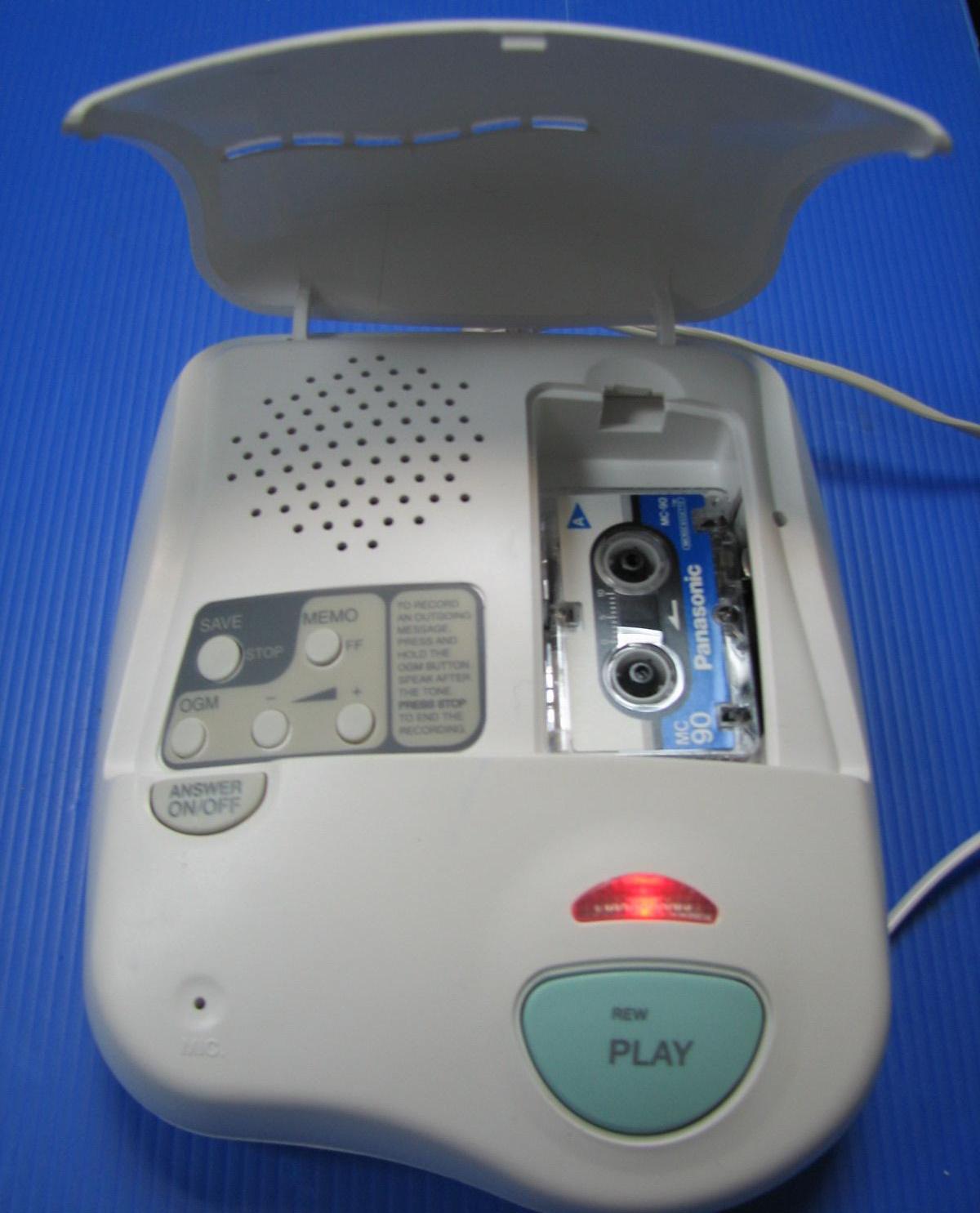
In past posts, I’ve paid homage to the audio ancestors with riffs on such endangered–some might say extinct–formats as DAT and Minidisc. This week we turn our attention to the smallest (and perhaps the cutest) tape format of them all: the Microcassette.
Introduced by the Olympus Corporation in 1969, the Microcassette used the same width tape (3.81 mm) as the more common Philips Compact Cassette but housed it in a much smaller and less robust plastic shell. The Microcassette also spooled from right to left (opposite from the compact cassette) as well as using slower recording speeds of 2.4 and 1.2 cm/s. The speed adjustment, allowing for longer uninterrupted recording times, could be toggled on the recorder itself. For instance, the original MC60 Microcassette allowed for 30 minutes of recorded content per “side” at standard speed and 60 minutes per side at low speed.
The microcassette was mostly used for recording voice–e.g. lectures, interviews, and memos. The thin tape (prone to stretching) and slow recording speeds made for a low-fidelity result that was perfectly adequate for the aforementioned applications, but not up to the task of capturing the wide dynamic and frequency range of music. As a result, the microcassette was the go-to format for cheap, portable, hand-held recording in the days before the smartphone and digital recording. It was standard to see a cluster of these around the lectern in a college classroom as late as the mid-1990s. Many of the recorders featured voice-activated recording (to prevent capturing “dead air”) and continuously variable playback speed to make transcription easier.
