundboard recordings of the band’s epic concerts during their prime era. Betty held onto her tapes until she fell on hard times in the 1980’s, lost her home, and had to move the tapes to a storage locker. She couldn’t pay the storage fees, so the locker contents went up for auction.
Betty Cantor-Jackson recorded the Grateful Dead’s show at Barton Hall in 1977, considered by many fans to be one of their best concerts.
Some 1000 audio reels ended up in the hands of three different buyers, none of whom knew what the tapes contained. Once the music was discovered, copies of the recordings began to leak to hardcore tape-traders within the Deadhead community, and they became affectionately referred to as “The Betty Boards.” It turns out the tapes include some legendary performances, such as the 1971 Capitol Theatre run, and the May 1977 tour, including “Barton Hall, May 8, 1977,” considered by many Deadheads as one of the best Grateful Dead concerts of all time.
You would think the current owners of Super Bowl 1 and Barton Hall, May 8, 1977 would be sitting on gold. But, that’s where the lawyers come in. Legally, the people who possess these tapes own the physical tapes, but not the content on those tapes. So, Troy Haupt owns the 2” inch quadriplex reels of Super Bowl 1, but the NFL owns what you can see on those reels. The NFL owns the copyright of the broadcast. Likewise, The Grateful Dead owns the music on the audio reels, regardless of who owns the physical tape that contains the music. Unfortunately, for NFL fans and Deadheads, this makes the content somewhat inaccessable for now. Troy Haupt has offered to sell his videotapes to the NFL, but they have mostly ignored him. If Troy tries to sell the tapes to a third party instead, the NFL says they will sue him, for unauthorized distribution of their content. The owners of the Grateful Dead tapes face a similar dilema. The band’s management isn’t willing to pay money for the physical tapes, but if the owners, or any third party the owners sell the tapes to, try to distribute the music, they will get sued. However, if it weren’t for Martin Haupt and Betty Cantor-Jackson, who had the foresight to record these events in the first place, the content would not exist at all.
Bill Christens-Barry and Mike Adamo test the MSI system
Over the past 6 months or so the Digital Production Center has been collaborating with Duke Collaboratory for Classics Computing (DC3) and the Conservation Services Department to investigate multispectral imaging capabilities for the Library. Multispectral imaging (MSI) is a mode of image capture that uses a series of narrow band lights of specific frequencies along with a series of filters to illuminate an object. Highly tailored hardware and software are used in a controlled environment to capture artifacts with the goal of revealing information not seen by the human eye. This type of capture system in the Library would benefit many departments and researchers alike. Our primary focus for this collaboration are the needs of the Papyri community, Conservation Services along with additional capacity for the Digital Production Center.
Josh Sosin of DC3 was already in contact with Mike Toth of R. B. Toth Associates, a company that is at the leading edge of MSI for Cultural Heritage and research communities, on a joint effort between DC3, Conservation Services and the Duke Eye Center to use Optical Coherence Tomography (OCT) to hopefully reveal hidden layers of mummy masks made of papyri. The DPC has a long standing relationship with Digital Transitions, a reseller of the Phase One digital back, which happens to be the same digital back used in the Toth MSI system. And the Conservation lab was already involved in the OCT collaboration so it was only natural to invite R. B. Toth Associates to the Library to show us their MSI system.
After observing the OCT work done at the Eye Center we made our way to the Library to setup the MSI system. Bill Christens-Barry of R. B. Toth Associates walked me through some very high-level physics related to MSI, we setup the system and got ready to capture selected material which included Ashkar-Gilson manuscripts, various papyri and other material that might benefit from MSI. By the time we started capturing images we had a full house. Crammed into the room were members of DC3, DPC, Conservation, Digital Transitions and Toth Associates all of whom had a stake in this collaboration. After long hours of sitting in the dark (necessary for MSI image capture) we emerged from the room blurry eyed and full of hope that something previously unseen would be revealed.
The text of this manuscript was revealed primarily with the IR narrowband light at 940 nm, which Bill enhanced.
The resulting captures are as ‘stack’ or ‘block’ of monochromatic images captured using different wavelengths of light and ultraviolet and infrared filters. Using software developed by Bill Christens-Barry to process and manipulate the images will reveal information if it is there by combining, removing or enhancing images in the stack. One of the first items we processed was Ashkar-GilsonMS14 Deuteronomy 4.2-4.23 seen below. This really blew us away.
This item went from nearly unreadable to almost entirely readable! Bill assured me that he had only done minimal processing and that he should be able to uncover more of the text in the darker areas with some fine tuning. The text of this manuscript was revealed primarily through the use of the IR filter and was not necessarily the direct product of exposing the manuscript to individual bands of light but the result is no less spectacular. Because the capture process is so time consuming and time was limited no other Ashkar-Gilson manuscript was digitized at this time.
We digitized the image on the left in 2010 and ever since then, when asked, ‘What is the most exciting thing you have digitized’ I often answer, “The Ashkar-Gilson manuscripts. Manuscripts from ca. 7th to 8th Century C.E. Some of them still have fur on the back and a number of them are unreadable… but you can feel the history.” Now my admiration for these manuscripts is renewed and maybe Josh can tell me what it says.
It is our hope that we can bring this technology to Duke University so we can explore our material in greater depth and reveal information that has not been seen for a very, very long time.
Beth Doyle, Head of Conservation Services, wrote a blog post for Preservation Underground about her experience with MSI. Check it out!
Mike Toth, Mike Adamo, Bill Christens-Barry, Beth Doyle, Josh Sosin and Michael Chan
Also, check out this article from the New & Observer.