The tiny tapes were also commonly used in telephone answering machines and dictation machines.
As you may have guessed, the rise of digital recording, handheld devices, and cheap data storage quickly relegated the microcassette to a museum piece by the early 21st century. While the compact cassette has enjoyed a resurgence as a hip medium for underground music, the poor audio quality and durability of the microcassette have largely doomed it to oblivion except among the most willful obscurantists. Still, many Rubenstein Library collections contain these little guys as carriers of valuable primary source material. That means we’re holding onto our Microcassette player for the long haul in all of its atavistic glory.
image by the author. other images in this post taken from Wikimedia Commons (https://commons.wikimedia.org/wiki/Category:Microcassette)
Last spring, we were awfully excited to see the DPLA/Europeana release of RightStatements.org, a suite of standardized rights statements for describing the copyright and re-use status of digital resources. We have never had a comprehensive approach towards rights management for the Duke Digital Repository, but with the release of RightsStatements.org, we now feel we are equipped to wrestle that beast.
Managing and communicating rights statuses for digital collections has long been a challenge for us. The DDR currently allows for the application and display of Creative Commons licenses, which can be used for situations where the copyright holders themselves can assert the rights statuses for their own resources. RightsStatements.org fills a giant gap for us, in that it allow us to assign machine-readable rights to repository resources for which we know something about the rights status but do not hold the copyrights for. Additionally, these statements accommodate for the often fluid and ambiguous nature of copyrights for cultural heritage materials.
So, it’s been nearly a year since the statements were published, and during that time a community best practice has started to develop. The approach we have decided on for rights management in the Duke Digital Repository follows this emerging best practice, and involves using one field – Dublin Core Rights, as that is the metadata standard our repository uses – to store either a Creative Commons or RightsStatements.org URI, and nothing but that URI, and another field – a local property which we are calling ‘Rights Note’ – to store free text contextual information relating to the rights status of the resource (as long as it’s not in conflict with rights statement applied). Having machine-processable rights statuses means we will have a much better rights management strategy (we don’t currently have a way to report on the rights status of repository materials), as well as the ability to clearly communicate to users what they can and cannot do with resources they find.
Now that we’ve got a strategy for doing rights management, however, we need to develop a strategy for implementing it. We’ll tackle the low-hanging fruit first – collections that have a single, identifiable creator or for which the date ranges put them into the public domain – and then move on to the trickier stuff – for example, collections representing multiple or unidentified creators. Digital collections of archival materials present especially difficult challenges, as the the repository ‘itemness’ is frequently at the folder-level, meaning that the ‘item’, in these cases, might contain works by multiple creators of varying rights statuses (think of a folder of correspondence, for example).
The good news is, there are a lot of smart people working on addressing these challenges. Laura Capell and Elliott Williams of the University of Miami published a helpful poster, Assigning Rights Statements to Legacy Digital Collections describing the the decision matrix they developed to help them apply rights statements to their digital collections, and as I was writing this blog post, the Society of American Archivists circulated their Guide to Implementing Rights Statements from RightsStatements.org (nice timing, SAA!). I’m hoping to find some good nuggets of wisdom in its pages. We feel especially well-positioned to tackle rights management here at Duke, as Dave Hansen, who was deeply involved in the development of RightsStatements.org, joined us as our Director of Copyright and Scholarly Communications last year. We’d love to hear from other organizations as they develop their own local implementations – we know we’re not in this alone!
We are still many months (well, OK — a year or more) away from unplugging the servers that keep the Endeca powered Search TRLN catalog and our local catalogs alive. But in the meantime work is well underway on its replacement. For those who don’t know, the libraries of Duke, UNC Chapel Hill, NC State, and NCCU have for many years maintained a shared catalog to make resources for all Triangle research libraries easily available to our communities. We all push our records to a centralized data pipeline that indexes our data in Endeca and even share much of the code that runs our local catalog user interfaces. While the browsing and searching capabilities of Endeca were innovative for library catalogs at the time, the rest of the library world has caught up and there are numerous open source solutions to providing convenient and powerful search and browse access to our holdings.
Some goals for the replacement for the Endeca based shared catalog system include:
Maintain functionality of the current catalog, including search & browse features.
Architect the new system so that it’s easier for staff to troubleshoot problems and test changes to the data pipeline.
Use open source tools already in common use by peer libraries to take advantage of community effort and knowledge.
Develop a platform that makes it easy for each institution to host their own copy of the catalog UI, that takes advantage of shared features and code, while allowing for local customization where needed.
Provide a centralized data service and index that can process and host all 12 million or so records from each institution that will provide the back end index for all local catalogs. (NCCU will use a separate vended solution for their catalog.)
The large team of librarians and staff from across the Research Triangle libraries have been hard at work planning for the new system and many characteristics of the new system are becoming clear:
We will use Solr as the replacement for Endeca. Solr will store and index our collective holdings and provide search and browse access to our holdings for our catalog applications.
Blacklight, a UI built to search and browse a Solr Index will provide the basis for our local catalogs. Blacklight is used by Stanford, Cornell, and many other libraries to provide the user interface to their catalogs.
We will build a Rails Engine that will add to Blacklight any customizations needed to support the consortial catalog and any additional features that the institutions want to share. This engine will make it easy to build a new Blacklight based catalog that will work with the TRLN Solr Index.
The data pipeline, Solr index and Catalog UI will be packaged in such a way that staff can run a near copy of the production system locally to develop and test changes.
What we have so far:
Scripts built with Traject that will take our MARC XML or MARC Binary records and transform them into an intermediate JSON format.
Scripts that take the JSON data and index the data in Solr.
The beginnings of a Rails engine that will form the basis of our Blacklight catalog user interfaces.
The technical implementation team is using the TRLN GitHub account to collaborate on development, and much work-in-progress code is posted there. There is still plenty of work left to do, a long list of requirements to accommodate and many unanswered questions, but the project is well underway to build the next shared catalog for the Triangle Research Libraries.
“There is nothing wrong with your television set. Do not attempt to adjust the picture. We are controlling transmission. We will control the horizontal. We will control the vertical. We repeat: there is nothing wrong with your television set.”
That was part of the cold open of one of the best science fiction shows of the 1960’s, “The Outer Limits.” The implication being that by controlling everything you see and hear in the next hour, the show’s producers were about to blow your mind and take you to the outer limits of human thought and fantasy, which the show often did.
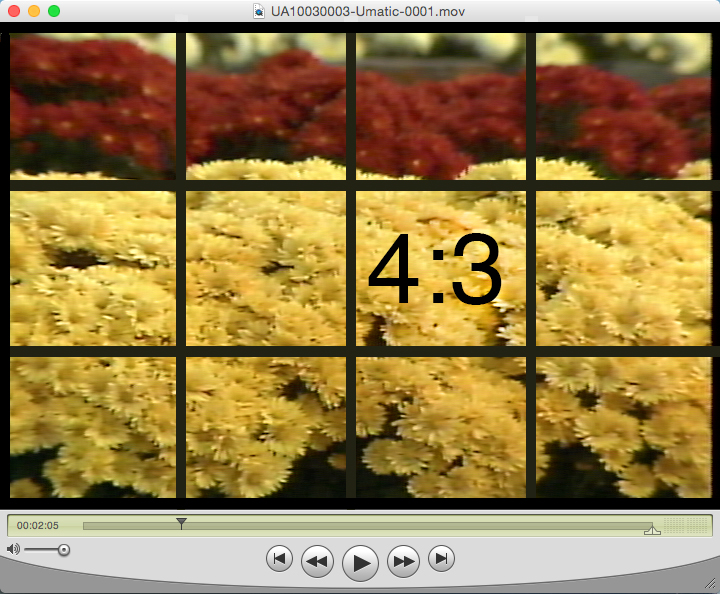
In regards to controlling the horizontal and the vertical, one of the more mysterious parts of my job is dealing with aspect ratios when it comes to digitizing videotape. The aspect ratio of any shape is the proportion of it’s dimensions. For example, the aspect ratio of a square is always 1 : 1 (width : height). That means, in any square, the width is always equal to the height, regardless of whether a square is 1-inch wide or 10-feet wide. Traditionally, television sets displayed images in a 4 : 3 ratio. So, if you owned a 20” CRT (cathode ray tube) TV back in the olden days, like say 1980, the broadcast image on the screen was 16” wide by 12” high. So, the height was 3/4 the size of the width, or 4 : 3. The 20” dimension was determined by measuring the rectangle diagonally, and was mainly used to categorize and advertise the TV.
Almost all standard-definition analog videotapes, like U-matic, Beta and VHS, have a 4 : 3 aspect ratio. But when digitizing the content, things get more complicated. Analog video monitors display pixels that are tall and thin in shape. The height of these pixels is greater than their width, whereas modern computer displays use pixels that are square in shape. On an analog video monitor, NTSC video displays at roughly 720 (tall and skinny) pixels per horizontal line, and there are 486 visible horizontal lines. If you do the math on that, 720 x 486 is not 4 : 3. But because the analog pixels display tall and thin, you need more of them aligned vertically to fill up a 4 : 3 video monitor frame.
When Duke Libraries digitizes analog video, we create a master file that is 720 x 486 pixels, so that if someone from the broadcast television world later wants to use the file, it will be native to that traditional standard-definition broadcast specification. However, in order to display the digitized video on Duke’s website, we make a new file, called a derivative, with the dimensions changed to 640 x 480 pixels, because it will ultimately be viewed on computer monitors, laptops and smart phones, which use square pixels. Because the pixels are square, 640 x 480 is mathematically a 4 : 3 aspect ratio, and the video will display properly. The derivative video file is also compressed, so that it will stream smoothly regardless of internet bandwidth limits.
“We now return control of your television set to you. Until next week at the same time, when the control voice will take you to – The Outer Limits.”
A little more than a year ago, I wrote about the proposed update to the 508 accessibility standards. And about three weeks ago, the US Access Board published the final rule that contains updates to the 508 accessibility requirements for Information and Communication Technology (ICT). The rules had not previously been updated since 2001 and as such had greatly lagged behind modern web conventions.
It’s important to note that the 508 guidelines are intended to serve as a vehicle for guiding procurement, while at the same time applying to content created by a given group/agency. As such, the language isn’t always straightforward.
What’s new?
As I outlined in my previous post, a major purpose of the new rule is to move away from regulating types of devices and instead focus on functionality:
… one of the primary purposes of the final rule is to replace the current product-based approach with requirements based on functionality, and, thereby, ensure that accessibility for people with disabilities keeps pace with advances in ICT.
To that effect, one of the biggest change over the old standard is the adoption of WCAG 2.0 as the compliance level. The fundamental premise of WCAG compliance is that content is ‘perceivable, operable, and understandable’ — bottom line is that as developers, we should strive to make sure all of our content is usable for everyone across all devices. The adoption of WCAG allows the board to offload responsibility of making incremental changes as technology advances (so we don’t have to wait another 15 years for updates) and also aligns our standards in the United States with those used around the world.
Harmonization with international standards and guidelines creates a larger marketplace for accessibility solutions, thereby attracting more offerings and increasing the likelihood of commercial availability of accessible ICT options.
Another change has to do with making a wider variety of electronic content accessible, including internal documents. It will be interesting to see to what degree this part of the rule is followed by non-federal agencies.
The Revised 508 Standards specify that all types of public-facing content, as well as nine categories of non-public-facing content that communicate agency official business, have to be accessible, with “content” encompassing all forms of electronic information and data. The existing standards require Federal agencies to make electronic information and data accessible, but do not delineate clearly the scope of covered information and data. As a result, document accessibility has been inconsistent across Federal agencies. By focusing on public-facing content and certain types of agency official communications that are not public facing, the revised requirements bring needed clarity to the scope of electronic content covered by the 508 Standards and, thereby, help Federal agencies make electronic content accessible more consistently.
The new rules do not go into effect until January 2018. There’s also a ‘safe harbor’ clause that protects content that was created before this enforcement date, assuming it was in compliance with the old rules. However, if you update that content after January, you’ll need to make sure it complies with the new final rule.
Existing ICT, including content, that meets the original 508 Standards does not have to be upgraded to meet the refreshed standards unless it is altered. This “safe harbor” clause (E202.2) applies to any component or portion of ICT that complies with the existing 508 Standards and is not altered. Any component or portion of existing, compliant ICT that is altered after the compliance date (January 18, 2018) must conform to the updated 508 Standards.
So long story short, a year from now you should make sure all the content you’re creating meets the new compliance level.
If you’ve visited the Duke University Libraries website in the past month, you may have noticed that it looks a bit more polished than it used to. Over the course of the fall 2016 semester, my talented colleague Michael Daul and I co-led a project to develop and implement a new theme for the site. We flipped the switch to launch the theme on January 6, 2017, the week before spring classes began. In this post, I’ll share some background on the project and its process, and highlight some noteworthy features of the new theme we put in place.
Newly refreshed Duke University Libraries website homepage.
Goals
We kicked off the project in Aug 2016 using the title “Website Refresh” (hat-tip to our friends at NC State Libraries for coining that term). The best way to frame it was not as a “redesign,” but more like a 50,000-mile maintenance tuneup for the site. We had four main goals:
Extend the Life of our current site (in Drupal 7) without a major redesign or redevelopment effort
Refresh the Look of the site to be modern but not drastically different
Better Code by streamlining HTML markup & CSS style code for easier management & flexibility
Enhance Accessibility via improved compliance with WCAG accessibility guidelines
Our site is fairly large and complex (1,200+ pages, for starters). So to keep the scope lean, we included no changes in content, information architecture, or platform (i.e., stayed on Drupal 7). We also worked with a lean stakeholder team to make decisions related to aesthetics.
Extending the Life of the Site
Our old website theme was aging; the project leading to its development began five years ago in Sep 2012, was announced in Jan 2013, and then eventually launched about three years ago in Jan 2014. Five years–and even three–is a long time in web years. Sites accumulate a lot of code cruft over time, the tools for managing and writing code become deprecated quickly. We wanted to invest a little time now to replace some pieces of the site’s front-end architecture with newer and better replacements, in order to buy us more time before we’d have to do an expensive full-scale overhaul from the ground up.
Refreshing the Look
Our 2014 site derived a lot its aesthetic from the main Duke.edu website at the time. Duke’s site has changed significantly since then, and meanwhile, web design trends have changed dramatically: flat design is in, skeuomorphism out. Google Web Fonts are in, Times, Arial, Verdana and company are out. Even a three year old site on the web can look quite dated.
Old site theme, dated aesthetics.New “refreshed” theme, with flatter, more modern aestheticCloseup on skeuomorphic embellishments vs. flat elements.
Better Code
Beyond evolving aesthetics, the various behind-the-scenes web frameworks and code workflows are in constant, rapid flux; it can really keep a developer’s head on a swivel. Better code means easier maintenance, and to that end our code got a lot better after implementing these solutions:
Bootstrap Upgrade. For our site’s HTML/CSS/JS framework, we moved from Bootstrap version 2 (2.3.1) to version 3 (3.3.7). This took weeks of work: it meant thousands of pages of markup revisions, only some of which could be done with a global Search & Replace.
Sass for CSS. We trashed all of our old theme’s CSS files and started over using Sass, a far more efficient way to express and maintain style rules than vanilla CSS.
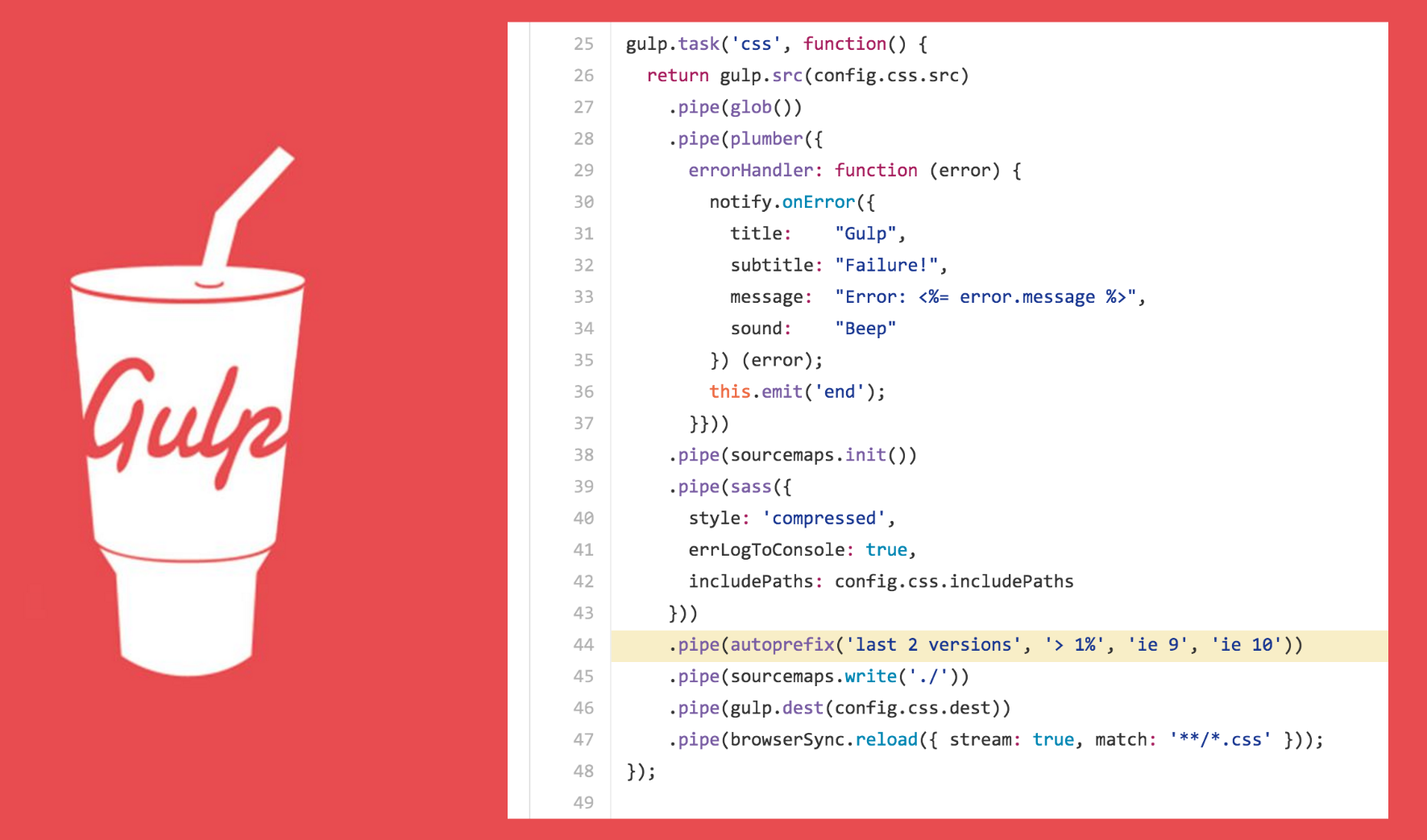
Gulp for Automation. Our new theme uses Gulp to automate code tasks like processing Sass into CSS, auto-prefixing style declarations to work on older browsers, and crunching 30+ css files down into one.
Font Awesome. We ditched most of our older image-based icons in favor of Font Awesome ones, which are far easier to reference and style, and faster to load.
Radix. This was an incredibly useful base theme for Drupal that encapsulates/integrates Sass, Gulp, Bootstrap, and FontAwesome. It also helped us get a Bootswatch starter theme in the mix to minimize the local styling we had to do on top of Bootstrap.
We named our new theme Dulcet and put it up on GitHub.
Sass for style management, e.g., expressing colors as reusable variables.Gulp for task automation, e.g., auto-prefixing styles to account for older browser workarounds.
Accessibility
Some of the code and typography revisions we’ve made in the “refresh” improve our site’s compliance with WCAG2.0 accessibility guidelines. We’re actively working on further assessment and development in this area. Our new theme is better suited to integrate with existing tools, e.g., to automatically add ARIA attributes to interactive page elements.
Feedback or Questions?
We would love to hear from you if you have any feedback on our new site, if you spot any oddities, or if you’re considering doing a similar project and have any questions. We encourage you to explore the site, and hope you find it a refreshing experience.
Here at the Duke University Libraries we recently hosted a series of workshops that were part of a larger Research Symposium on campus. It was an opportunity for various campus agencies to talk about all of the evolving and innovative ways that they are planning for and accommodating research data. A few of my colleagues and I were asked to present on the new Research Data program that we’re rolling out in collaboration with the Duke Digital Repository, and we were happy to oblige!
I was asked to speak directly about the various software development initiatives that we have underway with the Duke Digital Repository. Since we’re in the midst of rolling out a brand new program area, we’ve got a lot of things cooking!
When I started planning for the conversation I initially thought I would talk a lot about our Fedora/Hydra stack, and the various inter-related systems that we’re planning to integrate into our repository eco-system. But what resulted from that was a lot of technical terms, and open-source software project names that didn’t mean a whole lot to anyone; especially those not embedded in the work. As a result, I took a step back and decided to focus at a higher level. I wanted to present to our faculty that we were implementing a series of software solutions that would meet their needs for accommodation of their data. This had me revisiting the age-old question: What is our Repository? And for the purposes of this conversation, it boiled down to this:
And this:
It is a highly complex, often mind-boggling set of software components, that are wrangled and tamed by a highly talented team with a diversity of skills and experience, all for the purposes of supporting Preservation, Curation, and Access of digital materials.
Those are our tenets or objectives. They are the principles that guide out work. Let’s dig in a bit on each.
Our first objection is Preservation. We want our researchers to feel 100% confident that when they give us their data, that we are preserving the integrity, longevity, and persistence of their data.
Our second objective is to support Curation. We aim to do that by providing software solutions that facilitate management and description of file sets, and logical arrangement of complex data sets. This piece is critically important because the data cannot be optimized without solid description and modeling that informs on its purpose, intended use, and to facilitate discovery of the materials for use.
Finally our work, our software, aims to facilitate discovery & access. We do this by architecture thoughtful solutions that optimize metadata and modeling, we build out features that enhance the consumption and usability of different format types, we tweak, refine and optimize our code to enhance performance and user experience.
The repository is a complex beast. It’s a software stack, and an eco-system of components. It’s Fedora. It’s Hydra. It’s a whole lot of other project names that are equally attractive and mystifying. At it’s core though, it’s a software initiative- one that seeks to serve up an eco-system of components with optimal functionality that meet the needs and desires of our programmatic stakeholders- our University.
Preservation, Curation, & Access are the heart of it.
I am sure you have all been following the Library’s exploration into Multispectral Imaging (MSI) here on Bitstreams, Preservation Underground and the News & Observer. Previous posts have detailed our collaboration with R.B. Toth Associates and the Duke Eye Center, the basic process and equipment, and the wide range of departments that could benefit from MSI. In early December of last year (that sounds like it was so long ago!), we finished readying the room for MSI capture, installed the equipment, and went to MSI boot camp.
Obligatory before and after shot. In the bottom image, the new MSI system is in the background on the left with the full spectrum system that we have been using for years on the right. Other additions to the room are blackout curtains, neutral gray walls and black ceiling tiles all to control light spill between the two camera systems. Full spectrum overhead lighting and a new tile floor were installed which is standard for an imaging lab in the Library.
Well, boot camp came to us. Meghan Wilson, an independent contractor who has worked with R.B. Toth Associates for many years, started our training with an overview of the equipment and the basic science behind it. She covered the different lighting schemes and when they should be used. She explained MSI applications for identifying resins, adhesives and pigments and how to use UV lighting and filters to expose obscured text. We quickly went from talking to doing. As with any training session worth its salt, things went awry right off the bat (not Meghan’s fault). We had powered up the equipment but the camera would not communicate with the software and the lights would not fire when the shutter was triggered. This was actually a good experience because we had to troubleshoot on the spot and figure out what was going on together as a team. It turns out that there are six different pieces of equipment that have to be powered-up in a specific sequence in order for the system to communicate properly (tee up Apollo 13 soundtrack). Once we got the system up and running we took turns driving the software and hardware to capture a number of items that we had pre-selected. This is an involved process that produces a bunch of files that eventually produce an image stack that can be manipulated using specialized software. When it’s all said and done, files have been converted, cleaned, flattened, manipulated and variations produced that are somewhere in the neighborhood of 300 files. Whoa!
This is not your parents’ point and shoot—not the room, the lights, the curtains, the hardware, the software, the pricetag, none of it. But it is different in another more important way too. This process is team-driven and interdisciplinary. Our R&D working group is diverse and includes representatives from the following library departments.
The Digital Production Center (DPC) has expertise in high-end, full spectrum imaging for cultural heritage institutions along with a deep knowledge of the camera and lighting systems involved in MSI, file storage, naming and management of large sets of files with complex relationships.
The Duke Collaboratory for Classics Computing (DC3) offers a scholarly and research perspective on papyri, manuscripts, etc., as well as experience with MSI and other imaging modalities
The Conservation Lab brings expertise in the Libraries’ collections and a deep understanding of the materiality and history of the objects we are imaging.
Duke Libraries’ Data Visualization Services (DVS) has expertise in the processing and display of complex data.
The Rubenstein Library’s Collection Development brings a deep understanding of the collections, provenance and history of materials, and valuable contacts with researchers near and far.
To get the most out of MSI we need all of those skills and perspectives. What MSI really offers is the ability to ask—and we hope answer—strings of good questions. Is there ink beneath that paste-down or paint? Is this a palimpsest? What text is obscured by that stain or fire-damage or water damage? Can we recover it without having to intervene physically? What does the ‘invisible’ text say and what if anything does this tell us about the object’s history? Is the reflectance signature of the ink compatible with the proposed date or provenance of the object? That’s just for starters. But you can see how even framing the right question requires a range of perspectives; we have to understand what kinds of properties MSI is likely to illuminate, what kinds of questions the material objects themselves suggest or demand, what the historical and scholarly stakes are, what the wider implications for our and others’ collections are, and how best to facilitate human interface with the data that we collect. No single person on the team commands all of this.
Working in any large group can be a challenge. But when it all comes together, it is worth it. Below is a page from Jantz 723, one processed as a black and white image and the other a Principal Component Analysis produced by the MSI capture and processed using ImageJ and a set of tools created by Bill Christens-Barry of R.B. Toth Associates with false color applied using Photoshop. Using MSI we were able to better reveal this watermark which had previously been obscured.
Jantz 723
I think we feel like 16-year-old kids with newly minted drivers’ licenses who have never driven a car on the highway or out of town. A whole new world has just opened up to us, and we are really excited and a little apprehensive!
What now?
Practice, experiment, document, refine. Over the next 12 (16? 18) months we will work together to hone our collective skills, driving the system, deepening our understanding of the scholarly, conservation, and curatorial use-cases for the technology, optimizing workflow, documenting best practices, getting a firm grip on scale, pace, and cost of what we can do. The team will assemble monthly, practice what we have learned, and lean on each other’s expertise to develop a solid workflow that includes the right expertise at the right time. We will select a wide variety of materials so that we can develop a feel for how far we can push the system and what we can expect day to day. During all of this practice, workflows, guidelines, policies and expectations will come into sharper focus.
As you can tell from the above, we are going to learn a lot over the coming months. We plan to share what we learn via regular posts here and elsewhere. Although we are not prepared yet to offer MSI as a standard library service, we are interested to hear your suggestions for Duke Library collection items that may benefit from MSI imaging. We have a long queue of items that we would like to shoot, and are excited to add more research questions, use cases, and new opportunities to push our skills forward. To suggest materials, contact Molly Bragg, Digital Collections Program Manager (molly.bragg at Duke.edu), Joshua Sosin, Associate Professor in Classical Studies & History (jds15 at Duke.edu) or Curator of Collections (andrew.armacost at Duke.edu).
Today is an eventful day for the Duke Digital Repository (DDR). Later today, I and several of my colleagues will present on the DDR at Day 1 of the Duke Research Computing Symposium. We’ll be introducing new staff who’ll focus on managing, curating, and preserving research data, as well as the role that the DDR will play as both a service and a platform. This event serves as a soft launch of our plans – which I wrote about last September – to support the work of researchers at Duke.
Out-of-the-box DDR home page of the past
At the same time, the DDR gets a new look, at least on its home page. For years, we’ve used a rather drab and uninformative page that was essentially the out-of-the-box rendering by Blacklight, our discovery and access layer in the repository stack. Last fall, our DDR Program Committee took up the task of revamping that page to reflect how we conceptualize the repository and its major program areas.
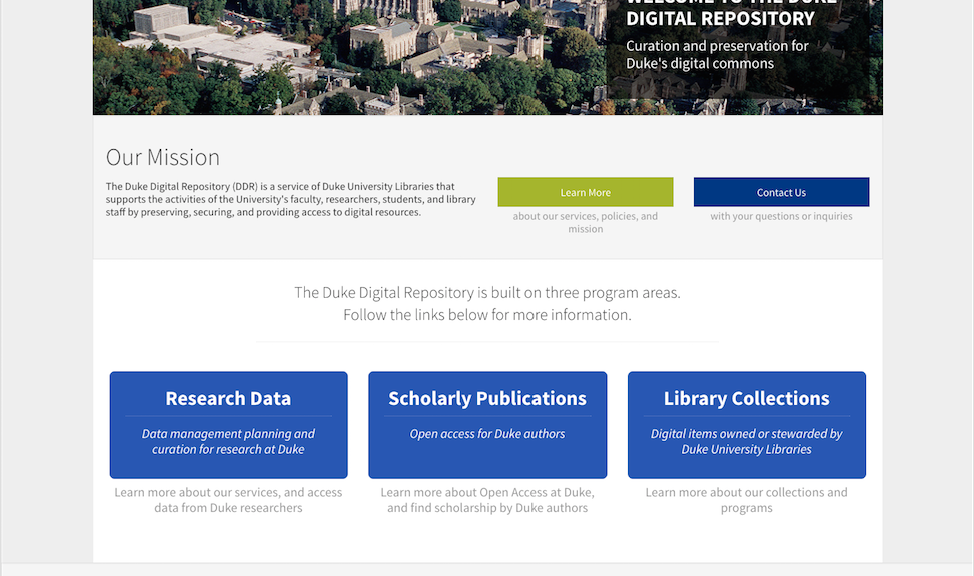
New DDR home page with aerial hero image and three program areas.
The page design will evolve with the DDR itself, but it went live earlier today. More information about the DDR initiative and our plans will follow in the coming months.
At Duke University Libraries (DUL), we are embarking on a new way to propose digitization projects. This isn’t a spur of the moment New Year’s resolution I promise, but has been in the works for months. Our goal in making a change to our proposal process is twofold: first, we want to focus our resources on specific types of projects, and second, we want to make our efforts as efficient as possible.
Introducing Digitization Initiatives
The new proposal workflow centers on what we are calling “digitization initiatives.” These are groups of digitization projects that relate to a specific theme or characteristic. DUL’s Advisory Council for Digital Collections develops guidelines for an initiative, and will then issue a call for proposals to the library. Once the call has been issued, library staff can submit proposals on or before one of two deadlines over a 6 month period. Following submission, proposals will be vetted, and accepted proposals will move onto implementation. Our previous system did not include deadlines, and proposals were asked to demonstrate broad strategic importance only.
DUL is issuing our first call for proposals now, and if this system proves successful we will develop a second digitization initiative to be announced in 2018.
I’ll say more about why we are embarking on this new system later, but first I would like to tell you about our first digitization initiative.
Call for Proposals
Duke University Libraries’ Advisory Council for Digital Collections has chosen diversity and inclusion as the theme of our first digitization initiative. This initiative draws on areas of strategic importance both for DUL (as noted in the 2016 strategic plan) and the University. Prospective champions are invited to think broadly about definitions of diversity and inclusion and how particular collections embody these concepts, which may include but is not limited to topics of race, religion, class, ability, socioeconomic status, gender, political beliefs, sexuality, age, and nation of origin.
Proposals will be due on March 15, 2017 or June 15, 2017.
Proposing non-diversity and inclusion related proposal
We have not forgotten about all the important digitization proposals that support faculty, important campus or off campus partnerships, and special events. In our experience, these are often small projects and do not require a lot of extra conservation, technical services, or metadata support so we are creating an“easy” project pipeline. This will be a more light-weight process that will still requires a proposal, but less strategic vetting at the outset. There will be more details coming out in late January or February on these projects so stay tuned.
Why this change?
I mentioned above that we are moving to this new system to meet two goals. First, this new system will allow us to focus proposal and vetting resources on projects that meet a specific strategic goal as articulated by an initiative’s guidelines. Additionally, over the last few years we have received a huge variety of proposals: some are small “no brainer” type proposals while others are extremely large and complicated. We only had one system for proposing and reviewing all proposals, and sometimes it seemed like too much process and sometimes too little. In other words one process size does not not fit all. By dividing our process into strategically focussed proposals on the one hand and easy projects on the other, we can spend more of our Advisory committee’s time on proposals that need it and get the smaller ones straight into the hands of the implementation team.
Another benefit of this process is that proposal deadlines will allow the implementation team to batch various aspects of our work (batching similar types of work makes it go faster). The deadlines will also allow us to better coordinate the digitization related work performed by other departments. I often find myself asking departments to fit digitization projects in with their already busy schedules, and it feels rushed and can create unnecessary stress. If the implementation team has a queue of projects to address, then we can schedule it well in advance.
I’m really excited to see this new process get off the ground, and I’m looking forward to seeing all the fantastic proposals that will result from the Diversity and Inclusion initiative!
Notes from the Duke University Libraries Digital Projects Team